Learning Dynamic Graph Representations through Timespan View Contrasts
Pith reviewed 2026-06-29 18:59 UTC · model grok-4.3
The pith
A contrastive framework learns dynamic graph node representations by enforcing temporal translation invariance across timespans.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
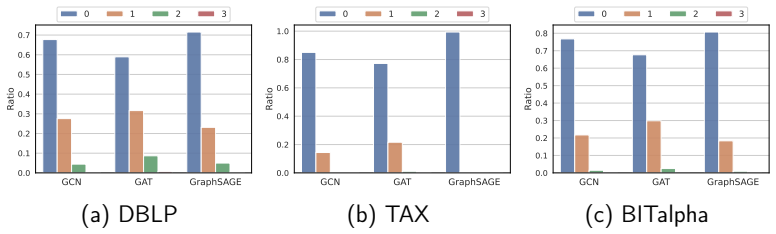
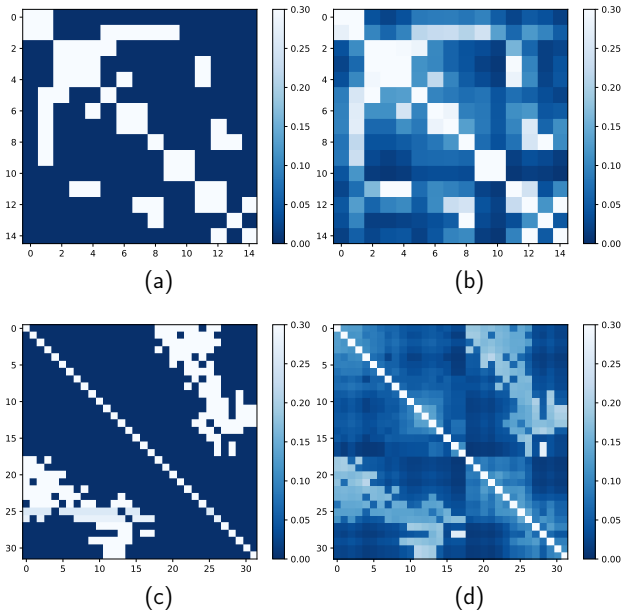
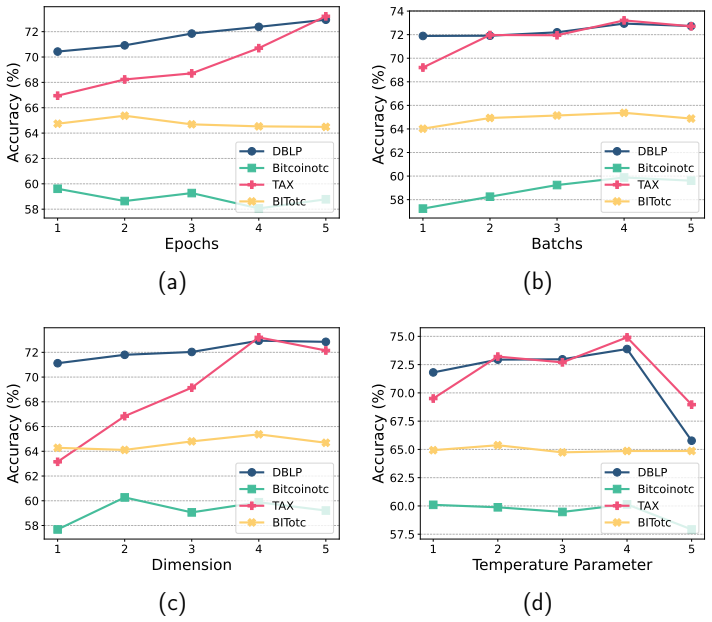
By treating different timespans of a dynamic graph as separate views and applying contrastive learning to enforce locally consistent temporal translation invariance, the CLDG framework produces node representations that perform well on downstream tasks. CLDG++ further incorporates graph diffusion and combines local-local, local-global, and global-global contrasts. Consistency between timespan views can be measured directly to identify anomalies without additional components.
What carries the argument
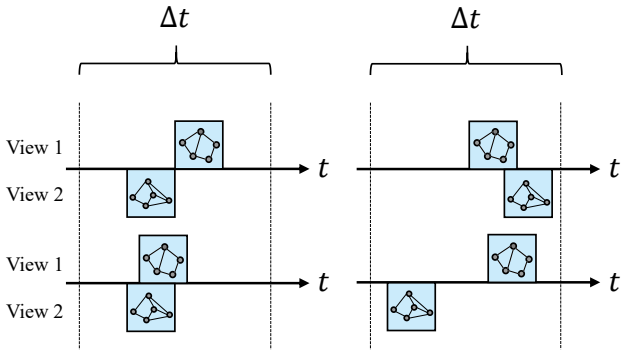
Temporal translation invariance, the inductive bias that identical nodes keep similar labels across timespans, which supplies positive pairs for contrastive learning between timespan-specific graph views.
If this is right
- CLDG representations improve accuracy on node classification in dynamic graphs.
- Consistency scores between timespans serve as indicators for anomaly detection on dynamic graphs.
- CLDG++ improves representation quality through diffusion-based global correlations and multi-scale contrasts.
- The approach reduces time and space complexity relative to methods that rely on explicit sequence models.
Where Pith is reading between the lines
- The same timespan-contrast mechanism could apply to other sequential data where local consistency over sliding windows is a reasonable prior.
- Varying the length and overlap of timespans might systematically affect how much invariance is enforced and how well anomalies are flagged.
- The anomaly detection component could be tested on streaming data such as transaction networks to check whether consistency drops reliably precede known events.
Load-bearing premise
Identical nodes tend to keep similar labels across different timespans.
What would settle it
A dynamic graph dataset in which the same nodes exhibit large, unpredictable label or feature changes between timespans, such that contrastive training on timespan pairs yields no gain over static baselines on classification or anomaly detection.
Figures



read the original abstract
The rich information underlying graphs has inspired further investigation of unsupervised graph representation. Existing studies mainly depend on node features and topological properties within static graphs to create self-supervised signals, neglecting the temporal components carried by real-world graph data, such as timestamps of edges. To overcome this limitation, this paper explores how to model temporal evolution on dynamic graphs elegantly. Specifically, we introduce a new inductive bias, namely temporal translation invariance, which illustrates the tendency of the identical node to keep similar labels across different timespans. Based on this assumption, we develop a dynamic graph representation framework CLDG that encourages the node to maintain locally consistent temporal translation invariance through contrastive learning on different timespans. Except for standard CLDG which only considers explicit topological links, our further proposed CLDG++ additionally employs graph diffusion to uncover global contextual correlations between nodes, and designs a multi-scale contrastive learning objective composed of local-local, local-global, and global-global contrasts to enhance representation capabilities. Interestingly, by measuring the consistency between different timespans to shape anomaly indicators, CLDG and CLDG++ are seamlessly integrated with the task of spotting anomalies on dynamic graphs, which has broad applications in many high-impact domains, such as finance, cybersecurity, and healthcare. Experiments demonstrate that CLDG and CLDG++ both exhibit desirable performance in downstream tasks including node classification and dynamic graph anomaly detection. Moreover, CLDG significantly reduces time and space complexity by implicitly exploiting temporal cues instead of complicated sequence models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a new inductive bias called temporal translation invariance (identical nodes tend to maintain similar labels across timespans) can be used to construct positive pairs for contrastive learning on dynamic graphs. This yields the CLDG framework (local contrasts on explicit topology) and CLDG++ (adding graph diffusion plus local-local, local-global, and global-global contrasts). The same consistency measure is repurposed for anomaly detection. Experiments are reported to show competitive node-classification and anomaly-detection performance with lower time/space complexity than sequence-based alternatives.
Significance. If the core assumption holds and the contrasts produce useful representations, the work supplies a lightweight alternative to recurrent or attention-based dynamic-graph models and a natural anomaly score. The multi-scale contrast design and seamless anomaly-detection integration are potentially useful contributions, but their value depends on independent validation of the translation-invariance premise.
major comments (3)
- [Abstract, §3] Abstract and §3 (inductive-bias definition): the temporal translation invariance assumption is introduced without citation to prior results, dataset statistics, or empirical validation, yet it directly supplies the positive-pair construction for all contrastive terms. If node embeddings or labels drift across timespans, the local-local, local-global, and global-global objectives become mis-specified; this is load-bearing for both representation quality and the downstream consistency-based anomaly score.
- [§4.2–4.3] §4.2–4.3 (CLDG++ objective): the multi-scale contrastive loss is defined by treating the same node at different timespans as positives solely because of the unvalidated invariance assumption. No ablation is described that isolates the contribution of each contrast type or tests performance when the assumption is relaxed (e.g., by using random or feature-based positives).
- [§5] §5 (experiments): performance claims on node classification and anomaly detection are presented, but the manuscript provides no quantitative check (e.g., label-consistency statistics across timespans on the evaluation graphs) that would confirm the assumption holds on the data used. Without such a check, it is unclear whether reported gains stem from the proposed bias or from other modeling choices.
minor comments (2)
- [§3–4] Notation for timespan views and diffusion operators should be introduced with explicit equations rather than prose descriptions to improve reproducibility.
- [Abstract, §5] The abstract states that CLDG “significantly reduces time and space complexity”; a direct complexity table or asymptotic comparison with the cited sequence-model baselines would strengthen this claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, agreeing that additional validation and ablations will strengthen the work. We will incorporate the suggested changes in the revised version.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (inductive-bias definition): the temporal translation invariance assumption is introduced without citation to prior results, dataset statistics, or empirical validation, yet it directly supplies the positive-pair construction for all contrastive terms. If node embeddings or labels drift across timespans, the local-local, local-global, and global-global objectives become mis-specified; this is load-bearing for both representation quality and the downstream consistency-based anomaly score.
Authors: We introduced temporal translation invariance as a novel inductive bias motivated by the observation that identical nodes often exhibit stable properties over short timespans in dynamic graphs. As a new assumption, it lacks prior citations by design. To address the concern, we will add motivation from real-world graph dynamics and, crucially, include dataset statistics on label/embedding consistency across timespans in the revised §3 and experiments section. This will provide empirical grounding for the positive-pair construction. revision: yes
-
Referee: [§4.2–4.3] §4.2–4.3 (CLDG++ objective): the multi-scale contrastive loss is defined by treating the same node at different timespans as positives solely because of the unvalidated invariance assumption. No ablation is described that isolates the contribution of each contrast type or tests performance when the assumption is relaxed (e.g., by using random or feature-based positives).
Authors: We agree that isolating the contribution of each contrast term (local-local, local-global, global-global) would clarify the framework's design. In the revision, we will add ablations in §4 that compare the full multi-scale objective against variants using only subsets of contrasts, as well as controls that replace timespan-based positives with random or feature-similarity positives. This will directly test sensitivity to the invariance assumption. revision: yes
-
Referee: [§5] §5 (experiments): performance claims on node classification and anomaly detection are presented, but the manuscript provides no quantitative check (e.g., label-consistency statistics across timespans on the evaluation graphs) that would confirm the assumption holds on the data used. Without such a check, it is unclear whether reported gains stem from the proposed bias or from other modeling choices.
Authors: We will revise §5 to include quantitative label-consistency statistics (e.g., average label agreement or embedding similarity for the same nodes across timespans) on all evaluation datasets. These checks will be presented alongside the main results to demonstrate that the assumption holds sufficiently on the data and to help attribute performance gains to the proposed bias. revision: yes
Circularity Check
No significant circularity; new inductive bias introduced as modeling assumption
full rationale
The paper states it introduces 'a new inductive bias, namely temporal translation invariance, which illustrates the tendency of the identical node to keep similar labels across different timespans' and develops CLDG 'based on this assumption' via contrastive learning on timespans. This is presented as a posited modeling choice to define positive pairs, not as a derived result or fitted parameter renamed as a prediction. No equations, self-citations, or uniqueness theorems are quoted that reduce any claimed output (representations or anomaly scores) to the input assumption by construction. The framework is self-contained against external benchmarks as a standard contrastive setup built on an explicit bias; no load-bearing step matches the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Temporal translation invariance: identical nodes keep similar labels across different timespans.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2102.09544
Combinatorial optimization and reasoning with graph neural net- works. arXiv preprint arXiv:2102.09544 . Chen, T., Kornblith, S., Norouzi, M., Hinton, G., 2020. A simple framework for contrastive learning of visual representations, in: ICML, PMLR. pp. 1597–1607. Chien, E., Chang, W.C., Hsieh, C.J., Yu, H.F., Zhang, J., Milenkovic, O., Dhillon, I.S., 2021....
-
[2]
Learning deep representations by mutual information estimation and maximization
Bootstrap your own latent-a new approach to self-supervised learn- ing. NeurIPS 33, 21271–21284. Han, B., Wei, Y., Wang, Q., Wan, S., 2023. Dual adaptive learning multi-task multi-view for graph network representation learning. Neural Networks 162, 297–308. Hassani, K., Khasahmadi, A.H., 2020. Contrastive multi-view representation learning on graphs, in: ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Graph attention networks. arXiv preprint arXiv:1710.10903 . Velickovic, P., Fedus, W., Hamilton, W.L., Liò, P., Bengio, Y., Hjelm, R.D.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
ICLR (Poster) 2, 4
Deep graph infomax. ICLR (Poster) 2, 4. Wang, D., Zhang, Z., Zhou, J., Cui, P., Fang, J., Jia, Q., Fang, Y., Qi, Y.,
-
[5]
Temporal-aware graph neural network for credit risk prediction, in: SDM, SIAM. pp. 702–710. Wang, H., Zhou, C., Chen, X., Wu, J., Pan, S., Wang, J., 2020. Graph stochastic neural networks for semi-supervised learning. NeurIPS 33, 19839–19848. Wu, S., Sun, F., Zhang, W., Xie, X., Cui, B., 2020. Graph neural networks in recommender systems: a survey. ACM Co...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.