Measure-to-measure Regression with Transformers
Pith reviewed 2026-06-29 14:44 UTC · model grok-4.3
The pith
Transformers can learn nonlinear maps between probability measures from finite observed input-output pairs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We formalize nonlinear M2M regression and introduce two easy-to-use, expressive, and scalable approaches to learn such operators: transformers as static M2M maps and transformers as dynamic M2M velocity fields. Our approach leverages the natural measure-dependent and mean-field structure of transformers to learn nonlinear M2M maps on the space of probability distributions.
What carries the argument
Transformers used as static maps from input measure to output measure, or as velocity fields that generate the map via a dynamical system, both exploiting the architecture's permutation-equivariant, mean-field behavior on sets of points.
If this is right
- The static and dynamic transformer formulations both generalize to measures not seen during training on synthetic and particle-system benchmarks.
- The same models produce accurate predictions of treatment-induced shifts in cell-population distributions on a colorectal-cancer organoid dataset.
- Because the methods operate directly on point-cloud representations of measures, they scale to the sample sizes typical of modern single-cell experiments without requiring explicit density estimation.
Where Pith is reading between the lines
- The dynamic velocity-field formulation may allow integration with existing continuous-time models of population dynamics outside the training distribution.
- If the mean-field transformer limit captures the necessary nonlinearities, similar architectures could be applied to other measure-valued processes such as empirical distributions in fluid mechanics or opinion dynamics.
- The finite-sample guarantee implicit in the organoid results suggests that collecting paired measure observations may be more data-efficient than collecting matched individual trajectories when the goal is population-level prediction.
Load-bearing premise
The measure-dependent and mean-field structure of transformers is sufficient to learn nonlinear maps on the space of probability distributions from finite observed input-output pairs of measures.
What would settle it
On the held-out patient-derived organoid dataset, if the transformer-predicted output measures show no improvement in matching the observed treatment-response distributions compared with a baseline that maps each input point cloud independently without using the global measure structure, the practical claim would be refuted.
Figures



read the original abstract
Many learning problems require predicting how populations evolve under an unknown transformation. A natural representation for such populations is a probability measure, with point clouds as a key example. In this work, we study the measure-to-measure (M2M) regression problem, in which one seeks to learn a map between probability measures from a finite collection of observed input-output pairs. In contrast to classical regression, where individual samples are transformed independently, M2M regression treats entire distributions as the data points. This perspective is vital in certain scientific applications, for example, cellular and molecular biology, where cells are known to evolve not as independent data points but as a collection. However, few existing approaches address the problem of M2M regression with sufficient expressivity and scalability. We present a formalization of nonlinear M2M regression and introduce two easy-to-use, expressive, and scalable approaches to learn such operators: transformers as static M2M maps and transformers as dynamic M2M velocity fields. Our approach leverages the natural measure-dependent and mean-field structure of transformers to learn nonlinear M2M maps on the space of probability distributions. We illustrate the effectiveness of our proposed method to generalize to unseen measures on synthetic experiments, interacting particle systems, and a large-scale patient-derived organoid dataset for predicting treatment response in colorectal cancer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript formalizes the nonlinear measure-to-measure (M2M) regression problem of learning maps between probability measures from finite observed input-output pairs. It introduces two transformer-based approaches—static M2M maps and dynamic M2M velocity fields—that exploit the measure-dependent and mean-field structure of transformers to learn nonlinear operators on the space of distributions. Effectiveness is illustrated via generalization to unseen measures on synthetic experiments, interacting particle systems, and a large-scale patient-derived organoid dataset for colorectal cancer treatment response prediction.
Significance. If the central claim holds—that the mean-field structure of transformers is sufficient to learn arbitrary nonlinear maps on probability measures from finite pairs—this would supply a scalable, expressive framework for population-level prediction tasks in biology and physics where classical pointwise regression is inadequate. The explicit use of transformers' built-in permutation invariance and aggregation properties for distributional data is a natural architectural choice that could reduce the need for custom measure-valued architectures.
major comments (2)
- [Abstract] Abstract: the claim that the proposed methods 'illustrate the effectiveness' of learning nonlinear M2M maps is unsupported by any quantitative results, error metrics, baseline comparisons, or ablation studies, preventing assessment of whether the data actually supports the sufficiency of the transformer mean-field structure for the stated task.
- [Abstract] Abstract: no equations, architectural specifications, or expressivity arguments are supplied to substantiate that the measure-dependent structure of transformers is in fact sufficient to learn arbitrary nonlinear maps on probability measures from finite input-output pairs, leaving the central modeling assumption untestable from the provided text.
minor comments (1)
- [Abstract] The abstract refers to 'synthetic experiments' and 'a large-scale patient-derived organoid dataset' without naming the specific datasets, number of measures, or dimensionality, which would aid reproducibility even at the high level.
Simulated Author's Rebuttal
We thank the referee for their comments. We respond to the major comments on the abstract below. The full manuscript contains the supporting details, but we will consider revisions to strengthen the abstract where possible.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the proposed methods 'illustrate the effectiveness' of learning nonlinear M2M maps is unsupported by any quantitative results, error metrics, baseline comparisons, or ablation studies, preventing assessment of whether the data actually supports the sufficiency of the transformer mean-field structure for the stated task.
Authors: The abstract provides a concise summary of the work. The manuscript includes quantitative experimental results on synthetic data, particle systems, and the organoid dataset, with comparisons and ablations detailed in the experimental section. We agree that the abstract could better hint at these results and will revise it to include a brief reference to the observed generalization performance and comparisons, subject to length constraints. revision: partial
-
Referee: [Abstract] Abstract: no equations, architectural specifications, or expressivity arguments are supplied to substantiate that the measure-dependent structure of transformers is in fact sufficient to learn arbitrary nonlinear maps on probability measures from finite input-output pairs, leaving the central modeling assumption untestable from the provided text.
Authors: We note that the abstract does not claim sufficiency for arbitrary nonlinear maps; it states that the approach leverages the structure to learn nonlinear M2M maps and illustrates effectiveness on specific tasks. The full paper provides the formalization, model architectures, and theoretical motivations in the methods section. The central claim is empirical effectiveness rather than universal sufficiency. We can revise the abstract to clarify the scope of the claims if needed, but the supporting details are in the main text. revision: no
Circularity Check
No significant circularity identified
full rationale
The provided abstract and context contain no equations, derivations, or load-bearing steps that reduce by construction to fitted parameters, self-definitions, or self-citation chains. The central claims rest on leveraging the pre-existing measure-dependent and mean-field properties of transformers (an external architectural fact) to address M2M regression, without any internal reduction of predictions to inputs or renaming of known results as novel derivations. This is the most common honest finding for papers that apply established models without introducing self-referential formalisms.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Stochastic Interpolants: A Unifying Framework for Flows and Diffusions
Michael S Albergo, Nicholas M Boffi, and Eric Vanden-Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions.arXiv preprint arXiv:2303.08797,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Meta optimal transport.arXiv preprint arXiv:2206.05262,
Brandon Amos, Samuel Cohen, Giulia Luise, and Ievgen Redko. Meta optimal transport.arXiv preprint arXiv:2206.05262,
-
[3]
Nicholas M Boffi, Michael S Albergo, and Eric Vanden-Eijnden. Flow map matching with stochastic interpolants: A mathematical framework for consistency models.arXiv preprint arXiv:2406.07507,
-
[4]
A Unified Perspective on the Dynamics of Deep Transformers
Valérie Castin, Pierre Ablin, José Antonio Carrillo, and Gabriel Peyré. A unified perspective on the dynamics of deep transformers.arXiv preprint arXiv:2501.18322,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Quantitative Clustering in Mean-Field Transformer Models
Shi Chen, Zhengjiang Lin, Yury Polyanskiy, and Philippe Rigollet. Quantitative clustering in mean-field transformer models, 2025a. arXiv:2504.14697. Shi Chen, Zhengjiang Lin, Yury Polyanskiy, and Philippe Rigollet. Critical attention scaling in long-context transformers. InInternational Conference on Learning Representations,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Generative Modeling via Drifting
Mingyang Deng, He Li, Tianhong Li, Yilun Du, and Kaiming He. Generative modeling via drifting. arXiv preprint arXiv:2602.04770,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Minibatch optimal transport distances; analysis and applications.arXiv preprint arXiv:2101.01792,
Kilian Fatras, Younes Zine, Szymon Majewski, Rémi Flamary, Rémi Gribonval, and Nicolas Courty. Minibatch optimal transport distances; analysis and applications.arXiv preprint arXiv:2101.01792,
-
[8]
Generative distribution embeddings.arXiv preprint arXiv:2505.18150,
Nic Fishman, Gokul Gowri, Peng Yin, Jonathan Gootenberg, and Omar Abudayyeh. Generative distribution embeddings.arXiv preprint arXiv:2505.18150,
-
[9]
Distribution-conditioned transport.arXiv preprint arXiv:2603.04736,
Nic Fishman, Gokul Gowri, Paolo LB Fischer, Marinka Zitnik, Omar Abudayyeh, and Jonathan Gootenberg. Distribution-conditioned transport.arXiv preprint arXiv:2603.04736,
-
[10]
The emergence of clusters in self-attention dynamics
Borjan Geshkovski, Cyril Letrouit, Yury Polyanskiy, and Philippe Rigollet. The emergence of clusters in self-attention dynamics. InNeural Information Processing Systems, 2024a. Borjan Geshkovski, Philippe Rigollet, and Domènec Ruiz-Balet. Measure-to-measure interpolation using transformers.arXiv preprint arXiv:2411.04551, 2024b. Borjan Geshkovski, Cyril L...
- [11]
-
[12]
A Call to Lagrangian Action: Learning Population Mechanics from Temporal Snapshots
Vincent Guan, Lazar Atanackovic, and Kirill Neklyudov. A call to lagrangian action: Learning population mechanics from temporal snapshots.arXiv preprint arXiv:2605.08550,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
12 Bowen Jing, Hannes Stärk, Tommi Jaakkola, and Bonnie Berger
arXiv preprint arXiv:2302.13752. 12 Bowen Jing, Hannes Stärk, Tommi Jaakkola, and Bonnie Berger. Generative modeling of molecular dynamics trajectories.Neural Information Processing Systems,
-
[14]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Continuous transformations of probability measures and their transport representations
Hugo Lavenant and Giuseppe Savaré. Continuous transformations of probability measures and their transport representations.arXiv preprint arXiv:2604.16653,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
A class of markov processes associated with nonlinear parabolic equations
Henry P McKean Jr. A class of markov processes associated with nonlinear parabolic equations. Proceedings of the National Academy of Sciences, 56(6):1907–1911,
1907
-
[19]
Wfr-fm: Simulation-free dynamic unbalanced optimal transport.arXiv preprint arXiv:2601.06810,
Qiangwei Peng, Zihan Wang, Junda Ying, Yuhao Sun, Qing Nie, Lei Zhang, Tiejun Li, and Peijie Zhou. Wfr-fm: Simulation-free dynamic unbalanced optimal transport.arXiv preprint arXiv:2601.06810,
-
[20]
arXiv preprint arXiv:2402.14753. Katarina Petrovi ´c, Lazar Atanackovic, Viggo Moro, Kacper Kapu ´sniak, Ismail Ilkan Ceylan, Michael M. Bronstein, Joey Bose, and Alexander Tong. Curly flow matching for learning non- gradient field dynamics. InNeural Information Processing Systems,
-
[21]
Meta Flow Maps enable scalable reward alignment
13 Peter Potaptchik, Adhi Saravanan, Abbas Mammadov, Alvaro Prat, Michael S Albergo, and Yee Whye Teh. Meta flow maps enable scalable reward alignment.arXiv preprint arXiv:2601.14430,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
SplineFlow: Flow Matching for Dynamical Systems with B-Spline Interpolants
Santanu Subhash Rathod, Pietro Liò, and Xiao Zhang. Splineflow: Flow matching for dynamical systems with b-spline interpolants.arXiv preprint arXiv:2601.23072,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Kristiyan Sakalyan, Alessandro Palma, Filippo Guerranti, Fabian J Theis, and Stephan Günnemann. Modeling microenvironment trajectories on spatial transcriptomics with nicheflow.arXiv preprint arXiv:2511.00977,
-
[24]
Michael E Sander, Pierre Ablin, Mathieu Blondel, and Gabriel Peyré
arXiv preprint arXiv:2410.03011. Michael E Sander, Pierre Ablin, Mathieu Blondel, and Gabriel Peyré. Sinkformers: Transformers with doubly stochastic attention. InInternational Conference on Artificial Intelligence and Statistics. PMLR,
-
[25]
Improving and generalizing flow-based generative models with minibatch optimal transport
Alexander Tong, Kilian Fatras, Nikolay Malkin, Guillaume Huguet, Yanlei Zhang, Jarrid Rector- Brooks, Guy Wolf, and Yoshua Bengio. Improving and generalizing flow-based generative models with minibatch optimal transport.arXiv preprint arXiv:2302.00482,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
arXiv preprint arXiv:2402.00522. Zhiting Wei, Yiheng Wang, Yicheng Gao, Shuguang Wang, Ping Li, Duanmiao Si, Yuli Gao, Siqi Wu, Danlu Li, Kejing Dong, et al. Benchmarking algorithms for generalizable single-cell perturbation response prediction.Nature Methods,
-
[27]
Tahoe-100m: A giga-scale single-cell perturbation atlas for context-dependent gene function and cellular modeling.BioRxiv, pages 2025–02,
Jesse Zhang, Airol A Ubas, Richard de Borja, Valentine Svensson, Nicole Thomas, Neha Thakar, Ian Lai, Aidan Winters, Umair Khan, Matthew G Jones, et al. Tahoe-100m: A giga-scale single-cell perturbation atlas for context-dependent gene function and cellular modeling.BioRxiv, pages 2025–02,
2025
-
[28]
Learning gaussian mix- ture models via transformer measure flows
Aleksandr Zimin, Anastasiia Kutakh, Yury Polyanskiy, and Philippe Rigollet. Learning gaussian mix- ture models via transformer measure flows. InICML 2025 Workshop on Methods and Opportunities at Small Scale,
2025
-
[29]
15 A Additional Experimental Details A.1 Multi-measure Objects In this section we outline additional experimental setup details for the Multi-measure Objects experiments. The kernel interaction process in this experiment is defined by the following dynamics equation, xt+∆t =x t +η(x t − X j Aijxj)∆t+σ √ ∆tϵ where Aij = exp(−∥x i −x j∥2/2h2)/P k exp(−∥xi −...
2024
-
[30]
We choose to treat these pairs as independent rather than employ complex solutions used for multi-marginal flow matching Rohbeck et al
We update on each of these 16 pairs in parallel. We choose to treat these pairs as independent rather than employ complex solutions used for multi-marginal flow matching Rohbeck et al. [2025]. This means that the models trained in this setup, sample two adjacent time-points for updating. Since the model is conditioned on time, it learns a single map then ...
2025
-
[31]
Statistics reported for each split
Cut-off Threshold: 0 .1 (c) PDO-75 Figure 4: Empirical distribution of ED across all measures. Statistics reported for each split. 17 A.4 Additional Information on Baselines In this section we offer information about our baseline methods. All models incorporate positional encoding for samples/particles. For time-dependent models, we use sinusoidal embeddin...
2025
-
[32]
maximum mean discrepancy (MMD)
demonstrated that OT-CFM yields competitive performance relative to CellOT [Bunne et al., 2023], an input convex neural network (ICNN)-based approach, on the colorectal cancer treatment-response dataset, which we consider in Section 5.3. Similar to [Bunne et al., 2023], OT-CFM provides an optimal transport-based approximation for the M2M operator, and as ...
2023
-
[33]
Computation of Losses.To compute distributional losses efficiently, we employ the Geometric Loss Functions package [Feydy et al., 2019]
for a definition of this metric. Computation of Losses.To compute distributional losses efficiently, we employ the Geometric Loss Functions package [Feydy et al., 2019]. This package provides auto-differentiable versions of these distances enabling efficient and scalable training of our static approaches. Specifically for the p-Wasserstein loss, we approx...
2019
-
[34]
Time is encoded and passed into the model with a sinusoidal timestep embedding. Together, this is then fed into a stack of AdaLNBlocks [Perez et al., 2018] blocks, each block uses adaptive layer normalization modulated by time embedding (and any additional covariates/conditions that are used, e.g. treatments in the biological expeirmets), and provides gat...
2018
-
[35]
20 Table 4: Hyperparameters for the M2M-TFM model on multi-measure Object experiments. Hyperparameter Value Input dimension 2 Hidden dimension 64 Number of layers 5 Number of attention heads 8 Learning rate5×10 −5 Dropout 0.05 Time embedding dimension 128 Time-varying dynamics True Time steps at inference 100 Measure Batch Size 16 Particle Batch Size 512 ...
2048
-
[36]
The hyperparameters for Meta-FM are shown in table Table
We use the same Meta-FM hyperparameters as [Atanackovic et al., 2025], but instead of a graph convolution network we use a transformer population embedding which uses 3 layers, with a width of 64, and 8 heads. The hyperparameters for Meta-FM are shown in table Table
2025
-
[37]
Table 10: Hyperparameters for the CFM model in the multi-measure object experiments. Hyperparameter Value Input dimension 2 Hidden dimension 512 Number of layers 4 Skip connections False OT during Training True Time steps at inference 100 Learning rate1×10 −4 Measure Batch Size 16 Particle Batch Size 512 Epochs (passes over training data) 1000 Table 11: H...
2048
-
[38]
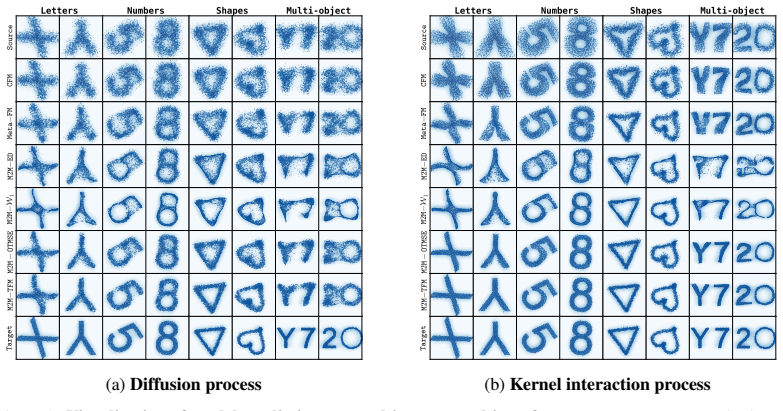
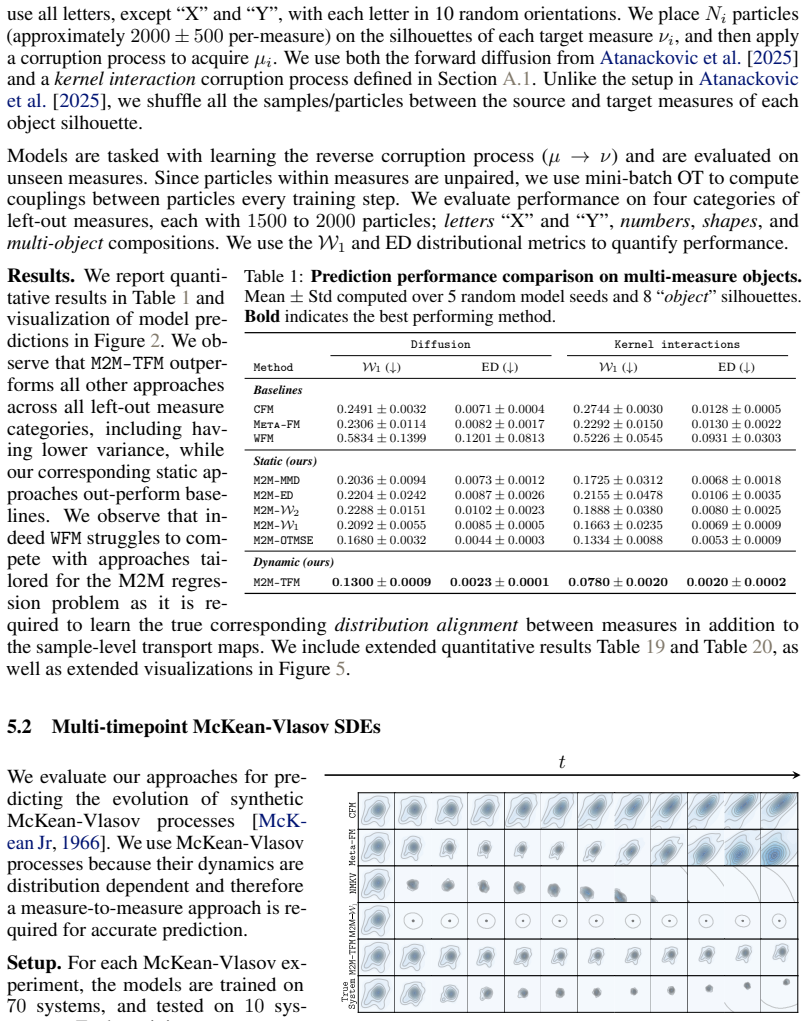
In Table 24 we provide results for our ablation over the number of inference steps, i.e number of function evaluations used in inference forM2M-TFMon the50dimensional systems. 24 Source Letters Numbers Shapes Multi-object CFM Meta−FM WFM M2M−ED M2M−MMD M2M−W1 M2M−W2 M2M− OTMSE M2M−TFM Target (a)Diffusion process Source Letters Numbers Shapes Multi-object ...
2027
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.