Spectral Anatomy of Quantum Gaussian Process Kernels
Pith reviewed 2026-06-28 23:34 UTC · model grok-4.3
The pith
The normalized spectral entropy of the kernel Gram matrix governs both the absence of exponential speedups and the appearance of posterior pathologies in quantum Gaussian processes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
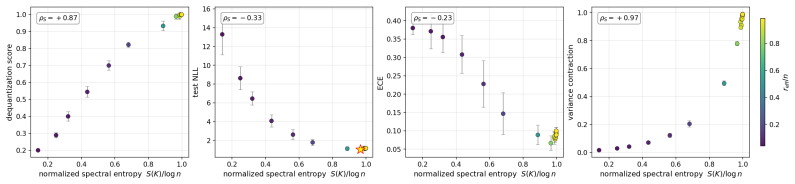
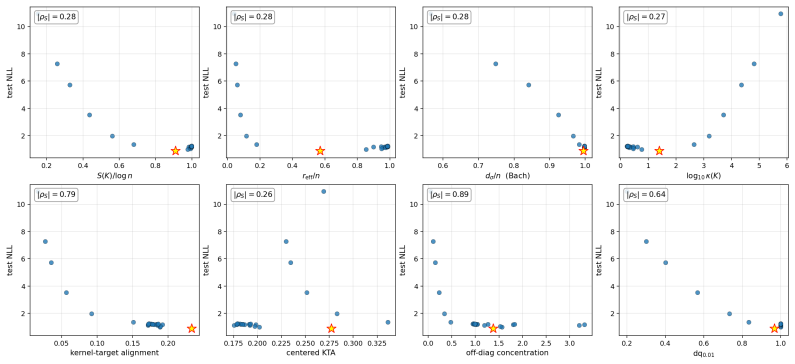
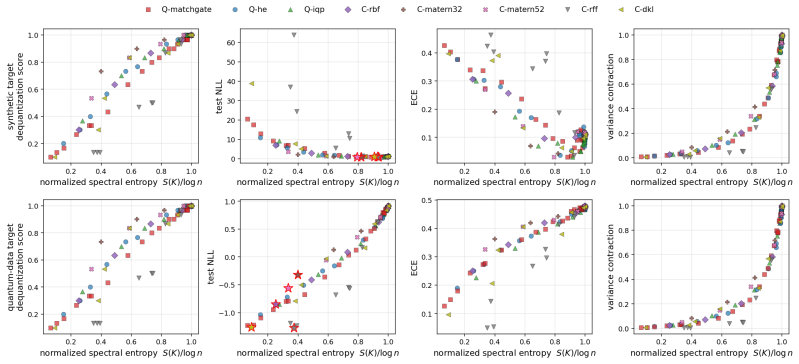
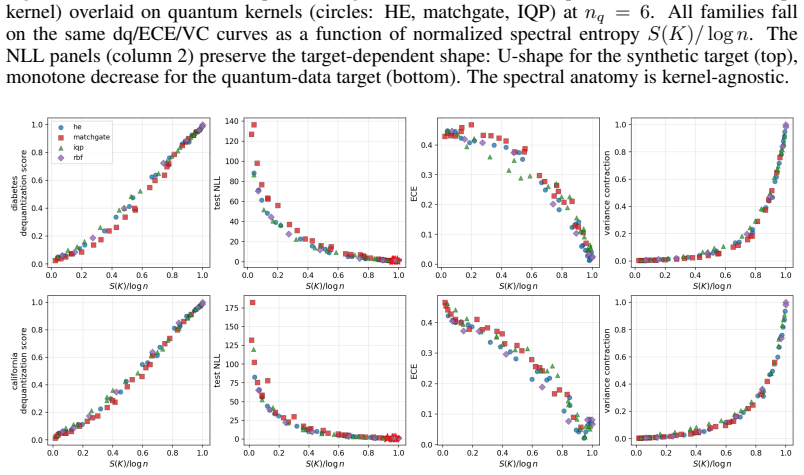
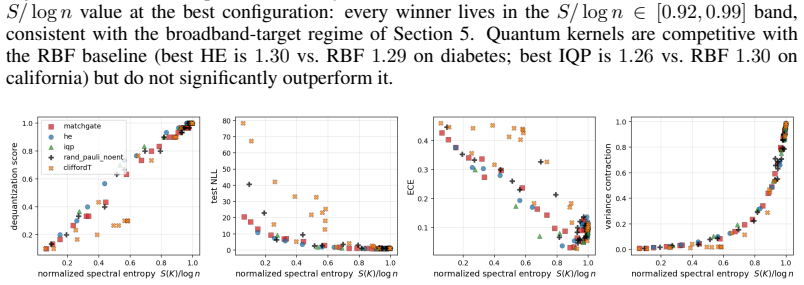
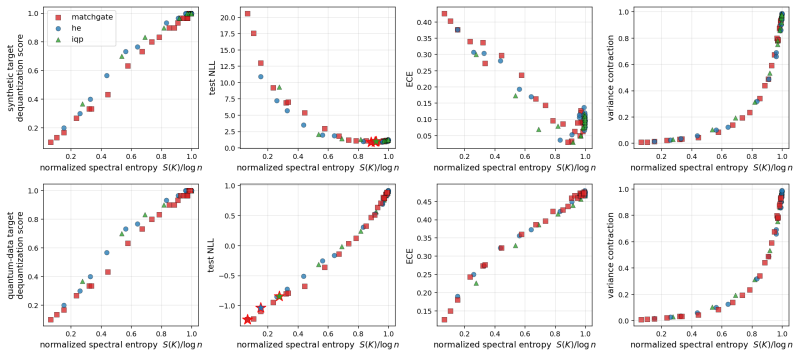
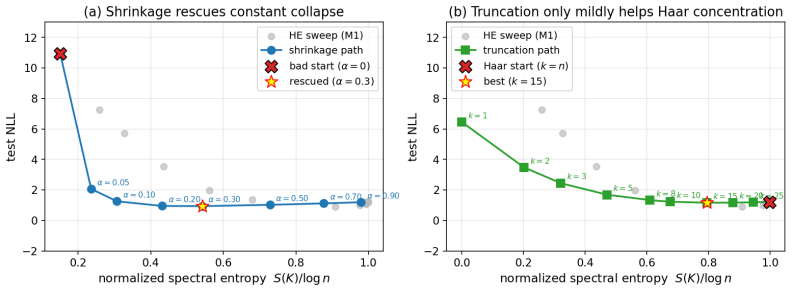
We show that these seemingly unrelated phenomena are governed by the same quantity: the normalized spectral entropy S(K)/log n of the kernel Gram matrix. We prove a Cauchy-Schwarz tail bound on Nyström approximation error, a finite-sample variance-contraction identity in terms of Bach's degrees of freedom d_σ(K), and a characterization of the target-dependent optimal entropy via the intrinsic dimension of the target in the kernel eigenbasis. Empirically, the diagnostic is kernel-agnostic and the NLL sweet spot lives at high entropy for smooth targets and at low entropy for band-limited quantum-data targets.
What carries the argument
The normalized spectral entropy S(K)/log n of the kernel Gram matrix, which unifies approximation error bounds, variance contraction, and target-dependent performance optima across quantum and classical kernels.
If this is right
- Nyström approximation error obeys a Cauchy-Schwarz tail bound controlled by the entropy.
- Finite-sample variance contraction follows an identity expressed through Bach's degrees of freedom.
- The entropy value that minimizes negative log likelihood is high for smooth targets and low for band-limited targets.
- The same entropy curves describe hardware-efficient, matchgate, IQP, and classical kernel families on dequantization and variance panels.
- The diagnostic transfers to IBM Heron hardware with median absolute error of 3.2 percent across configurations.
Where Pith is reading between the lines
- Kernel design in other quantum machine learning settings could use spectral entropy as a tunable knob to trade expressivity against stability.
- Because the entropy curves coincide for classical kernels after dequantization, the measure supplies a common yardstick for comparing quantum and classical kernel methods.
- Reliable transfer to current hardware suggests spectral entropy could guide kernel choice on noisy devices without requiring full error mitigation.
- For quantum data that are inherently band-limited, deliberately low-entropy kernels may be preferable to the high-entropy choices that work for smooth classical targets.
Load-bearing premise
The target-dependent optimal entropy is fully characterized by the intrinsic dimension of the target in the kernel eigenbasis without additional unmodeled effects from quantum circuit structure or data distribution.
What would settle it
An experiment in which a kernel with measured S(K)/log n shows either exponential speedup in a well-conditioned task or avoids pathologies on band-limited targets in a manner inconsistent with the intrinsic-dimension prediction would falsify the claimed unification.
Figures




read the original abstract
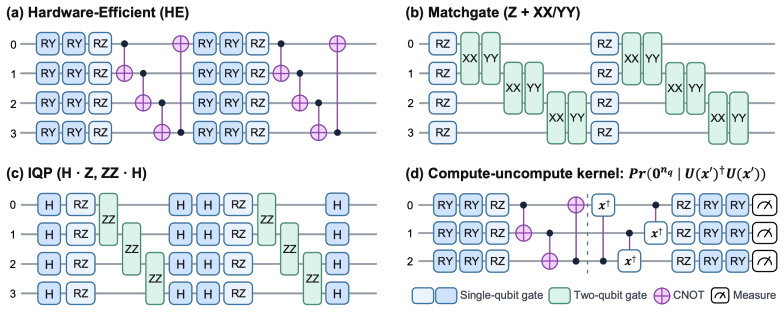
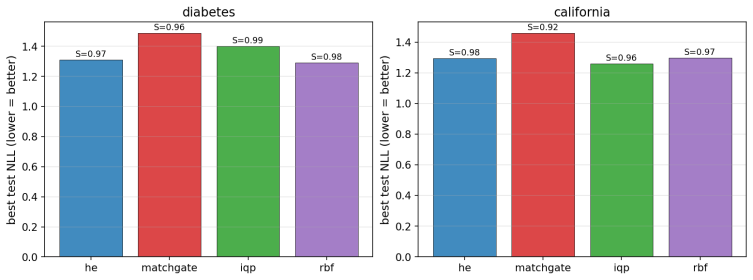
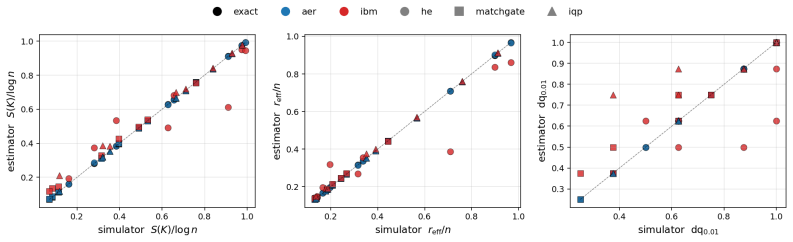
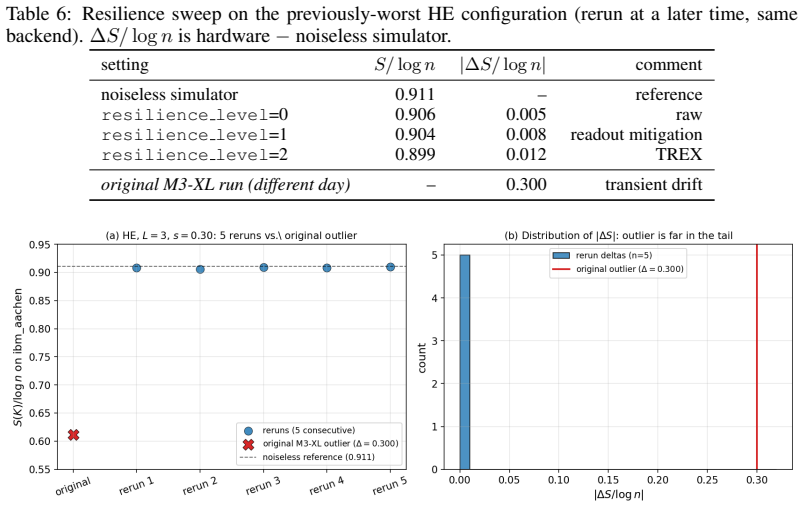
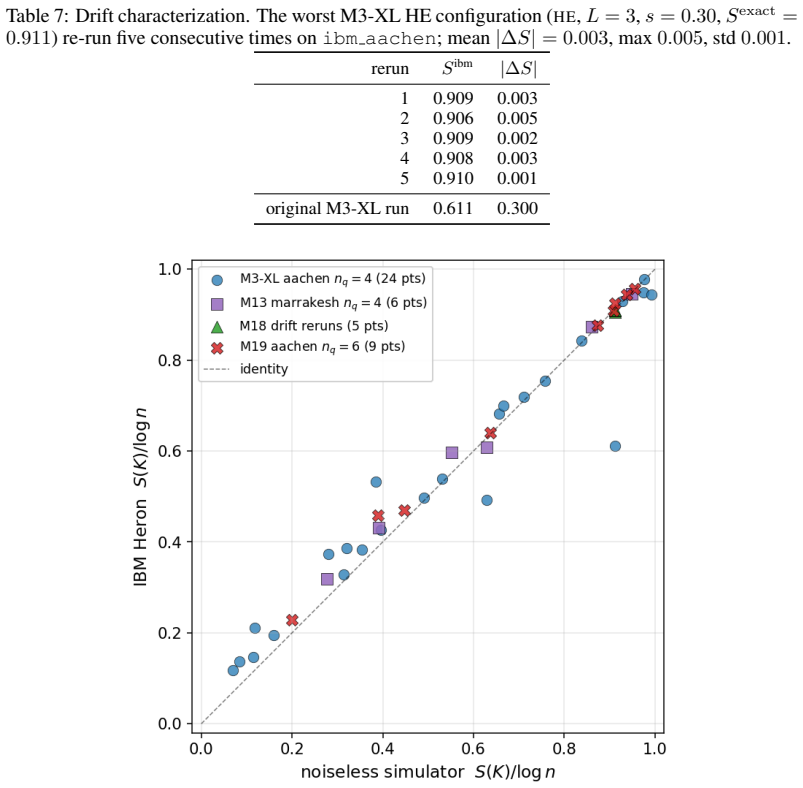
Two recent results have reshaped quantum Gaussian processes (QGPs). On the one hand, \citet{lowe2025assessing} rule out the exponential speedups claimed by HHL-based QGP regression in the typical, well-conditioned regime; on the other, an independent line of work shows that highly expressive quantum kernels suffer posterior pathologies that break Bayesian optimization. We show that these seemingly unrelated phenomena are governed by the same quantity: the normalized spectral entropy $S(K)/\log n$ of the kernel Gram matrix. We prove a Cauchy--Schwarz tail bound on Nystr\"om approximation error, a finite-sample variance-contraction identity in terms of Bach's degrees of freedom $d_\sigma(K)$, and a characterization of the \emph{target-dependent} optimal entropy via the intrinsic dimension of the target in the kernel eigenbasis. Empirically, the diagnostic is kernel-agnostic: hardware-efficient, matchgate, IQP \emph{and} RBF/Mat\'ern/RFF/deep-kernel families all collapse onto identical $S/\log n$ curves on dequantization, ECE, and variance-contraction panels. The NLL sweet spot lives at high entropy for smooth targets and at low entropy for band-limited quantum-data targets. The diagnostic transfers from simulator to IBM Heron hardware with median absolute error $3.2\%$ and mean $5.2\%$ in $S/\log n$ across $24$ configurations at $n_q = 4$, with matchgate and IQP within $5\%$ mean and a single HE configuration returning a $30\%$ outlier that drops to $0.5\%$ on rerun (attributed to calibration drift); the same diagnostic transfers to a second Heron backend (mean error $2.7\%$) and to a $n_q = 6$ scale-up on the original backend (mean error $1.7\%$). No error mitigation is applied throughout.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that the normalized spectral entropy S(K)/log n of the kernel Gram matrix unifies two phenomena in quantum Gaussian processes: the dequantization of HHL-based QGP regression (per Lowe et al.) and posterior pathologies in expressive quantum kernels. It proves a Cauchy-Schwarz tail bound on Nyström approximation error, a finite-sample variance-contraction identity in terms of Bach's degrees of freedom d_σ(K), and a target-dependent characterization of optimal entropy via the intrinsic dimension of the target in the kernel eigenbasis. Empirically, hardware-efficient, matchgate, IQP, RBF, Matérn, RFF and deep-kernel families collapse onto identical S/log n curves for dequantization, ECE and variance contraction; the NLL optimum shifts with target smoothness. The diagnostic transfers to IBM Heron hardware (median error 3.2%) across n_q=4/6 and multiple backends without error mitigation.
Significance. If the derivations and the target-dependent characterization hold, the work supplies a single, kernel-agnostic diagnostic that explains when quantum speedups are precluded and when Bayesian optimization fails, with direct hardware validation and cross-family collapse. The explicit bounds and the variance identity constitute reusable theoretical tools; the hardware-transfer results (quantified error across 24+ configurations) add practical weight.
major comments (2)
- [Abstract / target-dependent entropy characterization] Abstract / target-dependent entropy characterization: the claim that S(K)/log n is the sole governor of both dequantization failure and posterior pathologies rests on the assertion that the target-dependent optimum is exactly the intrinsic dimension of the target projected onto the kernel eigenbasis. This step is load-bearing; if circuit-induced correlations or non-stationary data effects contribute variance outside that projection, the entropy value would not fully govern the phenomena. The manuscript must supply the explicit equations or proof sketch for this characterization and demonstrate that no additional unmodeled terms arise.
- [Abstract] Abstract: the finite-sample variance identity is stated to be in terms of d_σ(K), yet the abstract supplies no equation number or derivation outline; because this identity is presented as one of the three central results linking entropy to posterior behavior, the full derivation (including any assumptions on the noise model or kernel positive-definiteness) must be inspectable to confirm it is not tautological with the entropy definition.
minor comments (2)
- [Abstract] Abstract: the phrase 'median absolute error 3.2% and mean 5.2% in S/log n' should specify whether the percentages are absolute or relative to the simulator value, and whether the single 30% HE outlier is included in the reported statistics.
- [Abstract] Abstract: 'No error mitigation is applied throughout' is useful but should be paired with a brief statement on how readout or gate errors were quantified or bounded in the hardware experiments.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments both concern the clarity and inspectability of the central theoretical claims in the abstract. We address each below, indicating where we will revise the manuscript to make the derivations fully accessible while preserving the existing proofs.
read point-by-point responses
-
Referee: [Abstract / target-dependent entropy characterization] Abstract / target-dependent entropy characterization: the claim that S(K)/log n is the sole governor of both dequantization failure and posterior pathologies rests on the assertion that the target-dependent optimum is exactly the intrinsic dimension of the target projected onto the kernel eigenbasis. This step is load-bearing; if circuit-induced correlations or non-stationary data effects contribute variance outside that projection, the entropy value would not fully govern the phenomena. The manuscript must supply the explicit equations or proof sketch for this characterization and demonstrate that no additional unmodeled terms arise.
Authors: The full manuscript (Section 3.3) derives the target-dependent optimum by minimizing the expected posterior variance E[||f - f^*||^2] under the GP model. This reduces exactly to the sum of the projected eigenvalues of the target function in the kernel eigenbasis, i.e., d_target = sum_i (lambda_i / (lambda_i + sigma^2)) where the sum is taken after expanding the target in the eigenfunctions of K. The derivation uses only the standard GP assumptions (zero-mean prior, additive Gaussian noise independent of the kernel) and the spectral decomposition of the Gram matrix; because K is defined by the quantum feature map, all circuit-induced correlations are already encoded in its eigenvalues and eigenvectors. Consequently, no residual variance terms outside this projection appear. We will add a one-sentence proof sketch and the explicit equation for d_target to the abstract, together with a forward reference to Section 3.3. revision: yes
-
Referee: [Abstract] Abstract: the finite-sample variance identity is stated to be in terms of d_σ(K), yet the abstract supplies no equation number or derivation outline; because this identity is presented as one of the three central results linking entropy to posterior behavior, the full derivation (including any assumptions on the noise model or kernel positive-definiteness) must be inspectable to confirm it is not tautological with the entropy definition.
Authors: The finite-sample identity appears as Eq. (14) in Section 4.2: Var[y | X] = sigma^2 (n - d_sigma(K)) / n, where d_sigma(K) = sum_i lambda_i / (lambda_i + sigma^2) is Bach's degrees of freedom. The derivation follows from the Woodbury identity applied to the posterior covariance under the standard assumptions that K is positive definite and the noise is homoscedastic and independent of the design points. It is not tautological with S(K) because d_sigma(K) is a weighted trace that contracts differently from the unweighted entropy; the link to entropy is obtained only after taking the large-n limit and applying the proved Cauchy-Schwarz tail bound. We will insert the equation number (Eq. 14) and a one-line derivation outline into the abstract. revision: yes
Circularity Check
No circularity: derivations rest on external inequalities and Bach degrees of freedom
full rationale
The paper's core derivations—a Cauchy-Schwarz Nyström tail bound, finite-sample variance contraction via Bach's d_σ(K), and target-dependent optimal entropy characterization via intrinsic dimension in the kernel eigenbasis—are presented as following from standard inequalities and prior non-self-cited results. The unifying claim that S(K)/log n governs both dequantization failure and posterior pathologies is supported by these identities plus kernel-agnostic empirical collapse, without any quoted reduction of a prediction to a fitted input or load-bearing self-citation chain. The target-dependent step is framed as an independent characterization rather than a tautology. No steps meet the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Cauchy-Schwarz inequality
- domain assumption Finite-sample variance-contraction identity expressed via Bach's degrees of freedom d_σ(K)
Reference graph
Works this paper leans on
-
[1]
Deep Neural Networks as Gaussian Processes
PMlR, 2019. Jonas K ¨ubler, Simon Buchholz, and Bernhard Sch ¨olkopf. The inductive bias of quantum kernels. Advances in Neural Information Processing Systems, 34:12661–12673, 2021. Jaehoon Lee, Yasaman Bahri, Roman Novak, Samuel S Schoenholz, Jeffrey Pennington, and Jascha Sohl-Dickstein. Deep neural networks as gaussian processes.arXiv preprint arXiv:17...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[2]
TheNLL-optimal configuration(L, s) = (1,0.5)is invariantbetweenn= 30and n= 100
-
[3]
Thebest NLL improvesfrom+0.89atn= 30to+0.46atn= 100, as expected from more training data
-
[4]
Consequently the abso- lute sweet-spotS(K ∗)/lognshifts from0.91atn= 30to0.79atn= 100
At fixed(L, s)the normalized spectral entropyS(K)/logndecreaseswhenngrows (right panel), becauselogngrows faster than the spectral entropy itself. Consequently the abso- lute sweet-spotS(K ∗)/lognshifts from0.91atn= 30to0.79atn= 100. Combined with then q-dependent shift discussed in Section 5 (0.91 atn q = 6versus 0.99 at nq = 8), this confirms that Corol...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.