Eigenvectors of Experts are Training-free Non-collapsing Routers
Pith reviewed 2026-06-28 23:24 UTC · model grok-4.3
The pith
Eigenvectors of expert weight matrices encode semantic information that can be used as a training-free router to prevent collapse in SMoE models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
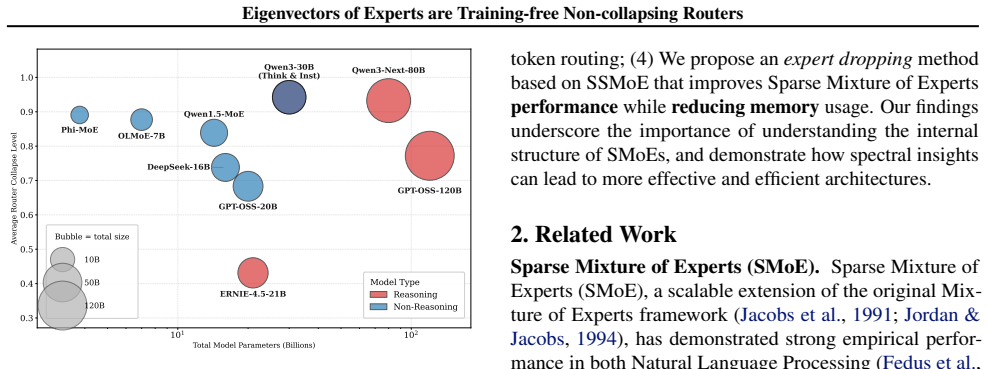
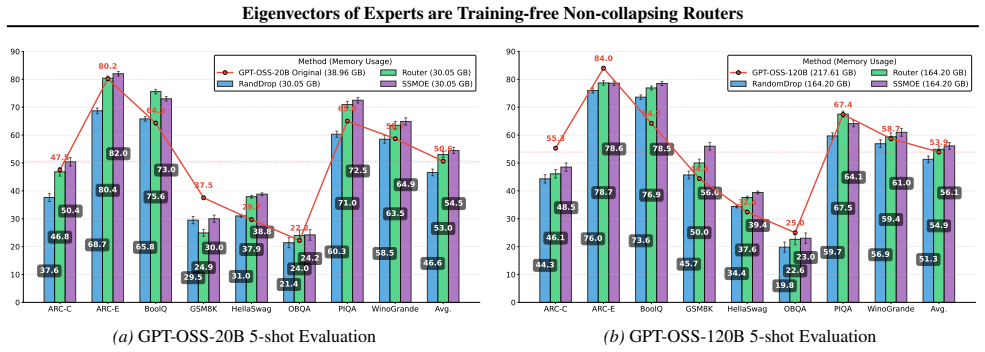
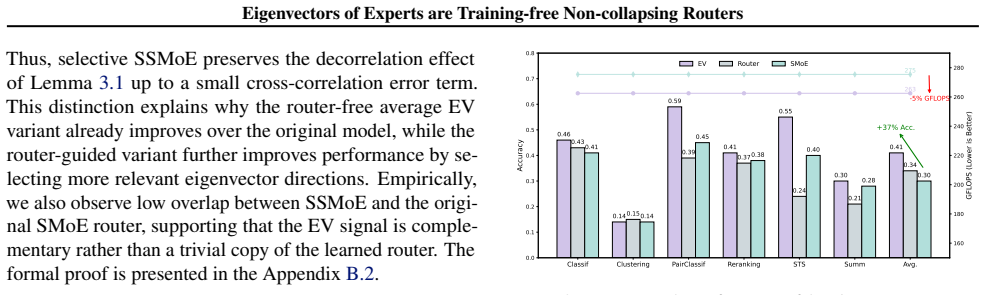
In advanced SMoE models the eigenvectors of expert weight matrices encode rich semantic information; singular value decomposition of those matrices therefore supplies routing scores that avoid expert collapse without any training or fine-tuning, yielding a framework called SSMoE whose performance holds across language and vision tasks under both clean and corrupt conditions.
What carries the argument
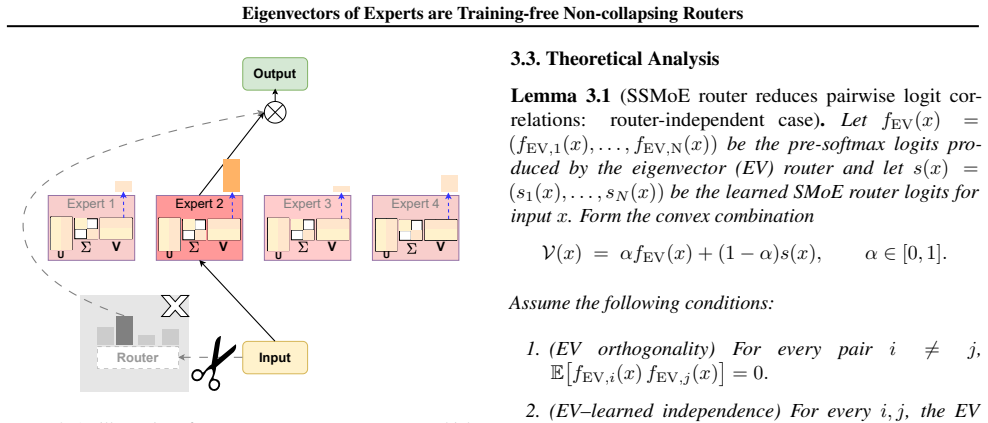
Singular Value Decomposition applied to expert weight matrices, whose eigenvectors supply the routing decisions.
If this is right
- SSMoE can be applied directly to existing pretrained SMoE models without further optimization.
- Routing derived from spectral properties reduces collapse on both language and vision tasks.
- The same eigenvectors remain effective under clean and corrupted input data.
- No additional training data or compute is required to obtain the router.
Where Pith is reading between the lines
- The finding suggests that pretrained expert matrices already embed task-relevant structure that conventional learned routers must rediscover.
- Similar spectral analysis could be tested on other modular architectures such as mixture-of-experts variants in vision transformers.
- If eigenvectors prove stable, they might serve as a diagnostic tool to inspect what semantic distinctions each expert has learned.
Load-bearing premise
The semantic encoding observed in the eigenvectors of expert weight matrices is stable enough to produce reliable routing decisions across models, tasks, and data distributions without retraining.
What would settle it
Run SSMoE on a new pretrained SMoE model on a standard benchmark and measure whether expert usage still collapses to a small subset of experts.
Figures
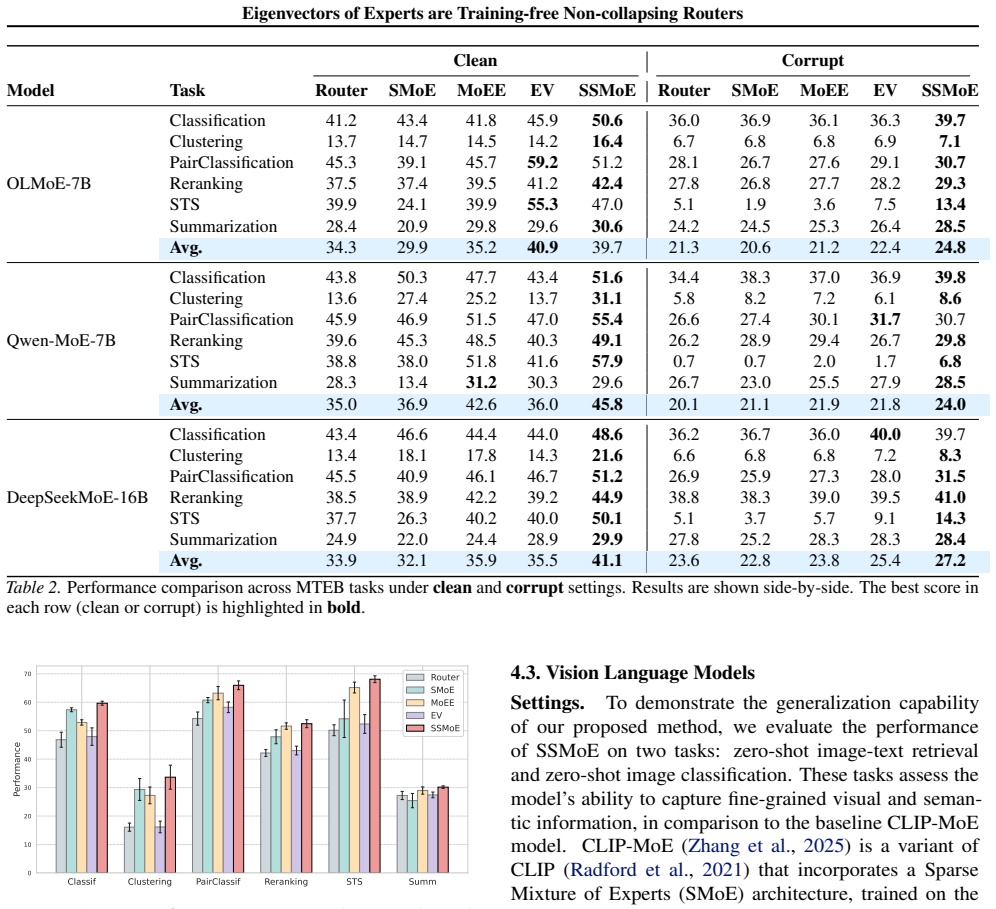
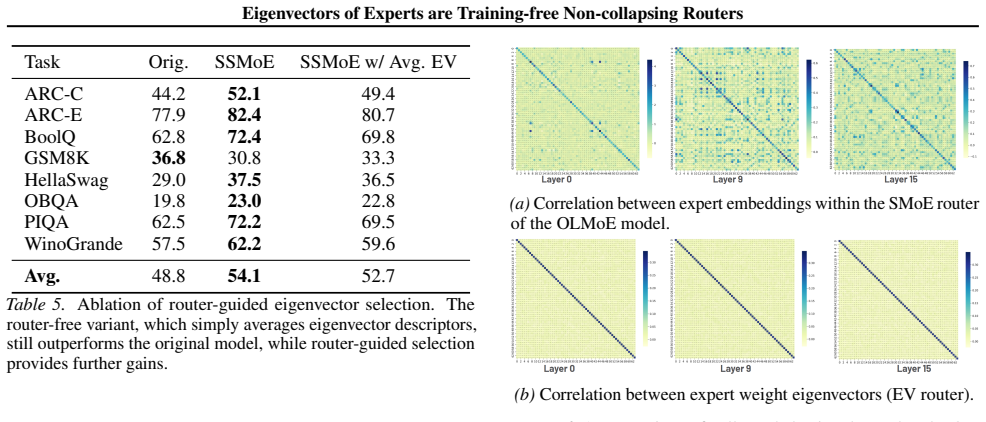
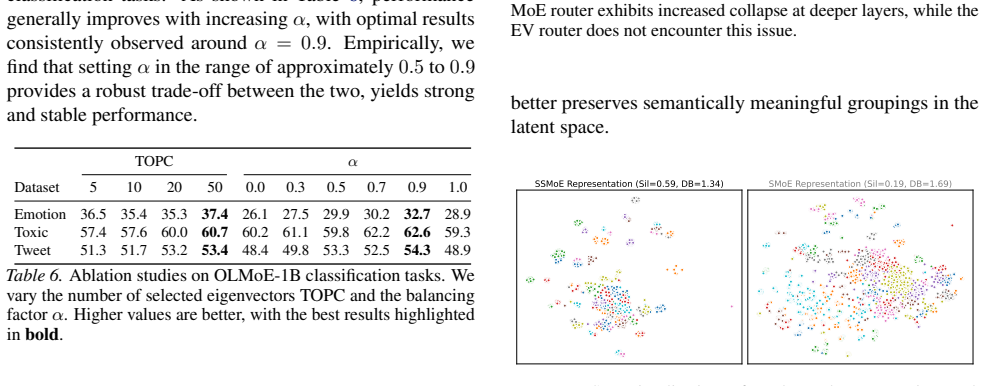
read the original abstract
Sparse Mixture of Experts (SMoE) architectures improve the training efficiency of Large Language Models (LLMs) by routing input tokens to a selected subset of specialized experts. Despite their remarkable success, both training and inference in SMoE models suffer from the expert collapse issue (Chi et al., 2022), which degrades model performance. Prior studies primarily focus on improving the router; however, such methods rely on training from scratch or fine-tuning, which requires high computational and data-processing costs. Furthermore, we demonstrate that, despite these efforts, the issue persists when advancing well-pretrained SMoE models, as evidenced by both theoretical and empirical results. To fill that gap, we analyze the advanced SMoE models and observe that the eigenvectors of expert weight matrices encode rich semantic information, pointing to an effective alternative to conventional routing strategies. Building on this insight, we propose Singular Value Decomposition SMoE (SSMoE), a novel and training-free framework that leverages spectral properties of the expert weights to address the collapse issue and enhance model performance. Extensive experiments across diverse language and vision tasks, under both clean and corrupt data settings, demonstrate the strong generalization and robustness of SSMoE. Our findings highlight how a deeper understanding of model internals can guide the development of more effective SMoE architectures. Our implementation is publicly available at https://github.com/giangdip2410/SSMoE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript observes that eigenvectors of expert weight matrices in pretrained SMoE models encode rich semantic information. It proposes SSMoE, a training-free router that applies SVD to these weights to generate routing decisions, claiming this mitigates expert collapse (which the authors assert persists even after prior router improvements) and improves performance. The approach is evaluated on language and vision tasks under clean and corrupted data, with public code released.
Significance. If the central observation and construction hold, the work supplies a low-cost, training-free alternative to learned routers in SMoE architectures, potentially lowering fine-tuning overhead while improving load balance and robustness. The public implementation is a clear strength that supports reproducibility.
major comments (3)
- [Abstract] Abstract: the assertion that collapse 'persists when advancing well-pretrained SMoE models, as evidenced by both theoretical and empirical results' is load-bearing for the motivation, yet the text supplies neither equations, theorems, nor any experimental protocol or metric quantifying this persistence.
- The construction of the SSMoE router is presented as leveraging 'spectral properties' to produce non-collapsing routing logits, but no derivation or argument is given showing why the top eigenvectors of W_e align with token-expert affinity directions learned during pretraining or remain stable under distribution shift; the skeptic concern that this may reduce to a static heuristic therefore cannot be assessed.
- The weakest assumption—that the observed semantic encoding is sufficiently general and invariant to expert specialization and data shifts—is stated but not tested with any controlled ablation (e.g., across different pretraining distributions or expert counts) that would be required to support the 'strong generalization' claim.
minor comments (1)
- [Abstract] The abstract is unusually dense and would benefit from a single sentence clarifying the exact routing rule (e.g., how many leading singular vectors are retained and how they are combined into logits).
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We address each major comment below, clarifying the manuscript's claims and indicating where revisions will strengthen the presentation. Our responses focus on substance and aim to improve clarity without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that collapse 'persists when advancing well-pretrained SMoE models, as evidenced by both theoretical and empirical results' is load-bearing for the motivation, yet the text supplies neither equations, theorems, nor any experimental protocol or metric quantifying this persistence.
Authors: We agree that the abstract statement would benefit from explicit pointers to the supporting material. Section 3 of the manuscript contains the theoretical analysis, including equations and a proof sketch showing that standard router improvements do not eliminate collapse in pretrained models. Section 4 presents the corresponding empirical protocol, using load-balance metrics and performance degradation under continued training. To make this immediately visible, we will revise the abstract to reference these sections and briefly note the key metrics employed. revision: yes
-
Referee: [—] The construction of the SSMoE router is presented as leveraging 'spectral properties' to produce non-collapsing routing logits, but no derivation or argument is given showing why the top eigenvectors of W_e align with token-expert affinity directions learned during pretraining or remain stable under distribution shift; the skeptic concern that this may reduce to a static heuristic therefore cannot be assessed.
Authors: The manuscript presents the alignment as an empirical observation supported by visualization and downstream performance, rather than a formal derivation. We will add a short explanatory paragraph in Section 3 that connects the top eigenvectors to the principal directions of expert specialization observed during pretraining, drawing on the fact that expert weight matrices encode token-feature covariances. While a full stability proof under arbitrary shifts is beyond the current scope, we will include a brief discussion of why the leading singular vectors are expected to be more robust than learned routers. This addition will allow readers to evaluate the heuristic concern directly. revision: partial
-
Referee: [—] The weakest assumption—that the observed semantic encoding is sufficiently general and invariant to expert specialization and data shifts—is stated but not tested with any controlled ablation (e.g., across different pretraining distributions or expert counts) that would be required to support the 'strong generalization' claim.
Authors: We acknowledge that the generalization claim would be stronger with additional controlled ablations. The current experiments already span multiple model scales, modalities, and both clean and corrupted data, but they do not systematically vary pretraining corpora or expert counts. We will add a new ablation subsection that reports results for models pretrained on different data distributions and with varying numbers of experts, thereby directly testing the invariance assumption. revision: yes
Circularity Check
No circularity: empirical observation leads to heuristic method without self-referential reduction
full rationale
The paper's core contribution is an empirical observation that eigenvectors of expert weight matrices encode semantic information, followed by the proposal of a training-free SSMoE router based on SVD. No load-bearing step reduces a claimed prediction or uniqueness result to a fitted parameter, self-citation chain, or definitional equivalence. The abstract and described approach treat the spectral property as an observed fact used to motivate a new construction, with performance validated by experiments rather than derived by construction from the inputs. This matches the default expectation of a non-circular paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
B ool Q : Exploring the Surprising Difficulty of Natural Yes/No Questions
Association for Computational Linguistics. doi: 10.18653/v1/N19-1300. URL https://aclantho logy.org/N19-1300/. Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., and Tafjord, O. Think you have solved question answering? try arc, the ai2 reasoning challenge,
-
[2]
Training Verifiers to Solve Math Word Problems
URL https://arxiv.org/abs/1803.0 5457. Coates, A., Ng, A., and Lee, H. An analysis of single- layer networks in unsupervised feature learning. In Gor- don, G., Dunson, D., and Dud ´ık, M. (eds.),Proceed- ings of the Fourteenth International Conference on Arti- ficial Intelligence and Statistics, volume 15 ofProceed- ings of Machine Learning Research, pp. ...
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[3]
Dai, D., Dong, L., Ma, S., Zheng, B., Sui, Z., Chang, B., and Wei, F
URL https://arxiv.org/abs/2504.0 5342. Dai, D., Dong, L., Ma, S., Zheng, B., Sui, Z., Chang, B., and Wei, F. StableMoE: Stable routing strategy for mixture of experts. In Muresan, S., Nakov, P., and Villavicencio, A. (eds.),Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 7085–7095, Dubli...
-
[4]
doi: 10.18653/v1/2022.acl-long.489
Association for Computational Linguistics. doi: 10.18653/v1/2022.acl-long.489. URL https://acla nthology.org/2022.acl-long.489/. Dai, D., Deng, C., Zhao, C., Xu, R., Gao, H., Chen, D., Li, J., Zeng, W., Yu, X., Wu, Y ., Xie, Z., Li, Y ., Huang, P., Luo, 10 Eigenvectors of Experts are Training-free Non-collapsing Routers F., Ruan, C., Sui, Z., and Liang, W...
-
[5]
Dutta, A., Krishnan, S., Kwatra, N., and Ramjee, R
URL https://proceedings.mlr.pres s/v162/du22c.html. Dutta, A., Krishnan, S., Kwatra, N., and Ramjee, R. Accu- racy is not all you need. In Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., and Zhang, C. (eds.),Advances in Neural Information Processing Sys- tems, volume 37, pp. 124347–124390. Curran Associates, Inc., 2024. doi: 10....
-
[6]
Jiang, T., Huang, S., Luan, Z., Wang, D., and Zhuang, F
URL https://arxiv.org/abs/2307.1 6645. Jiang, T., Huang, S., Luan, Z., Wang, D., and Zhuang, F. Scaling sentence embeddings with large language models. In Al-Onaizan, Y ., Bansal, M., and Chen, Y .-N. (eds.), Findings of the Association for Computational Linguis- tics: EMNLP 2024, pp. 3182–3196, Miami, Florida, USA, November 2024. Association for Computat...
-
[7]
URL https://doi.org/10.1109/TPAMI.2025.3 532688
doi: 10.1109/TPAMI.2025.3532688. URL https://doi.org/10.1109/TPAMI.2025.3 532688. Li, Z. and Zhou, T. Your mixture-of-experts LLM is se- cretly an embedding model for free. InThe Thirteenth International Conference on Learning Representations,
-
[8]
Can a Suit of Armor Conduct Electricity?
URL https://openreview.net/forum ?id=eFGQ97z5Cd. Li, Z., Liang, C., Zhang, Z., Hong, I., Kim, Y . J., Chen, W., and Zhao, T. Slimmoe: Structured compression of large moe models via expert slimming and distillation. In Second Conference on Language Modeling, 2025b. URL https://openreview.net/forum?id=oaCU sn391F. Lin, T.-Y ., Maire, M., Belongie, S., Hays,...
-
[9]
gpt-oss-120b & gpt-oss-20b Model Card
URL https://openreview.net/forum ?id=Pu3c0209cx. OpenAI, :, Agarwal, S., Ahmad, L., Ai, J., Altman, S., Ap- plebaum, A., Arbus, E., Arora, R. K., Bai, Y ., Baker, B., Bao, H., Barak, B., Bennett, A., Bertao, T., Brett, N., Brevdo, E., Brockman, G., Bubeck, S., Chang, C., Chen, K., Chen, M., Cheung, E., Clark, A., Cook, D., Dukhan, M., Dvorak, C., Fives, K...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
In: 2015 IEEE International Conference on Computer Vision (ICCV)
doi: 10.1109/ICCV.2015.303. Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., and Sutskever, I. Learning transferable visual models from natural language supervision. In Meila, M. and Zhang, T. (eds.),Proceedings of the 38th International Conference on Machine Learning, vol...
-
[11]
Eigenvectors of Experts are Training-free Non-collapsing Routers
URL https://openreview.net/forum ?id=B1ckMDqlg. Shen, L., Chen, G., Shao, R., Guan, W., and Nie, L. Mome: Mixture of multimodal experts for generalist multimodal large language models. In Globerson, A., Mackey, L., Bel- grave, D., Fan, A., Paquet, U., Tomczak, J., and Zhang, C. (eds.),Advances in Neural Information Processing Sys- tems, volume 37, pp. 420...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.