Augmented Lagrangian Predictive Coding
Pith reviewed 2026-06-28 23:58 UTC · model grok-4.3
The pith
Augmented Lagrangian Predictive Coding aligns local updates with backpropagation gradients in deep networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
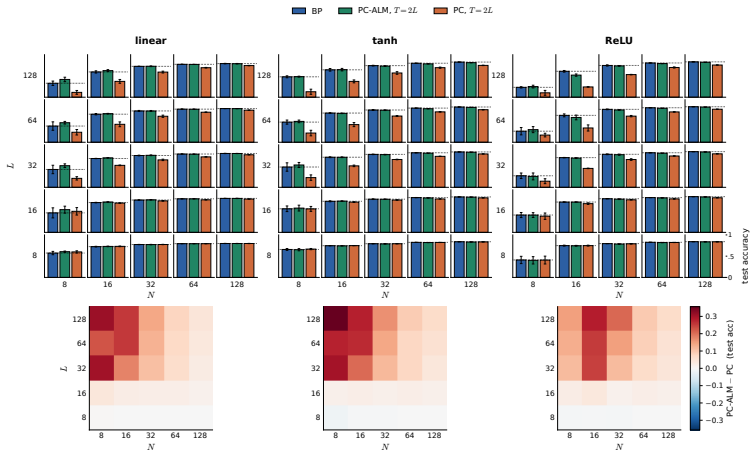
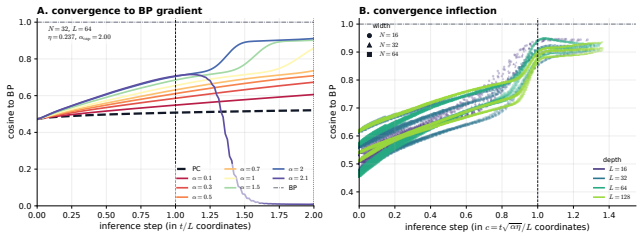
In linear PC networks, PC-ALM converges to an equilibrium with exact BP gradients distributed across the network via only layer-local updates. In nonlinear PC networks the method matches BP performance across all width-depth regimes up to depth 128.
What carries the argument
Layer-local Lagrange multiplier that accumulates per-layer constraint errors and drives dual ascent on the augmented Lagrangian.
If this is right
- Exact backpropagation gradients become available through layer-local updates alone in linear networks.
- Performance equals backpropagation in deep narrow nonlinear networks where standard predictive coding underperforms.
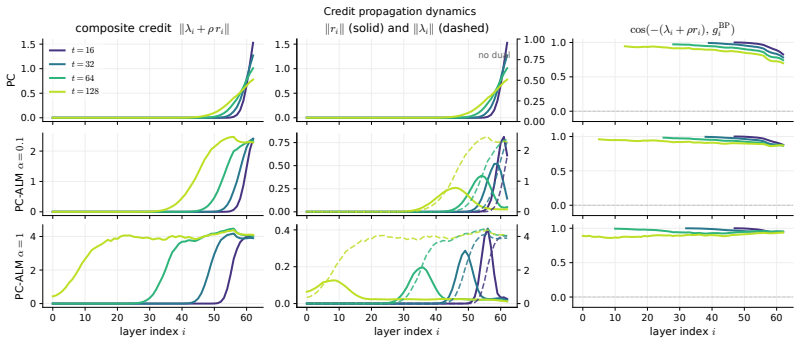
- Credit signals propagate ballistically across layers instead of by slow diffusion.
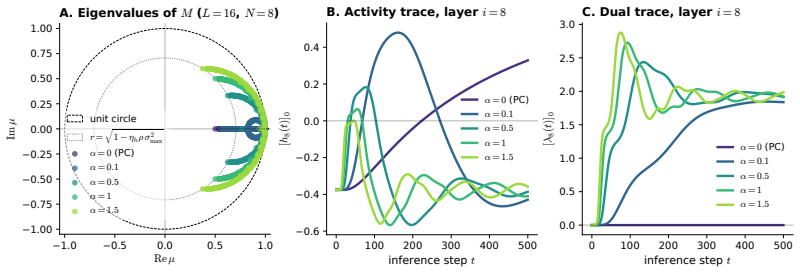
- Recurrent activation dynamics arise naturally from the dual-ascent process while keeping the per-layer inference budget unchanged.
Where Pith is reading between the lines
- The augmented Lagrangian construction may supply a general template for turning other local energy-minimization schemes into gradient-matching algorithms.
- Ballistic credit propagation offers a candidate mechanism for how very deep distributed systems could assign credit without centralized coordination.
- If the stability assumption holds, the same framework could be tested on recurrent or spiking networks where standard predictive coding has been limited by depth.
Load-bearing premise
The recurrent dynamics introduced by dual ascent on the augmented Lagrangian preserve stability and the original inference budget of predictive coding in nonlinear networks without introducing new failure modes or requiring extra global coordination.
What would settle it
A direct calculation showing that the fixed point of PC-ALM in a linear network does not satisfy the backpropagation gradient equations, or an experiment in which PC-ALM fails to match backpropagation accuracy in nonlinear networks of depth 128.
Figures

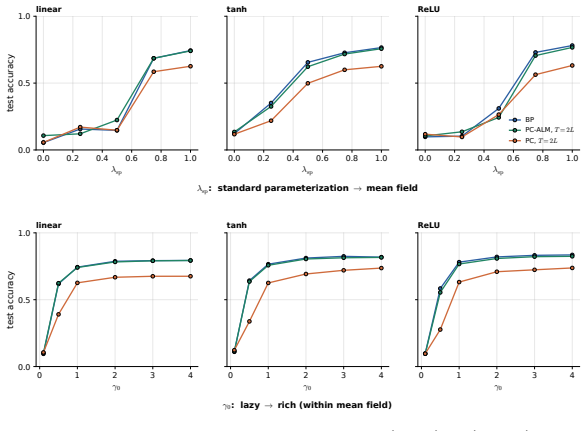
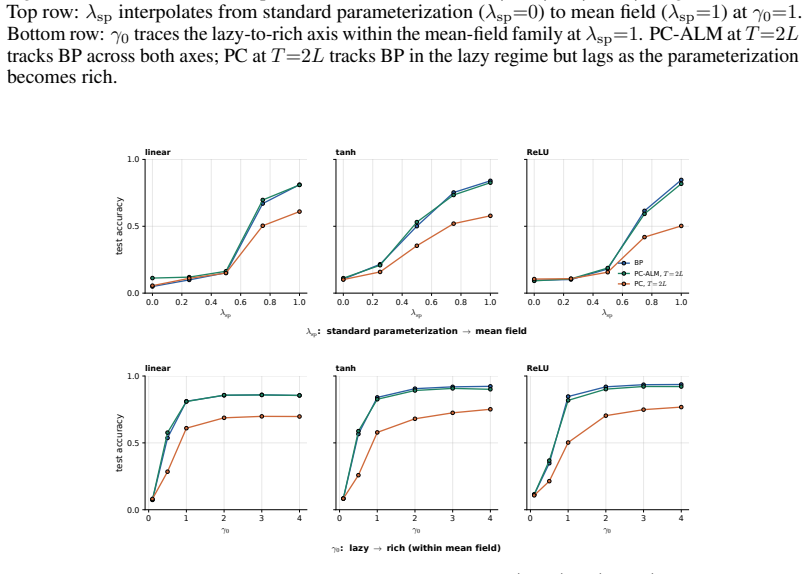

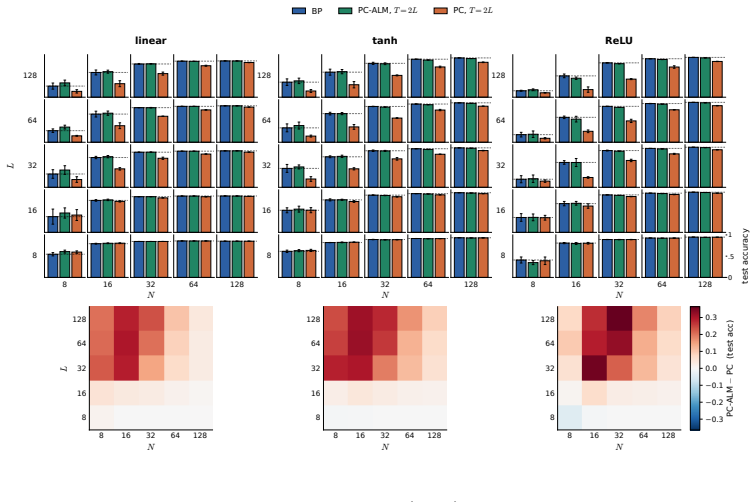
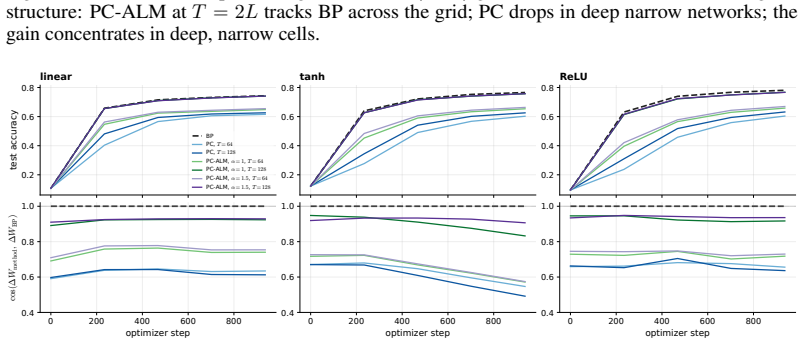
read the original abstract
Predictive coding (PC) is a local-learning alternative to backpropagation (BP), training deep networks via local energy-minimization dynamics rather than a global backward pass. We introduce Augmented Lagrangian Predictive Coding (PC-ALM), which maintains PC's inference budget but aligns each weight update toward BP by accumulating per-layer constraint errors into a layer-local Lagrange multiplier. In linear PC networks, PC-ALM converges to an equilibrium with exact BP gradients distributed across the network via only layer-local updates. We analyze PC-ALM in nonlinear PC networks up to depth 128 and show that it matches BP performance across all width-depth regimes, notably in deep narrow networks where PC underperforms. PC-ALM introduces recurrent dynamics in each layer's activations. Compared to PC's heat flow on a scalar energy, PC-ALM dynamics are driven by dual ascent on the augmented Lagrangian. We observe "ballistic" credit propagation across very deep networks, with credit signals evenly distributed across layers, compared to PC's slow, diffusive credit propagation. Beyond the algorithm itself, the augmented Lagrangian framework offers a generalization of PC, and may yield insights into how distributed systems could compute and propagate BP-like credit signals through purely local dynamics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Augmented Lagrangian Predictive Coding (PC-ALM), extending predictive coding by accumulating per-layer constraint errors into layer-local Lagrange multipliers. It claims that in linear PC networks this yields convergence to an equilibrium with exact backpropagation gradients via only layer-local updates; in nonlinear networks up to depth 128 it matches BP performance across width-depth regimes (especially deep narrow nets) while exhibiting ballistic rather than diffusive credit propagation.
Significance. If the linear exactness result and the nonlinear empirical parity hold under scrutiny, the work supplies a concrete local mechanism that recovers BP gradients without a global backward pass and offers a generalization of PC via dual-ascent dynamics. The reported ballistic credit distribution across very deep layers would be a notable empirical finding if accompanied by reproducible controls.
major comments (3)
- [Abstract] Abstract: the central claim that PC-ALM converges to exact BP gradients in the linear case is stated without any derivation, equilibrium equations, or proof sketch; because this exactness is the load-bearing theoretical result, the absence of even a high-level argument prevents verification of the 'parameter-free' or 'exact' character of the equilibrium.
- [Abstract] Nonlinear experiments (depth-128 regime): the abstract asserts performance parity with BP 'across all width-depth regimes' yet supplies neither error bars, number of runs, nor exclusion criteria; without these the claim that PC-ALM succeeds where standard PC fails in deep narrow networks cannot be assessed for robustness.
- [Abstract] Recurrent dynamics: the manuscript acknowledges that dual ascent introduces recurrent activation dynamics, yet the assumption that these preserve the original PC inference budget and introduce no new instability or coordination requirements is left unanalyzed; a stability bound or iteration-complexity comparison with vanilla PC is needed to support the 'maintains PC's inference budget' statement.
minor comments (1)
- [Abstract] The phrase 'ballistic credit propagation' is introduced without a quantitative definition or comparison metric (e.g., layer-wise gradient magnitude decay rate); a short clarifying sentence would aid readability.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive comments on our manuscript. We address each of the major comments below, providing clarifications and indicating where revisions will be made to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that PC-ALM converges to exact BP gradients in the linear case is stated without any derivation, equilibrium equations, or proof sketch; because this exactness is the load-bearing theoretical result, the absence of even a high-level argument prevents verification of the 'parameter-free' or 'exact' character of the equilibrium.
Authors: We acknowledge that the abstract, due to length constraints, does not include a derivation. However, the full manuscript provides the equilibrium analysis in the main text (Section 3). To address this, we will revise the abstract to include a concise high-level argument outlining the key equilibrium equations and why the gradients match those of backpropagation in the linear case. This will make the central claim more verifiable from the abstract alone. revision: yes
-
Referee: [Abstract] Nonlinear experiments (depth-128 regime): the abstract asserts performance parity with BP 'across all width-depth regimes' yet supplies neither error bars, number of runs, nor exclusion criteria; without these the claim that PC-ALM succeeds where standard PC fails in deep narrow networks cannot be assessed for robustness.
Authors: The abstract is a high-level summary and typically does not include detailed statistical information such as error bars or run counts, which are provided in the experimental section of the manuscript (Section 5). We agree that the abstract could be more precise. In the revision, we will add a brief statement indicating that results are averaged over multiple runs with reported standard deviations, and that the performance parity holds particularly in deep narrow regimes as shown in the figures. revision: partial
-
Referee: [Abstract] Recurrent dynamics: the manuscript acknowledges that dual ascent introduces recurrent activation dynamics, yet the assumption that these preserve the original PC inference budget and introduce no new instability or coordination requirements is left unanalyzed; a stability bound or iteration-complexity comparison with vanilla PC is needed to support the 'maintains PC's inference budget' statement.
Authors: The manuscript does note the introduction of recurrent dynamics due to dual ascent. While the empirical results demonstrate that the inference budget is maintained in practice (as PC-ALM achieves similar or better performance with comparable iteration counts), we agree that a more formal analysis would strengthen the claim. In the revised version, we will include a brief discussion or bound on the iteration complexity and stability in the main text or appendix, comparing the convergence behavior to standard PC. revision: yes
Circularity Check
No significant circularity
full rationale
The paper applies the augmented Lagrangian as an external optimization framework to predictive coding networks. The linear-case claim of exact BP gradient recovery is presented as a convergence property of the dual-ascent dynamics rather than a quantity fitted or defined inside the paper. Nonlinear results are empirical performance comparisons. No self-citation chain, ansatz smuggling, or reduction of a prediction to a fitted input is visible in the supplied text; the derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The augmented Lagrangian framework can be applied to predictive coding while preserving layer-local updates and the original inference budget.
invented entities (1)
-
layer-local Lagrange multiplier
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Nicolas Alonso, Jeffrey L. Krichmar, and Emre Neftci. Understanding and improving optimization in predictive coding networks. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, 2024. doi:10.1609/aaai.v38i10.28954
-
[2]
Armin Askari, Geoffrey Negiar, Rajiv Sambharya, and Laurent El Ghaoui. Lifted neural networks. arXiv preprint arXiv:1805.01532, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
How Auto-Encoders Could Provide Credit Assignment in Deep Networks via Target Propagation
Yoshua Bengio. How auto-encoders could provide credit assignment in deep networks via target propagation, 2014. URL https://arxiv.org/abs/1407.7906
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[4]
Bertsekas
Dimitri P. Bertsekas. Multiplier methods: A survey. Automatica, 12 0 (2): 0 133--145, 1976
1976
-
[5]
Neural networks as local-to-global computations
Alessandro Bosca and Robert Ghrist. Neural networks as local-to-global computations. arXiv preprint arXiv:2603.14831, 2026
-
[6]
Stephen Boyd, Neal Parikh, Eric Chu, Borja Peleato, and Jonathan Eckstein. Distributed optimization and statistical learning via the alternating direction method of multipliers. Foundations and Trends in Machine Learning, 3 0 (1): 0 1--122, 2011. doi:10.1561/2200000016
-
[7]
Formalizing locality for normative synaptic plasticity models
Colin Bredenberg, Ezekiel Williams, Cristina Savin, Blake Richards, and Guillaume Lajoie. Formalizing locality for normative synaptic plasticity models. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 5653--5684. Curran Associates, Inc., 2023. URL https://...
-
[8]
Carreira-Perpi \ n \'a n and Weiran Wang
Miguel \'A . Carreira-Perpi \ n \'a n and Weiran Wang. Distributed optimization of deeply nested systems. In Proceedings of the 17th International Conference on Artificial Intelligence and Statistics, PMLR 33, 2014
2014
-
[9]
Neural network training as an optimal control problem : — an augmented lagrangian approach —
Brecht Evens, Puya Latafat, Andreas Themelis, Johan Suykens, and Panagiotis Patrinos. Neural network training as an optimal control problem : — an augmented lagrangian approach —. In 2021 60th IEEE Conference on Decision and Control (CDC), page 5136–5143. IEEE, December 2021. doi:10.1109/cdc45484.2021.9682842. URL http://dx.doi.org/10.1109/CDC45484.2021.9682842
-
[10]
Thomas Frerix, Thomas M \"o llenhoff, Michael Moeller, and Daniel Cremers. Proximal backpropagation. In International Conference on Learning Representations, 2018. URL https://arxiv.org/abs/1706.04638
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[11]
Predictive coding under the free-energy principle
Karl Friston and Stefan Kiebel. Predictive coding under the free-energy principle. Philosophical Transactions of the Royal Society B: Biological Sciences, 364 0 (1521): 0 1211--1221, 2009. doi:10.1098/rstb.2008.0300
-
[12]
Decoupling backpropagation using constrained optimization methods
Akhilesh Gotmare, Valentin Thomas, Johanni Brea, and Martin Jaggi. Decoupling backpropagation using constrained optimization methods. In ICML 2018 Workshop on Credit Assignment in Deep Learning and Deep Reinforcement Learning, 2018. URL https://openreview.net/forum?id=BygR79WfWm
2018
-
[13]
Fenchel lifted networks: A L agrange relaxation of neural network training
Fangda Gu, Armin Askari, and Laurent El Ghaoui. Fenchel lifted networks: A L agrange relaxation of neural network training. In Proceedings of the 23rd International Conference on Artificial Intelligence and Statistics, PMLR 108, 2020
2020
-
[14]
Distributed optimization with sheaf homological constraints
Jakob Hansen and Robert Ghrist. Distributed optimization with sheaf homological constraints. In 2019 57th Annual Allerton Conference on Communication, Control, and Computing, pages 766--773, 2019. doi:10.1109/ALLERTON.2019.8919796
-
[15]
Hestenes
Magnus R. Hestenes. Multiplier and gradient methods. Journal of Optimization Theory and Applications, 4: 0 303--320, 1969
1969
-
[16]
Staudt, and Christopher Zach
Rasmus H ier, D. Staudt, and Christopher Zach. Dual propagation: Accelerating contrastive H ebbian learning with dyadic neurons. In International Conference on Machine Learning, PMLR 202, 2023
2023
- [17]
- [18]
-
[19]
On the Infinite Width and Depth Limits of Predictive Coding Networks
Francesco Innocenti, El Mehdi Achour, and Rafal Bogacz. On the infinite width and depth limits of predictive coding networks. arXiv preprint arXiv:2602.07697, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
A theoretical framework for back-propagation
Yann LeCun. A theoretical framework for back-propagation. Technical report, Proceedings of the 1988 Connectionist Models Summer School, 1988
1988
-
[21]
Gradient-based learning applied to document recognition
Yann LeCun, L \'e on Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86 0 (11): 0 2278--2324, 1998
1998
-
[22]
Difference target propagation
Dong-Hyun Lee, Saizheng Zhang, Asja Fischer, and Yoshua Bengio. Difference target propagation. In Joint european conference on machine learning and knowledge discovery in databases, pages 498--515. Springer, 2015
2015
-
[23]
Lifted Proximal Operator Machines
Jia Li, Cong Fang, and Zhouchen Lin. Lifted proximal operator machines. arXiv preprint arXiv:1811.01501, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[24]
Lillicrap, Adam Santoro, Luke Marris, Colin J
Timothy P. Lillicrap, Adam Santoro, Luke Marris, Colin J. Akerman, and Geoffrey Hinton. Backpropagation and the brain. Nature Reviews Neuroscience, 21 0 (6): 0 335--346, 2020. doi:10.1038/s41583-020-0277-3
- [25]
-
[26]
A theoretical framework for inference and learning in predictive coding networks
Beren Millidge, Yuhang Song, Tommaso Salvatori, Thomas Lukasiewicz, and Rafal Bogacz. A theoretical framework for inference and learning in predictive coding networks. arXiv preprint arXiv:2207.12316, 2022 a
-
[27]
Beren Millidge, Alexander Tschantz, and Christopher L. Buckley. Predictive coding approximates backprop along arbitrary computation graphs. Neural Computation, 34 0 (6): 0 1329--1368, 2022 b . doi:10.1162/neco_a_01497
-
[28]
Jorge Nocedal and Stephen J. Wright. Numerical Optimization. Springer, 2nd edition, 2006
2006
-
[29]
Benchmarking predictive coding networks -- made simple
Luca Pinchetti, Chang Qi, Oleh Lokshyn, Gaspard Olivers, Cornelius Emde, Mufeng Tang, Amine M'Charrak, Simon Frieder, Bayar Menzat, Rafal Bogacz, Thomas Lukasiewicz, and Tommaso Salvatori. Benchmarking predictive coding networks -- made simple. arXiv preprint arXiv:2407.01163, 2025
-
[30]
Michael J. D. Powell. A method for nonlinear constraints in minimization problems. Optimization, pages 283--298, 1969
1969
-
[31]
Rajesh P. Rao and Dana H. Ballard. Predictive coding in the visual cortex: a functional interpretation of some extra-classical receptive-field effects. Nature Neuroscience, 2: 0 79--87, 1999. doi:10.1038/4580
-
[32]
On the relationship between predictive coding and backpropagation
Robert Rosenbaum. On the relationship between predictive coding and backpropagation. PLoS ONE, 17 0 (3): 0 e0266102, 2022. doi:10.1371/journal.pone.0266102
-
[33]
Learning on arbitrary graph topologies via predictive coding
Tommaso Salvatori, Luca Pinchetti, Beren Millidge, Yuhang Song, Tianyi Bao, Rafal Bogacz, and Thomas Lukasiewicz. Learning on arbitrary graph topologies via predictive coding. In Advances in Neural Information Processing Systems, 2022
2022
-
[34]
Buckley, Thomas Lukasiewicz, Rajesh P.N
Tommaso Salvatori, Ankur Mali, Christopher L. Buckley, Thomas Lukasiewicz, Rajesh P.N. Rao, Karl Friston, and Alexander Ororbia. A survey on neuro-mimetic deep learning via predictive coding. Neural Networks, 195: 0 108161, 2026. ISSN 0893-6080. doi:https://doi.org/10.1016/j.neunet.2025.108161. URL https://www.sciencedirect.com/science/article/pii/S089360...
-
[35]
Equilibrium propagation: Bridging the gap between energy-based models and backpropagation
Benjamin Scellier and Yoshua Bengio. Equilibrium propagation: Bridging the gap between energy-based models and backpropagation. Frontiers in Computational Neuroscience, 11: 0 24, 2017. doi:10.3389/fncom.2017.00024
-
[36]
A Physical Theory of Backpropagation: Exact Gradients from the Least-Action Principle
Antonino Emanuele Scurria. A physical theory of backpropagation: Exact gradients from the least-action principle, 2026. URL https://arxiv.org/abs/2602.02281
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
Sheaf cohomology of linear predictive coding networks
Jeffrey Seely. Sheaf cohomology of linear predictive coding networks. arXiv preprint arXiv:2511.11092, 2025
-
[38]
Inferring neural activity before plasticity as a foundation for learning beyond backpropagation
Yuhang Song, Beren Millidge, Tommaso Salvatori, Thomas Lukasiewicz, Zhenghua Xu, and Rafal Bogacz. Inferring neural activity before plasticity as a foundation for learning beyond backpropagation. Nature Neuroscience, 2024. doi:10.1038/s41593-023-01514-1
-
[39]
Training neural networks without gradients: A scalable ADMM approach
Gavin Taylor, Ryan Burmeister, Zheng Xu, Bharat Singh, Ankit Patel, and Tom Goldstein. Training neural networks without gradients: A scalable ADMM approach. In Proceedings of the 33rd International Conference on Machine Learning, PMLR 48, 2016
2016
-
[40]
ADMM for efficient deep learning with global convergence
Junxiang Wang, Fuxun Yu, Xiang Chen, and Liang Zhao. ADMM for efficient deep learning with global convergence. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD '19, page 111–119, New York, NY, USA, 2019. Association for Computing Machinery. ISBN 9781450362016. doi:10.1145/3292500.3330936. URL https:/...
-
[41]
Lifted B regman training of neural networks
Xiaoyu Wang and Martin Benning. Lifted B regman training of neural networks. Journal of Machine Learning Research, 24, 2023
2023
-
[42]
A unified framework for lifted training and inversion approaches
Xiaoyu Wang, Alexandra Valavanis, Azhir Mahmood, Andreas Mang, Martin Benning, and Audrey Repetti. A unified framework for lifted training and inversion approaches. arXiv preprint arXiv:2510.09796, 2026
-
[43]
An augmented lagrangian method for training recurrent neural networks
Yue Wang, Chao Zhang, and Xiaojun Chen. An augmented lagrangian method for training recurrent neural networks. SIAM Journal on Scientific Computing, 47 0 (1): 0 C22--C51, 2025. doi:10.1137/23M1627614. URL https://doi.org/10.1137/23M1627614
-
[44]
James C. R. Whittington and Rafal Bogacz. An approximation of the error backpropagation algorithm in a predictive coding network with local hebbian synaptic plasticity. Neural Computation, 29 0 (5): 0 1229--1262, 2017. doi:10.1162/neco_a_00949
-
[45]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Han Xiao, Kashif Rasul, and Roland Vollgraf. Fashion- MNIST : a novel image dataset for benchmarking machine learning algorithms. arXiv preprint arXiv:1708.07747, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[46]
Contrastive Learning for Lifted Networks
Christopher Zach and Virginia Estellers. Contrastive learning for lifted networks. arXiv preprint arXiv:1905.02507, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[47]
On ADMM in deep learning: Convergence and saturation-avoidance
Jinshan Zeng, Shao-Bo Lin, Yuan Yao, and Ding-Xuan Zhou. On ADMM in deep learning: Convergence and saturation-avoidance. Journal of Machine Learning Research, 22, 2021
2021
-
[48]
Preconditioned inexact stochastic ADMM for deep models
Shenglong Zhou et al. Preconditioned inexact stochastic ADMM for deep models. Nature Machine Intelligence, 2026. doi:10.1038/s42256-026-01182-3
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.