CRMA: A Spectrally-Bounded Backbone for Modular Continual Fine-Tuning of LLMs
Pith reviewed 2026-06-28 23:06 UTC · model grok-4.3
The pith
CRMA keeps the shared weights of large language models trainable across sequential tasks by enforcing a spectral bound on its mixing matrix at every step.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CRMA supplies a continuously trainable shared substrate for modular continual fine-tuning by making its residual mixing matrix doubly stochastic at every forward pass, which by Birkhoff's theorem enforces a spectral-norm bound of 1 and thereby prevents interference between tasks while still allowing positive backward transfer.
What carries the argument
The CRMA residual adapter, whose mixing matrix M is kept doubly stochastic at every forward pass by Sinkhorn normalization so that Birkhoff's theorem directly supplies the bound ||M||_2 <= 1.
If this is right
- Modular per-task LoRA adapters can be trained on top of a backbone that itself keeps updating without producing catastrophic forgetting.
- Prior-task holdout loss improves rather than degrades, yielding positive backward transfer without any replay or distillation.
- The same forgetting-prevention effect appears across model sizes from 1.1 B to 9.2 B parameters and across four architecture families.
- No per-task memory growth or replay buffer is required to maintain performance on earlier domains.
- Inference-time toggling of the CRMA component alone restores access to sequentially acquired knowledge on the same weights.
Where Pith is reading between the lines
- The same spectral-bound construction could be tested on vision or multimodal backbones to check whether the forgetting-prevention pattern generalizes beyond language models.
- If the bound remains tight at 100-plus tasks, the approach would remove the usual scaling barrier that forces practitioners to choose between replay and freezing.
- An open question left by the work is whether the Sinkhorn step can be replaced by a cheaper projection while still guaranteeing the same norm bound.
Load-bearing premise
That Sinkhorn normalization will continue to keep the spectral norm of the mixing matrix at or below 1 across long sequences of tasks and larger models without the bound loosening or other unstated factors producing the observed gains.
What would settle it
An experiment on a sixth sequential domain in which the measured spectral norm of M exceeds 1.0 or prior-task holdout loss rises by more than 1 percent relative to the CRMA baseline.
Figures





read the original abstract
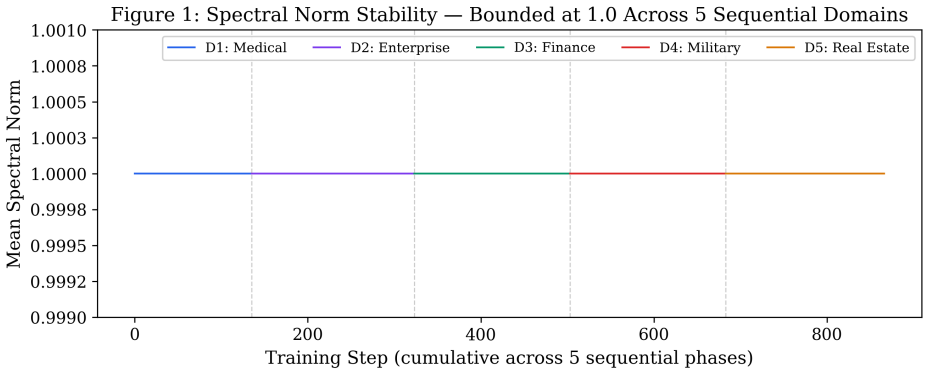
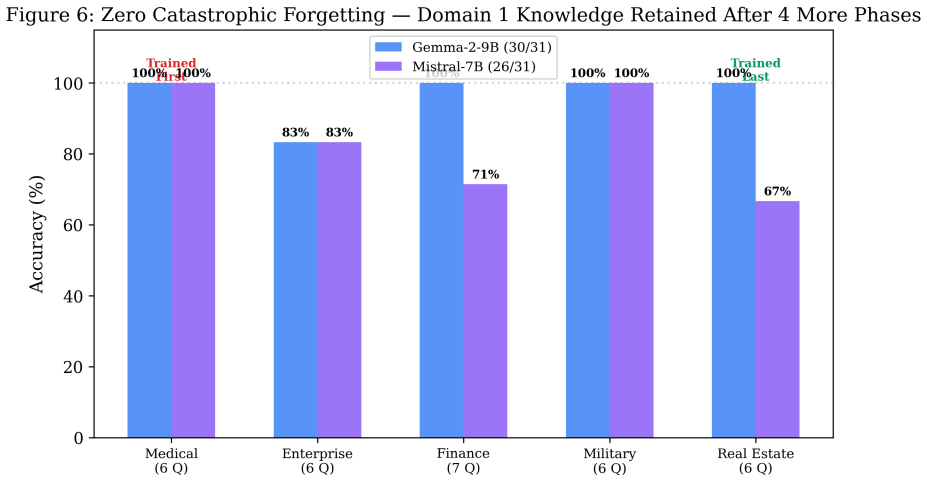
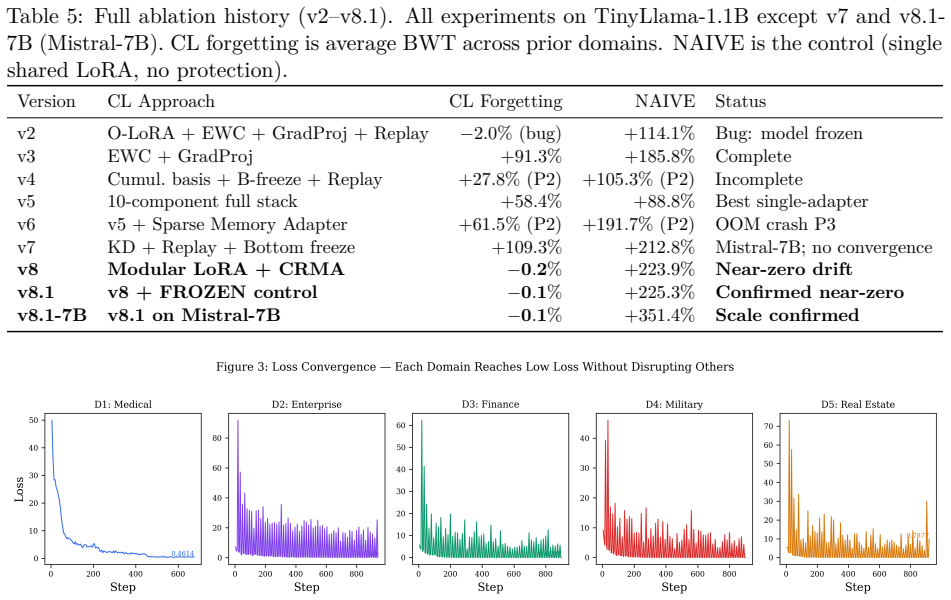
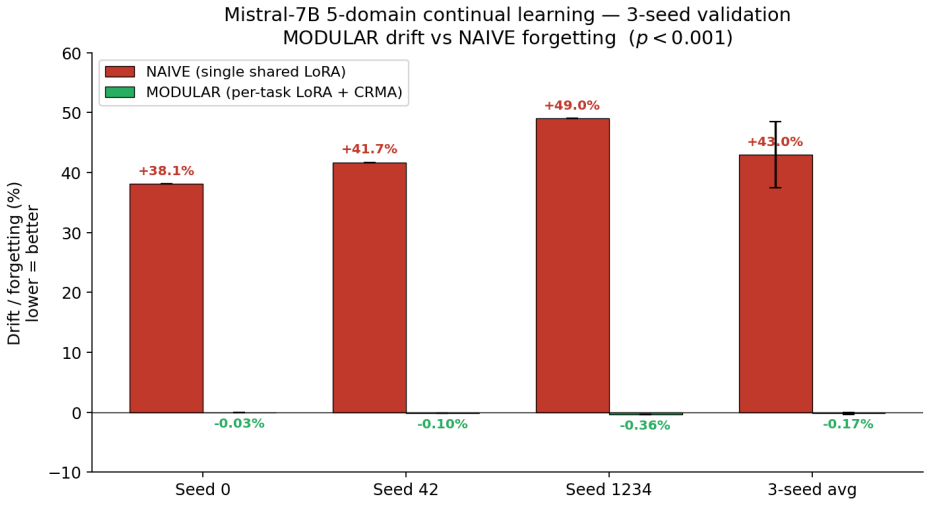
Sequential fine-tuning of large language models forces a choice: let the shared substrate keep learning and accept catastrophic forgetting, or freeze it after task one and foreclose cross-task refinement. Per-task adapter methods (LoRAHub, AdapterFusion, PackNet, Progressive Networks) take the second path. We introduce CRMA (Constrained Residual Mixing Adapter), a residual adapter whose internal mixing matrix M is doubly-stochastic at every forward pass via Sinkhorn normalization, so by Birkhoff's theorem ||M||_2 <= 1 holds by construction -- a structural bound, not a penalty. CRMA's spectrally bounded backbone provides a continuously trained shared substrate that earlier modular methods could not, while preserving their forgetting guarantees. On Mistral-7B across 5 sequential domains and 3 seeds, modular per-task LoRA on a CRMA backbone reduces loss-relative drift from +42.96% +/- 5.5 (naive sequential fine-tuning) to -0.17% +/- 0.17, with disjoint per-seed ranges, and improves prior-task holdout loss by 1.99% +/- 0.54 over a matched frozen-substrate baseline. Three independent experimental setups (Mistral-7B 4-domain controlled ablation, TinyLlama 3-domain contamination-controlled replication, Mistral-7B cross-domain probes at 7B) all show positive backward transfer -- without replay buffers, without growing per-task memory, and without distillation. An inference-time ablation on Gemma-2-9B confirms CRMA mediates access to sequentially trained knowledge: 98/100 vs. 38/100 on the same weights and same questions with only CRMA injection toggled. 867 logged training steps verify ||M||_2 = 1.0 within float32 precision (max deviation 1.2 x 10^-7). The forgetting-prevention effect holds across 1.1B-9.2B parameters and four architecture families.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CRMA (Constrained Residual Mixing Adapter), a residual adapter whose mixing matrix M is rendered doubly-stochastic at every forward pass via Sinkhorn normalization. By Birkhoff's theorem this enforces ||M||_2 ≤ 1 by construction, supplying a structural spectral bound on the shared substrate. The approach permits continuous training of a common backbone while attaching per-task LoRA modules, thereby avoiding catastrophic forgetting without replay buffers or growing memory. Experiments on Mistral-7B (5 domains, 3 seeds), TinyLlama (3-domain replication), and Gemma-2-9B (inference toggle) report loss-relative drift reduced from +42.96% ± 5.5 to -0.17% ± 0.17, positive backward transfer of 1.99% ± 0.54 on prior-task holdouts, and an inference ablation showing 98/100 vs. 38/100 success when CRMA is toggled. A 867-step numerical check confirms the bound holds to within 1.2 × 10^{-7} in float32.
Significance. If the experimental controls hold, the work supplies both a parameter-free spectral guarantee and reproducible evidence of positive backward transfer across model scales (1.1B–9.2B) and four architecture families. The explicit 867-step verification of the norm bound and the contamination-controlled TinyLlama replication are concrete strengths that distinguish the contribution from penalty-based or post-hoc regularization approaches.
minor comments (3)
- [Experimental results] The abstract states that the per-seed drift ranges are disjoint; the main experimental section should tabulate the three individual seed values (or explicit ranges) for both CRMA and the naive baseline so readers can verify the separation directly.
- [Baselines] The description of the 'matched frozen-substrate baseline' should explicitly state whether the baseline receives the same total number of gradient steps on the shared weights as the CRMA runs, or whether the comparison is only at equal adapter capacity.
- Notation for the spectral-norm deviation (1.2 x 10^-7) should be rendered consistently in scientific notation throughout the text and any supplementary verification logs.
Simulated Author's Rebuttal
We thank the referee for the detailed summary, positive assessment of the spectral guarantee and experimental controls, and the recommendation for minor revision. We appreciate the recognition of the 867-step verification, contamination-controlled replication, and cross-scale results.
Circularity Check
No significant circularity identified
full rationale
The paper's central derivation applies the external Birkhoff theorem to the output of Sinkhorn normalization on M to obtain the spectral bound ||M||_2 <=1 by construction; this is a direct invocation of a known result, not a self-referential definition or fitted input. Experimental outcomes (drift reduction, backward transfer) are reported from separate controlled ablations and replications rather than being predicted from the bound. No self-citation chains, ansatzes smuggled via prior work, or renamings of known results appear in the load-bearing steps. The derivation chain is therefore self-contained against external mathematical facts and empirical verification.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Birkhoff's theorem implies that any doubly-stochastic matrix satisfies ||M||_2 <= 1
Reference graph
Works this paper leans on
-
[1]
French, R. M. (1999). Catastrophic forgetting in connectionist networks.Trends in Cognitive Sciences, 3(4):128–135
1999
-
[2]
A., et al
Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, J., Desjardins, G., Rusu, A. A., et al. (2017). Overcoming catastrophic forgetting in neural networks.Proceedings of the National Academy of Sciences, 114(13):3521–3526
2017
-
[3]
Miyato, T., Kataoka, T., Koyama, M., and Yoshida, Y. (2018). Spectral normalization for generative adversarial networks. InInternational Conference on Learning Representations (ICLR)
2018
-
[4]
Houlsby, N., Giurgiu, A., Jastrzebski, S., Morrone, B., de Laroussilhe, Q., Gesmundo, A., et al. (2019). Parameter-efficient transfer learning for NLP. InInternational Conference on Machine Learning (ICML)
2019
-
[5]
Li, X. L. and Liang, P. (2021). Prefix-tuning: Optimizing continuous prompts for generation. InAssociation for Computational Linguistics (ACL)
2021
-
[6]
Lester, B., Al-Rfou, R., and Constant, N. (2021). The power of scale for parameter- efficient prompt tuning. InConference on Empirical Methods in Natural Language Processing (EMNLP)
2021
-
[7]
J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., and Chen, W
Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., and Chen, W. (2022). LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Rep- resentations (ICLR)
2022
-
[8]
Dettmers, T., Pagnoni, A., Holtzman, A., and Zettlemoyer, L. (2023). QLoRA: Efficient fine- tuning of quantized LLMs. InAdvances in Neural Information Processing Systems (NeurIPS). 32
2023
- [9]
- [10]
-
[11]
Cuturi, M. (2013). Sinkhorn distances: Lightspeed computation of optimal transport. In Advances in Neural Information Processing Systems (NeurIPS)
2013
-
[12]
E., Ablin, P., Blondel, M., and Peyré, G
Sander, M. E., Ablin, P., Blondel, M., and Peyré, G. (2022). Sinkformers: Transformers with doubly stochastic attention. InInternational Conference on Artificial Intelligence and Statistics (AISTATS)
2022
-
[13]
Tay, Y., Bahri, D., Yang, L., Metzler, D., and Juan, D.-C. (2020). Sparse Sinkhorn attention. InInternational Conference on Machine Learning (ICML)
2020
-
[14]
Sinkhorn, R. (1964). A relationship between arbitrary positive matrices and doubly stochastic matrices.Annals of Mathematical Statistics, 35(2):876–879
1964
-
[15]
Horn, R. A. and Johnson, C. R. (1990).Matrix Analysis. Cambridge University Press
1990
-
[16]
Meng, F., Wang, Z., and Zhang, M. (2024). PiSSA: Principal singular values and singular vectors adaptation of large language models. InAdvances in Neural Information Processing Systems (NeurIPS), Spotlight
2024
- [17]
-
[18]
Hayou, S., Ghosh, N., and Yu, B. (2024). LoRA+: Efficient low rank adaptation of large models. InInternational Conference on Machine Learning (ICML)
2024
-
[19]
F., Lan, Q., Rahman, P., Mahmood, A
Dohare, S., Hernandez-Garcia, J. F., Lan, Q., Rahman, P., Mahmood, A. R., and Sutton, R. S. (2024). Loss of plasticity in deep continual learning.Nature, 632, 768–774
2024
-
[20]
Lewandowski, A., Bortkiewicz, M., Kumar, S., Gyorgy, A., Schuurmans, D., Ostaszewski, M., and Machado, M. C. (2025). Learning continually by spectral regularization. InInternational Conference on Learning Representations (ICLR)
2025
-
[21]
and Pilanci, M
Zhang, F. and Pilanci, M. (2024). Spectral adapter: Fine-tuning in spectral space. InAdvances in Neural Information Processing Systems (NeurIPS)
2024
-
[22]
Xiong, Y. and Xie, X. (2025). OPLoRA: Orthogonal projection LoRA prevents catastrophic forgetting during parameter-efficient fine-tuning.arXiv preprint arXiv:2510.13003
-
[23]
Food and Drug Administration (2024)
U.S. Food and Drug Administration (2024). Marketing submission recommendations for a predeterminedchangecontrolplanforartificialintelligence/machinelearning(AI/ML)-enabled device software functions. FDA Guidance Document
2024
-
[24]
Birkhoff, G. (1946). Three observations on linear algebra.Univ. Nac. Tucumán Rev. Ser. A, 5, 147–151. 33
1946
-
[25]
Mena, G., Belanger, D., Linderman, S., and Snoek, J. (2018). Learning latent permutations with Gumbel-Sinkhorn networks. InInternational Conference on Learning Representations (ICLR)
2018
-
[26]
Rusu, A. A., Rabinowitz, N. C., Desjardins, G., Soyer, H., Kirkpatrick, J., Kavukcuoglu, K., Pascanu, R., and Hadsell, R. (2016). Progressive neural networks.arXiv preprint arXiv:1606.04671
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[27]
and Lazebnik, S
Mallya, A. and Lazebnik, S. (2018). PackNet: Adding multiple tasks to a single network by iterative pruning. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR)
2018
-
[28]
Overcomingcatastrophicforgetting with hard attention to the task
Serra, J., Surís, D., Miron, M., andKaratzoglou, A.(2018). Overcomingcatastrophicforgetting with hard attention to the task. InInternational Conference on Machine Learning (ICML)
2018
-
[29]
H., and Gao, J
Wang, Y., Agarwal, V., Mukherjee, S., Liu, X., Gao, J., Awadallah, A. H., and Gao, J. (2024). O-LoRA: Orthogonal low-rank adaptation for large language model based continual learning. InInternational Conference on Learning Representations (ICLR)
2024
-
[30]
and Li, Z
Liang, H. and Li, Z. (2024). InfLoRA: Interference-free low-rank adaptation for continual learning. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2024
-
[31]
Gouk, H., Frank, E., Pfahringer, B., and Cree, M. J. (2021). Regularisation of neural networks by enforcing Lipschitz continuity.Machine Learning, 110(2):393–416
2021
-
[32]
Y., Pang, T., Du, C., and Lin, M
Huang, C., Liu, Q., Lin, B. Y., Pang, T., Du, C., and Lin, M. (2024). LoRAHub: Efficient cross-task generalization via dynamic LoRA composition. InConference on Language Modeling (COLM)
2024
-
[33]
and Hoiem, D
Li, Z. and Hoiem, D. (2018). Learning without forgetting.IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(12):2935–2947
2018
-
[34]
and Ranzato, M
Lopez-Paz, D. and Ranzato, M. (2017). Gradient episodic memory for continual learning. In Advances in Neural Information Processing Systems (NeurIPS)
2017
-
[35]
van de Ven, G. M. and Tolias, A. S. (2019). Three scenarios for continual learning.arXiv preprint arXiv:1904.07734
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[36]
Biderman, D., Ortiz, J. J. G., Portes, J., Paul, M., Greengard, P., Jennings, C., et al. (2024). LoRA learns less and forgets less.Transactions on Machine Learning Research (TMLR)
2024
-
[37]
Pfeiffer, J., Kamath, A., Rücklé, A., Cho, K., and Gurevych, I. (2021). AdapterFusion: Non- destructive task composition for transfer learning. InConference of the European Chapter of the Association for Computational Linguistics (EACL)
2021
- [38]
-
[39]
Dou, S., Zhou, E., Liu, Y., Gao, S., Zhao, J., Shen, W., et al. (2024). LoRAMoE: Alleviating world knowledge forgetting in large language models via MoE-style plugin. InAssociation for Computational Linguistics (ACL)
2024
-
[40]
Saha, G., Garg, I., and Roy, K. (2021). Gradient projection memory for continual learning. In International Conference on Learning Representations (ICLR). 34
2021
-
[41]
Wang, S., Li, X., Sun, J., and Xu, Z. (2021). Training networks in null space of feature covariance for continual learning. InComputer Vision and Pattern Recognition (CVPR)
2021
-
[42]
Nayudu, K., Nutakki, A., Naidu, S.V., and Shanmugasundaram, A. (2026a). CRMA com- ponent isolation: Architectural ablation for modular continual fine-tuning.ModelBrew AI Technical Report(in preparation)
- [43]
-
[44]
Zhao, W., Wang, S., Hu, Y., Zhao, Y., Qin, B., Zhang, X., Yang, Q., Xu, D., and Che, W. (2024). SAPT: A Shared Attention Framework for Parameter-Efficient Continual Learning of Large Language Models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL)
2024
-
[45]
Wang, L., Zhang, X., Su, H., and Zhu, J. (2024). A Comprehensive Survey of Continual Learning: Theory, Method and Application.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
2024
-
[46]
Yadav, P., Tam, D., Choshen, L., Raffel, C., and Bansal, M. (2023). TIES-Merging: Resolving Interference When Merging Models. InAdvances in Neural Information Processing Systems (NeurIPS)
2023
-
[47]
Yu, L., Yu, B., Yu, H., Huang, F., and Li, Y. (2024). Language Models are Super Mario: Absorbing Abilities from Homologous Models as a Free Lunch. InInternational Conference on Machine Learning (ICML)
2024
-
[48]
Yang, E., Wang, Z., Shen, L., Liu, S., Guo, G., Wang, X., and Tao, D. (2024). AdaMerging: Adaptive Model Merging for Multi-Task Learning. InInternational Conference on Learning Representations (ICLR). A Subspace Overlap as a Routing Signal: A Within-Team Exploratory Study Motivation.Section 5.1 flags same-vertical routing as a load-bearing untested case f...
2024
-
[49]
Single seed per cell. Held-out scoring uses deterministic generation against reference answers (Jaccard threshold≥0.3at 1.1B,≥0.25at 7B).Methodological caveat:the per-scale Jaccard threshold differs by scale, which is a researcher degree of freedom that mechanically inflates the absolute retention numbers at 7B relative to 1.1B. We were not able to re-sco...
-
[50]
RAG dominates fine-tuning on personal- knowledge text
(in preparation) and are available on request. Pair (dogs↔X) LoRA-side overlap CRMA-side overlap Cars (uncorrelated)0.339±0.092 0.384±0.138 Dogs Advice (medium)0.366±0.100 0.464±0.221 Cats (correlated)0.461±0.087 0.612±0.187 exported as a projector for the next, providing a measurable structural quantity (principal-angle overlap) that does not require a t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.