Grounded Decoding: Retrieval-Anchored Probability Fusion for Faithful RAG
Pith reviewed 2026-06-28 22:42 UTC · model grok-4.3
The pith
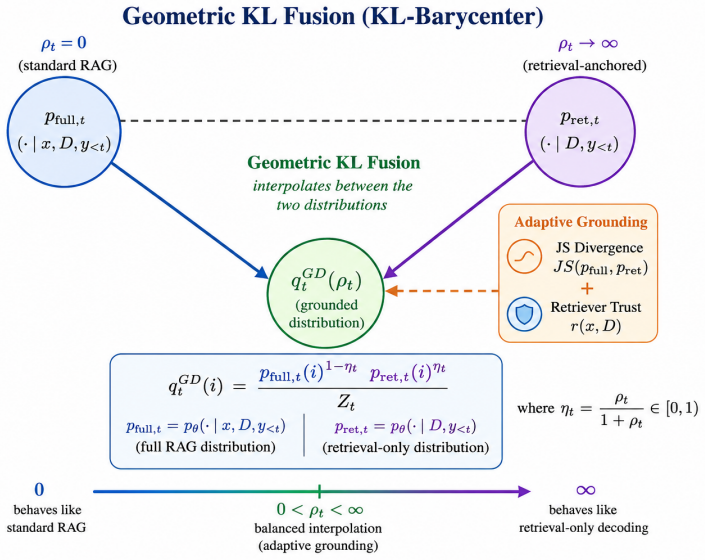
Grounded Decoding obtains the next-token distribution as the unique solution to a KL-barycenter objective that geometrically fuses the full RAG distribution with a retrieval-only distribution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
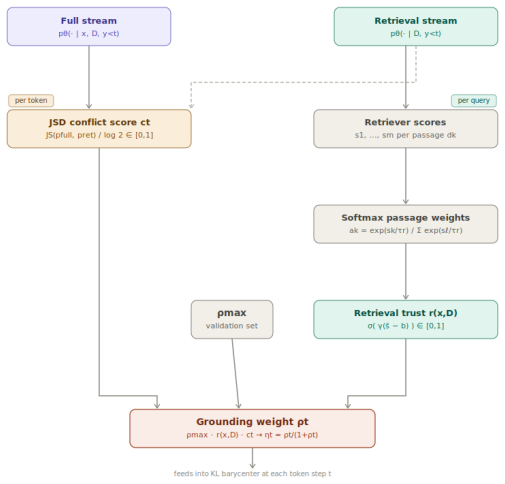
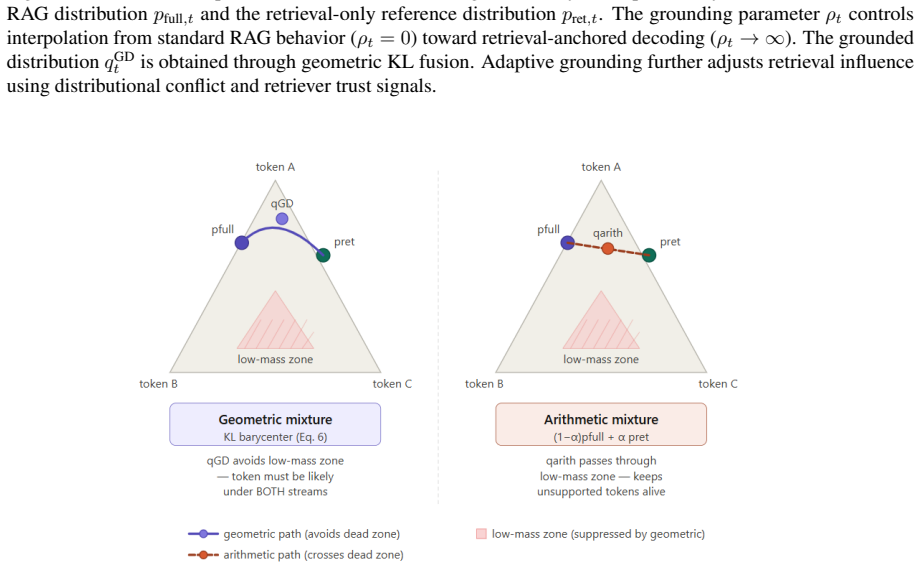
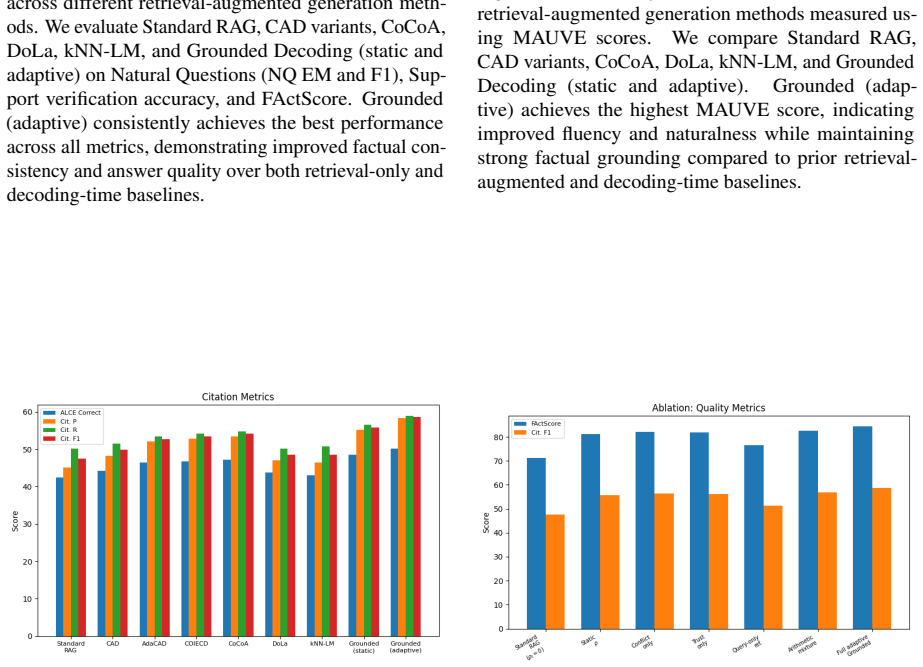
The central claim is that the optimal next-token distribution at each step is the unique minimizer of a KL-barycenter objective over the probability simplex, which produces the normalized geometric fusion of the full RAG distribution and the retrieval-only distribution. This formulation recovers standard RAG decoding exactly when the grounding weight is zero and smoothly increases the influence of retrieved evidence as the weight grows. A conflict-aware adaptive weighting scheme is introduced that adjusts the grounding strength dynamically on the basis of distributional disagreement and retriever confidence.
What carries the argument
KL-barycenter objective over the probability simplex, which yields the normalized geometric fusion of the full RAG distribution and the retrieval-only distribution
If this is right
- Standard RAG decoding is recovered exactly when the grounding weight is set to zero.
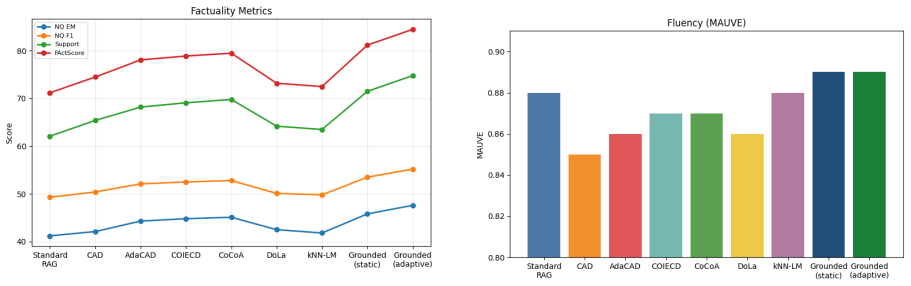
- Factual accuracy and citation quality rise on the ALCE, Natural Questions, and FActScore benchmarks.
- Fluency metrics remain comparable to standard RAG and other decoding baselines.
- The adaptive weighting scheme modulates grounding strength according to distributional disagreement and retriever confidence.
Where Pith is reading between the lines
- The same barycenter construction could be applied when multiple retrieval sources are available by including additional distributions in the objective.
- If retrieval contains systematic errors, the adaptive scheme would need to detect and down-weight those cases to avoid amplifying mistakes.
- Probability-level fusion offers a potential lightweight substitute for logit-level interventions in other constrained decoding settings.
Load-bearing premise
The retrieval-only distribution acts as a faithful factual anchor whose geometric fusion with the full RAG distribution increases consistency without introducing new factual errors or harming fluency.
What would settle it
A controlled test on inputs where the retrieved documents contain clear factual errors, measuring whether the fused outputs produce more factual mistakes than standard RAG outputs.
Figures





read the original abstract
As retrieval-augmented generation (RAG) systems scale, it becomes increasingly challenging to ensure faithful grounding in external evidence. Large language models may still prioritize parametric knowledge over retrieved information when conflicts arise. We propose a novel training-free decoding framework, \emph{Grounded Decoding}, designed to improve factual consistency in RAG without modifying model parameters. Unlike standard approaches that rely on a single conditional distribution, our method constructs two matched-prompt distributions at every generation step: (1) a full RAG distribution conditioned on the query, retrieved documents, and generated prefix, and (2) a retrieval-only distribution conditioned solely on retrieved evidence and the same prefix. The final next-token distribution is derived as the unique solution to a KL-barycenter objective over the probability simplex, yielding a normalized geometric fusion of the two distributions.This formulation naturally recovers standard RAG when the grounding weight is zero and smoothly shifts probability mass toward retrieved evidence as grounding strength increases. We further introduce a conflict-aware adaptive weighting scheme that dynamically adjusts grounding based on distributional disagreement and retriever confidence. Experiments on ALCE, Natural Questions, and FActScore demonstrate consistent improvements in factual accuracy and citation quality over standard RAG and competitive decoding-time baselines, while maintaining fluency. Our results indicate that probability-level fusion provides a strong and efficient alternative to logit-level intervention methods for faithful RAG decoding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Grounded Decoding, a training-free decoding framework for retrieval-augmented generation. At each step it constructs a full RAG distribution (conditioned on query, documents, and prefix) and a retrieval-only distribution (conditioned only on evidence and prefix), then takes their normalized geometric fusion as the unique minimizer of a weighted KL-barycenter objective over the simplex. An adaptive weighting scheme adjusts the grounding strength according to distributional disagreement and retriever . Experiments on ALCE, Natural Questions, and FActScore report gains in factual accuracy and citation quality while preserving fluency; the method recovers standard RAG when the grounding weight is zero.
Significance. If the claimed uniqueness and empirical improvements hold, the work supplies a simple, training-free probability-level fusion technique that anchors generation to retrieved evidence via the geometric-mean property of the KL barycenter. The fact that the formulation is parameter-light, recovers the baseline, and is supported by standard convex optimization arguments is a strength; reproducible gains on established factual-consistency benchmarks would make the method a practical addition to decoding-time interventions for RAG.
minor comments (3)
- [Abstract] The abstract asserts that the fused distribution is the 'unique solution' to the KL-barycenter objective and yields a normalized geometric fusion, yet supplies neither a short derivation nor a reference to the standard variational characterization (min_R ∑ w_i KL(R || P_i) yields R ∝ ∏ P_i^{w_i}). Adding one paragraph or an appendix equation would make the central claim self-contained.
- No ablation isolates the contribution of the barycenter fusion itself from the adaptive weighting scheme. Reporting results with fixed versus adaptive weights (and with the retrieval-only distribution ablated) would clarify which component drives the reported gains on ALCE, NQ, and FActScore.
- The adaptive weighting depends on distributional disagreement and retriever scores; a brief discussion of how these quantities are computed and any sensitivity to their estimation would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thoughtful summary and positive evaluation of Grounded Decoding. We are pleased that the significance of the training-free KL-barycenter fusion, its recovery of standard RAG, and the reported gains on factual-consistency benchmarks were recognized. The recommendation of minor revision is appreciated; we will incorporate any editorial or presentational suggestions in the revised manuscript.
Circularity Check
No significant circularity; derivation is standard math
full rationale
The central claim—that the fused distribution is the unique minimizer of the weighted KL-barycenter objective and equals the normalized geometric mean—follows directly from the known variational characterization of the right KL barycenter (min_R ∑ w_i KL(R || P_i) yields R ∝ ∏ P_i^{w_i} by strict convexity). This is external mathematics, not a self-definition, fitted input renamed as prediction, or self-citation chain. The adaptive weighting scheme is a separate heuristic using disagreement and retriever scores; it does not make the fusion equation reduce to its inputs by construction. Experiments on ALCE/NQ/FActScore provide external validation rather than tautological confirmation. No load-bearing step matches any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
free parameters (2)
- grounding weight
- adaptive weighting coefficients
axioms (1)
- standard math Existence and uniqueness of the solution to the KL-barycenter objective on the probability simplex
Reference graph
Works this paper leans on
-
[1]
Retrieval-Augmented Generation for Knowledge-Intensive
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K. Retrieval-Augmented Generation for Knowledge-Intensive. Advances in Neural Information Processing Systems , volume =
-
[2]
2020 , publisher =
Guu, Kelvin and Lee, Kenton and Tung, Zora and Pasupat, Panupong and Chang, Ming-Wei , booktitle =. 2020 , publisher =
2020
-
[3]
Proceedings of the 39th International Conference on Machine Learning , pages =
Improving Language Models by Retrieving from Trillions of Tokens , author =. Proceedings of the 39th International Conference on Machine Learning , pages =. 2022 , publisher =
2022
-
[4]
ACM Computing Surveys , volume =
Survey of Hallucination in Natural Language Generation , author =. ACM Computing Surveys , volume =. 2023 , doi =
2023
-
[5]
ACM Transactions on Information Systems , volume =
A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions , author =. ACM Transactions on Information Systems , volume =. 2025 , doi =
2025
-
[6]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages =
Enabling Large Language Models to Generate Text with Citations , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages =. 2023 , publisher =
2023
-
[7]
2023 , publisher =
Min, Sewon and Krishna, Kalpesh and Lyu, Xinxi and Lewis, Mike and Yih, Wen-tau and Koh, Pang Wei and Iyyer, Mohit and Zettlemoyer, Luke and Hajishirzi, Hannaneh , booktitle =. 2023 , publisher =
2023
-
[8]
Transactions of the Association for Computational Linguistics , volume =
Natural Questions: A Benchmark for Question Answering Research , author =. Transactions of the Association for Computational Linguistics , volume =. 2019 , doi =
2019
-
[9]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers) , pages =
Trusting Your Evidence: Hallucinate Less with Context-aware Decoding , author =. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers) , pages =. 2024 , publisher =
2024
-
[10]
2025 , publisher =
Wang, Han and Prasad, Archiki and Stengel-Eskin, Elias and Bansal, Mohit , booktitle =. 2025 , publisher =
2025
-
[11]
Findings of the Association for Computational Linguistics: ACL 2024 , pages =
Discerning and Resolving Knowledge Conflicts through Adaptive Decoding with Contextual Information-Entropy Constraint , author =. Findings of the Association for Computational Linguistics: ACL 2024 , pages =. 2024 , publisher =
2024
-
[12]
2025 , publisher =
Khandelwal, Anant and Gupta, Manish and Agrawal, Puneet , booktitle =. 2025 , publisher =
2025
-
[13]
Decoding as Optimisation on the Probability Simplex: From Top-
Ji, Xiaotong and Tutunov, Rasul and Zimmer, Matthieu and Bou-Ammar, Haitham , journal =. Decoding as Optimisation on the Probability Simplex: From Top-
-
[14]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
Contrastive Decoding: Open-ended Text Generation as Optimization , author =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2023 , publisher =
2023
-
[15]
Chuang, Yung-Sung and Xie, Yujia and Luo, Hongyin and Kim, Yoon and Glass, James and He, Pengcheng , booktitle =
-
[16]
International Conference on Learning Representations , year =
Generalization through Memorization: Nearest Neighbor Language Models , author =. International Conference on Learning Representations , year =
-
[17]
International Conference on Learning Representations , year =
The Curious Case of Neural Text Degeneration , author =. International Conference on Learning Representations , year =
-
[18]
Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
Hierarchical Neural Story Generation , author =. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2018 , publisher =
2018
-
[19]
Turning Up the Heat: Min-
Nguyen, Minh and Baker, Andrew and Neo, Clement and Roush, Allen and Kirsch, Andreas and Shwartz-Ziv, Ravid , booktitle =. Turning Up the Heat: Min-. 2025 , note =
2025
-
[20]
Advances in Neural Information Processing Systems , volume =
Training Language Models to Follow Instructions with Human Feedback , author =. Advances in Neural Information Processing Systems , volume =
-
[21]
Advances in Neural Information Processing Systems , volume =
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author =. Advances in Neural Information Processing Systems , volume =
-
[22]
Transactions on Machine Learning Research , year =
Unsupervised Dense Information Retrieval with Contrastive Learning , author =. Transactions on Machine Learning Research , year =
-
[23]
Asai, Akari and Wu, Zeqiu and Wang, Yizhong and Sil, Avirup and Hajishirzi, Hannaneh , booktitle =. Self-. 2024 , url =
2024
-
[24]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages =
Entity-Based Knowledge Conflicts in Question Answering , author =. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages =. 2021 , publisher =
2021
-
[25]
2024 , howpublished =
Meta. 2024 , howpublished =
2024
-
[26]
Jiang, Albert Q. and Sablayrolles, Alexandre and Mensch, Arthur and Bamford, Chris and Chaplot, Devendra Singh and de las Casas, Diego and Bressand, Florian and Lengyel, Gianna and Lample, Guillaume and Saulnier, Lucile and Lavaud, L. arXiv preprint arXiv:2310.06825 , year =
-
[27]
2021 , publisher =
Yang, Kevin and Klein, Dan , booktitle =. 2021 , publisher =
2021
-
[28]
International Conference on Learning Representations , year =
Plug and Play Language Models: A Simple Approach to Controlled Text Generation , author =. International Conference on Learning Representations , year =
-
[29]
2021 , publisher =
Krause, Ben and Gotmare, Akhilesh Deepak and McCann, Bryan and Keskar, Nitish Shirish and Joty, Shafiq and Socher, Richard and Rajani, Nazneen Fatema , booktitle =. 2021 , publisher =
2021
-
[30]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2024. https://arxiv.org/abs/2310.11511 Self- RAG : Learning to retrieve, generate, and critique through self-reflection . In International Conference on Learning Representations
Pith/arXiv arXiv 2024
-
[31]
Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George van den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, Diego de Las Casas, Aurelia Guy, Jacob Menick, Roman Ring, Tom Hennigan, Saffron Huang, Loren Maggiore, Chris Jones, Albin Cassirer, and 9 others. 2022. https://arxiv.org/abs/2112.044...
Pith/arXiv arXiv 2022
-
[32]
Yung-Sung Chuang, Yujia Xie, Hongyin Luo, Yoon Kim, James Glass, and Pengcheng He. 2024. DoLa : Decoding by contrasting layers improves factuality in large language models. In International Conference on Learning Representations
2024
-
[33]
Sumanth Dathathri, Andrea Madotto, Janice Lan, Jane Hung, Eric Frank, Piero Molino, Jason Yosinski, and Rosanne Liu. 2020. Plug and play language models: A simple approach to controlled text generation. In International Conference on Learning Representations
2020
-
[34]
Angela Fan, Mike Lewis, and Yann Dauphin. 2018. https://doi.org/10.18653/v1/P18-1082 Hierarchical neural story generation . In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 889--898. Association for Computational Linguistics
-
[35]
Tianyu Gao, Howard Yen, Jiatong Yu, and Danqi Chen. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.398 Enabling large language models to generate text with citations . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6465--6488. Association for Computational Linguistics
-
[36]
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang. 2020. REALM : Retrieval-augmented language model pre-training. In Proceedings of the 37th International Conference on Machine Learning, pages 3929--3938. PMLR
2020
-
[37]
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. 2020. The curious case of neural text degeneration. In International Conference on Learning Representations
2020
-
[38]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. 2025. https://doi.org/10.1145/3703155 A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions . ACM Transactions on Information Systems, 43(2):1--55. Also avail...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1145/3703155 2025
-
[39]
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand Joulin, and Edouard Grave. 2022. Unsupervised dense information retrieval with contrastive learning. Transactions on Machine Learning Research
2022
-
[40]
Xiaotong Ji, Rasul Tutunov, Matthieu Zimmer, and Haitham Bou-Ammar. 2026. Decoding as optimisation on the probability simplex: From top- K to top- P (nucleus) to best-of- K samplers. arXiv preprint arXiv:2602.18292
arXiv 2026
-
[41]
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. https://doi.org/10.1145/3571730 Survey of hallucination in natural language generation . ACM Computing Surveys, 55(12):1--38
-
[42]
Anant Khandelwal, Manish Gupta, and Puneet Agrawal. 2025. CoCoA : Confidence- and context-aware adaptive decoding for resolving knowledge conflicts in large language models. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 6835--6855. Association for Computational Linguistics
2025
-
[43]
Urvashi Khandelwal, Omer Levy, Dan Jurafsky, Luke Zettlemoyer, and Mike Lewis. 2020. Generalization through memorization: Nearest neighbor language models. In International Conference on Learning Representations
2020
-
[44]
Ben Krause, Akhilesh Deepak Gotmare, Bryan McCann, Nitish Shirish Keskar, Shafiq Joty, Richard Socher, and Nazneen Fatema Rajani. 2021. https://doi.org/10.18653/v1/2021.findings-emnlp.424 GeDi : Generative discriminator guided sequence generation . In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 4929--4952. Association for ...
-
[45]
Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. https://doi.org/10.1162/tacl_a_00276 Natural questions: A benchma...
-
[46]
u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K \"u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \"a schel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Advances in Neural Information Processing Systems, volume 33, pages 9459--9474
2020
-
[47]
doi: 10.18653/v1/2023.acl-long.687
Xiang Lisa Li, Ari Holtzman, Daniel Fried, Percy Liang, Jason Eisner, Tatsunori B. Hashimoto, Luke Zettlemoyer, and Mike Lewis. 2023. https://doi.org/10.18653/v1/2023.acl-long.687 Contrastive decoding: Open-ended text generation as optimization . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pap...
-
[48]
Shayne Longpre, Kartik Perisetla, Anthony Chen, Nikhil Ramesh, Chris DuBois, and Sameer Singh. 2021. https://doi.org/10.18653/v1/2021.emnlp-main.565 Entity-based knowledge conflicts in question answering . In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 7052--7063. Association for Computational Linguistics
-
[49]
Meta AI . 2024. Meta Llama 3 model card. https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md. Model card, accessed 2026-05-15
2024
-
[50]
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.741 FActScore : Fine-grained atomic evaluation of factual precision in long form text generation . In Proceedings of the 2023 Conference on Empirical Methods in Natural Lang...
-
[51]
Minh Nguyen, Andrew Baker, Clement Neo, Allen Roush, Andreas Kirsch, and Ravid Shwartz-Ziv. 2025. Turning up the heat: Min- P sampling for creative and coherent LLM outputs. In International Conference on Learning Representations. Oral; arXiv:2407.01082
arXiv 2025
-
[52]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with hum...
2022
-
[53]
Manning, Stefano Ermon, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model. In Advances in Neural Information Processing Systems, volume 36
2023
-
[54]
Weijia Shi, Xiaochuang Han, Mike Lewis, Yulia Tsvetkov, Luke Zettlemoyer, and Wen-tau Yih. 2024. https://doi.org/10.18653/v1/2024.naacl-short.69 Trusting your evidence: Hallucinate less with context-aware decoding . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technolo...
-
[55]
Han Wang, Archiki Prasad, Elias Stengel-Eskin, and Mohit Bansal. 2025. AdaCAD : Adaptively decoding to balance conflicts between contextual and parametric knowledge. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 11636...
2025
-
[56]
Kevin Yang and Dan Klein. 2021. https://doi.org/10.18653/v1/2021.naacl-main.276 FUDGE : Controlled text generation with future discriminators . In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 3511--3535. Association for Computational Linguistics
-
[57]
Xiaowei Yuan, Zhao Yang, Yequan Wang, Shengping Liu, Jun Zhao, and Kang Liu. 2024. https://doi.org/10.18653/v1/2024.findings-acl.234 Discerning and resolving knowledge conflicts through adaptive decoding with contextual information-entropy constraint . In Findings of the Association for Computational Linguistics: ACL 2024, pages 3903--3922. Association fo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.