What Do Students Learn? A Feature-Level Analysis of Dark Knowledge
Pith reviewed 2026-06-28 11:19 UTC · model grok-4.3
The pith
Effective knowledge distillation prunes low-frequency sample-specific features, and a model's dataset-level confusion matrix encodes analogous dark knowledge for teacher-free self-distillation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Knowledge distillation functions as a regularizer that prunes low-frequency sample-specific features and encourages reliance on compact reusable features; the dataset-level confusion matrix contains structural information analogous to a teacher's dark knowledge, which can be exploited directly as dynamic soft targets in a teacher-free self-distillation procedure called Confusion Distillation.
What carries the argument
The Interaction Tensor framework for decomposing feature learning, together with the dataset-level confusion matrix used as evolving soft targets in Confusion Distillation.
If this is right
- Students succeed in distillation by discarding low-frequency sample-specific features in favor of a compact reusable feature set.
- The confusion matrix computed over the training set can substitute for teacher logits as soft targets.
- Confusion Distillation achieves competitive accuracy on ResNet-34 and ResNet-50 for CIFAR-100 while avoiding a separate teacher model.
- The method outperforms CS-KD and PS-KD by 1.2 percentage points on the same benchmarks.
Where Pith is reading between the lines
- Tracking confusion evolution during training may supply a general signal for regularization in other self-supervised or semi-supervised settings.
- The pruning effect on low-frequency features could be tested by measuring feature reuse frequency before and after applying the method.
- Because no external teacher is required, the approach may scale to larger models where training a separate teacher is prohibitive.
Load-bearing premise
The dataset-level confusion matrix contains structural information analogous to the teacher's dark knowledge.
What would settle it
Running Confusion Distillation on a dataset where the confusion matrix shows no correlation with teacher logit patterns and measuring whether accuracy remains at or below standard cross-entropy training or other self-distillation baselines.
Figures
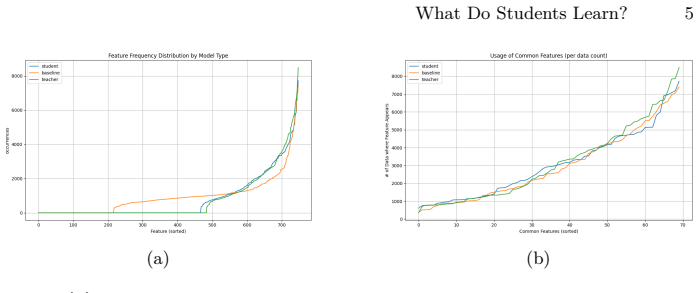
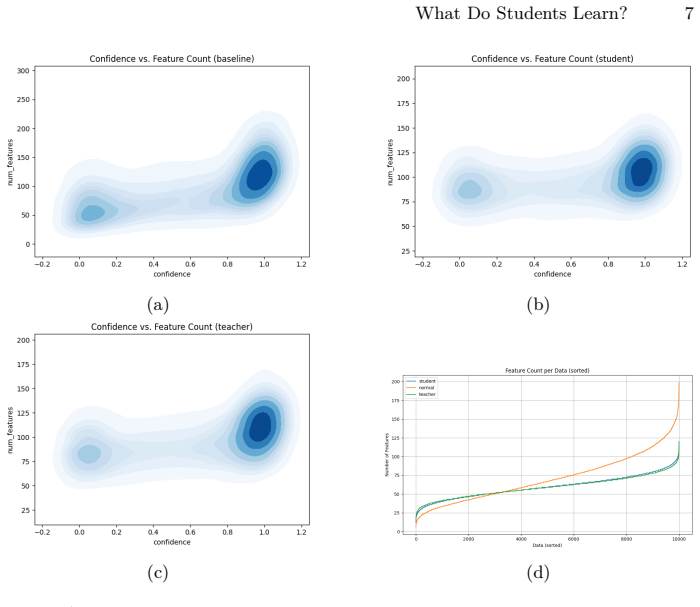
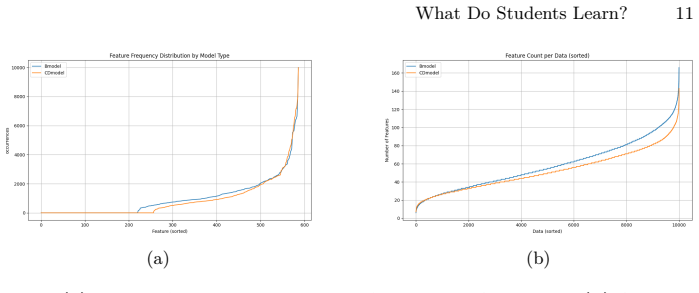
read the original abstract
Knowledge Distillation (KD) is a powerful tool for model compression, yet the precise mechanisms by which student models acquire feature representations remain underexplored. In this work, we analyze student feature learning using the Interaction Tensor framework. Our analysis reveals that effective KD acts as a regularizer that prunes low-frequency, sample-specific features, encouraging the student to rely on a compact set of highly reusable features. Crucially, we observe that the dataset-level confusion matrix contains structural information analogous to the teacher's "Dark Knowledge." Leveraging this insight, we propose Confusion Distillation (CD), a teacher-free self-distillation method that utilizes the model's own evolving confusion patterns as dynamic soft targets. CD achieves competitive performance on ResNet-34 and ResNet-50 for CIFAR-100, outperforming existing self-distillation methods like CS-KD and PS-KD by 1.2% while offering a computationally efficient alternative to standard KD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes student feature learning in knowledge distillation via the Interaction Tensor framework, claiming that effective KD regularizes by pruning low-frequency sample-specific features in favor of reusable ones. It asserts that the dataset-level confusion matrix encodes structural information analogous to a teacher's dark knowledge. This leads to the proposal of Confusion Distillation (CD), a teacher-free self-distillation method that uses the model's evolving confusion patterns as dynamic soft targets. CD is reported to achieve competitive accuracy on ResNet-34 and ResNet-50 for CIFAR-100, outperforming CS-KD and PS-KD by 1.2%.
Significance. If the analogy between confusion matrices and dark knowledge is substantiated and the performance claims hold under rigorous controls, the work could advance understanding of self-distillation mechanisms and provide a computationally lightweight alternative to standard KD. The application of the Interaction Tensor framework for feature-level analysis would be a strength if it yields falsifiable, reproducible insights into feature pruning.
major comments (2)
- [§3] §3 (Interaction Tensor analysis): the central assertion that the dataset-level confusion matrix contains structural information analogous to the teacher's dark knowledge lacks explicit quantitative support, such as cosine similarity, eigenvalue comparisons, or direct matrix alignment between student confusion patterns and those of a converged teacher model.
- [§5] §5 (CD method and experiments): the reported 1.2% gain over CS-KD and PS-KD on CIFAR-100 is load-bearing for the contribution, yet no ablation isolates the off-diagonal confusion structure from generic label smoothing or self-regularization effects; without this, the method risks reducing to standard regularization whose advantage may not persist under matched hyperparameters.
minor comments (2)
- [Experiments section] Table reporting CIFAR-100 results: include standard deviations across multiple runs and the exact number of trials to allow assessment of statistical significance for the 1.2% margin.
- [§2] Notation for the Interaction Tensor: clarify whether it is a new construction or drawn from prior work, and provide a self-contained definition or reference in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below, agreeing that additional quantitative support and ablations will strengthen the claims, and we will incorporate these in the revision.
read point-by-point responses
-
Referee: [§3] §3 (Interaction Tensor analysis): the central assertion that the dataset-level confusion matrix contains structural information analogous to the teacher's dark knowledge lacks explicit quantitative support, such as cosine similarity, eigenvalue comparisons, or direct matrix alignment between student confusion patterns and those of a converged teacher model.
Authors: We agree that the current presentation relies primarily on the Interaction Tensor analysis and downstream performance of CD for support. To provide explicit quantitative backing, the revised manuscript will include cosine similarity scores and eigenvalue spectrum comparisons between evolving student confusion matrices and those from a converged teacher model trained via standard KD. These metrics will be reported across training epochs on CIFAR-100. revision: yes
-
Referee: [§5] §5 (CD method and experiments): the reported 1.2% gain over CS-KD and PS-KD on CIFAR-100 is load-bearing for the contribution, yet no ablation isolates the off-diagonal confusion structure from generic label smoothing or self-regularization effects; without this, the method risks reducing to standard regularization whose advantage may not persist under matched hyperparameters.
Authors: This concern is well-taken, as the current experiments do not fully disentangle the structured off-diagonal contributions. In revision, we will add ablations using (i) only the diagonal of the confusion matrix (dynamic label smoothing) and (ii) off-diagonal elements with row-wise shuffling to preserve marginals but remove structure. All variants will use identical hyperparameter search budgets and be compared directly to CS-KD and PS-KD on the same ResNet-34/50 CIFAR-100 splits. revision: yes
Circularity Check
No significant circularity; derivation rests on empirical observation and experimental validation
full rationale
The paper's chain proceeds from Interaction Tensor analysis of student features under KD, to the observation that a dataset-level confusion matrix encodes reusable structure analogous to dark knowledge, to the proposal of Confusion Distillation using the model's own evolving predictions as soft targets, with performance measured on CIFAR-100. None of these steps reduce by construction to fitted parameters renamed as predictions, self-definitional equations, or load-bearing self-citations; the analogy is presented as an empirical finding rather than a tautology, and the 1.2% gain is an external experimental outcome. The method is therefore self-contained against the listed circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jiang, C
Y. Jiang, C. Baek, and J. Z. Kolter,On the Joint Interaction of Models, Data, and Features, In International Conference on Learning Representations (ICLR), 2024
2024
-
[2]
Hinton, O
G. Hinton, O. Vinyals, and J. Dean,Distilling the Knowledge in a Neural Network, in Proceedings of the NIPS Deep Learning and Representation Learning Workshop, 2015
2015
-
[3]
L.Yuan,F.EH.Tay,G.Li,T.Wang,andJ.Feng,Revisiting Knowledge Distillation via Label Smoothing Regularization, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[4]
H. Zhou, L. Song, J. Chen, Y. Zhou, G. Wang, J. Yuan, and Q. Zhang,Rethinking Soft Labels for Knowledge Distillation: A Bias-Variance Tradeoff Perspective, in International Conference on Learning Representations (ICLR), 2021
2021
-
[5]
K. He, X. Zhang, S. Ren, and J. Sun,Deep Residual Learning for Image Recog- nition, In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016
2016
-
[6]
S. Yun, J. Park, K. Lee, and J. Shin,Regularizing Class-wise Predictions via Self- knowledge Distillation, In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[7]
K. Kim, B. Ji, D. Yoon, and S. Hwang,Self-Knowledge Distillation with Progressive Refinement of Targets, In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021
2021
-
[8]
Romero, N
A. Romero, N. Ballas, S. E. Kahou, A. Chassang, C. Gatta, and Y. Bengio,FitNets: Hints for Thin Deep Nets,InInternationalConferenceonLearningRepresentations (ICLR), 2015
2015
-
[9]
Zagoruyko and N
S. Zagoruyko and N. Komodakis,Paying More Attention to Attention: Improv- ing the Performance of Convolutional Neural Networks via Attention Transfer, In International Conference on Learning Representations (ICLR), 2017
2017
-
[10]
J. Kim, S. Park, and N. Kwak,Paraphrasing Complex Network: Network Compres- sion via Factor Transfer, In Advances in Neural Information Processing Systems (NeurIPS), 2018
2018
-
[11]
Y. Tian, D. Krishnan, and P. Isola,Contrastive Representation Distillation, In International Conference on Learning Representations (ICLR), 2020
2020
-
[12]
W. Park, D. Kim, Y. Lu, and M. Cho,Relational Knowledge Distillation, In Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2019. What Do Students Learn? 15
2019
-
[13]
Furlanello, Z
T. Furlanello, Z. Lipton, M. Tschannen, L. Itti, and A. Anandkumar,Born Again Neural Networks, In International Conference on Machine Learning (ICML), 2018
2018
-
[14]
Zhang, T
Y. Zhang, T. Xiang, T. M. Hospedales, and H. Lu,Deep Mutual Learning, In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018
2018
-
[15]
Zhang, J
L. Zhang, J. Song, A. Gao, J. Chen, C. Bao, and K. Ma,Be Your Own Teacher: Improve the Performance of Convolutional Neural Networks via Self Distillation, In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019
2019
-
[16]
Raghu, J
M. Raghu, J. Gilmer, J. Yosinski, and J. Sohl-Dickstein,SVCCA: Singular Vector Canonical Correlation Analysis for Deep Learning Dynamics and Interpretability, In Advances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[17]
S.Kornblith,M.Norouzi,H.Lee,andG.Hinton,Similarity of Neural Network Rep- resentations Revisited, In International Conference on Machine Learning (ICML), 2019
2019
-
[18]
Xu, and C
T. Xu, and C. Liu,Data-Distortion Guided Self-Distillation for Deep Neural Net- works, In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2019
2019
-
[19]
Z. Yang, A. Zeng, Z. Li, T. Zhang, C. Yuan, and Y. Li,From Knowledge Distilla- tion to Self-Knowledge Distillation: A Unified Approach with Normalized Loss and Customized Soft Labels, In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[20]
Koço, and C Capponi,On multi-class classification through the minimization of the confusion matrix norm, In Asian Conference on Machine Learning (ACML), 2013
S. Koço, and C Capponi,On multi-class classification through the minimization of the confusion matrix norm, In Asian Conference on Machine Learning (ACML), 2013
2013
-
[21]
L. Yan, B. Zhong, and K.-K. Ma,Confusion-Aware Convolutional Neural Network for Image Classification, In International Conference on Neural Information Pro- cessing (ICONIP), 2019
2019
-
[22]
N. Tsoi, K. Candon, D. Li, Y. Milkessa, and M. Vázquez,Bridging the Gap: Unify- ing the Training and Evaluation of Neural Network Binary Classifiers, In Advances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[23]
D. Han, N. Moniz, and N. V. Chawla,AnyLoss: Transforming Classification Met- rics into Loss Functions, In Proceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), 2024
2024
-
[24]
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
P. Goyal, P. Dollár, R. Girshick, P. Noordhuis, L. Wesolowski, A. Kyrola, A. Tul- loch, Y. Jia, and K. He,Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour, ArXiv preprint arXiv:1706.02677, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [25]
-
[26]
Müller, S
R. Müller, S. Kornblith, and G. Hinton,When Does Label Smoothing Help?, In Advances in Neural Information Processing Systems (NeurIPS), 2019
2019
-
[27]
Feldman,Does Learning Require Memorization? A Short Tale about a Long Tail, In Proceedings of the 52nd Annual ACM SIGACT Symposium on Theory of Computing (STOC), 2020
V. Feldman,Does Learning Require Memorization? A Short Tale about a Long Tail, In Proceedings of the 52nd Annual ACM SIGACT Symposium on Theory of Computing (STOC), 2020
2020
-
[28]
A.TarvainenandH.Valpola,Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results, In Advances in Neural Information Processing Systems (NeurIPS), 2017
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.