Mitigating False Credit Propagation: Probabilistic Graphical Reward Aggregation for Rubric-Based Reinforcement Learning
Pith reviewed 2026-06-28 10:55 UTC · model grok-4.3
The pith
GEAR models rubric criteria as latent events in a dependency graph to block false credit from propagating through unmet prerequisites.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
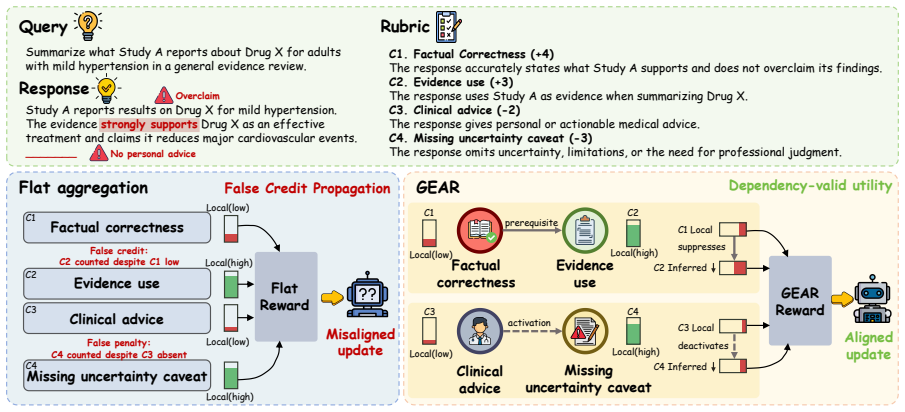
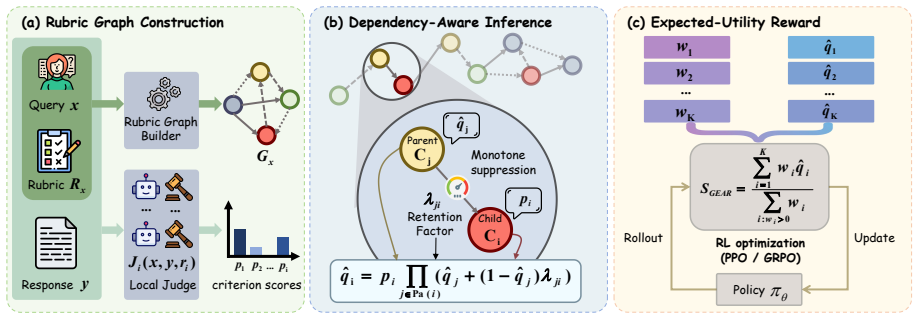
GEAR models each criterion outcome as a latent Bernoulli event in a typed rubric graph, propagates soft suppression from unsupported parent events to their children, and aggregates the resulting event probabilities into a normalized expected signed utility. This yields a linear-time reward computation that can be plugged into standard rubric-based RL pipelines without changing the outer optimization algorithm.
What carries the argument
Typed rubric graph whose nodes are latent Bernoulli events and whose edges carry soft suppression to enforce prerequisite and activation dependencies during aggregation.
If this is right
- Yields linear-time reward computation usable in any standard rubric-based RL pipeline.
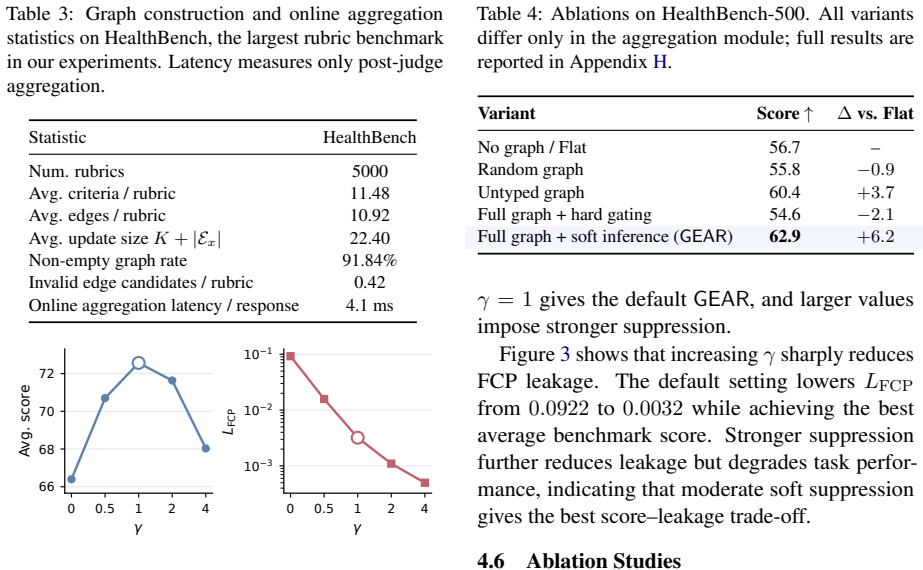
- Delivers relative gains up to 15.5% over flat aggregation on HealthBench, WritingBench, and PLawBench.
- Reduces leakage by 96.5% relative to flat aggregation while retaining more licensed downstream utility than deterministic gating.
Where Pith is reading between the lines
- The same suppression mechanism could be applied to any hierarchical scoring task that encodes logical dependencies between items.
- If the supplied graph relations contain systematic errors, the method would likely amplify those errors rather than correct them.
- Tracing which events receive suppression offers a built-in explanation for why a particular reward value was assigned.
Load-bearing premise
The prerequisite and activation relations among criteria are accurately and completely specified in the typed rubric graph provided as input.
What would settle it
An experiment that supplies an incorrect or incomplete rubric graph and measures whether GEAR then produces lower policy performance than flat aggregation on the same tasks.
Figures
read the original abstract
Rubric-based rewards are increasingly used for open-ended language model post-training, but criterion-level scores are often aggregated as independent utilities. This flat scalarization ignores rubric-specified prerequisite and activation relations among criteria, allowing reward or penalty to be counted even when the condition that licenses it is absent. We call this structural reward-aggregation failure \textbf{False Credit Propagation} (FCP). To address this limitation, we propose \ourname (\textbf{G}raphical \textbf{E}vent \textbf{A}ggregation for \textbf{R}ubric rewards), a probabilistic graphical framework for dependency-aware rubric aggregation. \ourname models each criterion outcome as a latent Bernoulli event in a typed rubric graph, propagates soft suppression from unsupported parent events to their children, and aggregates the resulting event probabilities into a normalized expected signed utility. This yields a linear-time reward computation that can be plugged into standard rubric-based RL pipelines without changing the outer optimization algorithm. Experiments on HealthBench, WritingBench, and PLawBench with two policy backbones show that \ourname consistently improves over flat aggregation and deterministic gating, achieving relative gains of up to 15.5\% over flat aggregation. FCP diagnostics further show that \ourname reduces leakage by 96.5\% relative to flat aggregation while preserving more licensed downstream utility than deterministic gating. Our code is publicly available at https://github.com/LvCan926/GEAR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that flat aggregation of rubric-based rewards in LM post-training ignores prerequisite/activation relations among criteria, causing False Credit Propagation (FCP). It proposes GEAR, which represents each criterion outcome as a latent Bernoulli event in a typed rubric graph, propagates soft suppression from unsupported parents to children, and aggregates the resulting probabilities into a normalized expected signed utility. This yields a linear-time, plug-in reward that is evaluated on HealthBench, WritingBench, and PLawBench with two policy backbones, reporting relative gains of up to 15.5% over flat aggregation and a 96.5% leakage reduction while preserving more licensed utility than deterministic gating. Public code is provided.
Significance. If the central claims hold, GEAR offers a principled, dependency-aware alternative to independent utility aggregation for rubric rewards, addressing a structural failure mode that can distort RL signals in open-ended tasks. The linear-time computation and public implementation are concrete strengths that would facilitate adoption and further testing.
major comments (2)
- [Abstract / Experiments] Abstract and experimental sections: the reported 15.5% gains and 96.5% leakage reduction are obtained under the authors' chosen typed rubric graphs; no sensitivity analysis or ablation on edge errors, missing prerequisites, or mis-specified activation relations is described. Because the method's core operation is soft suppression propagated along those edges, the absence of such tests leaves the robustness of the gains unverified when the input graph (a manual authoring artifact) deviates from ground truth.
- [Method description] The weakest assumption listed in the stress-test note—that the typed rubric graph accurately and completely encodes all relations—is treated as given rather than tested. If any dependency is omitted or incorrect, suppression can either fail to block false credit or incorrectly damp licensed downstream events; this directly affects whether the normalized expected utility remains a faithful reward signal.
minor comments (1)
- [Abstract] The abstract states that the framework 'can be plugged into standard rubric-based RL pipelines without changing the outer optimization algorithm,' but does not specify whether the Bernoulli parameters or graph structure are held fixed during policy optimization or re-estimated.
Simulated Author's Rebuttal
We appreciate the referee's insightful comments on the robustness of GEAR to rubric graph specifications. Below we respond to each major comment and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and experimental sections: the reported 15.5% gains and 96.5% leakage reduction are obtained under the authors' chosen typed rubric graphs; no sensitivity analysis or ablation on edge errors, missing prerequisites, or mis-specified activation relations is described. Because the method's core operation is soft suppression propagated along those edges, the absence of such tests leaves the robustness of the gains unverified when the input graph (a manual authoring artifact) deviates from ground truth.
Authors: We agree that evaluating sensitivity to graph misspecification is important, since soft suppression propagates along the edges. The reported results use the rubric graphs as provided by the benchmarks, which represent the intended relations for those tasks. To address the concern, the revised manuscript will add a dedicated sensitivity analysis subsection. This will include controlled perturbations such as random edge removal (simulating missing prerequisites), edge addition (simulating spurious relations), and edge type flips, with results reported on performance deltas and leakage reduction across the three benchmarks. revision: yes
-
Referee: [Method description] The weakest assumption listed in the stress-test note—that the typed rubric graph accurately and completely encodes all relations—is treated as given rather than tested. If any dependency is omitted or incorrect, suppression can either fail to block false credit or incorrectly damp licensed downstream events; this directly affects whether the normalized expected utility remains a faithful reward signal.
Authors: We will expand the method section to explicitly restate this assumption, discuss its implications for reward fidelity, and reference the stress-test note more prominently. The new sensitivity experiments described above will directly quantify how deviations affect the normalized expected signed utility, providing empirical grounding rather than leaving the assumption unexamined. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper defines a new probabilistic graphical model (GEAR) that takes a typed rubric graph as explicit input and computes event probabilities via soft suppression propagation along its edges. Reported gains (up to 15.5% relative improvement, 96.5% leakage reduction) are obtained from downstream RL experiments on HealthBench, WritingBench, and PLawBench rather than from any fitted parameter or self-referential equation. No equations, self-citations, or ansatzes in the abstract or description reduce the core claim to a renaming or tautological fit of the same data. The method is presented as a plug-in framework whose correctness is externally falsifiable via the public code and benchmark results.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Rubric criteria possess prerequisite and activation relations that can be represented as a typed graph.
- domain assumption Criterion outcomes can be represented as latent Bernoulli random variables whose probabilities are adjusted by parent events.
invented entities (1)
-
Typed rubric graph with latent Bernoulli events
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2022 , eprint=
Training language models to follow instructions with human feedback , author=. 2022 , eprint=
2022
-
[2]
2022 , eprint=
Constitutional AI: Harmlessness from AI Feedback , author=. 2022 , eprint=
2022
-
[3]
2024 , eprint=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. 2024 , eprint=
2024
-
[4]
2025 , eprint=
Multidimensional Rubric-oriented Reward Model Learning via Geometric Projection Reference Constraints , author=. 2025 , eprint=
2025
-
[5]
2025 , eprint=
HealthBench: Evaluating Large Language Models Towards Improved Human Health , author=. 2025 , eprint=
2025
-
[6]
2023 , eprint=
GPQA: A Graduate-Level Google-Proof Q&A Benchmark , author=. 2023 , eprint=
2023
-
[7]
2025 , eprint=
AdvancedIF: Rubric-Based Benchmarking and Reinforcement Learning for Advancing LLM Instruction Following , author=. 2025 , eprint=
2025
-
[8]
2026 , eprint=
OpenRubrics: Towards Scalable Synthetic Rubric Generation for Reward Modeling and LLM Alignment , author=. 2026 , eprint=
2026
-
[9]
2026 , eprint=
Learning Query-Specific Rubrics from Human Preferences for DeepResearch Report Generation , author=. 2026 , eprint=
2026
-
[10]
2026 , eprint=
RubricHub: A Comprehensive and Highly Discriminative Rubric Dataset via Automated Coarse-to-Fine Generation , author=. 2026 , eprint=
2026
-
[11]
2025 , eprint=
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains , author=. 2025 , eprint=
2025
-
[12]
2026 , eprint=
Chasing the Tail: Effective Rubric-based Reward Modeling for Large Language Model Post-Training , author=. 2026 , eprint=
2026
-
[13]
2026 , eprint=
RULERS: Locked Rubrics and Evidence-Anchored Scoring for Robust LLM Evaluation , author=. 2026 , eprint=
2026
-
[14]
2026 , eprint=
RubricEval: A Rubric-Level Meta-Evaluation Benchmark for LLM Judges in Instruction Following , author=. 2026 , eprint=
2026
-
[15]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , url =
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric and Zhang, Hao and Gonzalez, Joseph and Stoica, Ion , booktitle =. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , url =
-
[16]
2024 , eprint=
RewardBench: Evaluating Reward Models for Language Modeling , author=. 2024 , eprint=
2024
-
[17]
2014 , publisher=
Probabilistic reasoning in intelligent systems: networks of plausible inference , author=. 2014 , publisher=
2014
-
[18]
2009 , publisher=
Probabilistic graphical models: principles and techniques , author=. 2009 , publisher=
2009
-
[19]
2023 , eprint=
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment , author=. 2023 , eprint=
2023
-
[20]
2024 , eprint=
Prometheus: Inducing Fine-grained Evaluation Capability in Language Models , author=. 2024 , eprint=
2024
-
[21]
2024 , eprint=
Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models , author=. 2024 , eprint=
2024
-
[22]
2025 , eprint=
A Survey on LLM-as-a-Judge , author=. 2025 , eprint=
2025
-
[23]
2025 , eprint=
WritingBench: A Comprehensive Benchmark for Generative Writing , author=. 2025 , eprint=
2025
-
[24]
Rubrik ' s Cube: Testing a New Rubric for Evaluating Explanations on the CUBE dataset
Galvan-Sosa, Diana and Gaudeau, Gabrielle and Kavumba, Pride and Li, Yunmeng and Gu, Hongyi and Yuan, Zheng and Sakaguchi, Keisuke and Buttery, Paula. Rubrik ' s Cube: Testing a New Rubric for Evaluating Explanations on the CUBE dataset. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. ...
-
[25]
2025 , eprint=
ResearchRubrics: A Benchmark of Prompts and Rubrics For Evaluating Deep Research Agents , author=. 2025 , eprint=
2025
-
[26]
2026 , eprint=
DEER: A Benchmark for Evaluating Deep Research Agents on Expert Report Generation , author=. 2026 , eprint=
2026
-
[27]
2026 , eprint=
Autorubric: Unifying Rubric-based LLM Evaluation , author=. 2026 , eprint=
2026
-
[28]
2026 , eprint=
Learning to Judge: LLMs Designing and Applying Evaluation Rubrics , author=. 2026 , eprint=
2026
-
[29]
2025 , eprint=
Reinforcement Learning with Rubric Anchors , author=. 2025 , eprint=
2025
-
[30]
2026 , eprint=
Breaking the Exploration Bottleneck: Rubric-Scaffolded Reinforcement Learning for General LLM Reasoning , author=. 2026 , eprint=
2026
-
[31]
Motivation
A Simple "Motivation" Can Enhance Reinforcement Finetuning of Large Reasoning Models , author=. 2026 , eprint=
2026
-
[32]
Representing Scoring Rubrics as Graphs for Automatic Short Answer Grading
Condor, Aubrey and Pardos, Zachary and Linn, Marcia. Representing Scoring Rubrics as Graphs for Automatic Short Answer Grading. Artificial Intelligence in Education. 2022
2022
-
[33]
2025 , eprint=
PaperBench: Evaluating AI's Ability to Replicate AI Research , author=. 2025 , eprint=
2025
-
[34]
2026 , eprint=
PLawBench: A Rubric-Based Benchmark for Evaluating LLMs in Real-World Legal Practice , author=. 2026 , eprint=
2026
-
[35]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[36]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[37]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[38]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.