LimiX-2M: Mitigating Low-Rank Collapse and Attention Bottlenecks in Tabular Foundation Models
Pith reviewed 2026-06-28 06:58 UTC · model grok-4.3
The pith
RaBEL tokenization and S->N->F reordering enable a 2M-parameter tabular model to outperform larger baselines with lower costs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
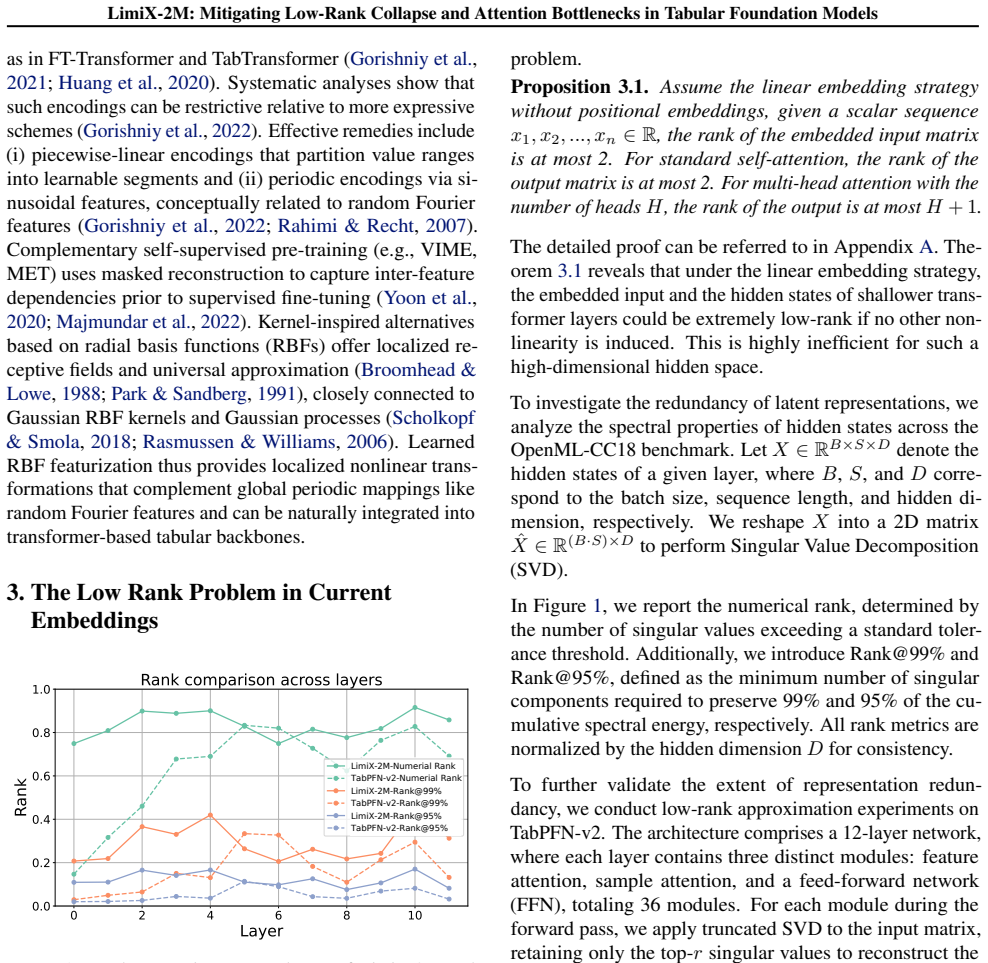
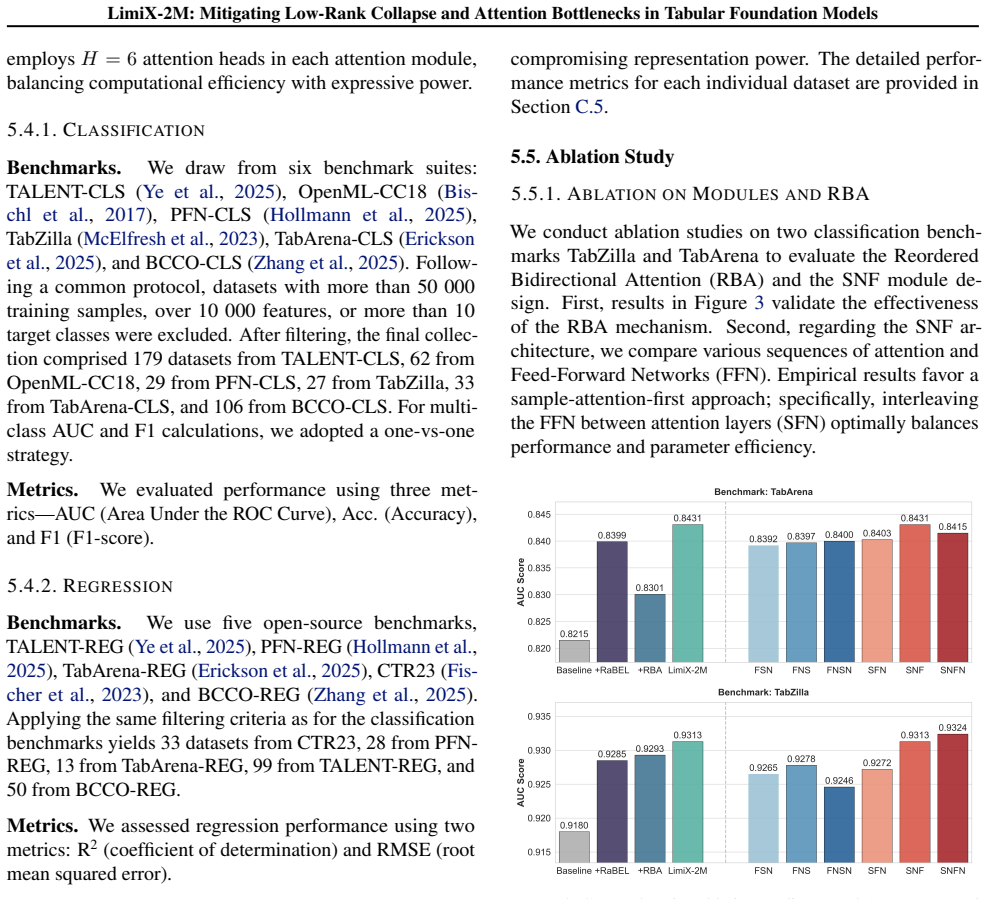
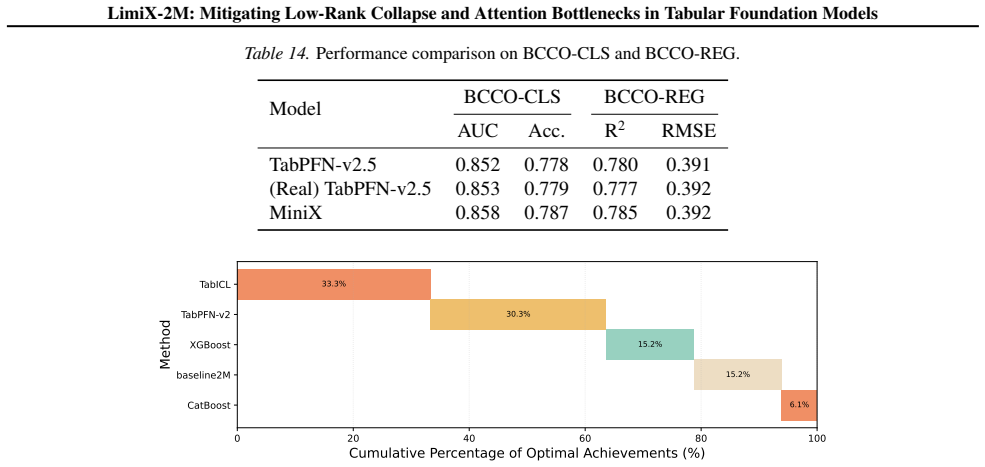
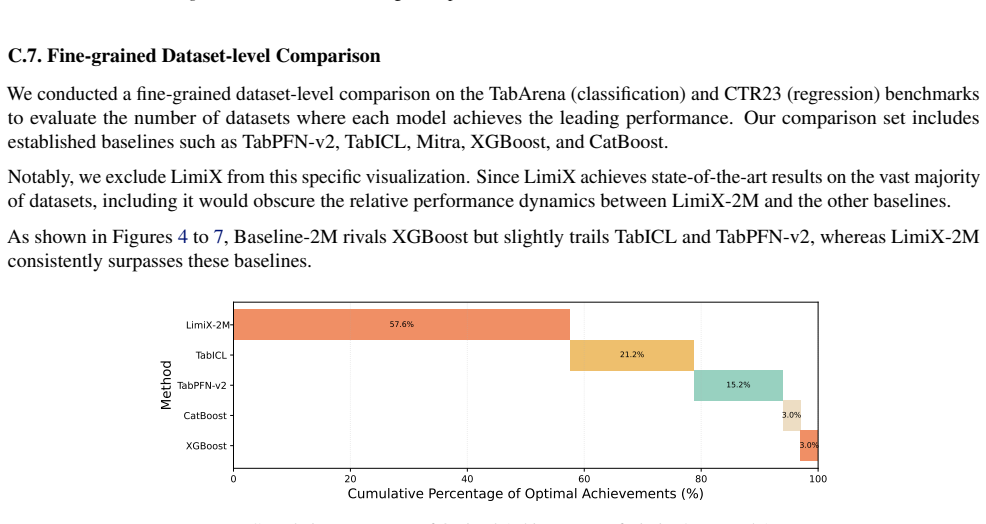
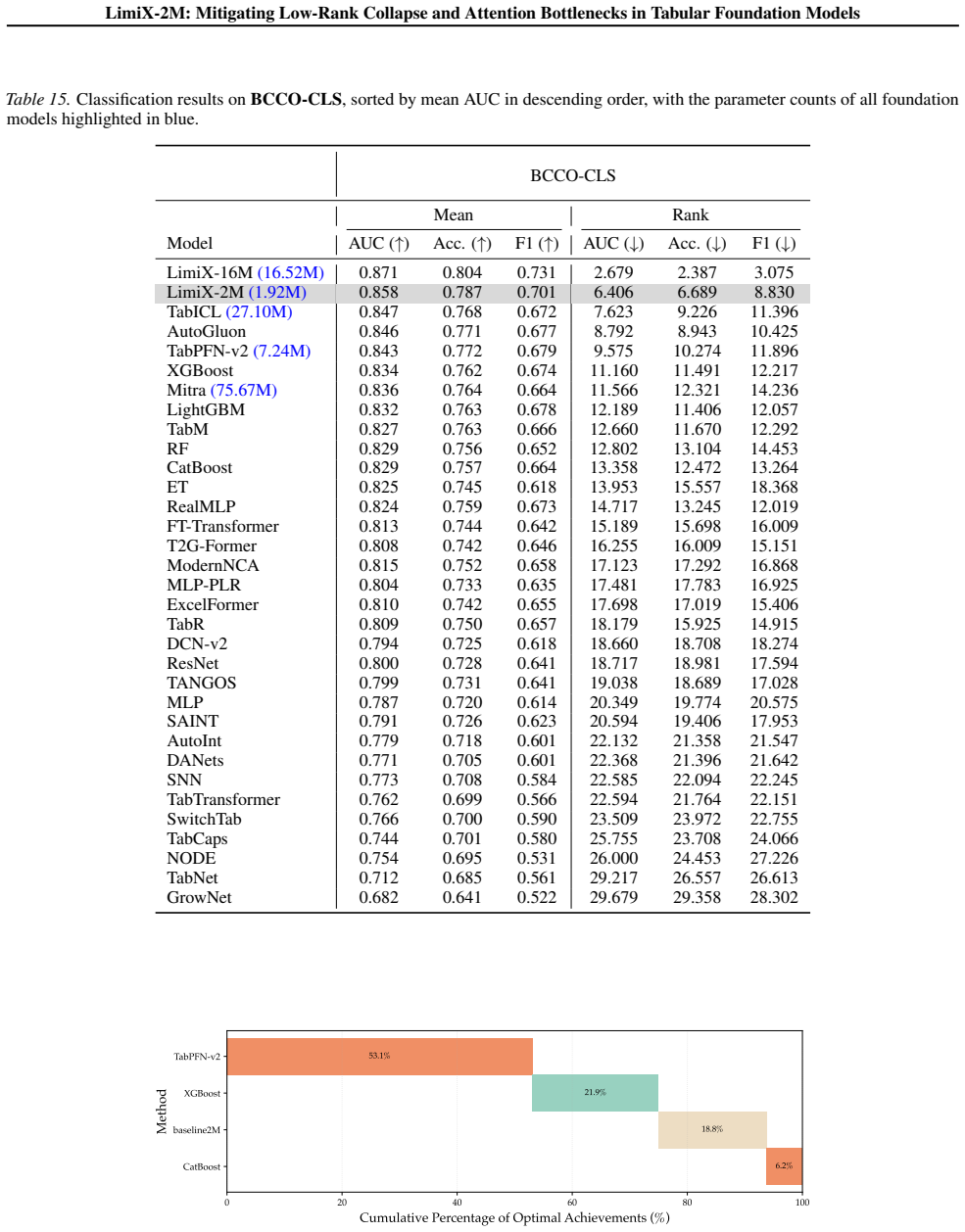
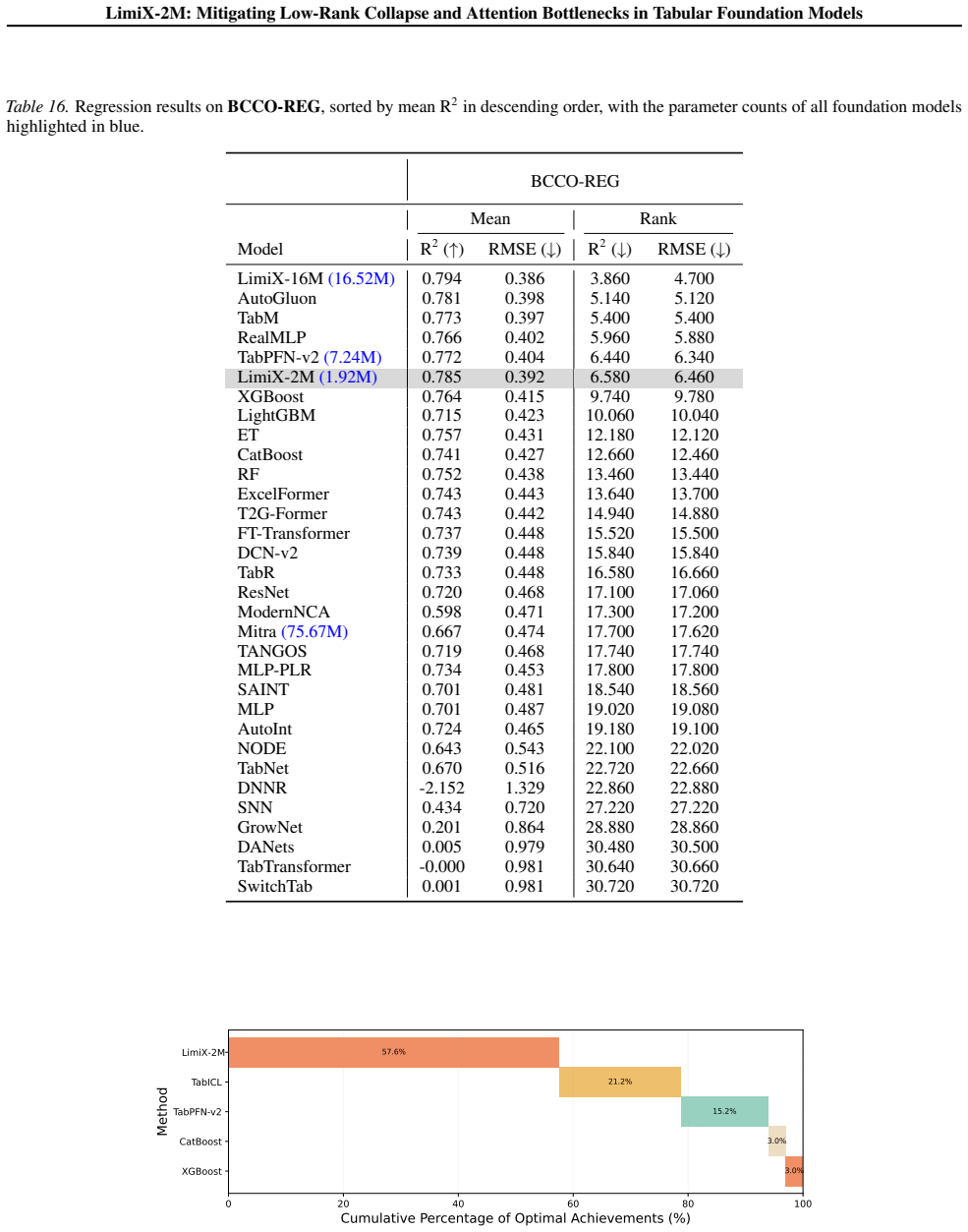
Low-rank collapse and attention bottlenecks in TFMs arise from affine scalar tokenization that injects value variation through an essentially one-dimensional channel and from routing that fails to align with readout. RaBEL expands each scalar into compact localized RBF features, optionally exponent-gated, to improve conditioning and shallow-layer effective rank. The reordered bidirectional block S->N->F aggregates cross-sample context before feature mixing and uses attention pooling. Together these produce LimiX-2M, a 2M-parameter model that outperforms larger TabPFN-v2 and TabICL baselines on widely used tabular benchmarks while reducing training and inference costs.
What carries the argument
RaBEL tokenization expands each scalar into compact localized RBF features (optionally exponent-gated) to raise value sensitivity and effective rank; paired with S->N->F reordered bidirectional blocks that aggregate cross-sample context before feature mixing and apply attention pooling.
If this is right
- LimiX-2M outperforms larger TabPFN-v2 and TabICL baselines on widely used tabular benchmarks.
- Training and inference costs decrease relative to the larger baselines.
- Shallow-layer effective rank rises because each feature now carries richer localized value variation.
- Redundant hidden states decrease once computation is reordered to align with readout.
- Value-aware tokenization and readout-aligned routing become key levers for the accuracy-efficiency trade-off in TFMs.
Where Pith is reading between the lines
- The same tokenization change could be tested on time-series or graph data where scalar inputs similarly constrain early-layer expressivity.
- Combining these components with larger parameter counts might produce further gains beyond the 2M scale demonstrated.
- Designs for other foundation models could adopt localized RBF-style expansions when feature values are the bottleneck rather than sequence length.
Load-bearing premise
Low-rank collapse and attention bottlenecks are the main performance limiters in current TFMs and are directly resolved by RaBEL tokenization plus S->N->F reordering without other unaccounted factors driving the gains.
What would settle it
A controlled ablation where standard tokenization plus matched compute matches or exceeds LimiX-2M accuracy, or where removing the RBF expansion or the S->N->F reordering eliminates the reported gains.
Figures

read the original abstract
Tabular foundation models (TFMs) increasingly rival tree ensembles, but their performance is often compute-inefficient: with standard affine scalar tokenization, each feature injects value variation through an essentially one-dimensional channel, and feature IDs/positional signals cannot increase within-feature value degrees of freedom, yielding weak early-layer value sensitivity and redundant hidden states. We present a unified tokenize-and-route framework for strong TFMs: RaBEL expands each scalar into compact localized RBF features (optionally exponent-gated) to improve conditioning and shallow-layer effective rank, while a reordered bidirectional block S->N->F aligns computation with the readout by aggregating cross-sample context before feature mixing and using attention pooling. Together, these changes yield LimiX-2M, a 2M-parameter model that outperforms larger TabPFN-v2 and TabICL baselines on widely used tabular benchmarks while reducing training and inference costs. These results highlight value-aware tokenization and readout-aligned routing as key levers for improving the accuracy--efficiency trade-off in TFMs. Model checkpoints and inference code are available at https://github.com/limix-ldm-ai/LimiX.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a tokenize-and-route framework for tabular foundation models to address low-rank collapse arising from standard affine scalar tokenization (where each feature injects variation through a one-dimensional channel) and attention bottlenecks. It proposes RaBEL tokenization, which expands each scalar into compact localized RBF features (optionally exponent-gated) to improve conditioning and shallow-layer effective rank, together with a reordered bidirectional block using S->N->F routing that aggregates cross-sample context before feature mixing and employs attention pooling to align with readout. These modifications produce the LimiX-2M model (2M parameters) claimed to outperform larger TabPFN-v2 and TabICL baselines on standard tabular benchmarks while lowering training and inference costs. Checkpoints and inference code are released.
Significance. If the empirical results hold, the work identifies value-aware tokenization and readout-aligned routing as practical levers for improving the accuracy-efficiency trade-off in TFMs. The public release of model checkpoints and inference code is a clear strength that supports reproducibility and enables independent verification or extension.
minor comments (1)
- Abstract: the phrase 'widely used tabular benchmarks' is used without naming the specific datasets or providing a forward reference to the experimental section or table that lists them; this reduces immediate clarity for readers assessing the scope of the superiority claim.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No major comments appear in the provided report.
Circularity Check
No significant circularity detected
full rationale
The paper's central claims rest on an empirical comparison: RaBEL tokenization and S->N->F reordering are proposed as architectural modifications that increase effective rank and align with readout, with the resulting 2M-parameter model shown to outperform baselines on tabular benchmarks. No derivation chain reduces a claimed prediction or first-principles result to its own fitted inputs by construction, nor does any load-bearing step rely on self-citation of an unverified uniqueness theorem or ansatz. The abstract and provided text present the improvements as measured outcomes rather than tautological redefinitions or statistically forced predictions. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- RBF feature count per scalar
axioms (1)
- domain assumption Reordered bidirectional attention (S->N->F) aligns computation with readout and improves cross-sample aggregation before feature mixing.
invented entities (1)
-
RaBEL tokenization
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics , pages =
Understanding the difficulty of training deep feedforward neural networks , author =. Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics , pages =. 2010 , editor =
2010
-
[3]
Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification , year=
He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian , booktitle=. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification , year=
-
[4]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[5]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[6]
Nature , volume =
Accurate predictions on small data with a tabular foundation model , author =. Nature , volume =. 2025 , doi =
2025
-
[7]
arXiv preprint arXiv:2207.01848 , year =
TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second , author =. arXiv preprint arXiv:2207.01848 , year =
-
[8]
Proceedings of the 42nd International Conference on Machine Learning (ICML) , year =
TabICL: A Tabular Foundation Model for In-Context Learning on Large Data , author =. Proceedings of the 42nd International Conference on Machine Learning (ICML) , year =
-
[9]
2016 , doi =
Chen, Tianqi and Guestrin, Carlos , booktitle =. 2016 , doi =
2016
-
[10]
Advances in Neural Information Processing Systems 30 (NeurIPS) , pages =
LightGBM: A Highly Efficient Gradient Boosting Decision Tree , author =. Advances in Neural Information Processing Systems 30 (NeurIPS) , pages =
-
[11]
Advances in neural information processing systems , volume=
CatBoost: unbiased boosting with categorical features , author=. Advances in neural information processing systems , volume=
-
[12]
arXiv preprint arXiv:2207.08815 , year =
Why Do Tree-Based Models Still Outperform Deep Learning on Tabular Data? , author =. arXiv preprint arXiv:2207.08815 , year =
-
[13]
arXiv preprint arXiv:2012.06678 , year =
TabTransformer: Tabular Data Modeling Using Contextual Embeddings , author =. arXiv preprint arXiv:2012.06678 , year =
Pith/arXiv arXiv 2012
-
[14]
Advances in Neural Information Processing Systems 34 (NeurIPS) , year =
Revisiting Deep Learning Models for Tabular Data , author =. Advances in Neural Information Processing Systems 34 (NeurIPS) , year =
-
[15]
Advances in Neural Information Processing Systems 35 (NeurIPS) , pages =
On Embeddings for Numerical Features in Tabular Deep Learning , author =. Advances in Neural Information Processing Systems 35 (NeurIPS) , pages =
-
[16]
Complex Systems , volume =
Multivariable Functional Interpolation and Adaptive Networks , author =. Complex Systems , volume =
-
[17]
Neural Computation , volume =
Universal Approximation Using Radial-Basis-Function Networks , author =. Neural Computation , volume =
-
[18]
2018 , publisher=
Learning with kernels: support vector machines, regularization, optimization, and beyond , author=. 2018 , publisher=
2018
-
[19]
2006 , publisher =
Gaussian Processes for Machine Learning , author =. 2006 , publisher =
2006
-
[20]
Advances in Neural Information Processing Systems 20 (NeurIPS) , pages =
Random Features for Large-Scale Kernel Machines , author =. Advances in Neural Information Processing Systems 20 (NeurIPS) , pages =
-
[21]
Williams, Christopher K. I. and Seeger, Matthias , booktitle =. Using the Nystr
-
[22]
arXiv preprint arXiv:2206.08564 , year =
MET: Masked Encoding for Tabular Data , author =. arXiv preprint arXiv:2206.08564 , year =
-
[23]
Advances in Neural Information Processing Systems 33 (NeurIPS) , year =
VIME: Extending the Success of Self- and Semi-Supervised Learning to Tabular Domain , author =. Advances in Neural Information Processing Systems 33 (NeurIPS) , year =
-
[24]
arXiv preprint arXiv:2509.03505 , year=
LimiX: Unleashing Structured-Data Modeling Capability for Generalist Intelligence , author=. arXiv preprint arXiv:2509.03505 , year=
-
[25]
Bayan and Goldstein, Tom , journal=
Somepalli, Gowthami and Goldblum, Micah and Schwarzschild, Avi and Bruss, C. Bayan and Goldstein, Tom , journal=
-
[26]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
TabNet: Attentive Interpretable Tabular Learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=
-
[27]
2019 , eprint=
Decoupled Weight Decay Regularization , author=. 2019 , eprint=
2019
-
[28]
Advances in neural information processing systems , volume=
Mitra: Mixed synthetic priors for enhancing tabular foundation models , author=. Advances in neural information processing systems , volume=
-
[29]
2026 , eprint=
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models , author=. 2026 , eprint=
2026
-
[30]
arXiv e-prints , pages=
A closer look at tabpfn v2: Strength, limitation, and extension , author=. arXiv e-prints , pages=
-
[31]
arXiv preprint arXiv:1708.03731 , year=
Openml benchmarking suites , author=. arXiv preprint arXiv:1708.03731 , year=
-
[32]
Advances in Neural Information Processing Systems , volume=
When do neural nets outperform boosted trees on tabular data? , author=. Advances in Neural Information Processing Systems , volume=
-
[33]
arXiv preprint arXiv:2506.16791 , year=
TabArena: A living benchmark for machine learning on tabular data , author=. arXiv preprint arXiv:2506.16791 , year=
-
[34]
AutoML Conference 2023 (Workshop) , year=
OpenML-CTR23--a curated tabular regression benchmarking suite , author=. AutoML Conference 2023 (Workshop) , year=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.