Beyond Structural Symmetries: Linear Mode Connectivity via Neuron Identifiability
Pith reviewed 2026-06-28 07:24 UTC · model grok-4.3
The pith
Neuron identifiability enables representation merging without alignment and yields linear low-loss paths even in asymmetric networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our analysis shows that neural networks can admit large families of approximately equivalent solutions even in structurally asymmetric models. We further show that neuron identifiability enables representation merging without prior alignment, and characterize when such merging admits a linear low-loss path. These findings highlight the role of effective function classes in affecting the loss landscape.
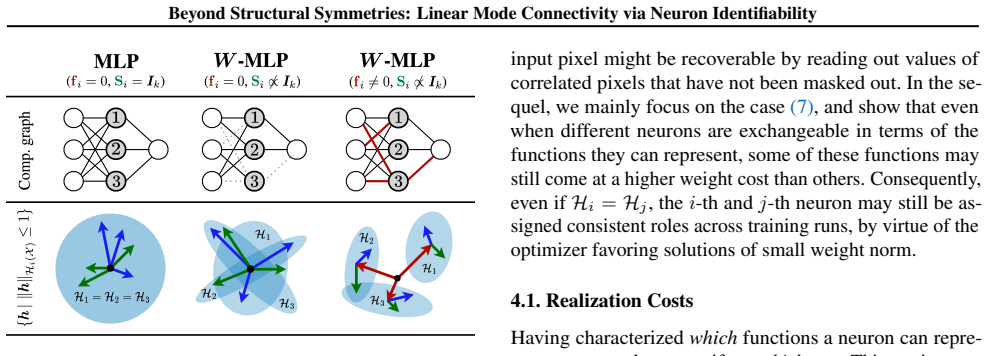
What carries the argument
Effective function classes, defined as the set of functions a neuron can realize on its input support together with the norm cost of realizing them, which is used to formalize effective symmetry breaking via neuron identifiability.
If this is right
- Structurally asymmetric models still contain large families of approximately equivalent solutions.
- Representation merging becomes possible without any prior alignment step when neurons are identifiable.
- Linear low-loss paths between merged solutions exist under conditions tied to the effective function classes.
- The loss landscape connectivity is shaped by effective function classes beyond fixed architectural symmetries.
Where Pith is reading between the lines
- Training runs may converge to solutions that differ mainly in how identifiable neurons are assigned rather than in the functions they compute.
- Techniques that rely on post-training alignment could be simplified or replaced when identifiability already holds.
- The same framework might be applied to understand connectivity after pruning or in continual learning settings where representations are reused.
Load-bearing premise
The formalization of effective function classes accurately captures the relevant interplay between parameters, data, and representations that determines practical symmetries and merging behavior.
What would settle it
An experiment or counter-example in which identifiable neurons across runs do not permit merging without alignment or in which the merged path fails to remain low-loss.
Figures

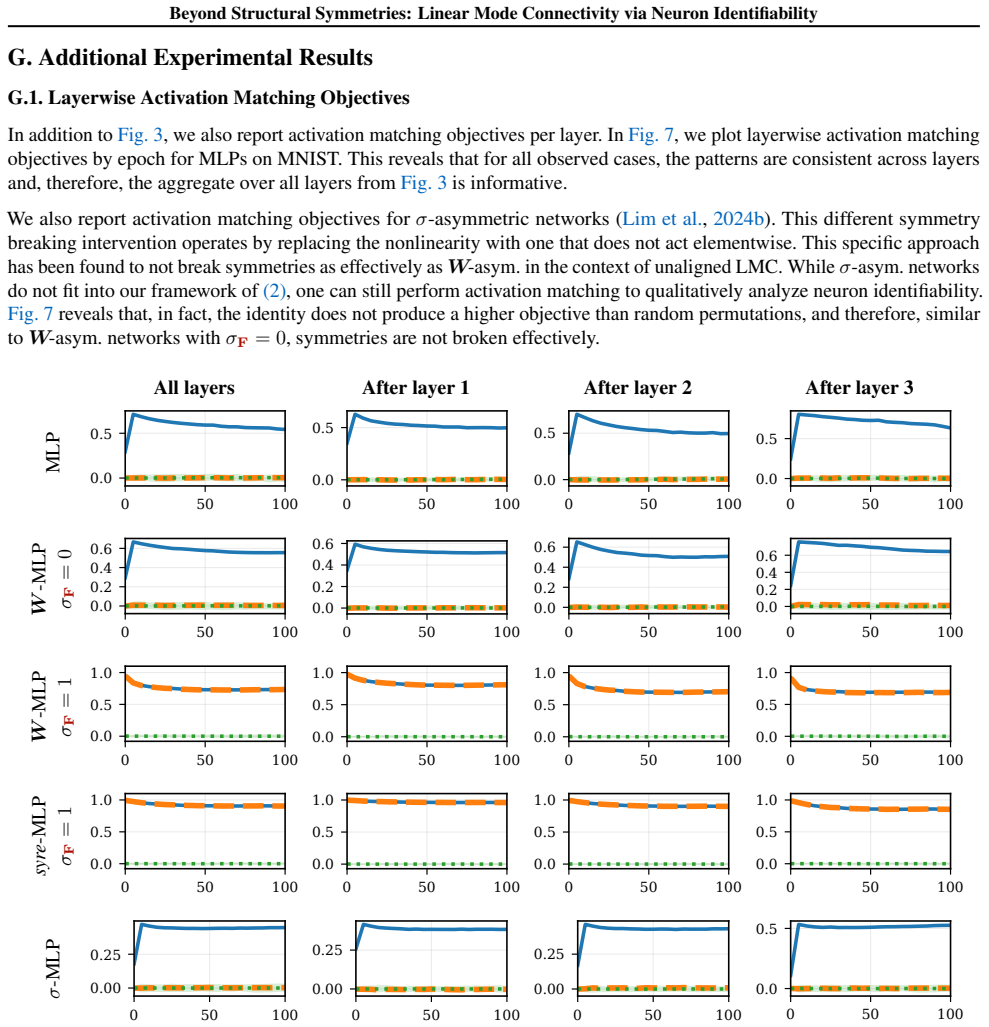
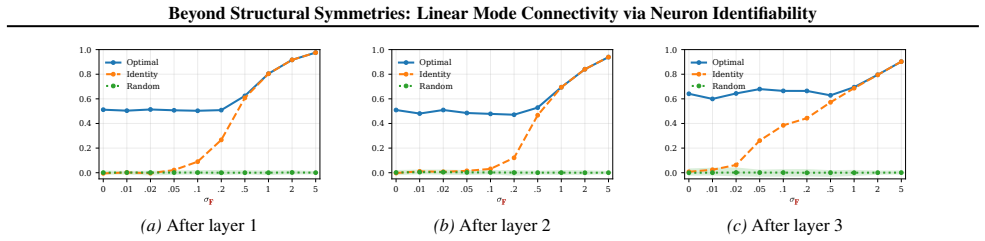
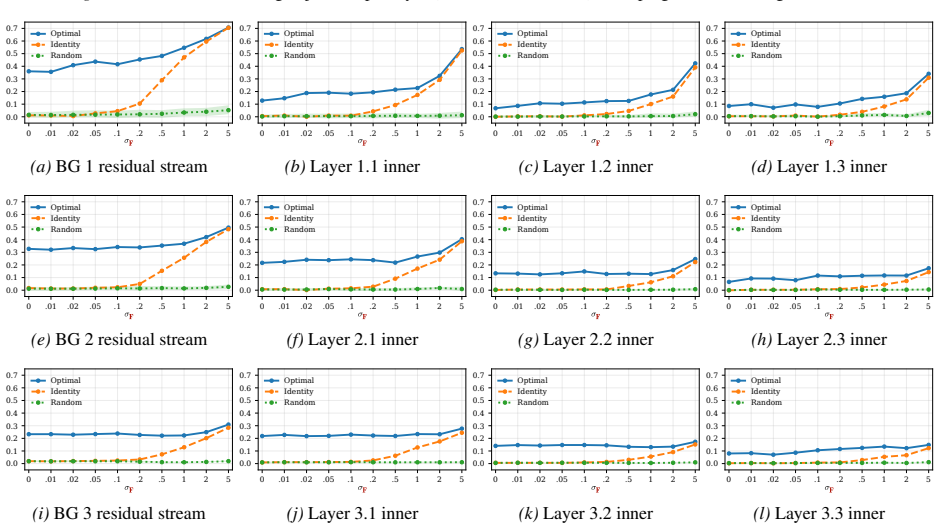
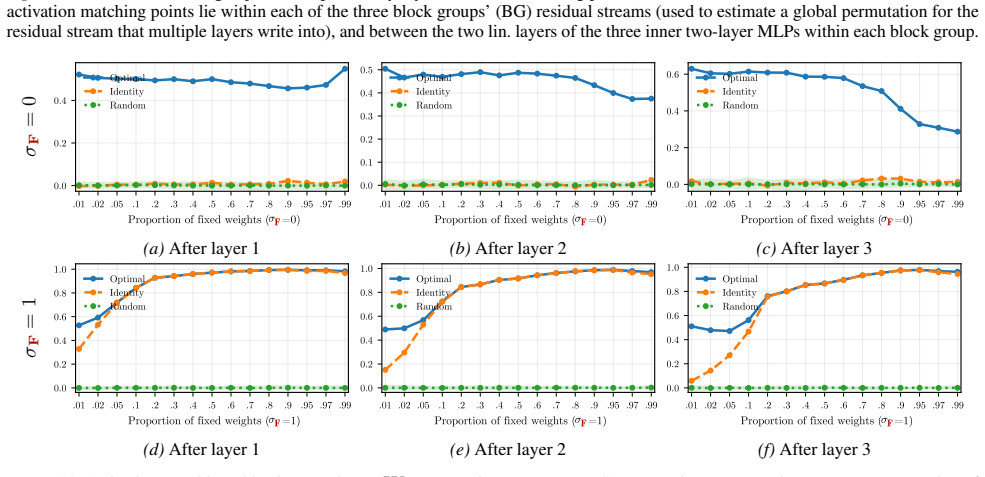

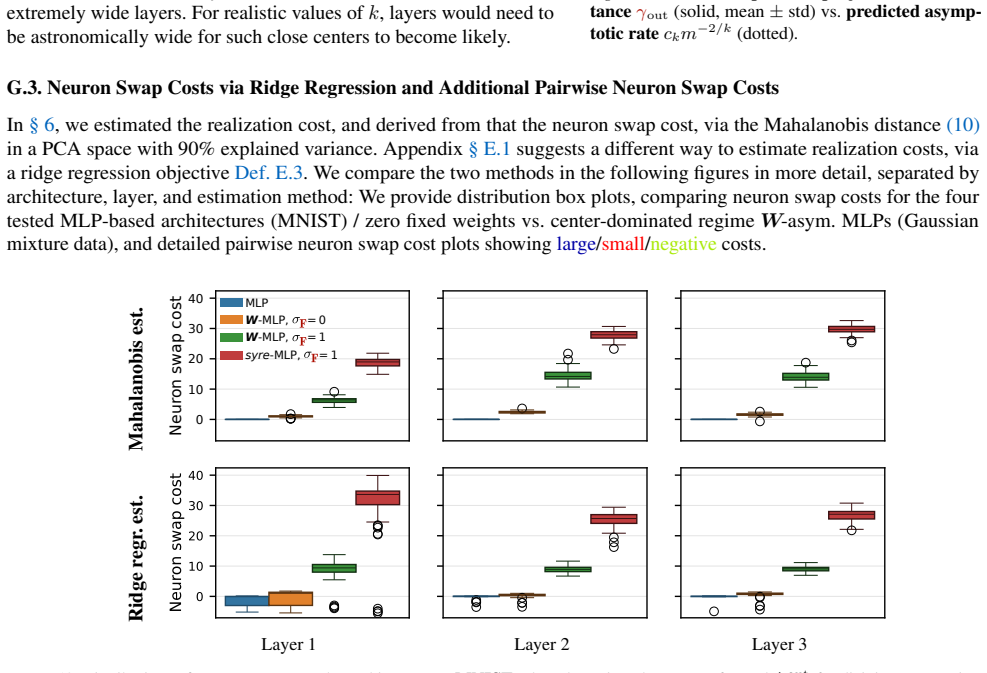
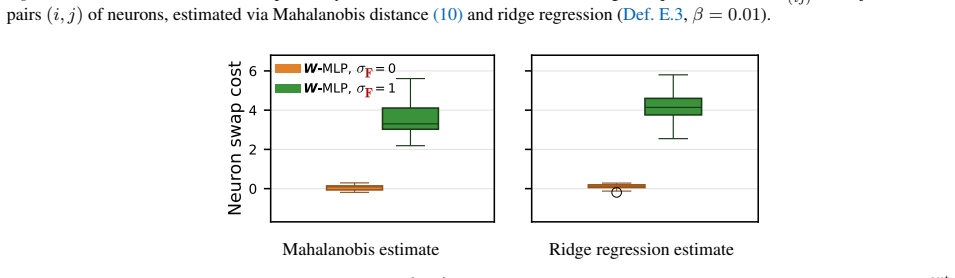
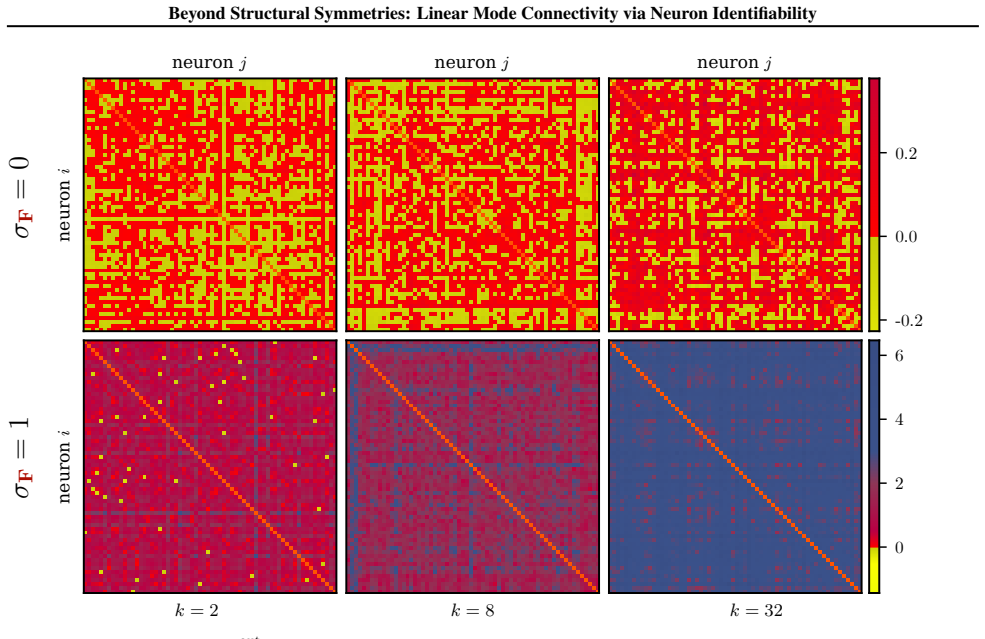
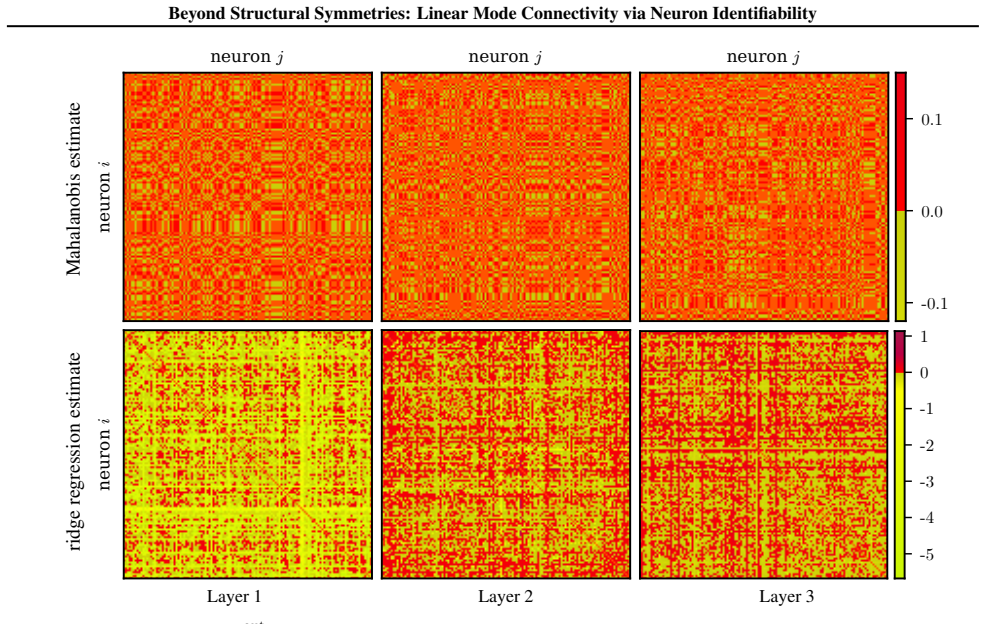
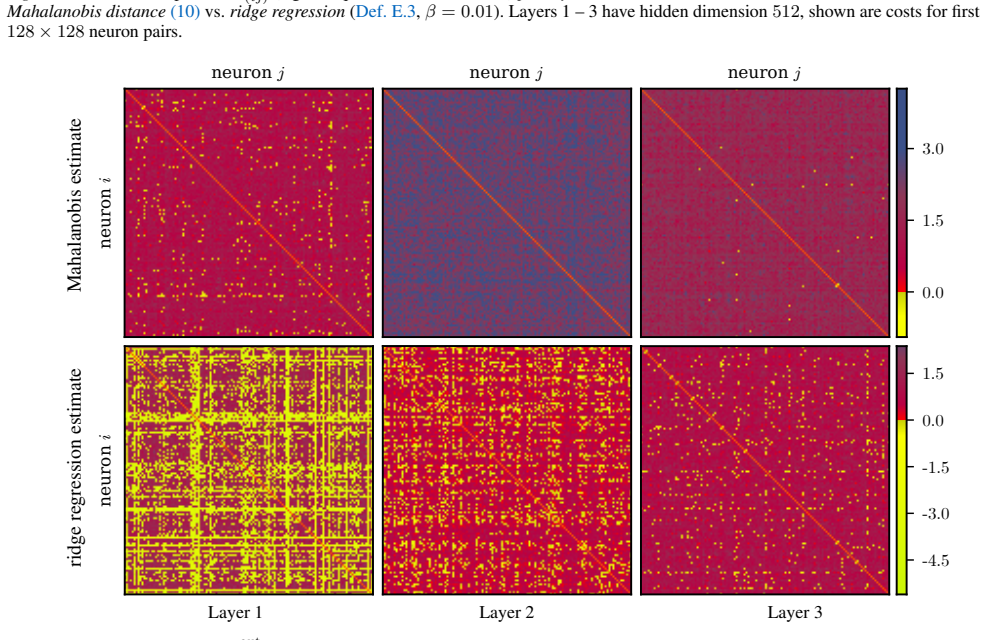




read the original abstract
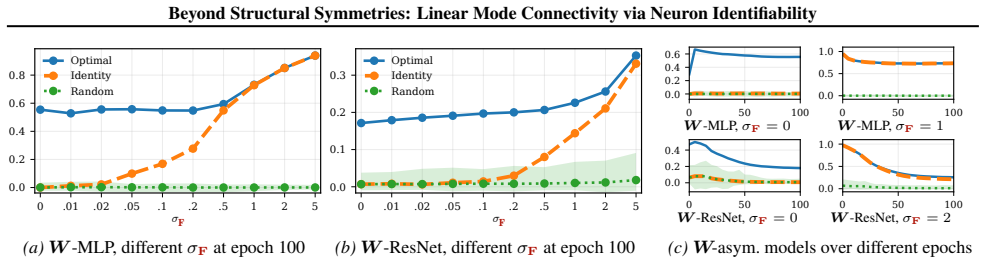
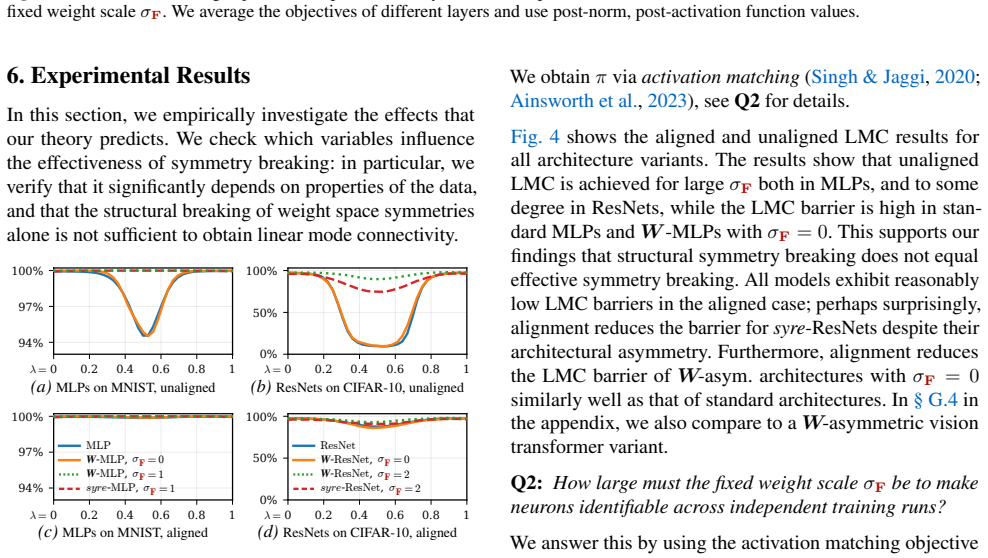
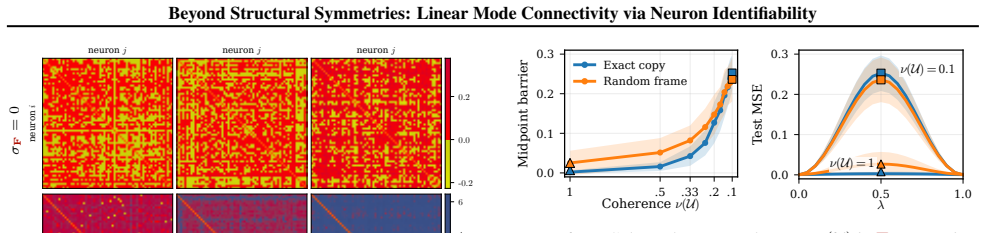
Many striking phenomena in deep learning, such as linear mode connectivity and the structured behavior of training dynamics, are closely tied to parameter symmetries: transformations that leave the realized function unchanged. Despite growing attention to parameter symmetries, the exact interplay between parameters, data, and representations remains underexplored. To investigate this, we develop a theoretical framework of effective function classes, i.e., the set of functions a neuron can realize on its input support, and the norm cost of realizing them. We then formalize effective symmetry breaking via neuron identifiability across independent training runs. Our analysis shows that neural networks can admit large families of approximately equivalent solutions even in structurally asymmetric models. We further show that neuron identifiability enables representation merging without prior alignment, and characterize when such merging admits a linear low-loss path. These findings highlight the role of effective function classes in affecting the loss landscape.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a theoretical framework centered on effective function classes—the set of functions realizable by a neuron on its input support together with the associated norm cost—to formalize neuron identifiability across independent training runs. It claims this framework reveals large families of approximately equivalent solutions even in structurally asymmetric networks, enables representation merging without prior alignment, and characterizes conditions under which such merging admits a linear low-loss path, thereby highlighting the role of effective function classes in shaping the loss landscape beyond structural symmetries.
Significance. If the central claims hold, the work provides a data- and representation-dependent lens on symmetries that could explain linear mode connectivity and model merging in settings where structural symmetries are absent. The introduction of effective function classes as an analytical tool is a conceptual contribution, though the manuscript does not appear to deliver machine-checked proofs, reproducible code, or explicit falsifiable predictions that would strengthen its impact.
major comments (2)
- [theoretical framework section] The central argument that neuron identifiability yields large families of approximately equivalent solutions and enables unaligned linear merging rests on the claim that effective function classes accurately capture the interplay between parameters, data, and representations. No derivation or counter-example verification is supplied showing that this formalization remains valid under ReLU nonlinearities or realistic data distributions that may induce higher-order interactions across neurons (see the definition and subsequent analysis of effective function classes).
- [analysis of linear paths] The characterization of when merging admits a linear low-loss path is presented as following from neuron identifiability, yet the manuscript provides no explicit test or bound demonstrating that the effective-function-class construction is independent of the specific data support or norm costs in a way that would survive perturbations to the input distribution.
minor comments (2)
- [abstract and introduction] The abstract and introduction use the term 'approximately equivalent solutions' without a precise quantitative definition (e.g., in terms of function distance or loss difference) that is later tied back to the effective-function-class norm cost.
- [theoretical framework] Notation for the effective function class and its norm cost should be introduced with an explicit equation or set notation to avoid ambiguity when the framework is applied to merging.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the presentation of our theoretical framework. We address each major comment below and indicate the corresponding revisions.
read point-by-point responses
-
Referee: [theoretical framework section] The central argument that neuron identifiability yields large families of approximately equivalent solutions and enables unaligned linear merging rests on the claim that effective function classes accurately capture the interplay between parameters, data, and representations. No derivation or counter-example verification is supplied showing that this formalization remains valid under ReLU nonlinearities or realistic data distributions that may induce higher-order interactions across neurons (see the definition and subsequent analysis of effective function classes).
Authors: We agree that explicit verification strengthens the framework. The current manuscript defines effective function classes in a manner intended to be general, but does not include a dedicated derivation for ReLU or counter-example checks against higher-order neuron interactions. In the revision we will add a subsection deriving the effective function class for ReLU neurons on finite support and include a simple counter-example illustrating robustness (or breakdown) under cross-neuron interactions. revision: yes
-
Referee: [analysis of linear paths] The characterization of when merging admits a linear low-loss path is presented as following from neuron identifiability, yet the manuscript provides no explicit test or bound demonstrating that the effective-function-class construction is independent of the specific data support or norm costs in a way that would survive perturbations to the input distribution.
Authors: The manuscript characterizes linear paths via neuron identifiability but does not supply perturbation bounds on the effective-function-class construction. We will add an explicit stability bound (in the form of a Lipschitz-style estimate) showing how changes in input distribution affect the norm cost and the resulting linear-path guarantee, together with a brief numerical illustration on a synthetic distribution shift. revision: yes
Circularity Check
No circularity: new framework definitions do not reduce claims to inputs by construction
full rationale
The provided abstract introduces 'effective function classes' as a novel theoretical construct to formalize neuron identifiability and symmetry breaking. No equations, fitted parameters, or self-citations are present that would make any 'prediction' equivalent to the inputs by definition. The claims about large families of equivalent solutions and linear merging follow from the stated framework rather than assuming the result. Per hard rules, absent any quotable reduction (self-definitional, fitted-input, or self-citation load-bearing), the derivation is treated as self-contained with score 0. Full text reference does not alter this as no circular steps are exhibitable from given material.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Parameter symmetries exist that leave the realized function unchanged.
invented entities (2)
-
effective function classes
no independent evidence
-
neuron identifiability
no independent evidence
Reference graph
Works this paper leans on
-
[1]
The Eleventh International Conference on Learning Representations , year=
Git Re-Basin: Merging Models modulo Permutation Symmetries , author=. The Eleventh International Conference on Learning Representations , year=
-
[2]
arXiv preprint arXiv:2305.03053 , year=
Zipit! merging models from different tasks without training , author=. arXiv preprint arXiv:2305.03053 , year=
-
[3]
International Mathematics Research Notices , volume=
Small Ball Probabilities for Linear Images of High-Dimensional Distributions , author=. International Mathematics Research Notices , volume=
-
[4]
Advances in Neural Information Processing Systems , volume=
On the power and limitations of random features for understanding neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[5]
Keller Jordan and Hanie Sedghi and Olga Saukh and Rahim Entezari and Behnam Neyshabur , booktitle=
-
[6]
Re-basin via implicit
Pe. Re-basin via implicit. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[7]
arXiv preprint arXiv:2002.06440 , year=
Federated learning with matched averaging , author=. arXiv preprint arXiv:2002.06440 , year=
-
[8]
Editing Models with Task Arithmetic
Editing models with task arithmetic , author=. arXiv preprint arXiv:2212.04089 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Advances in Neural Information Processing Systems , volume=
Symmetry teleportation for accelerated optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
Vershynin, Roman , year =. High-
-
[11]
The Twelfth International Conference on Learning Representations , year=
Improving Convergence and Generalization Using Parameter Symmetries , author=. The Twelfth International Conference on Learning Representations , year=
-
[12]
Advances in Neural Information Processing Systems , volume=
The empirical impact of neural parameter symmetries, or lack thereof , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
Small nonlinearities in activation functions create bad local minima in neural networks , abstract =
Yun, Chulhee and Sra, Suvrit and Jadbabaie, Ali , month = sep, year =. Small nonlinearities in activation functions create bad local minima in neural networks , abstract =
-
[14]
The Thirty Second Annual Conference on Learning Theory , year=
How do infinite width bounded norm networks look in function space? , author=. The Thirty Second Annual Conference on Learning Theory , year=
-
[15]
The Thirty Seventh Annual Conference on Learning Theory , pages=
Exact mean square linear stability analysis for SGD , author=. The Thirty Seventh Annual Conference on Learning Theory , pages=. 2024 , organization=
2024
-
[16]
Advances in Neural Information Processing Systems , volume=
Rank diminishing in deep neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
Proceedings of the National Academy of Sciences , volume=
Prevalence of neural collapse during the terminal phase of deep learning training , author=. Proceedings of the National Academy of Sciences , volume=. 2020 , publisher=
2020
-
[18]
Transactions on Machine Learning Research , issn=
The Low-Rank Simplicity Bias in Deep Networks , author=. Transactions on Machine Learning Research , issn=
-
[19]
Advances in Neural Information Processing Systems , volume=
Intrinsic dimension of data representations in deep neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
International Conference on Learning Representations , year=
The Intrinsic Dimension of Images and Its Impact on Learning , author=. International Conference on Learning Representations , year=
-
[21]
Journal of Machine Learning Research , volume=
All models are wrong, but many are useful: Learning a variable's importance by studying an entire class of prediction models simultaneously , author=. Journal of Machine Learning Research , volume=
-
[22]
Machine Learning , volume=
Parameter identifiability of a deep feedforward ReLU neural network , author=. Machine Learning , volume=. 2023 , publisher=
2023
-
[23]
European Conference on Computer Vision , pages=
Predicting is not understanding: Recognizing and addressing underspecification in machine learning , author=. European Conference on Computer Vision , pages=. 2022 , organization=
2022
-
[24]
Journal of Machine Learning Research , volume=
Underspecification presents challenges for credibility in modern machine learning , author=. Journal of Machine Learning Research , volume=
-
[25]
The Thirteenth International Conference on Learning Representations , year=
Remove Symmetries to Control Model Expressivity and Improve Optimization , author=. The Thirteenth International Conference on Learning Representations , year=
-
[26]
Weight-space symmetry in deep networks gives rise to permutation saddles, connected by equal-loss valleys across the loss landscape , author=. arXiv preprint arXiv:1907.02911 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[27]
International Conference on Machine Learning , pages=
Sharp minima can generalize for deep nets , author=. International Conference on Machine Learning , pages=. 2017 , organization=
2017
-
[28]
International Conference on Machine Learning , pages=
Deep networks on toroids: removing symmetries reveals the structure of flat regions in the landscape geometry , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[29]
International Conference on Machine Learning , pages=
Similarity of neural network representations revisited , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[30]
Deep Variational Canonical Correlation Analysis
Deep variational canonical correlation analysis , author=. arXiv preprint arXiv:1610.03454 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
NIPS workshop on bayesian deep learning , volume=
Improving the identifiability of neural networks for Bayesian inference , author=. NIPS workshop on bayesian deep learning , volume=
-
[32]
International Conference on Machine Learning , pages=
Hidden symmetries of ReLU networks , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[33]
Advances in Neural Information Processing Systems , volume=
Implicit bias of gradient descent on reparametrized models: On equivalence to mirror descent , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
Journal of Machine Learning Research , volume=
The implicit bias of gradient descent on separable data , author=. Journal of Machine Learning Research , volume=
-
[35]
International Conference on Machine Learning , pages=
Network morphism , author=. International Conference on Machine Learning , pages=. 2016 , organization=
2016
-
[36]
International Conference on Learning Representations , year=
Neural Mechanics: Symmetry and Broken Conservation Laws in Deep Learning Dynamics , author=. International Conference on Learning Representations , year=
-
[37]
International Conference on Machine Learning , pages=
Batch normalization: Accelerating deep network training by reducing internal covariate shift , author=. International Conference on Machine Learning , pages=. 2015 , organization=
2015
-
[38]
The Twelfth International Conference on Learning Representations , year=
A Symmetry-Aware Exploration of Bayesian Neural Network Posteriors , author=. The Twelfth International Conference on Learning Representations , year=
-
[39]
Ziyin, Liu and Xu, Yizhou and Poggio, Tomaso and Chuang, Isaac , month = may, year =. Parameter. doi:10.48550/arXiv.2502.05300 , abstract =
-
[40]
Song, Minhak and Ahn, Kwangjun and Yun, Chulhee , month = oct, year =. Does
-
[41]
Forty-second International Conference on Machine Learning , year=
Understanding Mode Connectivity via Parameter Space Symmetry , author=. Forty-second International Conference on Machine Learning , year=
- [42]
-
[43]
OPT 2022: Optimization for Machine Learning (NeurIPS 2022 Workshop) , year=
On convexity and linear mode connectivity in neural networks , author=. OPT 2022: Optimization for Machine Learning (NeurIPS 2022 Workshop) , year=
2022
-
[44]
International Conference on Machine Learning , pages=
On the spectral bias of neural networks , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[45]
Putterman, Theo and Lim, Derek and Gelberg, Yoav and Bronstein, Michael M and Jegelka, Stefanie and Maron, Haggai , booktitle=
-
[46]
Predicting neural network accuracy from weights
Predicting neural network accuracy from weights , author=. arXiv preprint arXiv:2002.11448 , year=
-
[47]
arXiv preprint arXiv:2002.05688 , year=
Classifying the classifier: dissecting the weight space of neural networks , author=. arXiv preprint arXiv:2002.05688 , year=
-
[48]
Advances in Neural Information Processing Systems , volume=
Hyper-representations as generative models: Sampling unseen neural network weights , author=. Advances in Neural Information Processing Systems , volume=
-
[49]
, author=
Lora: Low-rank adaptation of large language models. , author=. ICLR , volume=
-
[50]
Forty-first International Conference on Machine Learning , year=
Improved Generalization of Weight Space Networks via Augmentations , author=. Forty-first International Conference on Machine Learning , year=
-
[51]
Forty-first International Conference on Machine Learning , year=
Equivariant Deep Weight Space Alignment , author=. Forty-first International Conference on Machine Learning , year=
-
[52]
International Conference on Learning Representations , year=
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. International Conference on Learning Representations , year=
-
[53]
Zhao, Bo and Walters, Robin and Yu, Rose , month = jun, year =. Symmetry in. doi:10.48550/arXiv.2506.13018 , abstract =
-
[54]
Zamir, Guy and Dokania, Aryan and Zhao, Bo and Yu, Rose , month = apr, year =. Improving. doi:10.48550/arXiv.2504.15399 , abstract =
-
[55]
Laird, Lucas and Zhao, Bo and Yu, Rose and Walters, Robin , month = jun, year =. Data-
-
[56]
Understanding Mode Connectivity via Parameter Space Symmetry , author=
-
[57]
The Eleventh International Conference on Learning Representations , year=
Symmetries, Flat Minima, and the Conserved Quantities of Gradient Flow , author=. The Eleventh International Conference on Learning Representations , year=
-
[58]
2000 , publisher=
Functions of bounded variation and free discontinuity problems , author=. 2000 , publisher=
2000
-
[59]
, month = apr, year =
Evans, Lawrence Craig and Gariepy, Ronald F. , month = apr, year =. Measure
-
[60]
Andriushchenko, Maksym and Croce, Francesco and Müller, Maximilian and Hein, Matthias and Flammarion, Nicolas , month = jun, year =. A. doi:10.48550/arXiv.2302.07011 , abstract =
-
[61]
npj Artificial Intelligence , author =
Symmetry breaking in neural network optimization: insights from input dimension expansion , volume =. npj Artificial Intelligence , author =. 2025 , note =. doi:10.1038/s44387-025-00010-0 , abstract =
-
[62]
Structured
Rochussen, Tommy , month = may, year =. Structured
-
[63]
International Conference on Learning Representations , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations , year=
-
[64]
Weighted
Rahimi, Ali and Recht, Benjamin , year =. Weighted. Advances in
-
[65]
International Conference on Learning Representations , year=
The Role of Permutation Invariance in Linear Mode Connectivity of Neural Networks , author=. International Conference on Learning Representations , year=
-
[66]
International Conference on Machine Learning , year=
Linear Mode Connectivity and the Lottery Ticket Hypothesis , author=. International Conference on Machine Learning , year=
-
[67]
Conference on learning theory , pages=
Norm-based capacity control in neural networks , author=. Conference on learning theory , pages=. 2015 , organization=
2015
-
[68]
arXiv preprint arXiv:2007.06737 , year=
Representation transfer by optimal transport , author=. arXiv preprint arXiv:2007.06737 , year=
-
[69]
Advances in Neural Information Processing Systems , volume=
Learning to learn by gradient descent by gradient descent , author=. Advances in Neural Information Processing Systems , volume=
-
[70]
Advances in Neural Information Processing Systems , volume=
What is being transferred in transfer learning? , author=. Advances in Neural Information Processing Systems , volume=
-
[71]
Advances in Neural Information Processing Systems , volume=
A Tale of Two Symmetries: Exploring the Loss Landscape of Equivariant Models , author=. Advances in Neural Information Processing Systems , volume=
-
[72]
Advances in Neural Information Processing Systems , volume=
Model fusion via optimal transport , author=. Advances in Neural Information Processing Systems , volume=
-
[73]
The Twelfth International Conference on Learning Representations , year=
Graph Metanetworks for Processing Diverse Neural Architectures , author=. The Twelfth International Conference on Learning Representations , year=
-
[74]
Advances in Neural Information Processing Systems , volume=
Explaining landscape connectivity of low-cost solutions for multilayer nets , author=. Advances in Neural Information Processing Systems , volume=
-
[75]
L2 Regularization versus Batch and Weight Normalization
L2 regularization versus batch and weight normalization , author=. arXiv preprint arXiv:1706.05350 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[76]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Generalized Linear Mode Connectivity for Transformers , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[77]
Advances in Neural Information Processing Systems , volume=
Neural functional transformers , author=. Advances in Neural Information Processing Systems , volume=
-
[78]
arXiv preprint arXiv:2310.17513 , year=
The expressive power of low-rank adaptation , author=. arXiv preprint arXiv:2310.17513 , year=
-
[79]
Advanced Neural Computers , pages=
On the algebraic structure of feedforward network weight spaces , author=. Advanced Neural Computers , pages=. 1990 , publisher=
1990
-
[80]
The Thirteenth International Conference on Learning Representations , year=
Deep Linear Probe Generators for Weight Space Learning , author=. The Thirteenth International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.