FLAGG: Flexible Autoregressive Graph Generation
Pith reviewed 2026-06-28 07:20 UTC · model grok-4.3
The pith
FLAGG converts any one-shot graph generator into an autoregressive model by learning to reverse a stochastic node removal process.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
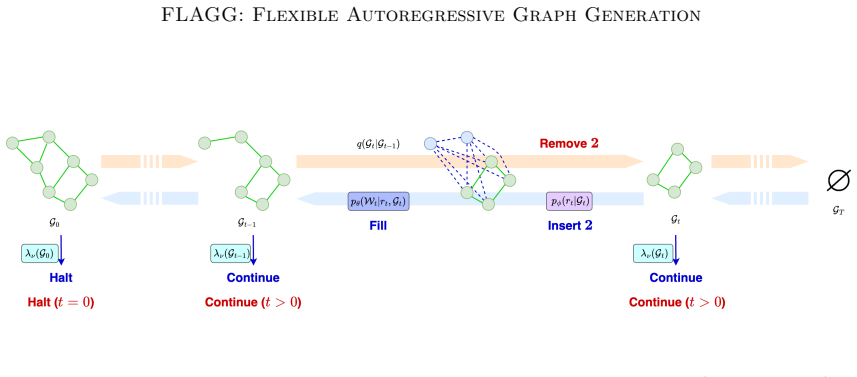
FLAGG sequentially generates portions of graphs with one-shot models by specifying the generation policy through a stochastic node removal process that an Insertion Model learns to reverse, which allows any one-shot model to become autoregressive and produces higher sampling quality than one-shot or autoregressive baselines on datasets spanning different graph sizes and domains.
What carries the argument
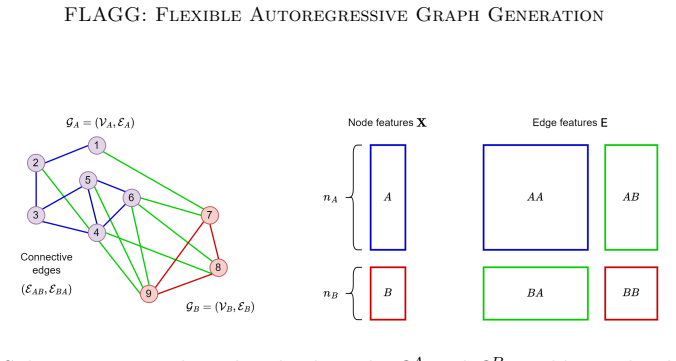
The Insertion Model that learns to reverse a chosen stochastic node removal process, thereby turning a one-shot generator into a sequential one.
Load-bearing premise
A stochastic node removal process exists such that an Insertion Model can reliably learn to reverse it, enabling any one-shot model to become autoregressive while preserving generation quality across graph domains and sizes.
What would settle it
On a new graph dataset the FLAGG version of a one-shot model would need to show lower sampling quality than both the unmodified one-shot model and standard autoregressive baselines.
Figures
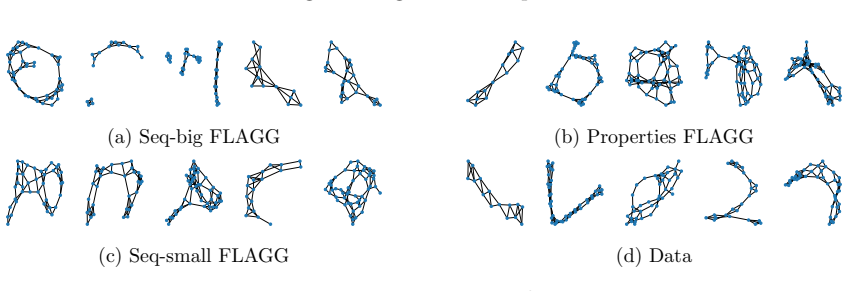

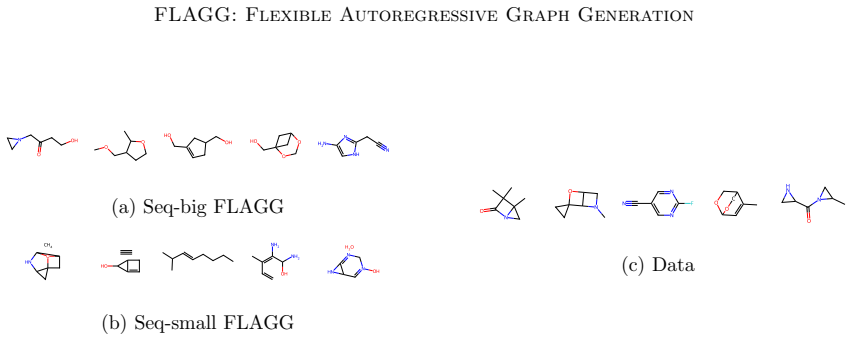

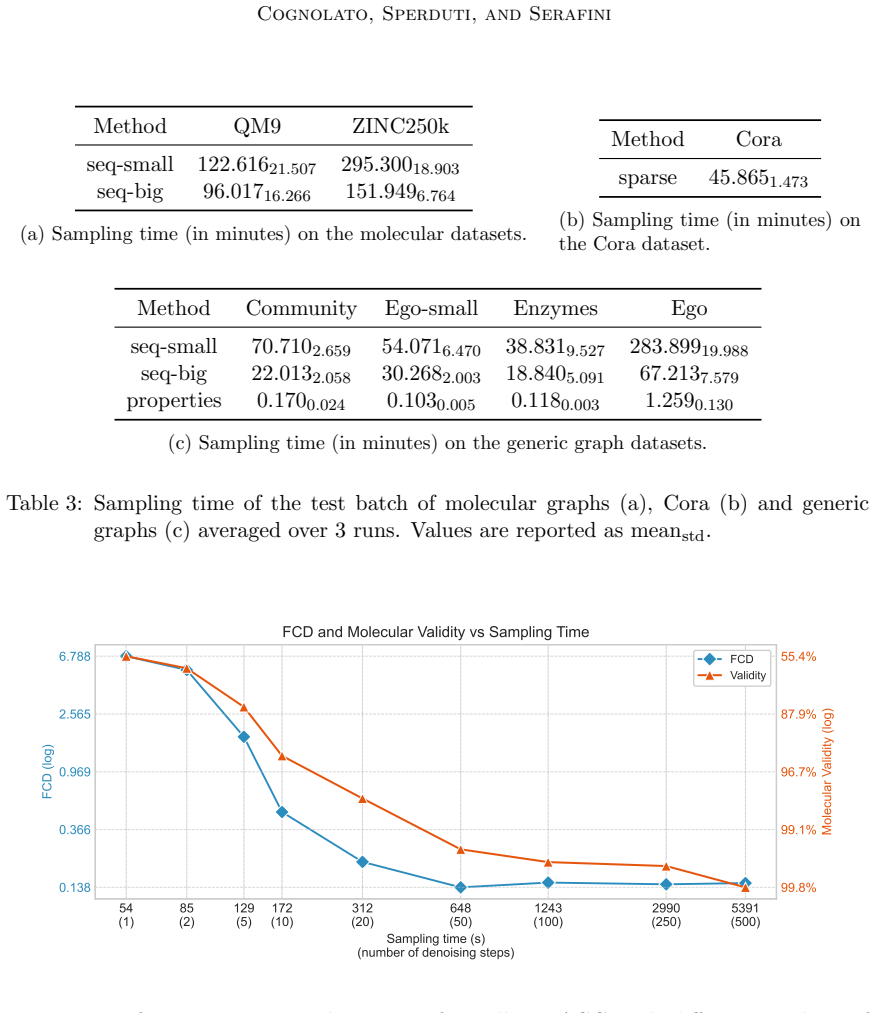



read the original abstract
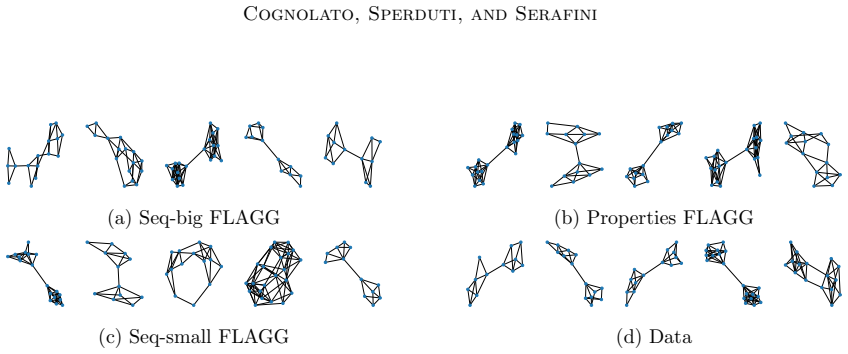
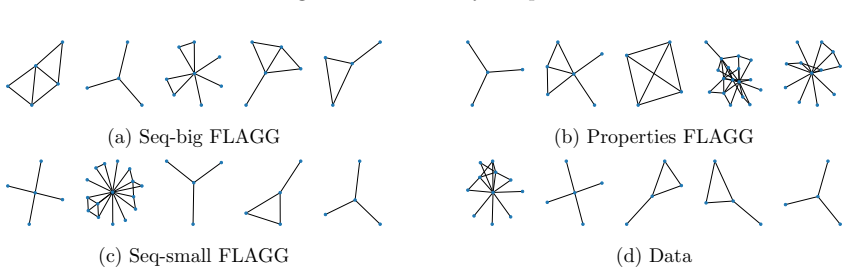
The Deep Graph Generation's panorama spans two extremes: one-shot and sequential models. The former generates nodes and edges jointly, while the latter samples them autoregressively. Each method performs better in different graph domains depending on size and topology, but neither is applicable to all graph categories. For instance, one-shot methods struggle with generating large graphs, while sequential methods underperform on smaller graphs. A possible way to overcome these limitations is to flexibly combine the two methods in a unique system. In this work, we propose the FLAGG (Flexible Autoregressive Graph Generation) framework, which sequentially generates portions of graphs with one-shot models. FLAGG can apply any one-shot model to make it autoregressive, allowing flexibility in choosing the sequential policy. This policy is specified through a stochastic node removal process, which an Insertion Model learns to reverse. We evaluate FLAGG with the DiGress one-shot model on several data sets of different graph sizes and domains. We show that the approach outperforms both one-shot and autoregressive baselines in terms of sampling quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the FLAGG framework, which converts any one-shot graph generation model into an autoregressive generator by learning to reverse a user-specified stochastic node removal process via a separate Insertion Model. The approach is evaluated by applying it to the DiGress one-shot model on multiple graph datasets spanning different sizes and domains; the central empirical claim is that the resulting sequential generator outperforms both the original one-shot model and existing autoregressive baselines in sampling quality.
Significance. If the reported outperformance is confirmed with fixed removal/insertion policies and standard controls for implementation details, the work would provide a practical, modular bridge between one-shot and sequential paradigms. This flexibility in choosing the sequential policy could improve applicability across graph scales and topologies where neither extreme currently dominates.
minor comments (2)
- [Abstract] The abstract states that FLAGG 'outperforms both one-shot and autoregressive baselines' but does not name the specific metrics (e.g., MMD, validity, uniqueness), the exact datasets, or the number of runs; these details are needed to assess whether the comparison is load-bearing.
- The description of the stochastic node removal process and the Insertion Model's training objective should be expanded with pseudocode or a short algorithmic outline to make the reversal mechanism reproducible from the text alone.
Simulated Author's Rebuttal
We thank the referee for their constructive review and recommendation of minor revision. The report provides a clear summary of our contribution but does not enumerate any specific major comments requiring point-by-point rebuttal.
Circularity Check
No significant circularity
full rationale
The paper is an empirical proposal of the FLAGG framework that converts one-shot models to autoregressive ones via a learned reversal of a stochastic node removal process. No equations, fitted parameters, or derivations are presented that reduce the central claim to a self-definition, renamed input, or self-citation chain. The load-bearing content consists of direct experimental comparisons against baselines on multiple datasets, which are externally falsifiable and do not rely on internal circular reductions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Learning on Graphs Conference , pages=
A survey on deep graph generation: Methods and applications , author=. Learning on Graphs Conference , pages=. 2022 , organization=
2022
-
[2]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
A systematic survey on deep generative models for graph generation , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2022 , publisher=
2022
-
[3]
First Berkeley Symposium on Mathematical Statistics and Probability , year = 1949, month = jan, pages =
On the Theory of Stochastic Processes, with Particular Reference to Applications. First Berkeley Symposium on Mathematical Statistics and Probability , year = 1949, month = jan, pages =
1949
-
[4]
International Conference on Machine Learning , pages=
Deep unsupervised learning using nonequilibrium thermodynamics , author=. International Conference on Machine Learning , pages=. 2015 , organization=
2015
-
[5]
Advances in Neural Information Processing Systems , volume=
Denoising diffusion probabilistic models , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
International Conference on Learning Representations , year=
Score-Based Generative Modeling through Stochastic Differential Equations , author=. International Conference on Learning Representations , year=
-
[7]
International Conference on Learning Representations , year=
Flow Matching for Generative Modeling , author=. International Conference on Learning Representations , year=
-
[8]
International Conference on Machine Learning , pages=
Improved denoising diffusion probabilistic models , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[9]
Advances in Neural Information Processing Systems , volume=
Structured denoising diffusion models in discrete state-spaces , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
International Conference on Learning Representations , year=
DiGress: Discrete Denoising diffusion for graph generation , author=. International Conference on Learning Representations , year=
-
[11]
International Conference on Machine Learning , pages=
Efficient and Degree-Guided Graph Generation via Discrete Diffusion Modeling , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[12]
International Conference on Machine Learning , pages=
Junction tree variational autoencoder for molecular graph generation , author=. International Conference on Machine Learning , pages=. 2018 , organization=
2018
-
[13]
International Conference on Machine Learning , pages=
Graphrnn: Generating realistic graphs with deep auto-regressive models , author=. International Conference on Machine Learning , pages=. 2018 , organization=
2018
-
[14]
Advances in Neural Information Processing Systems , volume=
Efficient graph generation with graph recurrent attention networks , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
International Conference on Machine Learning , pages=
Order Matters: Probabilistic Modeling of Node Sequence for Graph Generation , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[16]
International Conference on Learning Representations , year=
GraphAF: a Flow-based Autoregressive Model for Molecular Graph Generation , author=. International Conference on Learning Representations , year=
-
[17]
International Conference on Machine Learning , pages=
Graphdf: A discrete flow model for molecular graph generation , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[18]
Journal of Machine Learning Research , volume=
Fitting Autoregressive Graph Generative Models through Maximum Likelihood Estimation , author=. Journal of Machine Learning Research , volume=
-
[19]
International Conference on Machine Learning , pages=
Autoregressive diffusion model for graph generation , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[20]
International Conference on Machine Learning , pages=
Scalable deep generative modeling for sparse graphs , author=. International Conference on Machine Learning , pages=. 2020 , organization=
2020
-
[21]
arXiv preprint arXiv:1611.07308 , year=
Variational graph auto-encoders , author=. arXiv preprint arXiv:1611.07308 , year=
-
[22]
Graphvae: Towards generation of small graphs using variational autoencoders , author=. Artificial Neural Networks and Machine Learning--ICANN 2018: 27th International Conference on Artificial Neural Networks, Rhodes, Greece, October 4-7, 2018, Proceedings, Part I 27 , pages=. 2018 , organization=
2018
-
[23]
ICML 2018 workshop on Theoretical Foundations and Applications of Deep Generative Models , year=
MolGAN: An implicit generative model for small molecular graphs , author=. ICML 2018 workshop on Theoretical Foundations and Applications of Deep Generative Models , year=
2018
-
[24]
International Conference on Machine Learning , pages=
Spectre: Spectral conditioning helps to overcome the expressivity limits of one-shot graph generators , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[25]
Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
Moflow: an invertible flow model for generating molecular graphs , author=. Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
-
[26]
International Conference on Artificial Intelligence and Statistics , pages=
Permutation invariant graph generation via score-based generative modeling , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2020 , organization=
2020
-
[27]
Meng Liu and Keqiang Yan and Bora Oztekin and Shuiwang Ji , booktitle=. Graph
-
[28]
International Conference on Machine Learning , pages=
Score-based generative modeling of graphs via the system of stochastic differential equations , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[29]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Conditional diffusion based on discrete graph structures for molecular graph generation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[30]
Size Matters: Large Graph Generation with Hi
Alex Owen Davies and Nirav Ajmeri and Telmo M Silva Filho , booktitle=. Size Matters: Large Graph Generation with Hi
-
[31]
International Conference on Machine Learning , year=
Editing Partially Observable Networks via Graph Diffusion Models , author=. International Conference on Machine Learning , year=
-
[32]
International Conference on Learning Representations , year=
Efficient and Scalable Graph Generation through Iterative Local Expansion , author=. International Conference on Learning Representations , year=
-
[33]
European Conference on Artificial Intelligence , pages=
SaGess: A Sampling Graph Denoising Diffusion Model for Scalable Graph Generation , author=. European Conference on Artificial Intelligence , pages=. 2024 , publisher=
2024
-
[34]
arXiv preprint arXiv:2403.01535 , year=
Neural graph generator: Feature-conditioned graph generation using latent diffusion models , author=. arXiv preprint arXiv:2403.01535 , year=
-
[35]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Generative Modelling of Structurally Constrained Graphs , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[36]
Wright, J. W. , title =. 1975 , issue_date =. doi:10.1145/321864.321874 , journal =
-
[37]
International Conference on Machine Learning , pages =
Welling, Max and Teh, Yee Whye , title =. International Conference on Machine Learning , pages =. 2011 , isbn =
2011
-
[38]
ICML 2021 Workshop on Automated Machine Learning (AutoML) , year=
PonderNet: Learning to Ponder , author=. ICML 2021 Workshop on Automated Machine Learning (AutoML) , year=
2021
-
[39]
Vincent D Blondel and Jean-Loup Guillaume and Renaud Lambiotte and Etienne Lefebvre , title =. 2008 , month =. doi:10.1088/1742-5468/2008/10/P10008 , url =
-
[40]
Proceedings of the AAAI conference on artificial intelligence , volume=
Weisfeiler and leman go neural: Higher-order graph neural networks , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[41]
The Semantic Web: 15th International Conference, ESWC 2018, Heraklion, Crete, Greece, June 3--7, 2018, Proceedings 15 , pages=
Modeling relational data with graph convolutional networks , author=. The Semantic Web: 15th International Conference, ESWC 2018, Heraklion, Crete, Greece, June 3--7, 2018, Proceedings 15 , pages=. 2018 , organization=
2018
-
[42]
arXiv preprint arXiv:2012.09699 , year=
A generalization of transformer networks to graphs , author=. arXiv preprint arXiv:2012.09699 , year=
arXiv 2012
-
[43]
Scientific data , volume=
Quantum chemistry structures and properties of 134 kilo molecules , author=. Scientific data , volume=. 2014 , publisher=
2014
-
[44]
Journal of chemical information and modeling , volume=
ZINC: a free tool to discover chemistry for biology , author=. Journal of chemical information and modeling , volume=. 2012 , publisher=
2012
-
[45]
On the evolution of random graphs , author=. Publ. math. inst. hung. acad. sci , volume=
-
[46]
Reviews of modern physics , volume=
Statistical mechanics of complex networks , author=. Reviews of modern physics , volume=. 2002 , publisher=
2002
-
[47]
AI magazine , volume=
Collective classification in network data , author=. AI magazine , volume=
-
[48]
Nucleic acids research , volume=
BRENDA, the enzyme database: updates and major new developments , author=. Nucleic acids research , volume=. 2004 , publisher=
2004
-
[49]
Sen, Prithviraj and Namata, Galileo and Bilgic, Mustafa and Getoor, Lise and Gallagher, Brian and Eliassi-Rad, Tina , title =. AI Magazine , volume =. doi:https://doi.org/10.1609/aimag.v29i3.2157 , year =
-
[50]
International Conference on Learning Representations , year=
On Evaluation Metrics for Graph Generative Models , author=. International Conference on Learning Representations , year=
-
[51]
Scalfani and guillaume godin and Axel Pahl and Francois Berenger and JLVarjo and strets123 and JP and DoliathGavid , howpublished =
Greg Landrum and Paolo Tosco and Brian Kelley and Ric and sriniker and gedeck and Riccardo Vianello and NadineSchneider and David Cosgrove and Eisuke Kawashima and Andrew Dalke and Dan N and Gareth Jones and Brian Cole and Matt Swain and Samo Turk and AlexanderSavelyev and Alain Vaucher and Maciej Wójcikowski and Ichiru Take and Daniel Probst and Kazuya U...
-
[52]
Advances in Neural Information Processing Systems , volume=
Pytorch: An imperative style, high-performance deep learning library , author=. Advances in Neural Information Processing Systems , volume=
-
[53]
doi:10.5281/zenodo.3828935 , license =
Falcon, William and. doi:10.5281/zenodo.3828935 , license =
-
[54]
, booktitle=
Fey, Matthias and Lenssen, Jan E. , booktitle=. Fast Graph Representation Learning with
-
[55]
2019 , url =
Omry Yadan , title =. 2019 , url =
2019
-
[56]
European Conference on Artificial Intelligence , pages=
IFH: a diffusion framework for flexible design of graph generative models , author=. European Conference on Artificial Intelligence , pages=. 2024 , publisher=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.