Synthics: Synthetic Physics-like Datasets for Machine Learning
Pith reviewed 2026-06-28 02:07 UTC · model grok-4.3
The pith
A Bayesian probabilistic context-free grammar generates synthetic physics-like regression datasets that match real equations on all eight structural features and enable equivalent hyperparameter tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a Bayesian probabilistic context-free grammar fitted to the Feynman equation corpus can sample novel equations whose eight measured structural properties match the corpus distribution, whereas an unsmoothed probabilistic grammar matches only two of them. When these synthetic equations are paired with inputs drawn from recovered applicability domains, the resulting regression datasets allow a gradient-boosted regressor to select, on average, the sixth-best hyperparameter configuration out of twenty when tested on real data, matching the result obtained by tuning directly on real data and beating both random expression trees and pure noise.
What carries the argument
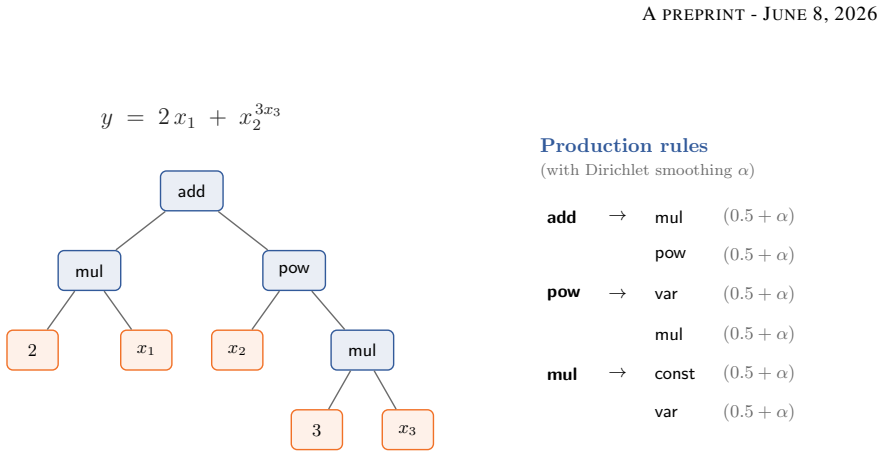
Bayesian Probabilistic Context-Free Grammar that encodes the algebraic structure of the equation corpus through a prior and is used both to sample new equations and to characterise their applicability domains.
If this is right
- The Bayesian prior is required to achieve structural fidelity when the training corpus is limited in size.
- Synthetic datasets produced this way can substitute for real data in hyperparameter tuning without loss of downstream performance.
- Non-intrusive probing recovers both the applicability domain and inter-variable constraints for each generated equation.
- The generated data substantially outperforms both random expression trees and unstructured noise in the same tuning task.
Where Pith is reading between the lines
- The same grammar-based generation pipeline could be applied to equation corpora from chemistry or biology to create synthetic data for those fields.
- Further validation on additional model families such as neural networks or support-vector machines would test whether the equivalence generalises beyond gradient boosting.
- The recovered applicability domains might be reused to generate data that respects physical units or conservation laws not explicitly present in the grammar.
- One could measure whether equations sampled from the grammar obey additional invariants such as dimensional consistency that were not part of the original eight structural features.
Load-bearing premise
That agreement on eight structural features plus matching performance in one hyperparameter-tuning task is enough to guarantee the synthetic data will be useful for other machine learning models and other physics domains.
What would settle it
Repeat the hyperparameter-tuning experiment with a neural-network regressor instead of gradient boosting and check whether the synthetic-data tuning still selects configurations whose test performance on real data matches that of real-data tuning.
Figures





read the original abstract
Representative data is fundamental in machine learning, as limited data hinders generalisation. Collecting sufficient real-world samples is often infeasible. Synthetic data generation offers a practical solution, but only if the generated data faithfully reflects the structure of real observations. In this paper, a method for generating synthetic regression datasets that structurally resemble physics equations from a given equation corpus is presented. The approach uses a Bayesian Probabilistic Context-Free Grammar to capture the underlying algebraic structure of the corpus, from which novel equations are sampled. To ensure the generated inputs lie within a physically meaningful domain, the applicability domain is characterised for each equation through non-intrusive probing, also recovering inter-variable constraints. Input sampling further mimics realistic experimental conditions by drawing from random sub-ranges of the valid domain with mixed uniform and truncated normal distributions. The generated data is statistically validated against the Feynman equation corpus using Kolmogorov-Smirnov tests. The generated equations match the corpus on all of the eight studied structural features, compared to only two for an unsmoothed purely probabilistic grammar, demonstrating that the Bayesian prior is essential for structural fidelity given the size of the corpus. In a downstream hyperparameter-tuning task, a gradient-boosted regressor tuned on the synthetic data picks, on average, the 6th-best configuration out of 20 on real data, matching the result of tuning on real data itself and substantially outperforming random expression trees (10th) and noise (19th).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Synthics, a method that trains a Bayesian probabilistic context-free grammar on the Feynman equation corpus to sample novel equations, then generates regression datasets by probing applicability domains and sampling inputs from mixed uniform/truncated-normal distributions over sub-ranges. It reports that the synthetic equations match the corpus on all eight structural features via Kolmogorov-Smirnov tests (versus only two features for an unsmoothed baseline grammar) and that hyperparameter tuning of a gradient-boosted regressor on the synthetic data yields the same average rank (6th of 20) on real data as tuning directly on real data.
Significance. If the structural-matching and downstream-equivalence results hold under fuller verification, the work supplies a concrete route to large-scale synthetic regression data that preserves algebraic structure from a physics corpus, which could mitigate data scarcity in scientific ML. The explicit demonstration that the Bayesian prior is required for fidelity (via the baseline comparison) and the reproducible downstream task are strengths that could be cited by follow-on studies.
major comments (3)
- [§5.2] §5.2 (downstream experiment): equivalence is shown only for hyperparameter tuning of gradient-boosted regressors on a single real dataset; this single-task, single-model result is load-bearing for the claim that synthetic data has 'utility matching real data in downstream ML use,' yet no transfer experiments to other tasks (e.g., symbolic regression) or model families are reported.
- [§4.1–4.2] §4.1–4.2 (structural validation): the eight features and the exact KS-test procedure (including sample sizes, multiple-testing correction, and power analysis) are not detailed enough to confirm that 'match on all eight' is robust rather than an artifact of feature selection or low statistical power; this directly supports the central claim that the Bayesian prior is 'essential for structural fidelity.'
- [§3.3] §3.3 (applicability-domain probing): the non-intrusive probing and inter-variable constraint recovery are validated only indirectly through the same narrow downstream result; no direct ablation or sensitivity check on the probing step is provided, leaving open whether domain characterization errors propagate into the reported equivalence.
minor comments (2)
- The definition of the eight structural features should be moved from the appendix to the main text or given an explicit table for reader accessibility.
- Notation for the Bayesian prior hyperparameters (free parameters listed in the axiom ledger) is introduced without a consolidated table; a single reference table would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. We address each major comment below with clarifications from the manuscript and indicate where revisions will be made to improve clarity and robustness without altering the core claims or results.
read point-by-point responses
-
Referee: [§5.2] §5.2 (downstream experiment): equivalence is shown only for hyperparameter tuning of gradient-boosted regressors on a single real dataset; this single-task, single-model result is load-bearing for the claim that synthetic data has 'utility matching real data in downstream ML use,' yet no transfer experiments to other tasks (e.g., symbolic regression) or model families are reported.
Authors: The downstream experiment in §5.2 is explicitly framed as a targeted demonstration of utility for hyperparameter tuning of gradient-boosted regressors, using the average rank (6th of 20) on real data as the metric. This matches the performance of tuning directly on real data and outperforms the baselines (random trees at 10th, noise at 19th). While we agree the result is narrow, it directly supports the paper's claim of 'utility matching real data in downstream ML use' within the regression setting studied. We will revise the discussion in §5.2 and the conclusion to explicitly qualify the scope as an initial validation on this task and model family, and note that broader transfer (e.g., to symbolic regression) remains future work. No new experiments are added at this stage. revision: partial
-
Referee: [§4.1–4.2] §4.1–4.2 (structural validation): the eight features and the exact KS-test procedure (including sample sizes, multiple-testing correction, and power analysis) are not detailed enough to confirm that 'match on all eight' is robust rather than an artifact of feature selection or low statistical power; this directly supports the central claim that the Bayesian prior is 'essential for structural fidelity.'
Authors: Section 4.1 defines the eight structural features (number of operators, constants, variables, etc.) drawn from the Feynman corpus analysis. Section 4.2 reports KS tests showing matches on all eight for the Bayesian PCFG versus only two for the unsmoothed baseline. We will expand §4.2 to include: (i) explicit sample sizes used for the KS tests (number of sampled equations), (ii) confirmation that no multiple-testing correction was applied because the features are treated as separate univariate comparisons, and (iii) a brief power discussion based on the observed effect sizes. These additions will be made from the existing experimental logs without changing the reported outcomes. revision: yes
-
Referee: [§3.3] §3.3 (applicability-domain probing): the non-intrusive probing and inter-variable constraint recovery are validated only indirectly through the same narrow downstream result; no direct ablation or sensitivity check on the probing step is provided, leaving open whether domain characterization errors propagate into the reported equivalence.
Authors: The applicability-domain probing in §3.3 is a core methodological step that enables physically meaningful input sampling; its correctness is supported by the subsequent structural fidelity (all eight features matched) and the downstream equivalence. We acknowledge the validation is indirect. We will add a short paragraph in §3.3 and §4 discussing the probing's role and why direct ablation was not performed (computational cost of repeated domain characterization), while noting that errors would have manifested in the KS mismatches or degraded downstream ranks—which were not observed. This clarifies rather than expands the experiments. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper's core derivation fits a Bayesian PCFG to the Feynman corpus to sample new equations, then validates structural fidelity via KS tests on eight features (showing superiority to an unsmoothed baseline) and utility via a downstream hyperparameter-tuning task on real data. These steps rely on external corpus statistics, baseline comparison, and real-data performance rather than any self-definitional reduction, fitted parameter renamed as prediction, or load-bearing self-citation chain. The Bayesian prior's role is demonstrated empirically against the baseline, not assumed by construction. No ansatzes, uniqueness theorems, or renamings of known results appear as load-bearing elements. The chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Bayesian prior hyperparameters
axioms (1)
- domain assumption A probabilistic context-free grammar can adequately capture the algebraic structure of equations in the Feynman corpus.
Reference graph
Works this paper leans on
-
[1]
Accurate predictions on small data with a tabular foundation model.Nature, 637 (8045):319–326, 2025
Noah Hollmann, Samuel Müller, Lennart Purucker, Arjun Krishnakumar, Max Körfer, Shi Bin Hoo, Robin Tibor Schirrmeister, and Frank Hutter. Accurate predictions on small data with a tabular foundation model.Nature, 637 (8045):319–326, 2025
2025
-
[2]
Laith Alzubaidi, Jinshuai Bai, Aiman Al-Sabaawi, Jose Santamaría, A. S. Albahri, Bashar Sami Nayyef Al- dabbagh, Mohammed A. Fadhel, Mohamed Manoufali, Jinglan Zhang, Ali H. Al-Timemy, Ye Duan, Amjed Abdullah, Laith Farhan, Yi Lu, Ashish Gupta, Felix Albu, Amin Abbosh, and Yuantong Gu. A survey on deep learning tools dealing with data scarcity: definition...
2023
-
[3]
Mandeep Goyal and Qusay H. Mahmoud. A systematic review of synthetic data generation techniques using generative AI.Electronics, 13(17):3509, 2024
2024
-
[4]
How useful is synthetic data in developing predictive models for health?Studies in Health Technology and Informatics, 2025
Mohammad Ahmed Basri and Helen Chen. How useful is synthetic data in developing predictive models for health?Studies in Health Technology and Informatics, 2025
2025
-
[5]
Training deep networks with synthetic data: Bridging the reality gap by domain randomization
Jonathan Tremblay, Aayush Prakash, David Acuna, Mark Brophy, Varun Jampani, Cem Anil, Thang To, Eric Cameracci, Shaad Boochoon, and Stan Birchfield. Training deep networks with synthetic data: Bridging the reality gap by domain randomization. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 969–977, 2018
2018
-
[6]
Domain randomiza- tion for transferring deep neural networks from simulation to the real world
Josh Tobin, Rachel Fong, Alex Ray, Jonas Schneider, Wojciech Zaremba, and Pieter Abbeel. Domain randomiza- tion for transferring deep neural networks from simulation to the real world. InProceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 23–30. IEEE, 2017
2017
-
[7]
Maddix, Junming Yin, Nick Erickson, Abdul Fatir Ansari, Boran Han, Shuai Zhang, Leman Akoglu, Christos Faloutsos, Michael W
Xiyuan Zhang, Danielle C. Maddix, Junming Yin, Nick Erickson, Abdul Fatir Ansari, Boran Han, Shuai Zhang, Leman Akoglu, Christos Faloutsos, Michael W. Mahoney, Cuixiong Hu, Huzefa Rangwala, George Karypis, and Bernie Wang. Mitra: Mixed synthetic priors for enhancing tabular foundation models. arXiv preprint, 2025
2025
-
[8]
Physics- informed machine learning.Nature Reviews Physics, 3:422–440, 2021
George Em Karniadakis, Ioannis G Kevrekidis, Lu Lu, Paris Perdikaris, Sifan Wang, and Liu Yang. Physics- informed machine learning.Nature Reviews Physics, 3:422–440, 2021
2021
-
[9]
John R. Rice. The algorithm selection problem. InAdvances in Computers, volume 15, pages 65–118. Elsevier, 1976
1976
-
[10]
Kate A. Smith-Miles. Cross-disciplinary perspectives on meta-learning for algorithm selection.ACM Computing Surveys, 41(1):6:1–6:25, 2008. doi: 10.1145/1456650.1456656
-
[11]
Meta-learning: A survey.arXiv preprint arXiv:1810.03548, 2018
Joaquin Vanschoren. Meta-learning: A survey.arXiv preprint arXiv:1810.03548, 2018
Pith/arXiv arXiv 2018
-
[12]
Joaquin Vanschoren, Jan N. van Rijn, Bernd Bischl, and Luis Torgo. OpenML: Networked science in machine learning.ACM SIGKDD Explorations Newsletter, 15(2):49–60, 2014. doi: 10.1145/2641190.2641198
-
[13]
Efficient and robust automated machine learning
Matthias Feurer, Aaron Klein, Katharina Eggensperger, Jost Springenberg, Manuel Blum, and Frank Hutter. Efficient and robust automated machine learning. InAdvances in Neural Information Processing Systems, volume 28, 2015. 13 APREPRINT- JUNE8, 2026
2015
-
[14]
Kusner, Brooks Paige, and José Miguel Hernández-Lobato
Matt J. Kusner, Brooks Paige, and José Miguel Hernández-Lobato. Grammar variational autoencoder. In Proceedings of the 34th International Conference on Machine Learning, volume 70 ofProceedings of Machine Learning Research, pages 1945–1954. PMLR, 2017
1945
-
[15]
Probabilistic grammars for equation discovery.Knowledge- Based Systems, 224:107077, 2021
Jure Brence, Ljupˇco Todorovski, and Sašo Džeroski. Probabilistic grammars for equation discovery.Knowledge- Based Systems, 224:107077, 2021
2021
-
[16]
Efficient generator of mathematical expressions for symbolic regression.Machine Learning, 112(11):4563–4596, 2023
Sebastian Mežnar, Sašo Džeroski, and Ljupˇco Todorovski. Efficient generator of mathematical expressions for symbolic regression.Machine Learning, 112(11):4563–4596, 2023
2023
-
[17]
Karakasidis
Dimitrios Angelis, Filippos Sofos, and Theodoros E. Karakasidis. Artificial intelligence in physical sciences: Symbolic regression trends and perspectives.Archives of Computational Methods in Engineering, 30(6):3845– 3865, 2023
2023
-
[18]
Interpretable scientific discovery with symbolic regression: A review.Artificial Intelligence Review, 57(1):2, 2024
Nour Makke and Sanjay Chawla. Interpretable scientific discovery with symbolic regression: A review.Artificial Intelligence Review, 57(1):2, 2024
2024
-
[19]
AI Feynman: A physics-inspired method for symbolic regression
Silviu-Marian Udrescu and Max Tegmark. AI Feynman: A physics-inspired method for symbolic regression. Science Advances, 6(16):eaay2631, 2020
2020
-
[20]
Neural symbolic regression that scales
Luca Biggio, Tommaso Bendinelli, Alexander Neitz, Aurelien Lucchi, and Giambattista Parascandolo. Neural symbolic regression that scales. InProceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 936–945. PMLR, 2021
2021
-
[21]
End-to-end symbolic regression with transformers
Pierre-Alexandre Kamienny, Stéphane d’Ascoli, Guillaume Lample, and François Charton. End-to-end symbolic regression with transformers. InAdvances in Neural Information Processing Systems, volume 35, pages 10269– 10281, 2022
2022
-
[22]
Parshin Shojaee, Kazem Meidani, Amir Barati Farimani, and Chandan K. Reddy. Transformer-based planning for symbolic regression. InAdvances in Neural Information Processing Systems, volume 36, 2023
2023
-
[23]
Shun Sato and Issei Sato. Can test-time computation mitigate reproduction bias in neural symbolic regression? arXiv preprint arXiv:2505.22081, 2025
arXiv 2025
-
[24]
Active expansion sampling for learning feasible domains in an unbounded input space
Wei Chen and Mark Fuge. Active expansion sampling for learning feasible domains in an unbounded input space. Structural and Multidisciplinary Optimization, 57:925–945, 2017
2017
-
[25]
A novel adaptive sampling based methodol- ogy for feasible region identification of compute intensive models using artificial neural network.AIChE Journal, 67(2), 2021
Nirupaplava Metta, Rohit Ramachandran, and Marianthi Ierapetritou. A novel adaptive sampling based methodol- ogy for feasible region identification of compute intensive models using artificial neural network.AIChE Journal, 67(2), 2021
2021
-
[26]
Constrained adaptive sampling for domain reduction in surrogate model generation: Applications to hydrogen production.AIChE Journal, 67(7), 2021
Julian Straus, Jabir Ali Ouassou, Brage Rugstad Knudsen, and Rahul Anantharaman. Constrained adaptive sampling for domain reduction in surrogate model generation: Applications to hydrogen production.AIChE Journal, 67(7), 2021
2021
-
[27]
Chance-constrained flow matching for high-fidelity constraint-aware generation
Jinhao Liang, Yixuan Sun, Anirban Samaddar, Sandeep Madireddy, and Ferdinando Fioretto. Chance-constrained flow matching for high-fidelity constraint-aware generation. arXiv preprint arXiv:2509.25157, 2025
arXiv 2025
-
[28]
The feynman lectures on physics; vol
Richard P Feynman, Robert B Leighton, Matthew Sands, and Everett M Hafner. The feynman lectures on physics; vol. i.American Journal of Physics, 33(9):750–752, 1965
1965
-
[29]
Feynman symbolic regression database
Silviu-Marian Udrescu and Max Tegmark. Feynman symbolic regression database. https://space.mit.edu/ home/tegmark/aifeynman.html, 2020. Accessed: 2026-05-18
2020
-
[30]
Optuna: A next-generation hyperparameter optimization framework
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. Optuna: A next-generation hyperparameter optimization framework. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 2623–2631. ACM, 2019
2019
-
[31]
Algorithms for hyper-parameter optimization
James Bergstra, Rémi Bardenet, Yoshua Bengio, and Balázs Kégl. Algorithms for hyper-parameter optimization. InAdvances in Neural Information Processing Systems, volume 24, pages 2546–2554, 2011
2011
-
[32]
The original borda count and partial voting.Social Choice and Welfare, 40(2):353–358, 2013
Peter Emerson. The original borda count and partial voting.Social Choice and Welfare, 40(2):353–358, 2013. 14 APREPRINT- JUNE8, 2026 Appendix Figure A1: Validation of the standard PCFG. Per-feature distribution comparison between the Feynman corpus (blue) and 1000 generated equations (orange); the final panel shows operator frequencies. Two of the eight s...
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.