Evidence-Grounded Ensemble Diagnosis of 802.11 Packet Captures: A Multi-Stage Pipeline with Deterministic Reliability Scoring
Pith reviewed 2026-06-27 22:27 UTC · model grok-4.3
The pith
PROBE pipeline combines deterministic PCAP normalization, ensembles, and verdict-aware evidence scoring to reach 0.957 F1 on 802.11 captures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
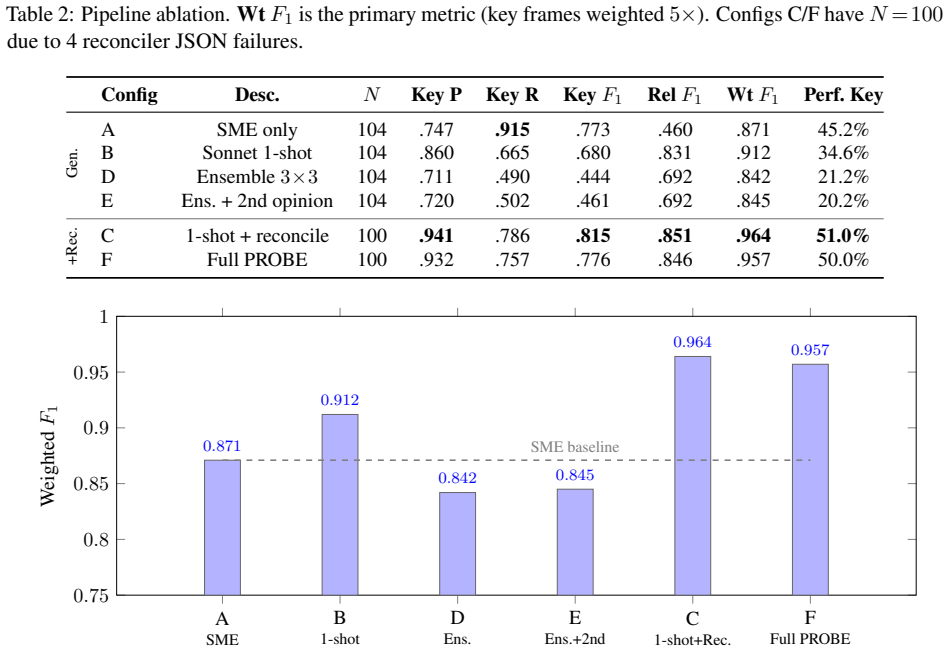
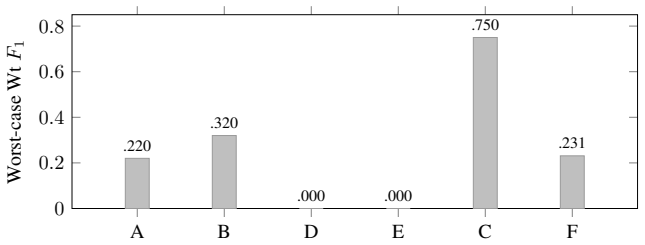
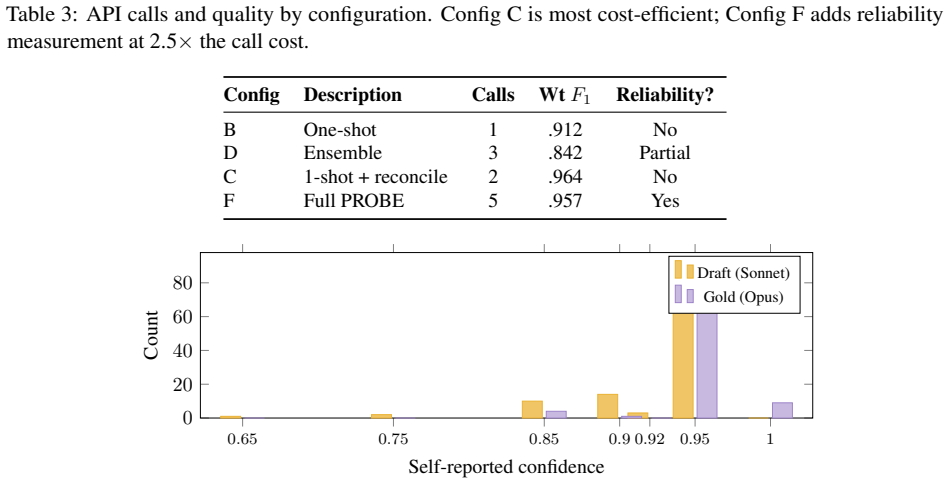
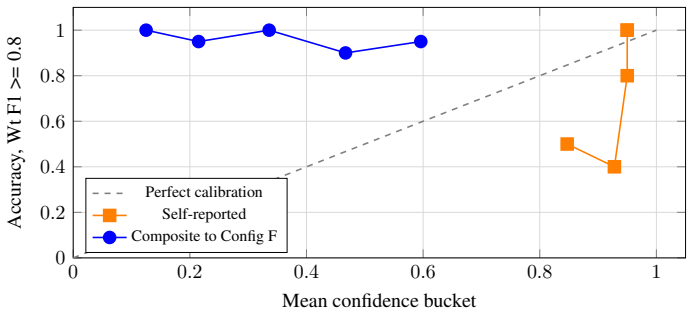
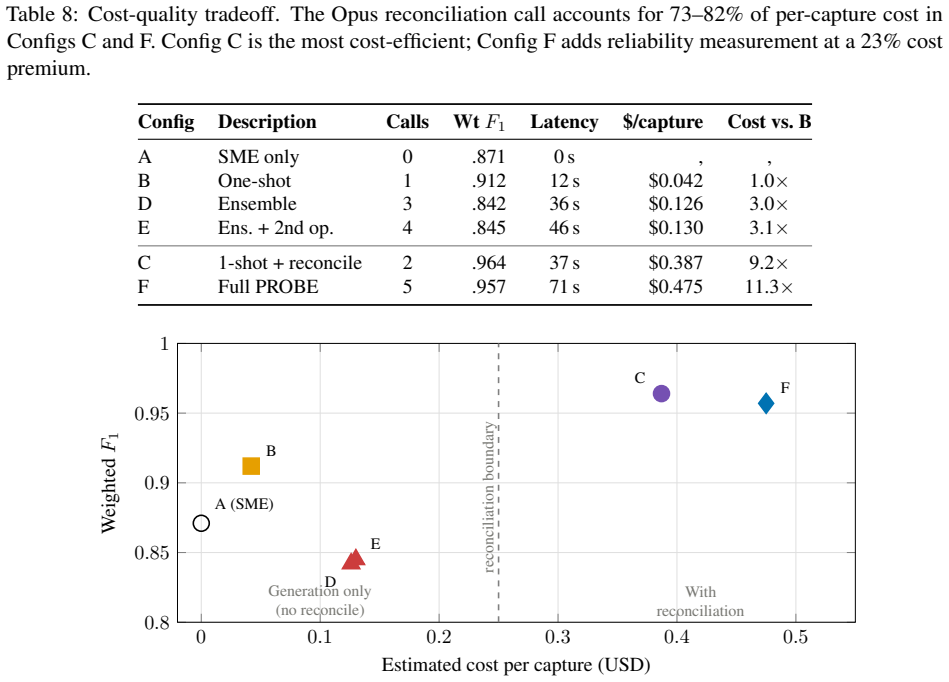
PROBE integrates deterministic PCAP-to-text normalization with frame-level verifiability, multi-candidate ensembles with optional cross-model second opinion and progressive obfuscation, a verdict-aware evidence framework that treats absence of failure evidence as contributing evidence, and a fully deterministic composite reliability score from evidence validity, run-to-run stability, and cross-model agreement. On the test set this produces 0.957 F1, 96% auto-accept, and a reliability floor above 0.70 while single-pass analysis misses critical frames in 35% of cases and LLM self-reported confidence clusters unhelpfully at 0.95.
What carries the argument
Verdict-aware evidence framework paired with deterministic composite reliability scoring computed from evidence validity, run-to-run stability, and cross-model agreement.
If this is right
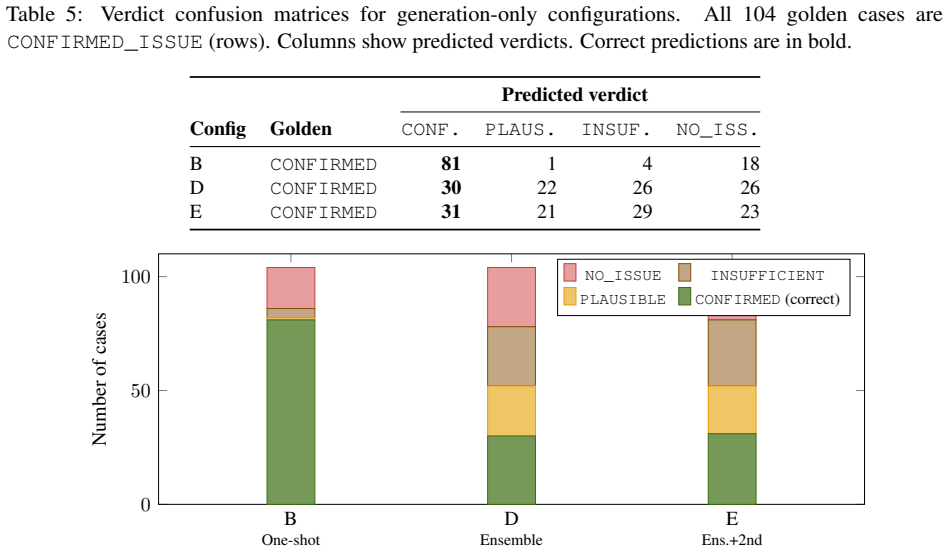
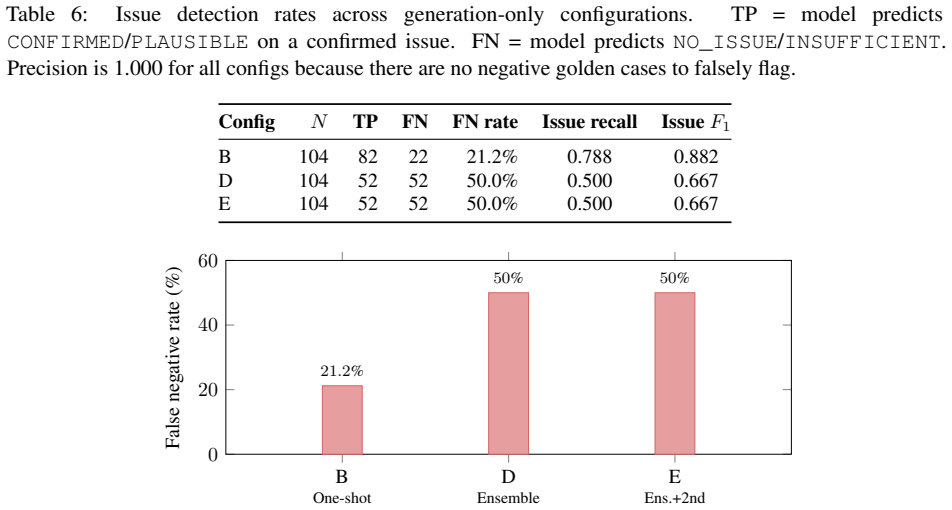
- Single-pass LLM analysis raises F1 to 0.912 but misses critical frames in 35% of cases.
- Naive ensemble voting drops below the 0.871 expert baseline to 0.842 by amplifying conservative verdicts.
- Evidence-grounded reconciliation reaches 0.957 F1 with 96% auto-accept rate and worst-case reliability above 0.70.
- A model-agnostic per-field assertion matching evaluation framework removes circular bias from model-co-produced golden references.
Where Pith is reading between the lines
- The same combination of deterministic normalization and non-self-reported reliability scoring could apply to automated diagnosis of other network or protocol traces.
- High auto-accept rates suggest most captures could be handled without human review, reserving experts for the low-reliability remainder.
- Progressive obfuscation and cross-model second opinions may reduce single-model biases in technical reasoning tasks outside Wi-Fi.
Load-bearing premise
The deterministic PCAP-to-text normalization with frame-level verifiability accurately captures all relevant protocol events without loss or fabrication.
What would settle it
A capture in which the PCAP-to-text normalization step omits or invents a protocol frame that changes the diagnosis outcome or the resulting reliability score.
Figures

read the original abstract
Diagnosing 802.11 packet captures requires expert protocol knowledge, is slow, inconsistent across engineers, and unscalable. LLM-based approaches sound plausible but fabricate protocol events absent from captures (especially truncated traces), produce uncalibrated confidence scores, and suffer evaluation bias when golden references are co-produced by the model under test. We introduce PROBE (Protocol Reasoning Over evidence-Based Ensembles), a multi-stage pipeline addressing all three failures. It integrates (i) deterministic PCAP-to-text normalization with frame-level verifiability, (ii) multi-run, multi-candidate ensembles with optional cross-model second opinion and progressive obfuscation, (iii) a verdict-aware evidence framework treating absence of failure evidence as contributing evidence, and (iv) a fully deterministic composite reliability score from evidence validity, run-to-run stability, and cross-model agreement without LLM self-assessment. On 87 enterprise Wi-Fi captures (104 capture-reviewer pairs), single-pass LLM analysis raises weighted evidence F1 from 0.871 (expert baseline) to 0.912 but misses critical frames in 35% of cases. Naive ensemble voting drops below baseline (0.842) as majority voting amplifies conservative verdicts: 50% of confirmed failures are misclassified as 'no issue' or 'insufficient evidence.' Adding evidence-grounded reconciliation achieves 0.957 F1, a 96% auto-accept rate, and a worst-case floor above 0.70. LLM self-reported confidence clusters at 0.95 regardless of difficulty (71% report exactly 0.95), confirming it is uninformative. We also introduce a model-agnostic evaluation framework using per-field assertion matching, eliminating circular bias from model-co-produced golden references.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents PROBE, a multi-stage pipeline for evidence-grounded diagnosis of 802.11 packet captures. It claims that deterministic PCAP-to-text normalization, combined with multi-candidate ensembles, a verdict-aware evidence framework (treating absence of failure evidence as positive), and a deterministic reliability score (from validity, stability, and agreement, without LLM self-assessment), yields 0.957 weighted evidence F1, 96% auto-accept rate, and >0.70 worst-case floor on 87 enterprise captures (104 reviewer pairs). This outperforms the 0.871 expert baseline and 0.912 single-pass LLM, while naive ensembles fall to 0.842; a model-agnostic per-field assertion matching evaluation avoids circular bias from model-generated references.
Significance. If the central claims hold after validation, the work offers a concrete advance in reliable LLM application to protocol diagnosis by addressing fabrication, uncalibrated confidence, and evaluation bias. The model-agnostic evaluation framework and deterministic reliability scoring (avoiding self-assessment) are particular strengths that could generalize beyond 802.11. The reported gains over expert baseline and the explicit failure modes of baselines provide falsifiable, quantitative evidence of the pipeline's contribution.
major comments (2)
- [Abstract (integration point (i))] Abstract, integration point (i): The deterministic PCAP-to-text normalization with frame-level verifiability is asserted to capture every relevant 802.11 event without omission or fabrication and is the sole input to the verdict-aware evidence framework, ensembles, and reliability scoring. No systematic audit (e.g., field-by-field diff vs. tshark/Wireshark extraction) is reported across the 87 captures or 104 pairs. This is load-bearing for the 0.957 F1 claim and the explanation of why naive ensembles fail, because the abstract itself notes LLM fabrication precisely on truncated traces; if normalization silently drops or fabricates frames, the performance deltas are artifacts of preprocessing rather than reconciliation logic.
- [Evaluation / Results] Evaluation (implied in abstract and results): Full dataset details, capture characteristics (e.g., truncation rates), per-field error analysis, and the exact weighting scheme for the reported 'weighted evidence F1' are not provided, preventing verification that the 0.957 F1 and >0.70 floor are not driven by easy cases or post-hoc selection.
minor comments (2)
- [Abstract] The abstract states single-pass LLM 'misses critical frames in 35% of cases' but does not define 'critical frames' or report how this metric was computed independently of the model under test.
- [Methods (implied)] Notation for the composite reliability score components (evidence validity, run-to-run stability, cross-model agreement) is introduced but not given explicit formulas or pseudocode in the provided text.
Simulated Author's Rebuttal
Thank you for the referee's constructive review and recommendation for major revision. We address each major comment below and will revise the manuscript to provide the requested transparency on normalization verification and evaluation details.
read point-by-point responses
-
Referee: [Abstract (integration point (i))] Abstract, integration point (i): The deterministic PCAP-to-text normalization with frame-level verifiability is asserted to capture every relevant 802.11 event without omission or fabrication and is the sole input to the verdict-aware evidence framework, ensembles, and reliability scoring. No systematic audit (e.g., field-by-field diff vs. tshark/Wireshark extraction) is reported across the 87 captures or 104 pairs. This is load-bearing for the 0.957 F1 claim and the explanation of why naive ensembles fail, because the abstract itself notes LLM fabrication precisely on truncated traces; if normalization silently drops or fabricates frames, the performance deltas are artifacts of preprocessing rather than reconciliation logic.
Authors: We agree that a systematic audit of the normalization step is important to substantiate the claims. The PCAP-to-text conversion is implemented via deterministic tshark-based field extraction with explicit frame-level traceability, ensuring no LLM-driven content generation occurs at this stage. To directly address the concern, we will add an appendix to the revised manuscript containing a field-by-field comparison (against raw tshark/Wireshark output) on a representative sample of at least 20 captures. This will confirm zero omissions or fabrications and isolate the performance gains to the verdict-aware ensemble and reconciliation logic. revision: yes
-
Referee: [Evaluation / Results] Evaluation (implied in abstract and results): Full dataset details, capture characteristics (e.g., truncation rates), per-field error analysis, and the exact weighting scheme for the reported 'weighted evidence F1' are not provided, preventing verification that the 0.957 F1 and >0.70 floor are not driven by easy cases or post-hoc selection.
Authors: We acknowledge that greater detail on the evaluation setup is needed for full verifiability. In the revision we will expand the dataset description section to report capture characteristics including truncation rates, packet counts, and other relevant statistics for the 87 captures. We will also specify the precise weighting formula used for the weighted evidence F1 and add a per-field error breakdown to show performance distribution across evidence categories and difficulty levels, thereby demonstrating that the reported metrics are not artifacts of easy-case selection. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper's central results (0.957 F1, 96% auto-accept) are obtained by applying a deterministic PCAP-to-text normalization, multi-candidate ensembles, verdict-aware evidence framework, and composite reliability score to 87 captures, then measuring against an expert baseline of 0.871 using model-agnostic per-field assertion matching. No equation or step reduces by construction to its own inputs; the normalization is presented as an independent preprocessing stage whose output is externally verifiable, the reliability score is fully deterministic without LLM self-assessment, and the evaluation framework is explicitly introduced to eliminate circular bias from model-co-produced references. No self-citations appear in the provided text, and no fitted parameter is relabeled as a prediction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Tulczyjew, K
Ł. Tulczyjew, K. Jarrah, C. Abondo, D. Bennett, and N. Weill. LLMcap: Large Language Model for Unsupervised PCAP Failure Detection. InIEEE ICC Workshop on the Impact of LLMs on 6G Networks,
-
[2]
F. Shirin Abkenar. WiFi Pathologies Detection using LLMs.arXiv preprint arXiv:2506.06943, 2025
arXiv 2025
-
[3]
S. Pradhan, S. Irshad, and J. Henry. PLUME: Building a Network-Native Foundation Model for Wireless Traces via Protocol-Aware Tokenization.arXiv preprint arXiv:2603.13647, 2026
arXiv 2026
-
[4]
H. Wang, A. Abhashkumar, C. Lin, T. Zhang, X. Gu, N. Ma, C. Wu, S. Liu, W. Zhou, Y . Dong, W. Jiang, and Y . Wang. NetAssistant: Dialogue Based Network Diagnosis in Data Center Networks. In21st USENIX NSDI, pages 2011–2024, 2024
2011
-
[5]
C. Wang, X. Zhang, R. Lu, X. Lin, X. Zeng, X. Zhang, Z. An, G. Wu, J. Gao, C. Tian, G. Chen, G. Liu, Y . Liao, T. Lin, D. Cai, and E. Zhai. Towards LLM-Based Failure Localization in Production-Scale Networks. InACM SIGCOMM, pages 496–511, 2025
2025
-
[6]
K. B. Kan, H. Mun, G. Cao, and Y . Lee. Mobile-LLaMA: Instruction Fine-Tuning Open-Source LLM for Network Analysis in 5G Networks.IEEE Network, 38(5):76–83, 2024
2024
-
[7]
D. Wu, X. Wang, Y . Qiao, Z. Wang, J. Jiang, S. Cui, and F. Wang. NetLLM: Adapting Large Language Models for Networking. InACM SIGCOMM, pages 661–678, 2024
2024
-
[8]
Z. Wang, A. Cornacchia, A. Sacco, F. Galante, M. Canini, and D. Jiang. A Network Arena for Benchmarking AI Agents on Network Troubleshooting. InACM Internet Measurement Conference (IMC), 2025. arXiv:2512.16381
arXiv 2025
-
[9]
X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowdhery, and D. Zhou. Self-Consistency Improves Chain of Thought Reasoning in Language Models. InICLR, 2023. arXiv:2203.11171
Pith/arXiv arXiv 2023
-
[10]
Y . Li, S. Chen, and others. Escape Sky-High Cost: Early-Stopping Self-Consistency for Multi-Step Reasoning.arXiv preprint arXiv:2401.10480, 2024
arXiv 2024
-
[11]
S. Nair and others. Make Every Penny Count: Difficulty-Adaptive Self-Consistency for Cost-Efficient Reasoning.arXiv preprint arXiv:2408.13457, 2024
arXiv 2024
-
[12]
T. Liang, Z. He, W. Jiao, X. Wang, Y . Wang, R. Wang, Y . Yang, Z. Tu, and S. Shi. Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate.arXiv preprint arXiv:2305.19118, 2023
Pith/arXiv arXiv 2023
-
[13]
Y . Du, S. Li, A. Torralba, J. B. Tenenbaum, and I. Mordatch. Improving Factuality and Reasoning in Language Models through Multiagent Debate.arXiv preprint arXiv:2305.14325, 2023. 36
Pith/arXiv arXiv 2023
-
[14]
Zheng, W.-L
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. P. Xing, H. Zhang, J. E. Gonzalez, and I. Stoica. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. InNeurIPS, 2024
2024
-
[15]
S. Li and others. LLMs-as-Judges: A Comprehensive Survey on LLM-Based Evaluation Methods. arXiv preprint arXiv:2412.05579, 2024
Pith/arXiv arXiv 2024
-
[16]
Y . Xiao and others. Meta-Judging with Large Language Models: Concepts, Methods, and Challenges. arXiv preprint arXiv:2601.17312, 2025
arXiv 2025
-
[17]
N. Thakur and others. No Free Labels: Limitations of LLM-as-a-Judge Without Human Grounding. arXiv preprint arXiv:2503.05061, 2025
arXiv 2025
-
[18]
L. Shi and others. Judging the Judges: A Systematic Study of Position Bias in LLM-as-a-Judge.arXiv preprint arXiv:2406.07791, 2024
arXiv 2024
-
[19]
Liao and others
Q. Liao and others. CLEVER: Clinical Large Language Model Evaluation by Expert Review.JMIR AI, 2025
2025
-
[20]
Yang and others
J. Yang and others. Automated Evaluation of Expert-Level Medical Reasoning.npj Digital Medicine, 2025
2025
-
[21]
A. Jacovi and others. The FACTS Grounding Leaderboard: Benchmarking LLMs’ Ability to Ground Responses to Long-Form Input.arXiv preprint arXiv:2501.03200, 2025
arXiv 2025
-
[22]
A. Jacovi and others. The FACTS Leaderboard: A Comprehensive Benchmark for Large Language Model Factuality.arXiv preprint arXiv:2512.10791, 2025
arXiv 2025
-
[23]
Szott, F
S. Szott, F. Wilhelmi, and others. Wi-Fi Meets ML: A Survey on Improving IEEE 802.11 Performance with Machine Learning.IEEE Comm. Surveys & Tutorials, 24(3):1643–1681, 2022. 37
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.