A Unifying View of Attention Sinks: Two Algorithms, Two Solutions
Pith reviewed 2026-06-27 19:49 UTC · model grok-4.3
The pith
Attention sinks can implement either a null update or a global broadcast in transformers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Visually similar sink patterns reflect two distinct mechanisms: adaptive nop, where a head suppresses its update by routing to a null token, and broadcast, where a sink aggregates and redistributes global information. In that case, sinks serve an analogous role: a safe destination when there is nothing useful to compute. Proposed interventions like gating or registers work because they implicitly target one or the other, revealing a duality between method and assumed mechanism. Each mechanism leaves distinct traces which we formalize on synthetic tasks and use to derive practical diagnostics. Applied to pretrained vision transformers, these diagnostics reveal that both mechanisms exist at sc
What carries the argument
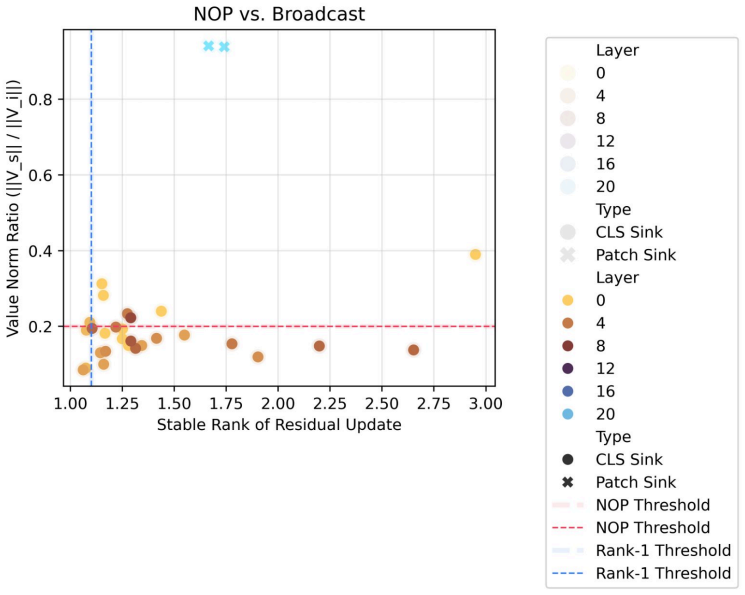
The traces that separate nop sinks (negligible value norms) from broadcast sinks (low-rank outputs) as reliable signatures of each algorithm.
If this is right
- Gating implicitly assumes nop sinks while registers implicitly assume broadcast sinks.
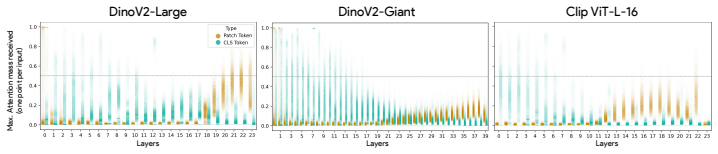
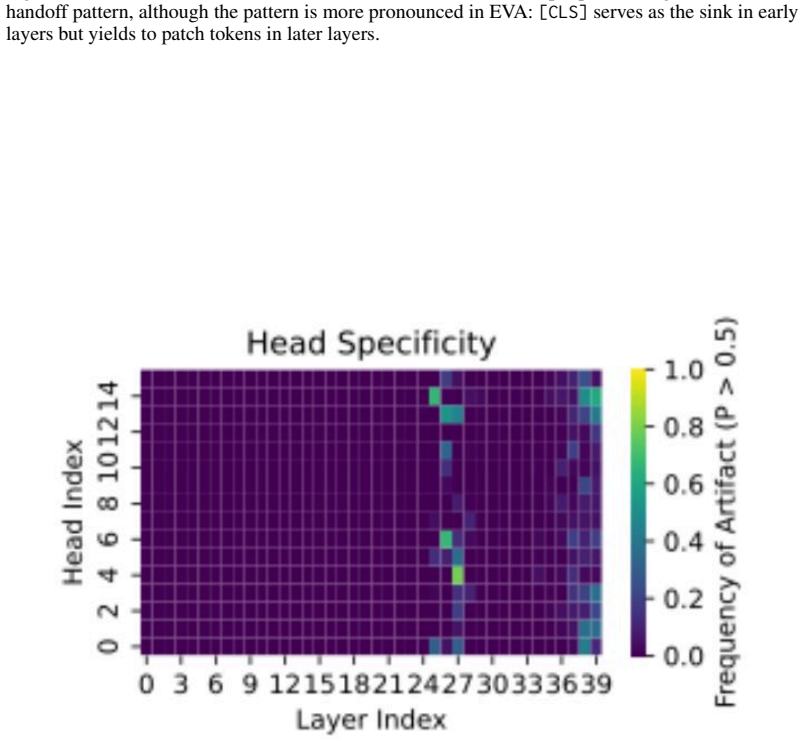
- Both mechanisms coexist in pretrained vision transformers and concentrate in specialized heads.
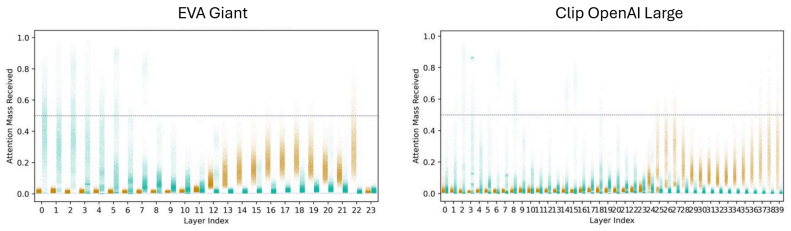
- Sinks transition from the CLS token in early layers to patch tokens in deeper layers.
- Register tokens designed for broadcast are also repurposed for nop, so neither intervention suffices alone.
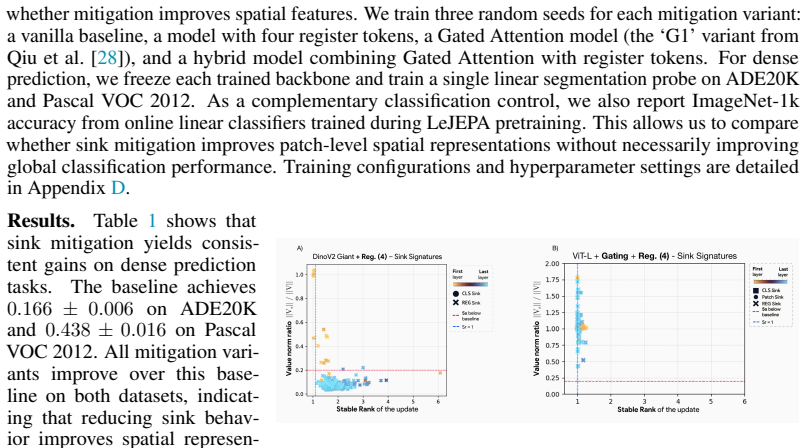
- Combining gating with registers yields complementary gains in stability and performance.
Where Pith is reading between the lines
- The same diagnostics could be run on language models to test whether the nop-broadcast split appears outside vision tasks.
- Layer-wise shifts from nop to broadcast suggest attention heads progressively move from suppression to information sharing with depth.
- Future architectures might embed explicit support for both mechanisms rather than relying on post-hoc fixes.
Load-bearing premise
The traces derived from synthetic tasks reliably distinguish the underlying mechanisms when applied to pretrained vision transformers without post-hoc adjustment.
What would settle it
Observing a sink head whose value-norm and output-rank signatures do not align with either the nop pattern or the broadcast pattern in a pretrained model would falsify the claim that these are the two mechanisms.
Figures







read the original abstract
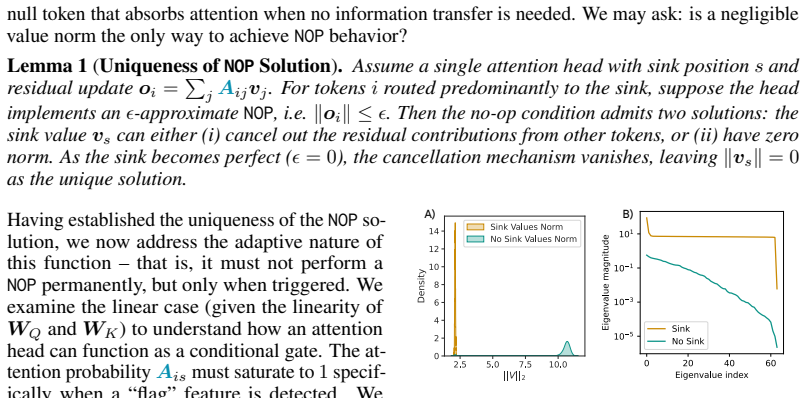
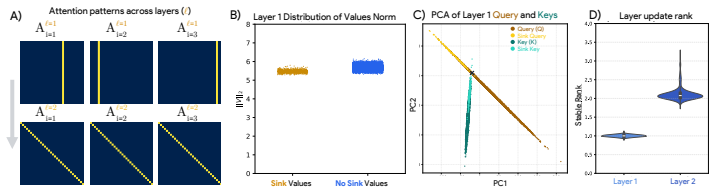
When attention concentrates on a single token, a sink, what is the model actually computing? Attention sinks are ubiquitous in softmax transformers, yet this shared visual signature can hide fundamentally different algorithms. We show that visually similar sink patterns can reflect two distinct mechanisms: {i} adaptive nop, where a head suppresses its update by routing to a null token, and {ii} broadcast, where a sink aggregates and redistributes global information. In that case, sinks serve an analogous role: a safe destination when there is nothing useful to compute. Proposed interventions like gating or registers work because they implicitly target one or the other, revealing a duality between method and assumed mechanism: gating implicitly assumes nop; registers implicitly assume broadcast. Each mechanism leaves distinct traces (nop sinks exhibit negligible value norms; broadcast sinks induce low-rank outputs) which we formalize on synthetic tasks and use to derive practical diagnostics. Applied to pretrained vision transformers, these diagnostics reveal that both mechanisms exist at scale: sinks transition from CLS in early layers to patches in deeper layers, and concentrate in specialized heads. Strikingly, register tokens, designed for broadcast, are repurposed to also serve nop, confirming that neither intervention alone suffices. Combining gating with registers yields complementary gains in stability and performance. Overall, we find that the same attention pattern can reflect two very different computations and effective intervention requires first asking what the model is actually computing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that visually similar attention sink patterns in softmax transformers can arise from two distinct mechanisms: (i) adaptive nop, in which a head suppresses its update by routing attention to a null token, and (ii) broadcast, in which a sink token aggregates and redistributes global information. It formalizes these mechanisms and their distinguishing traces (negligible value norms for nop sinks; low-rank outputs for broadcast sinks) on synthetic tasks, derives practical diagnostics from them, applies the diagnostics to pretrained vision transformers to conclude that both mechanisms coexist at scale (with sinks transitioning from CLS to patches and concentrating in specialized heads), shows that register tokens are repurposed for nop despite being designed for broadcast, and reports that combining gating (targeting nop) with registers (targeting broadcast) produces complementary gains in stability and performance.
Significance. If the diagnostics reliably map to the hypothesized mechanisms without confounding, the work provides a useful unifying perspective that explains why gating and register interventions succeed or fall short and motivates mechanism-aware rather than pattern-aware fixes. The synthetic-task formalization and the observation that registers are co-opted for nop are concrete strengths that could guide future intervention design.
major comments (1)
- [experiments on pretrained vision transformers] Application of diagnostics to pretrained ViTs (experiments section following synthetic tasks): the central claim that both mechanisms exist at scale and that the interventions exhibit a duality rests on the traces (negligible value norms; low-rank outputs) being unambiguous identifiers. The manuscript applies these traces directly without post-hoc adjustment or controls for confounders such as layer depth, head specialization, or training dynamics; if other factors can produce the same traces, the evidence for coexistence and the necessity of combined interventions does not follow.
minor comments (2)
- [abstract and results] The abstract and main text would benefit from explicit quantitative results, error bars, and exclusion criteria for the ViT experiments to allow verification of effect sizes and robustness.
- [introduction and formalization] Notation for the two mechanisms and their traces should be introduced with a single consistent table or figure early in the paper to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The major comment concerns the strength of evidence when applying the diagnostics to pretrained ViTs. We respond point by point below.
read point-by-point responses
-
Referee: Application of diagnostics to pretrained ViTs (experiments section following synthetic tasks): the central claim that both mechanisms exist at scale and that the interventions exhibit a duality rests on the traces (negligible value norms; low-rank outputs) being unambiguous identifiers. The manuscript applies these traces directly without post-hoc adjustment or controls for confounders such as layer depth, head specialization, or training dynamics; if other factors can produce the same traces, the evidence for coexistence and the necessity of combined interventions does not follow.
Authors: The synthetic tasks are constructed to isolate each mechanism, demonstrating that negligible value norms arise specifically from adaptive nop and low-rank outputs from broadcast, independent of other variables. When the same traces are observed in pretrained ViTs, they exhibit the predicted layer-wise transition (CLS to patches) and head specialization, and register tokens are repurposed for nop despite their broadcast-oriented design. These alignments with the formalization provide evidence for coexistence. We acknowledge that the manuscript does not report explicit post-hoc controls or adjustments for confounders such as training dynamics. A dedicated limitations discussion on potential alternative explanations for the traces will be added in revision to clarify the scope of the claims. revision: partial
Circularity Check
No significant circularity; derivation is self-contained empirical mapping
full rationale
The paper defines two mechanisms (adaptive nop and broadcast), derives their distinguishing traces (negligible value norms vs. low-rank outputs) from synthetic tasks by construction of those tasks, then applies the resulting diagnostics to pretrained ViTs as an independent test. No equation or parameter is fitted to the target data and then relabeled as a prediction; no self-citation chain supplies the central distinction; the mapping from mechanism to trace is not tautological but is presented as a testable signature. The overall argument therefore remains non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Attention is all you need.Advances in Neural Information Processing Systems (NeurIPS), 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[2]
An image is worth 16x16 words: Transformers for image recognition at scale.Proceedings of the International Conference on Learning Representations (ICLR), 2020
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.Proceedings of the International Conference on Learning Representations (ICLR), 2020
2020
-
[3]
Scaling vision transform- ers.Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022
Xiaohua Zhai, Alexander Kolesnikov, Neil Houlsby, and Lucas Beyer. Scaling vision transform- ers.Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[4]
Scaling vision transformers to 22 billion parameters.Proceedings of the International Conference on Machine Learning (ICML), 2023
Mostafa Dehghani, Josip Djolonga, Basil Mustafa, Piotr Padlewski, Jonathan Heek, Justin Gilmer, Andreas Peter Steiner, Mathilde Caron, Robert Geirhos, Ibrahim Alabdulmohsin, et al. Scaling vision transformers to 22 billion parameters.Proceedings of the International Conference on Machine Learning (ICML), 2023
2023
-
[5]
Siglip 2: Multilingual vision- language encoders with improved semantic understanding, localization, and dense features
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alab- dulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, Olivier Hénaff, Jeremiah Harmsen, Andreas Steiner, and Xiaohua Zhai. Siglip 2: Multilingual vision- language encoders with improved semantic understanding, localization, and dense features....
2025
-
[6]
Language models are few-shot learners.Advances in Neural Information Processing Systems (NeurIPS), 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[7]
Llama 2: Open foundation and fine-tuned chat models.ArXiv e-print, 2023
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.ArXiv e-print, 2023
2023
-
[8]
Training language models to follow instructions with human feedback.Advances in Neural Information Processing Systems (NeurIPS), 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[9]
Why do llms attend to the first token?ArXiv e-print, 2025
Federico Barbero, Alvaro Arroyo, Xiangming Gu, Christos Perivolaropoulos, Michael Bronstein, Petar Veliˇckovi´c, and Razvan Pascanu. Why do llms attend to the first token?ArXiv e-print, 2025. 10
2025
-
[10]
Attention sinks and compression valleys in llms are two sides of the same coin.ArXiv e-print, 2025
Enrique Queipo-de Llano, Álvaro Arroyo, Federico Barbero, Xiaowen Dong, Michael Bronstein, Yann LeCun, and Ravid Shwartz-Ziv. Attention sinks and compression valleys in llms are two sides of the same coin.ArXiv e-print, 2025
2025
-
[11]
Spectral filters, dark signals, and attention sinks.ArXiv e-print, 2024
Nicola Cancedda. Spectral filters, dark signals, and attention sinks.ArXiv e-print, 2024
2024
-
[12]
Artifacts and attention sinks: Structured approximations for efficient vision transformers.ArXiv e-print, 2025
Andrew Lu, Wentinn Liao, Liuhui Wang, Huzheng Yang, and Jianbo Shi. Artifacts and attention sinks: Structured approximations for efficient vision transformers.ArXiv e-print, 2025
2025
-
[13]
Vision transformers need registers.ArXiv e-print, 2023
Timothée Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Vision transformers need registers.ArXiv e-print, 2023
2023
-
[14]
Vision transformers don’t need trained registers.ArXiv e-print, 2025
Nick Jiang, Amil Dravid, Alexei Efros, and Yossi Gandelsman. Vision transformers don’t need trained registers.ArXiv e-print, 2025
2025
-
[15]
On the emergence of position bias in transformers.Proceedings of the International Conference on Learning Representations (ICLR), 2025
Xinyi Wu, Yifei Wang, Stefanie Jegelka, and Ali Jadbabaie. On the emergence of position bias in transformers.Proceedings of the International Conference on Learning Representations (ICLR), 2025
2025
-
[16]
A unified view of attention and residual sinks: Outlier-driven rescaling is essential for transformer training.ArXiv e-print, 2026
Zihan Qiu, Zeyu Huang, Kaiyue Wen, Peng Jin, Bo Zheng, Yuxin Zhou, Haofeng Huang, Zekun Wang, Xiao Li, Huaqing Zhang, et al. A unified view of attention and residual sinks: Outlier-driven rescaling is essential for transformer training.ArXiv e-print, 2026
2026
-
[17]
Attention sinks: A’catch, tag, re- lease’mechanism for embeddings.Proceedings of the International Conference on Learning Representations (ICLR), 2024
Stephen Zhang, Mustafa Khan, and Vardan Papyan. Attention sinks: A’catch, tag, re- lease’mechanism for embeddings.Proceedings of the International Conference on Learning Representations (ICLR), 2024
2024
-
[18]
Massive activations in large language models.ArXiv e-print, 2024
Mingjie Sun, Xinlei Chen, J Zico Kolter, and Zhuang Liu. Massive activations in large language models.ArXiv e-print, 2024
2024
-
[19]
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale.Advances in neural information processing systems, 35: 30318–30332, 2022
2022
-
[20]
Quantizable transformers: Removing outliers by helping attention heads do nothing.Advances in Neural Information Processing Systems (NeurIPS), 2023
Yelysei Bondarenko, Markus Nagel, and Tijmen Blankevoort. Quantizable transformers: Removing outliers by helping attention heads do nothing.Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[21]
Methods of improving llm training stability.arXiv preprint arXiv:2410.16682, 2024
Oleg Rybakov, Mike Chrzanowski, Peter Dykas, Jinze Xue, and Ben Lanir. Methods of improving llm training stability.arXiv preprint arXiv:2410.16682, 2024
arXiv 2024
-
[22]
See what you are told: Visual attention sink in large multimodal models.ArXiv e-print, 2025
Seil Kang, Jinyeong Kim, Junhyeok Kim, and Seong Jae Hwang. See what you are told: Visual attention sink in large multimodal models.ArXiv e-print, 2025
2025
-
[23]
Hidden dynamics of massive activations in transformer training.ArXiv e-print, 2025
Jorge Gallego-Feliciano, S Aaron McClendon, Juan Morinelli, Stavros Zervoudakis, and Anto- nios Saravanos. Hidden dynamics of massive activations in transformer training.ArXiv e-print, 2025
2025
-
[24]
Attention cannot be an explanation.ArXiv e-print, 2022
Arjun R Akula and Song-Chun Zhu. Attention cannot be an explanation.ArXiv e-print, 2022
2022
-
[25]
Is attention explanation? an introduction to the debate.Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), 2022
Adrien Bibal, Rémi Cardon, David Alfter, Rodrigo Wilkens, Xiaoou Wang, Thomas Francois, and Patrick Watrin. Is attention explanation? an introduction to the debate.Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), 2022
2022
-
[26]
Attention is not not explanation.Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), 2019
Sarah Wiegreffe and Yuval Pinter. Attention is not not explanation.Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), 2019
2019
-
[27]
Active-dormant attention heads: Mechanistically demystifying extreme-token phenomena in llms.Proceedings of the International Conference on Learning Representations (ICLR), 2025
Tianyu Guo, Druv Pai, Yu Bai, Jiantao Jiao, Michael I Jordan, and Song Mei. Active-dormant attention heads: Mechanistically demystifying extreme-token phenomena in llms.Proceedings of the International Conference on Learning Representations (ICLR), 2025
2025
-
[28]
Gated attention for large language models: Non-linearity, sparsity, and attention-sink-free.ArXiv e-print, 2025
Zihan Qiu, Zekun Wang, Bo Zheng, Zeyu Huang, Kaiyue Wen, Songlin Yang, Rui Men, Le Yu, Fei Huang, Suozhi Huang, et al. Gated attention for large language models: Non-linearity, sparsity, and attention-sink-free.ArXiv e-print, 2025. 11
2025
-
[29]
Why do llms attend to the first token?Proceedings of the Conference on Language Modeling (COLM), 2025
Federico Barbero, Álvaro Arroyo, Xiangming Gu, Christos Perivolaropoulos, Michael Bronstein, Petar Veliˇckovi´c, and Razvan Pascanu. Why do llms attend to the first token?Proceedings of the Conference on Language Modeling (COLM), 2025
2025
-
[30]
What are you sinking? a geometric approach on attention sink.ArXiv e-print, 2025
Valeria Ruscio, Umberto Nanni, and Fabrizio Silvestri. What are you sinking? a geometric approach on attention sink.ArXiv e-print, 2025
2025
-
[31]
When attention sink emerges in language models: An empirical view.ArXiv e-print, 2024
Xiangming Gu, Tianyu Pang, Chao Du, Qian Liu, Fengzhuo Zhang, Cunxiao Du, Ye Wang, and Min Lin. When attention sink emerges in language models: An empirical view.ArXiv e-print, 2024
2024
-
[32]
When attention sink emerges in language models: An empirical view.Proceedings of the International Conference on Learning Representations (ICLR), 2025
Xiangming Gu, Tianyu Pang, Chao Du, Qian Liu, Fengzhuo Zhang, Cunxiao Du, Ye Wang, and Min Lin. When attention sink emerges in language models: An empirical view.Proceedings of the International Conference on Learning Representations (ICLR), 2025
2025
-
[33]
On the role of attention masks and layernorm in transformers.Advances in Neural Information Processing Systems, 37:14774–14809, 2024
Xinyi Wu, Amir Ajorlou, Yifei Wang, Stefanie Jegelka, and Ali Jadbabaie. On the role of attention masks and layernorm in transformers.Advances in Neural Information Processing Systems, 37:14774–14809, 2024
2024
-
[34]
Using attention sinks to identify and evaluate dormant heads in pretrained llms.ArXiv e-print, 2025
Pedro Sandoval-Segura, Xijun Wang, Ashwinee Panda, Micah Goldblum, Ronen Basri, Tom Goldstein, and David Jacobs. Using attention sinks to identify and evaluate dormant heads in pretrained llms.ArXiv e-print, 2025
2025
-
[35]
Block-recurrent dynamics in vision transformers.ArXiv e-print, 2025
Mozes Jacobs, Thomas Fel, Richard Hakim, Alessandra Brondetta, Demba Ba, and T Andy Keller. Block-recurrent dynamics in vision transformers.ArXiv e-print, 2025
2025
-
[36]
Anti-oversmoothing in deep vision transformers via the fourier domain analysis: From theory to practice.ArXiv e-print, 2022
Peihao Wang, Wenqing Zheng, Tianlong Chen, and Zhangyang Wang. Anti-oversmoothing in deep vision transformers via the fourier domain analysis: From theory to practice.ArXiv e-print, 2022
2022
-
[37]
Mind the gap: a spectral analysis of rank collapse and signal propagation in attention layers.ArXiv e-print, 2024
Thiziri Nait Saada, Alireza Naderi, and Jared Tanner. Mind the gap: a spectral analysis of rank collapse and signal propagation in attention layers.ArXiv e-print, 2024
2024
-
[38]
Norm-based capacity control in neural networks.Conference on learning theory, 2015
Behnam Neyshabur, Ryota Tomioka, and Nathan Srebro. Norm-based capacity control in neural networks.Conference on learning theory, 2015
2015
-
[39]
Stronger generalization bounds for deep nets via a compression approach.Proceedings of the International Conference on Machine Learning (ICML), 2018
Sanjeev Arora, Rong Ge, Behnam Neyshabur, and Yi Zhang. Stronger generalization bounds for deep nets via a compression approach.Proceedings of the International Conference on Machine Learning (ICML), 2018
2018
-
[40]
Dinov2: Learning robust visual features without supervision.ArXiv e-print, 2023
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.ArXiv e-print, 2023
2023
-
[41]
Openclip
Gabriel Ilharco, Mitchell Wortsman, Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar, Hongseok Namkoong, John Miller, Hannaneh Hajishirzi, Ali Farhadi, et al. Openclip. Zenodo, 2021
2021
-
[42]
Randall Balestriero and Yann LeCun. Lejepa: Provable and scalable self-supervised learning without the heuristics.arXiv preprint arXiv:2511.08544, 2025
Pith/arXiv arXiv 2025
-
[43]
Replacing softmax with relu in vision transformers.arXiv preprint arXiv:2309.08586, 2023
Mitchell Wortsman, Jaehoon Lee, Justin Gilmer, and Simon Kornblith. Replacing softmax with relu in vision transformers.arXiv preprint arXiv:2309.08586, 2023
arXiv 2023
-
[44]
Hemanth Saratchandran, Jianqiao Zheng, Yiping Ji, Wenbo Zhang, and Simon Lucey. Re- thinking attention: Polynomial alternatives to softmax in transformers.arXiv preprint arXiv:2410.18613, 2024
arXiv 2024
-
[45]
Jason Ramapuram, Federico Danieli, Eeshan Dhekane, Floris Weers, Dan Busbridge, Pierre Ablin, Tatiana Likhomanenko, Jagrit Digani, Zijin Gu, Amitis Shidani, et al. Theory, analysis, and best practices for sigmoid self-attention.arXiv preprint arXiv:2409.04431, 2024. 12 A Toy Models of Attention Sinks A.1 Toy Model of NOP We implement the NOP task from sec...
arXiv 2024
-
[46]
Clipped-softmax attention.Clipped-softmax [ 20] replaces the usual row-wise softmax with a stretched-and-clipped variant. First form standard softmax weights ˜A= softmax(S)∈R n×n,˜a ij = esij Pn k=1 esik .(30) Given hyperparametersζ≥1,γ≤0, define the elementwise clipped-softmax clipped_softmax(S;ζ, γ) := clip (ζ−γ) ˜A+γ,0,1 ,(31) whereclip(x,0,1)truncates...
-
[47]
ReLU-attention with 1/n sequence-length scaling.ReLU-attention [ 43] uses a pointwise ReLU on scores and normalizes only by sequence length. For each pair(i, j), aReLU ij = 1 n ReLU(sij) = 1 n max{sij,0},(33) so the attention matrix is AReLU = 1 n ReLU(S)(elementwise).(34) The output is AttnReLU(X) =A ReLUV= 1 n ReLU(S)V.(35) Rows of AReLU are not normali...
-
[48]
General scaled point-wise attention family.This family generalizes ReLU-attention by replac- ing softmax with a generic elementwise nonlinearity plus a length-dependent scaling [44]. For an activationh:R→Rand exponentα∈[0,1], define a(h,α) ij =n −α h(sij),A h,α =n −αh(S)(elementwise).(36) 18 The attention output is Attnh,α(X) =A h,αV=n −αh(S)V,(37) with h...
-
[49]
dynamic scale
Polynomial attention with p 1/n scaling.Polynomial attention [ 44] replaces the softmax by an elementwise polynomial of the scores, with a p 1/n prefactor chosen to control the Frobenius norm of the attention matrix. Starting from the same score matrix S, define for a degree-p >0 power Apoly = r 1 n S⊙p,(38) whereS ⊙p denotes the elementwise power(S ⊙p)ij...
-
[50]
easy-to-attend
Sigmoid self-attention.Sigmoid attention [ 45] replaces row-wise softmax by an elementwise sigmoid with an additive bias that can depend onn. With the sameS, define σb(u) := 1 +e −(u+b) −1 (40) for a learnable or hand-chosen biasb(scalar or matrix). Then Asig =σ b(S)(elementwise), a sig ij =σ sij +b ,(41) and Attnsig(X) =A sigV=σ b(S)V.(42) Rows of Asig a...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.