Active Flow Expansion for Out-of-Distribution Discovery: from Theory to Molecules
Pith reviewed 2026-06-27 18:32 UTC · model grok-4.3
The pith
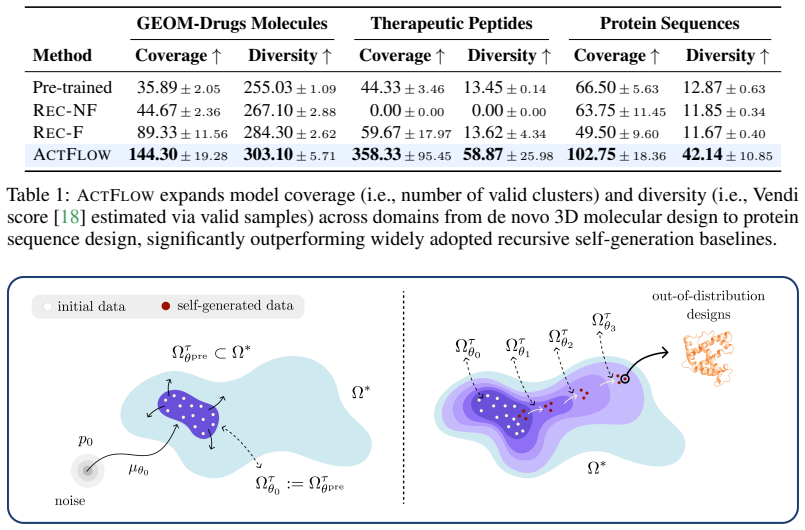
ActFlow enlarges a pre-trained flow model's generable set to cover new valid designs outside the initial data distribution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that Active Flow Expansion enlarges the generable set of a pre-trained flow model to increase coverage of the valid design space by iteratively adapting the model to synthetic data generated through active exploration in the learned representation, guided by verifier feedback, and that this process admits statistical learning guarantees for out-of-distribution flow modeling.
What carries the argument
Active Flow Expansion (ActFlow), a continued pre-training procedure that treats the generable set as the object to enlarge and uses verifier feedback on actively explored synthetic samples to adapt the model beyond its initial support.
If this is right
- A pre-trained flow model can be continued to sample valid designs that receive negligible probability under the original fit.
- Generable-set expansion is analyzed as a local-to-global reachability process that yields the first statistical learning guarantees for out-of-distribution flow modeling.
- The approach outperforms widely used synthetic flow pre-training baselines on molecule, peptide, and protein sequence tasks.
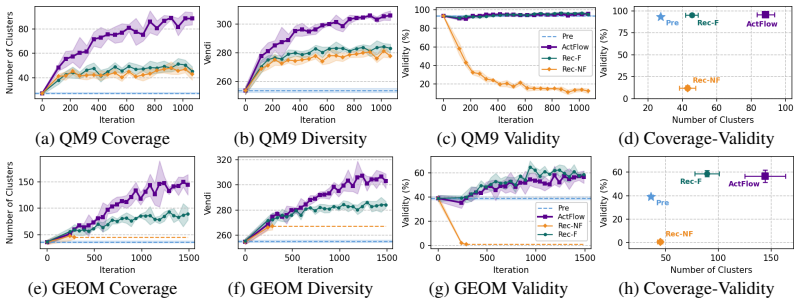
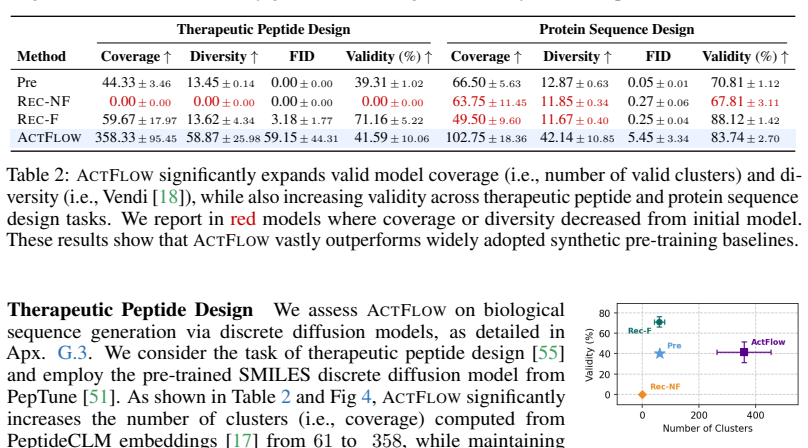
- Coverage gains are demonstrated on small organic molecules, mid-sized drug-like molecules, therapeutic peptides, and protein sequences.
Where Pith is reading between the lines
- If the verifier remains reliable at larger scales, the same loop could be applied to other domains where validity oracles exist but exhaustive data collection is impossible.
- The local-to-global reachability framing suggests that similar expansion procedures might be derived for diffusion models or other generative architectures whose support is also initially limited by training data.
- Repeated cycles of expansion could gradually map larger fractions of the valid design space, provided the verifier does not degrade as the generated distribution shifts.
Load-bearing premise
Verifier feedback on synthetic data from active exploration inside the learned flow reliably marks new valid regions without introducing bias or false positives that halt or corrupt the expansion.
What would settle it
A controlled experiment in which ActFlow produces no measurable increase in valid coverage on a task where independent enumeration confirms the existence of valid designs outside the initial distribution and where the verifier is known to be accurate.
Figures


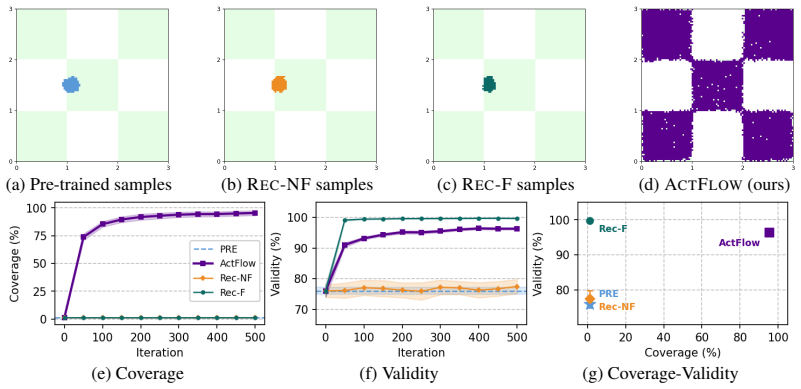


read the original abstract
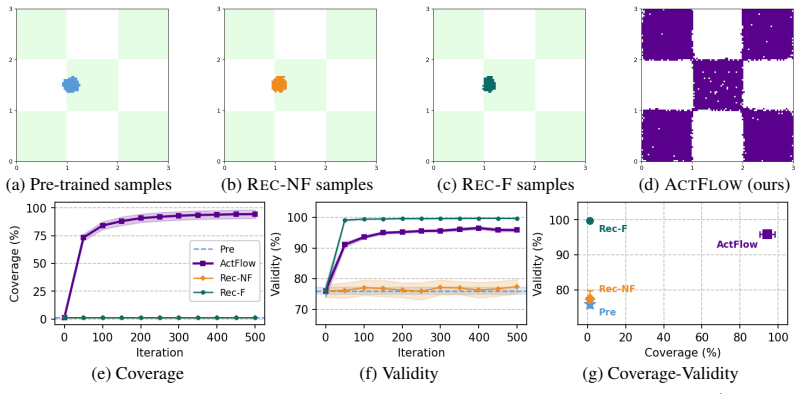
Standard flow and diffusion pre-training matches the distribution of available data (e.g., molecules), which often covers only a small fraction of the valid design space. In generative discovery, however, one aims to sample valid new-to-nature designs, assigned negligible probability under, and thus inaccessible to, standard models fitted to the observed data. To overcome this limitation, we depart from data distribution matching and view a generative model through its generable set: the region it covers with non-negligible probability. This allows to introduce a new learning principle for out-of-distribution flow modeling: enlarging a model's generable set to increase coverage of the valid design space. We propose Active Flow Expansion (ActFlow), a continued pre-training method that employs verifier feedback to expand a pre-trained model over new valid regions by iteratively adapting to synthetic data generated through active exploration in the learned flow representation. Theoretically, we establish to our knowledge first-of-their-kind statistical learning guarantees for out-of-distribution flow modeling, analyzing generable set expansion as a local-to-global reachability process over a learned representation. Empirically, we assess ActFlow with suitable out-of-distribution generative modeling metrics across small organic molecules, mid-sized drug-like molecules, therapeutic peptides, and protein sequence design tasks. Results show that ActFlow expands valid coverage far beyond the region modeled by the initial pre-trained model, significantly outperforming widely adopted synthetic flow pre-training methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Active Flow Expansion (ActFlow), a continued pre-training method for flow-based generative models that enlarges the model's generable set beyond the initial data distribution. It uses verifier feedback on synthetic samples generated via active exploration in the learned flow representation to iteratively adapt the model toward new valid regions. The manuscript claims first-of-their-kind statistical learning guarantees analyzing this expansion as a local-to-global reachability process, and reports empirical outperformance over standard synthetic flow pre-training on OOD generative metrics for small organic molecules, drug-like molecules, therapeutic peptides, and protein sequences.
Significance. If the theoretical guarantees are rigorous and the empirical coverage gains are not artifacts of verifier bias, the work could meaningfully advance generative discovery by shifting focus from distribution matching to explicit expansion of valid coverage. The empirical results across multiple molecular domains and the emphasis on OOD metrics are strengths, but significance is tempered by the load-bearing role of unanalyzed verifier reliability outside the training support.
major comments (3)
- [Theoretical analysis] Theoretical analysis (reachability process): the statistical learning guarantees treat verifier feedback on actively generated OOD samples as a reliable mechanism for identifying new valid regions, but provide no error analysis, false-positive bounds, or robustness to distribution shift in the verifier. This assumption is load-bearing for the local-to-global claim and the reported coverage expansion.
- [Empirical evaluation] Empirical evaluation section: the OOD generative modeling metrics and coverage gains may reduce to quantities defined by the active exploration parameters and verifier thresholds, creating potential circularity; no ablation or sensitivity analysis on verifier calibration outside the original support is reported.
- [Abstract and method] Abstract and method description: the central claim of 'significantly outperforming widely adopted synthetic flow pre-training methods' rests on the verifier correctly labeling new valid regions without systematic bias, yet no data exclusion criteria, verifier training details, or failure-mode analysis for false positives are provided.
minor comments (2)
- [Introduction] Notation for 'generable set' is introduced without a formal definition or comparison to related concepts such as support or mode coverage in the flow literature.
- [Figures] Figure captions for the molecular tasks should explicitly state the number of runs, error bars, and whether the initial pre-trained model is held fixed across baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and for recognizing the potential of shifting focus from distribution matching to explicit generable-set expansion. We address each major comment below with clarifications on assumptions and empirical design, indicating revisions where appropriate.
read point-by-point responses
-
Referee: [Theoretical analysis] Theoretical analysis (reachability process): the statistical learning guarantees treat verifier feedback on actively generated OOD samples as a reliable mechanism for identifying new valid regions, but provide no error analysis, false-positive bounds, or robustness to distribution shift in the verifier. This assumption is load-bearing for the local-to-global claim and the reported coverage expansion.
Authors: The statistical guarantees formalize the local-to-global reachability of the generable set in the learned flow representation, treating verifier feedback as an external labeling mechanism (standard in oracle-based active learning). The analysis does not claim robustness to arbitrary verifier errors; it quantifies expansion given reliable validity signals. We agree that explicit error bounds would strengthen the result and will add a dedicated paragraph discussing this modeling assumption and its implications in the revised theoretical section. revision: yes
-
Referee: [Empirical evaluation] Empirical evaluation section: the OOD generative modeling metrics and coverage gains may reduce to quantities defined by the active exploration parameters and verifier thresholds, creating potential circularity; no ablation or sensitivity analysis on verifier calibration outside the original support is reported.
Authors: OOD metrics are computed via domain-specific validity oracles (e.g., RDKit validity for molecules, sequence validity rules for peptides/proteins) that are independent of the training verifier. Coverage is measured as the fraction of valid samples lying outside the initial data support. We will incorporate sensitivity analyses on verifier threshold and exploration radius in the revised empirical section to address calibration concerns. revision: yes
-
Referee: [Abstract and method] Abstract and method description: the central claim of 'significantly outperforming widely adopted synthetic flow pre-training methods' rests on the verifier correctly labeling new valid regions without systematic bias, yet no data exclusion criteria, verifier training details, or failure-mode analysis for false positives are provided.
Authors: The method section details that the verifier is trained via supervised learning on the initial in-distribution data using standard splits and cross-validation; data exclusion follows published dataset protocols (ZINC, ChEMBL, peptide and protein databases). The multi-domain empirical results provide indirect evidence against systematic bias. We will expand the method description with explicit exclusion criteria and a short failure-mode paragraph in the revision. revision: partial
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper defines a new learning principle around enlarging the generable set of a flow model and proposes ActFlow as an iterative method using active exploration and verifier feedback, supported by statistical learning guarantees framed as a local-to-global reachability analysis. No equations or definitions are shown to reduce the claimed guarantees or expansion metrics directly to the input parameters or verifier thresholds by construction. The theoretical component is presented as an independent analysis of the reachability process rather than a tautology, and empirical claims are benchmarked against external baselines without evidence of fitted quantities being relabeled as predictions. No load-bearing self-citations, imported uniqueness theorems, or ansatz smuggling are identifiable from the text. The overall derivation remains self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Data unlearning in diffusion models
Silas Alberti, Kenan Hasanaliyev, Manav Shah, and Stefano Ermon. Data unlearning in diffusion models. In Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, editors,International Conference on Learning Representations, volume 2025, pages 3084–3100, 2025. 10
2025
-
[2]
Self-consuming generative models go mad
Sina Alemohammad, Josue Casco-Rodriguez, Lorenzo Luzi, Ahmed Imtiaz Humayun, Hossein Babaei, Daniel LeJeune, Ali Siahkoohi, and Richard Baraniuk. Self-consuming generative models go mad. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[3]
Self-improving diffusion models with synthetic data.arXiv preprint arXiv:2408.16333, 2024
Sina Alemohammad, Ahmed Imtiaz Humayun, Shruti Agarwal, John Collomosse, and Richard Baraniuk. Self-improving diffusion models with synthetic data.arXiv preprint arXiv:2408.16333, 2024
arXiv 2024
-
[4]
Geom, energy-annotated molecular conforma- tions for property prediction and molecular generation.Scientific Data, 9(1):185, 2022
Simon Axelrod and Rafael Gomez-Bombarelli. Geom, energy-annotated molecular conforma- tions for property prediction and molecular generation.Scientific Data, 9(1):185, 2022
2022
-
[5]
Shekoofeh Azizi, Simon Kornblith, Chitwan Saharia, Mohammad Norouzi, and David J Fleet. Synthetic data from diffusion models improves imagenet classification.arXiv preprint arXiv:2304.08466, 2023
arXiv 2023
-
[6]
Safe model-based reinforcement learning with stability guarantees.Advances in neural information processing systems, 30, 2017
Felix Berkenkamp, Matteo Turchetta, Angela Schoellig, and Andreas Krause. Safe model-based reinforcement learning with stability guarantees.Advances in neural information processing systems, 30, 2017
2017
-
[7]
Oxford University Press, 2013
St´ephane Boucheron, G ´abor Lugosi, and Pascal Massart.Concentration Inequalities: A Nonasymptotic Theory of Independence. Oxford University Press, 2013
2013
-
[8]
DIME: Diffusion-based maximum entropy reinforcement learning
Onur Celik, Zechu Li, Denis Blessing, Ge Li, Daniel Palenicek, Jan Peters, Georgia Chalvatzaki, and Gerhard Neumann. DIME: Diffusion-based maximum entropy reinforcement learning. In Forty-second International Conference on Machine Learning, 2025
2025
-
[9]
Yongcan Chen, Ruyun Hu, Keyi Li, Yating Zhang, Lihao Fu, Jianzhi Zhang, and Tong Si. Deep mutational scanning of an oxygen-independent fluorescent protein creilov for comprehensive profiling of mutational and epistatic effects.ACS Synthetic Biology, 12(5):1461–1473, 2023
2023
-
[10]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[11]
Diffdock: Diffusion steps, twists, and turns for molecular docking
Gabriele Corso, Hannes St¨ark, Bowen Jing, Regina Barzilay, and Tommi Jaakkola. Diffdock: Diffusion steps, twists, and turns for molecular docking. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[12]
Verifier-constrained flow expansion for discovery beyond the data
Riccardo De Santi, Kimon Protopapas, Ya-Ping Hsieh, and Andreas Krause. Verifier-constrained flow expansion for discovery beyond the data. InInternational Conference on Learning Representations (ICLR), April 2026
2026
-
[13]
Flow density control: Generative optimization beyond entropy-regularized fine-tuning
Riccardo De Santi, Marin Vlastelica, Ya-Ping Hsieh, Zebang Shen, Niao He, and Andreas Krause. Flow density control: Generative optimization beyond entropy-regularized fine-tuning. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[14]
Provable maximum entropy manifold exploration via diffusion models
Riccardo De Santi, Marin Vlastelica, Ya-Ping Hsieh, Zebang Shen, Niao He, and Andreas Krause. Provable maximum entropy manifold exploration via diffusion models. InInternational Conference on Machine Learning, 2025
2025
-
[15]
RAFT: Reward ranked finetuning for generative foundation model alignment.Transactions on Machine Learning Research, 2023
Hanze Dong, Wei Xiong, Deepanshu Goyal, Yihan Zhang, Winnie Chow, Rui Pan, Shizhe Diao, Jipeng Zhang, KaShun SHUM, and Tong Zhang. RAFT: Reward ranked finetuning for generative foundation model alignment.Transactions on Machine Learning Research, 2023
2023
-
[16]
Mixed continuous and categorical flow matching for 3d de novo molecule generation.ArXiv, pages arXiv–2404, 2024
Ian Dunn and David Ryan Koes. Mixed continuous and categorical flow matching for 3d de novo molecule generation.ArXiv, pages arXiv–2404, 2024
2024
-
[17]
Feller and Claus O
Aaron L. Feller and Claus O. Wilke. Peptide-specific chemical language model successfully predicts membrane diffusion of cyclic peptides.bioRxiv, 2024
2024
-
[18]
The vendi score: A diversity evaluation metric for machine learning.Trans
Dan Friedman and Adji Bousso Dieng. The vendi score: A diversity evaluation metric for machine learning.Trans. Mach. Learn. Res., 2023, 2022. 11
2023
-
[19]
Reinforced self-training (rest) for language modeling.arXiv preprint arXiv:2308.08998, 2023
Caglar Gulcehre, Tom Le Paine, Srivatsan Srinivasan, Ksenia Konyushkova, Lotte Weerts, Abhishek Sharma, Aditya Siddhant, Alex Ahern, Miaosen Wang, Chenjie Gu, et al. Reinforced self-training (rest) for language modeling.arXiv preprint arXiv:2308.08998, 2023
Pith/arXiv arXiv 2023
-
[20]
Tango: direct optimization of constrained synthesizability for generative molecular design.Nature Computational Science, 2026
Jeff Guo and Philippe Schwaller. Tango: direct optimization of constrained synthesizability for generative molecular design.Nature Computational Science, 2026
2026
-
[21]
Constrained molecular generation via sequential flow model fine-tuning
Sven Gutjahr, Riccardo De Santi, Luca Schaufelberger, Kjell Jorner, and Andreas Krause. Constrained molecular generation via sequential flow model fine-tuning. InInternational Conference on Machine Learning (ICML), 2026
2026
-
[22]
Merck molecular force field
Thomas A Halgren. Merck molecular force field. i. basis, form, scope, parameterization, and performance of mmff94.Journal of computational chemistry, 17(5-6):490–519, 1996
1996
-
[23]
Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
2017
-
[24]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[25]
Equivariant diffusion for molecule generation in 3d
Emiel Hoogeboom, Vıctor Garcia Satorras, Cl´ement Vignac, and Max Welling. Equivariant diffusion for molecule generation in 3d. InInternational conference on machine learning, pages 8867–8887. PMLR, 2022
2022
-
[26]
Highly accurate protein structure prediction with alphafold.nature, 596(7873):583–589, 2021
John Jumper, Richard Evans, Alexander Pritzel, Tim Green, Michael Figurnov, Olaf Ron- neberger, Kathryn Tunyasuvunakool, Russ Bates, Augustin ˇZ´ıdek, Anna Potapenko, et al. Highly accurate protein structure prediction with alphafold.nature, 596(7873):583–589, 2021
2021
-
[27]
Learning-based model predictive control for safe exploration
Torsten Koller, Felix Berkenkamp, Matteo Turchetta, and Andreas Krause. Learning-based model predictive control for safe exploration. In2018 IEEE conference on decision and control (CDC), pages 6059–6066. IEEE, 2018
2018
-
[28]
Adaptive estimation of a quadratic functional by model selection.The Annals of Statistics, 28(5):1302–1338, 2000
B´eatrice Laurent and Pascal Massart. Adaptive estimation of a quadratic functional by model selection.The Annals of Statistics, 28(5):1302–1338, 2000
2000
-
[29]
Smiles pair encoding: a data-driven substructure tokenization algorithm for deep learning.Journal of chemical information and modeling, 61(4):1560–1569, 2021
Xinhao Li and Denis Fourches. Smiles pair encoding: a data-driven substructure tokenization algorithm for deep learning.Journal of chemical information and modeling, 61(4):1560–1569, 2021
2021
-
[30]
Language models of protein sequences at the scale of evolution enable accurate structure prediction
Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Nikita Smetanin, Allan dos Santos Costa, Maryam Fazel-Zarandi, Tom Sercu, Sal Candido, et al. Language models of protein sequences at the scale of evolution enable accurate structure prediction. bioRxiv, 2022
2022
-
[31]
Flow matching for generative modeling.International Conference on Learning Representations (ICLR), 2023
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.International Conference on Learning Representations (ICLR), 2023
2023
-
[32]
Flow matching guide and code.arXiv preprint arXiv:2412.06264, 2024
Yaron Lipman, Marton Havasi, Peter Holderrieth, Neta Shaul, Matt Le, Brian Karrer, Ricky TQ Chen, David Lopez-Paz, Heli Ben-Hamu, and Itai Gat. Flow matching guide and code.arXiv preprint arXiv:2412.06264, 2024
Pith/arXiv arXiv 2024
-
[33]
Flow-grpo: Training flow matching models via online rl
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via online rl. Advances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[34]
Discrete diffusion modeling by estimating the ratios of the data distribution.International Conference on Learning Representations (ICLR), 2024
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution.International Conference on Learning Representations (ICLR), 2024
2024
-
[35]
Do we need all the syn- thetic data? targeted image augmentation via diffusion models
Dang Nguyen, Jiping Li, Jinghao Zheng, and Baharan Mirzasoleiman. Do we need all the syn- thetic data? targeted image augmentation via diffusion models. InThe Fourteenth International Conference on Learning Representations, 2026. 12
2026
-
[36]
Your absorbing discrete diffusion secretly models the conditional distributions of clean data
Jingyang Ou, Shen Nie, Kaiwen Xue, Fengqi Zhu, Jiacheng Sun, Zhenguo Li, and Chongxuan Li. Your absorbing discrete diffusion secretly models the conditional distributions of clean data. International Conference on Learning Representations (ICLR), 2025
2025
-
[37]
Bandits with preference feedback: A stackelberg game perspective.Advances in Neural Information Processing Systems, 37:11997– 12034, 2024
Barna P´asztor, Parnian Kassraie, and Andreas Krause. Bandits with preference feedback: A stackelberg game perspective.Advances in Neural Information Processing Systems, 37:11997– 12034, 2024
2024
-
[38]
Imitating human behaviour with diffusion models.International Conference on Learning Representations (ICLR), 2023
Tim Pearce, Tabish Rashid, Anssi Kanervisto, Dave Bignell, Mingfei Sun, Raluca Georgescu, Sergio Valcarcel Macua, Shan Zheng Tan, Ida Momennejad, Katja Hofmann, et al. Imitating human behaviour with diffusion models.International Conference on Learning Representations (ICLR), 2023
2023
-
[39]
Value matching: Scalable and gradient-free reward-guided flow adaptation
Cristian Perez Jensen, Luca Schaufelberger, Riccardo De Santi, Kjell Jorner, and Andreas Krause. Value matching: Scalable and gradient-free reward-guided flow adaptation. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[40]
Quantum chemistry structures and properties of 134 kilo molecules.Scientific data, 1(1):1–7, 2014
Raghunathan Ramakrishnan, Pavlo O Dral, Matthias Rupp, and O Anatole V on Lilienfeld. Quantum chemistry structures and properties of 134 kilo molecules.Scientific data, 1(1):1–7, 2014
2014
-
[41]
Jarrid Rector-Brooks, Th´eophile Lambert, Marta Skreta, Daniel Roth, Yueming Long, Zi-Qi Li, Xi Zhang, Miruna Cretu, Francesca-Zhoufan Li, Tanvi Ganapathy, et al. General multimodal protein design enables dna-encoding of chemistry.arXiv preprint arXiv:2604.05181, 2026
Pith/arXiv arXiv 2026
-
[42]
Simple and effective masked diffusion language models.Advances in Neural Information Processing Systems, 37:130136–130184, 2024
Subham Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin Chiu, Alexander Rush, and V olodymyr Kuleshov. Simple and effective masked diffusion language models.Advances in Neural Information Processing Systems, 37:130136–130184, 2024
2024
-
[43]
A generalized representer theorem
Bernhard Sch¨olkopf, Ralf Herbrich, and Alex J Smola. A generalized representer theorem. In International conference on computational learning theory, pages 416–426. Springer, 2001
2001
-
[44]
Simplified and generalized masked diffusion for discrete data.Advances in neural information processing systems, 37:103131–103167, 2024
Jiaxin Shi, Kehang Han, Zhe Wang, Arnaud Doucet, and Michalis Titsias. Simplified and generalized masked diffusion for discrete data.Advances in neural information processing systems, 37:103131–103167, 2024
2024
-
[45]
Ai models collapse when trained on recursively generated data.Nature, 631(8022):755– 759, 2024
Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Nicolas Papernot, Ross Anderson, and Yarin Gal. Ai models collapse when trained on recursively generated data.Nature, 631(8022):755– 759, 2024
2024
-
[46]
Deep unsuper- vised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsuper- vised learning using nonequilibrium thermodynamics. InInternational conference on machine learning, pages 2256–2265. PMLR, 2015
2015
-
[47]
Generative modeling by estimating gradients of the data distribution.Advances in neural information processing systems, 32, 2019
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution.Advances in neural information processing systems, 32, 2019
2019
-
[48]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. International Conference on Learning Representations (ICLR), 2021
2021
-
[49]
Safe exploration for optimization with gaussian processes
Yanan Sui, Alkis Gotovos, Joel Burdick, and Andreas Krause. Safe exploration for optimization with gaussian processes. InInternational conference on machine learning, pages 997–1005. PMLR, 2015
2015
-
[50]
Stagewise safe bayesian optimization with gaussian processes
Yanan Sui, Vincent Zhuang, Joel Burdick, and Yisong Yue. Stagewise safe bayesian optimization with gaussian processes. InInternational conference on machine learning, pages 4781–4789. PMLR, 2018
2018
-
[51]
Peptune: De novo generation of therapeutic peptides with multi-objective-guided discrete diffusion.42nd International Conference on Machine Learning, 2025
Sophia Tang, Yinuo Zhang, and Pranam Chatterjee. Peptune: De novo generation of therapeutic peptides with multi-objective-guided discrete diffusion.42nd International Conference on Machine Learning, 2025. 13
2025
-
[52]
Safe exploration in finite markov decision processes with gaussian processes.Advances in neural information processing systems, 29, 2016
Matteo Turchetta, Felix Berkenkamp, and Andreas Krause. Safe exploration in finite markov decision processes with gaussian processes.Advances in neural information processing systems, 29, 2016
2016
-
[53]
Masatoshi Uehara, Yulai Zhao, Tommaso Biancalani, and Sergey Levine. Understanding reinforcement learning-based fine-tuning of diffusion models: A tutorial and review.arXiv preprint arXiv:2407.13734, 2024
arXiv 2024
-
[54]
Masatoshi Uehara, Yulai Zhao, Chenyu Wang, Xiner Li, Aviv Regev, Sergey Levine, and Tom- maso Biancalani. Inference-time alignment in diffusion models with reward-guided generation: Tutorial and review.arXiv preprint arXiv:2501.09685, 2025
arXiv 2025
-
[55]
Therapeutic peptides: current applications and future directions.Signal transduction and targeted therapy, 7(1):48, 2022
Lei Wang, Nanxi Wang, Wenping Zhang, Xurui Cheng, Zhibin Yan, Gang Shao, Xi Wang, Rui Wang, and Caiyun Fu. Therapeutic peptides: current applications and future directions.Signal transduction and targeted therapy, 7(1):48, 2022
2022
-
[56]
De novo design of protein structure and function with rfdiffusion.Nature, 620(7976):1089–1100, 2023
Joseph L Watson, David Juergens, Nathaniel R Bennett, Brian L Trippe, Jason Yim, Helen E Eisenach, Woody Ahern, Andrew J Borst, Robert J Ragotte, Lukas F Milles, et al. De novo design of protein structure and function with rfdiffusion.Nature, 620(7976):1089–1100, 2023
2023
-
[57]
Smiles, a chemical language and information system
David Weininger. Smiles, a chemical language and information system. 1. introduction to methodology and encoding rules.J. Chem. Inf. Comput. Sci., 28(1):31–36, 1988
1988
-
[58]
Wittmann, Frances H
Jason Yang, Wenda Chu, Daniel Khalil, Raul Astudillo, Bruce J. Wittmann, Frances H. Arnold, and Yisong Yue. Steering generative models with experimental data for protein fitness optimiza- tion. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[59]
Self-play fine-tuning of diffusion models for text-to-image generation.Advances in Neural Information Processing Systems, 37:73366–73398, 2024
Huizhuo Yuan, Zixiang Chen, Kaixuan Ji, and Quanquan Gu. Self-play fine-tuning of diffusion models for text-to-image generation.Advances in Neural Information Processing Systems, 37:73366–73398, 2024
2024
-
[60]
Masked diffusion models are secretly time-agnostic masked models and exploit inaccurate categorical sampling.International Conference on Learning Representations (ICLR), 2025
Kaiwen Zheng, Yongxin Chen, Hanzi Mao, Ming-Yu Liu, Jun Zhu, and Qinsheng Zhang. Masked diffusion models are secretly time-agnostic masked models and exploit inaccurate categorical sampling.International Conference on Learning Representations (ICLR), 2025. 14 A Appendix Contents B Central Limitation of Standard Pre-training with an Imperfect Model 16 C A ...
2025
-
[61]
the first term increases likelihood of synthetic samples that have been certified as valid by the verifier and therefore support expansion into new valid regions
-
[62]
the second term decreases likelihood of queried samples that were explicitly rejected by the verifier and therefore encode evidence against those directions of expansion. Thus, unlike standard valid-only pre-training, the signed replay update usesbothoutcomes of the verifier query and converts the online generation-and-verification loop into a principled ...
2080
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.