GPU Acceleration of Collinear and Noncollinear DFT Using a Numerical Atomic Orbital-Based DFT Code
Pith reviewed 2026-06-27 14:31 UTC · model grok-4.3
The pith
GPU acceleration in OpenMX yields 2.02x and 2.60x speedups for collinear and noncollinear DFT on two nodes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
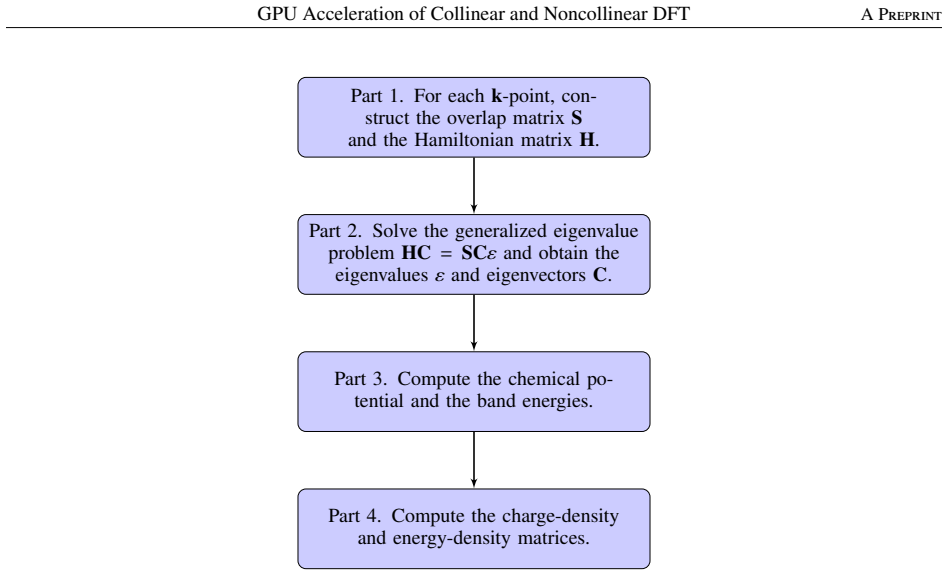
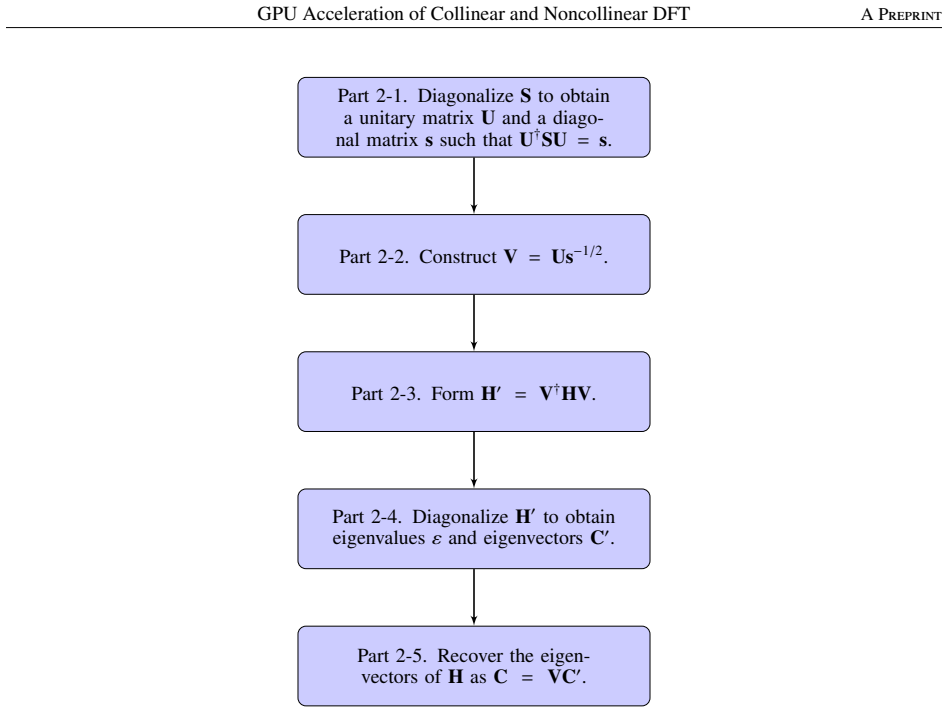
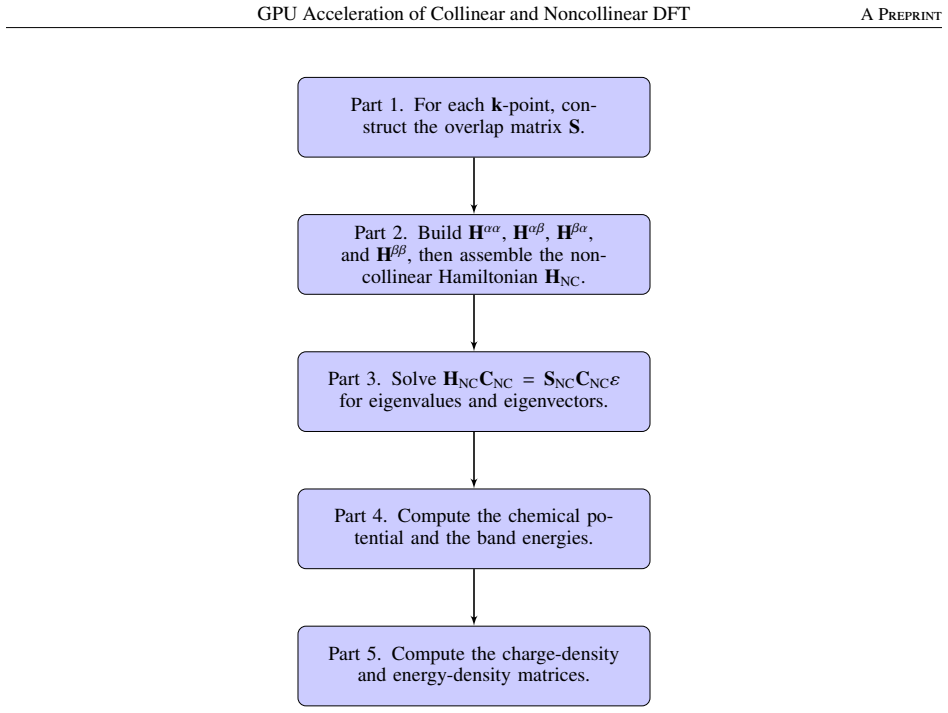
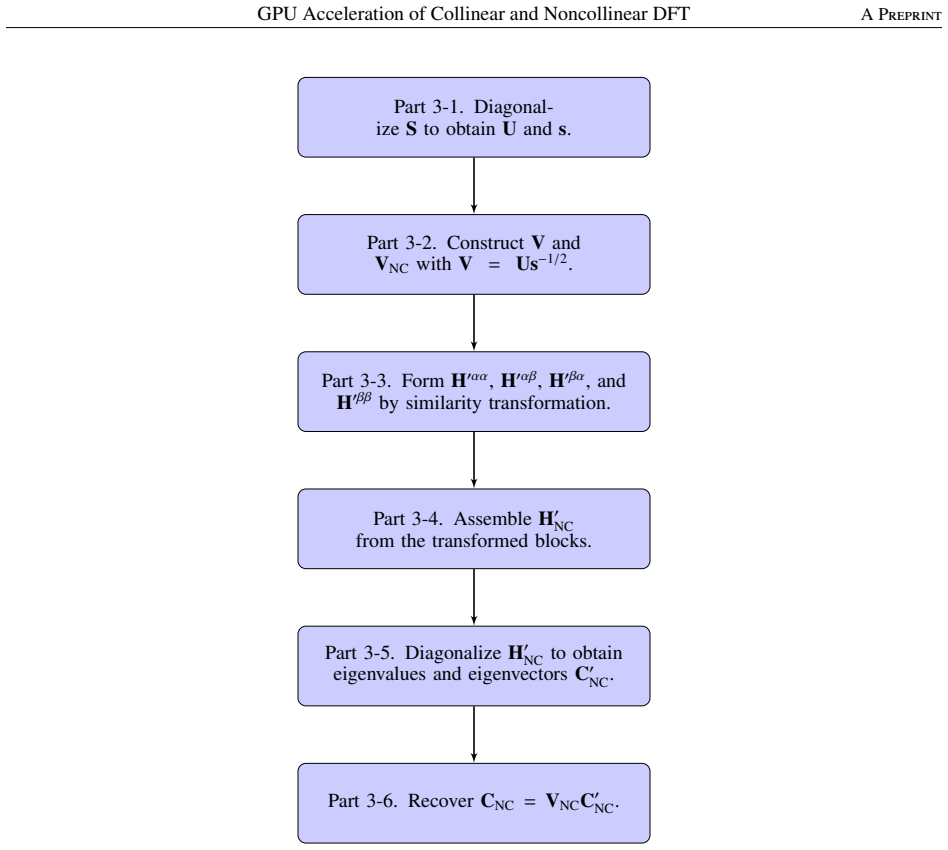
We implement GPU acceleration of collinear and noncollinear density functional theory (DFT) calculations in the numerical atomic orbitals (NAOs) code OpenMX by offloading matrix multiplications and eigenvalue solves (plus selected auxiliary steps) to cuBLAS/cuSOLVER and OpenACC. Benchmarks on the Pegasus supercomputer (per node: a 48-core Intel Xeon Platinum 8468 CPU and one NVIDIA H100 GPU) compare GPU-accelerated and CPU-only runs under identical settings. For a 512-atom collinear case on two nodes (two GPUs total), the GPU-accelerated calculation achieves a 2.02 times speedup over a CPU-only run on two nodes (96 CPU cores total); for a 384-atom noncollinear case on two nodes (two GPUs tot
What carries the argument
Offloading of matrix multiplications and eigenvalue solves to cuBLAS/cuSOLVER together with OpenACC directives in the OpenMX NAO-DFT implementation.
If this is right
- GPU acceleration becomes available inside an existing NAO-based DFT code for both collinear and noncollinear spin treatments.
- A single GPU per node can outperform a full node of 48 CPU cores by a factor of roughly two for the tested system sizes.
- The same offloading strategy works for noncollinear calculations that are typically more expensive than collinear ones.
- No change to the numerical atomic orbital basis or to the DFT Hamiltonian construction is required to obtain the measured gains.
Where Pith is reading between the lines
- The same offloading pattern could be ported to other NAO codes that already rely on dense linear algebra for the same steps.
- Speedup ratios may change if the number of GPUs per node increases or if the CPU-only baseline uses fewer cores per node.
- The approach could make routine noncollinear DFT studies of larger magnetic or spin-orbit systems more feasible on GPU-equipped clusters.
- Direct comparison of the same input files on a wider range of GPU generations would test how portable the observed gains remain.
Load-bearing premise
The reported speedups assume that the chosen benchmark systems, node configurations, and identical settings on the Pegasus supercomputer produce representative performance numbers for typical user workloads.
What would settle it
Running the same OpenMX GPU-accelerated and CPU-only calculations on a different hardware platform with different CPU-GPU balance or on systems substantially larger or smaller than 384-512 atoms and measuring whether the 2.0-2.6x speedups persist.
Figures





read the original abstract
We implement GPU acceleration of collinear and noncollinear density functional theory (DFT) calculations in the numerical atomic orbitals (NAOs) code OpenMX by offloading matrix multiplications and eigenvalue solves (plus selected auxiliary steps) to cuBLAS/cuSOLVER and OpenACC. Benchmarks on the Pegasus supercomputer (per node: a 48-core Intel Xeon Platinum 8468 CPU and one NVIDIA H100 GPU) compare GPU-accelerated and CPU-only runs under identical settings. For a 512-atom collinear case on two nodes (two GPUs total), the GPU-accelerated calculation achieves a 2.02 times speedup over a CPU-only run on two nodes (96 CPU cores total); for a 384-atom noncollinear case on two nodes (two GPUs total), the speedup is 2.60 times over two CPU-only nodes (96 cores). These results demonstrate practical GPU-accelerated DFT in an NAO-based code for both collinear and noncollinear calculations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes an implementation of GPU acceleration for collinear and noncollinear DFT in the numerical atomic orbital code OpenMX. Selected linear-algebra kernels (matrix multiplications and eigenvalue solves) plus auxiliary steps are offloaded to cuBLAS/cuSOLVER with OpenACC directives. Direct wall-time benchmarks on the Pegasus supercomputer (48-core Xeon Platinum 8468 + one H100 GPU per node) report a 2.02× speedup for a 512-atom collinear system on two nodes (two GPUs vs. 96 CPU cores) and a 2.60× speedup for a 384-atom noncollinear system under identical settings.
Significance. If the reported timings are reproducible, the work supplies concrete evidence that standard GPU libraries can deliver practical acceleration in an established NAO-based DFT package for both collinear and noncollinear cases. The direct, controlled comparison on identical node configurations is a strength for an engineering implementation paper and could inform users running magnetism or spin-orbit calculations.
major comments (2)
- [Implementation and Results sections] The manuscript states concrete benchmark numbers but provides insufficient implementation detail on which exact routines were offloaded, how data movement between host and device was managed, and what fraction of runtime remains on the CPU. This information is load-bearing for the central performance claim because the reported 2.02× and 2.60× speedups cannot be assessed for generality or communication overhead without it.
- [Benchmark subsection] No validation tests (e.g., total-energy or force comparisons between GPU and CPU runs on the same systems) or overhead breakdown (cuBLAS time vs. data-transfer time) are presented. Without these, it is impossible to confirm that the acceleration preserves numerical accuracy or that the speedups are not dominated by unoffloaded portions of the code.
minor comments (1)
- [Abstract and Results] The abstract and text refer to “identical settings” but do not explicitly list the OpenMX input parameters (basis set, cutoff, k-points, SCF convergence) used for the 512-atom and 384-atom benchmarks; adding a short table would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and will revise the manuscript to incorporate the requested details and tests.
read point-by-point responses
-
Referee: [Implementation and Results sections] The manuscript states concrete benchmark numbers but provides insufficient implementation detail on which exact routines were offloaded, how data movement between host and device was managed, and what fraction of runtime remains on the CPU. This information is load-bearing for the central performance claim because the reported 2.02× and 2.60× speedups cannot be assessed for generality or communication overhead without it.
Authors: We agree that additional implementation specifics are needed for a complete assessment. In the revised manuscript we will expand the Implementation section to list the exact offloaded routines (e.g., cublasDgemm, cublasZgemm, and the specific cuSOLVER eigensolvers), describe the OpenACC data clauses and host-device transfer strategy used to minimize communication, and report profiling-derived fractions of runtime spent on the CPU versus the GPU for the benchmark systems. revision: yes
-
Referee: [Benchmark subsection] No validation tests (e.g., total-energy or force comparisons between GPU and CPU runs on the same systems) or overhead breakdown (cuBLAS time vs. data-transfer time) are presented. Without these, it is impossible to confirm that the acceleration preserves numerical accuracy or that the speedups are not dominated by unoffloaded portions of the code.
Authors: We acknowledge the absence of these elements in the submitted version. The revised manuscript will include a dedicated validation subsection reporting total-energy and force differences between CPU-only and GPU runs on the same systems (confirming agreement to machine precision) together with a timing breakdown separating cuBLAS/cuSOLVER kernel execution from data-transfer overhead. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an engineering report on GPU offloading of matrix operations and eigensolves in OpenMX, with claims consisting solely of measured wall-time ratios (2.02x collinear, 2.60x noncollinear) on Pegasus nodes. No derivation chain, equations, fitted parameters, or self-citation load-bearing steps exist; the results are direct empirical timings under identical settings and reduce to the benchmark data themselves.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
J. D. Owens, M. Houston, D. Luebke, S. Green, J. E. Stone, and J. C. Phillips, Proc. IEEE96, 879 (2008)
2008
-
[2]
S. W. Keckler, inProceedings of the 2011 IEEE International Symposium on Workload Characterization (IISWC’11)(IEEE, Austin, TX, 2011), p. 1
2011
-
[3]
Peši ´c, and R
J. Peši ´c, and R. Gaji´c, Phys. Scr.T162014027 (2014)
2014
-
[4]
Carabaño, F
J. Carabaño, F. Dios, M. Daneshtalab, and M. Ebrahimi, inProceedings of the 2013 8th International Workshop on Reconfigurable and Communication-Centric Systems-on-Chip (ReCoSoC’13)(IEEE, Darmstadt, Germany, 2013), pp. 1–7. 22 GPU Acceleration of Collinear and Noncollinear DFTA Preprint
2013
-
[5]
Mittal, and J
S. Mittal, and J. S. Vetter, ACM Comput. Surv.47, 4, Article 69 (2015)
2015
-
[6]
D. C. Jespersen, Scientific Programming,18, 193 (2010)
2010
-
[7]
R. Ginjupalli, and G. Khanna, arXiv:1006.0663 [physics.comp-ph] (2010)
Pith/arXiv arXiv 2010
-
[8]
W. P. Huhn, B. Lange, V . Wen-zhe Yu, M. Yoon, and V . Blum, Comp. Phys. Comm.254, 107314 (2020)
2020
-
[9]
Yasuda, J
K. Yasuda, J. Comput. Chem.29, 334 (2007)
2007
-
[10]
Yasuda, J
K. Yasuda, J. Chem. Theory Comput.4, 1230 (2008)
2008
-
[11]
K. A. Wilkinson, P. Sherwood, M. F. Guest, and K. J. Naidoo, J. Comput. Chem.32, 2313 (2011)
2011
-
[12]
D. B. Williams-Young, W. A. de Jong, H. J. J. van Dam, and C. Yang, Front. Chem.10, 8 (2020)
2020
-
[13]
Genovese, M
L. Genovese, M. Ospici, T. Deutsch, J.-F. Méhaut, A. Neelov, and S. Goedecker, J. Chem. Phys.131, 034103 (2009)
2009
-
[14]
Genovese, B
L. Genovese, B. Videau, D. Caliste, J.-F. Méhaut, S. Goedecker, and T. Deutsch, inElectronic Structure Calcu- lations on Graphics Processing Units: From Quantum Chemistry to Condensed Matter Physics, edited by R. C. Walker and A. W. Götz (John Wiley & Sons, Ltd., West Sussex, 2016), Chap. 6, pp. 115-134
2016
-
[15]
Wortmann, S
D. Wortmann, S. Baroni, A. Degomme, P. Delugas, S. de Gironcoli, A. Ferretti, A. García, L. Genovese, P. Giannozzi, A. Kozhevnikov and N. Spallanzani,Second Release ofMaXSoftware: Report on Performance Achieved, Deliverable D2.2 (H2020 CoE MaX, Jülich, 2020)
2020
- [16]
-
[17]
Hohenberg, and W
P. Hohenberg, and W. Kohn, Phys. Rev.136, 864 (1964)
1964
-
[18]
Kohn, and L
W. Kohn, and L. J. Sham, Phys. Rev.140, 1133 (1965)
1965
-
[19]
Burke, J
K. Burke, J. Chem. Phys.136, 150901 (2012)
2012
-
[20]
R. O. Jones, Newsletter124, 1 (2014)
2014
-
[21]
A. D. Becke, J. Chem. Phys.140, 18A301 (2014)
2014
-
[22]
A. Jain, Y . Shin, and K.A. Persson, Nature Rev. Mater.1, 1 (2016)
2016
-
[23]
M. C. Payne, M. P. Teter, D. C. Allan, T. A. Arias, and J. D. Joannopoulos, Rev. Modern Phys.64, 1046 (1992)
1992
-
[24]
Kresse, and J
G. Kresse, and J. Furthmüller, Phys. Rev. B54, 11169 (1996)
1996
-
[25]
Giannozzi, S
P. Giannozzi, S. Baroni, N. Bonini, M. Calandra, R. Car, C. Cavazzoni, D. Ceresoli, G. L. Chiarotti, M. Cococ- cioni, I. Dabo, A. Dal Corso, S. de Gironcoli, S. Fabris, G. Fratesi, R. Gebauer, U. Gerstmann, C. Gougoussis, A. Kokalj, M. Lazzeri, L. Martin-Samos, N. Marzari, F. Mauri, R. Mazzarello, S. Paolini, A. Pasquarello, L. Paulatto, C. Sbraccia, S. S...
2009
-
[26]
Gonze, J.-M
X. Gonze, J.-M. Beuken, R. Caracas, F. Detraux, M. Fuchs, G.-M. Rignanese, L. Sindic, M. Verstraete, G. Zerah, F. Jollet, M. Torrent, A. Roy, M. Mikami, Ph. Ghosez, J.-Y . Raty, and D. C. Allan, Comput. Mater. Sci.25, 478 (2002)
2002
-
[27]
S. J. Clark, M. D. Segall, C. J. Pickard, P. J. Hasnip, M. I. J. Probert, K. Refson, M. C. Payne, and Z. Kristallogr. 220, 567 (2005)
2005
-
[28]
M. J. Frisch, J. A. Pople, and J. S. Binkley, J. Chem. Phys.80, 3265 (1984)
1984
-
[29]
T. H. Dunning, J. Chem. Phys.90, 1007 (1989)
1989
-
[30]
Szabo and N
A. Szabo and N. S. Ostlund,Modern Quantum Chemistry: Introduction to Advanced Electronic Structure Theory, 1st ed. (Dover, Mineola, NY , 1996)
1996
-
[31]
A. K. Wilson, T. van Mourik, and T. H. Dunning, J. Mol. Struct.388, 339 (1996)
1996
-
[32]
Weigend, and R
F. Weigend, and R. Ahlrichs, Phys. Chem. Chem. Phys.7, 3297 (2005)
2005
-
[33]
Valiev, E
M. Valiev, E. J. Bylaska, N. Govind, K. Kowalski, T. P. Straatsma, H. J. J. van Dam, D. Wang, J. Nieplocha, E. Apra, T. L. Windus, and W. A. de Jong, Comput. Phys. Commun.181, 1477 (2010)
2010
-
[34]
Hutter, M
J. Hutter, M. Iannuzzi, F. Schiffmann, and J. VandeV ondele, WIREs Comput. Mol. Sci.4, 15 (2014)
2014
-
[35]
te Velde, F
G. te Velde, F. M. Bickelhaupt, E. J. Baerends, C. F. Guerra, S. J. A. van Gisbergen, J. G. Snijders, and T. Ziegler, J. Comput. Chem.22, 931 (2001)
2001
-
[36]
van Lenthe, and E
E. van Lenthe, and E. J. Baerends, J. Comput. Chem.24, 1142 (2003)
2003
-
[37]
F. W. Averill, and D. E. Ellis, J. Chem. Phys59, 6412 (1973). 23 GPU Acceleration of Collinear and Noncollinear DFTA Preprint
1973
-
[38]
Zunger, and A
A. Zunger, and A. J. Freeman, Phys. Rev. B15, 4716 (1977)
1977
-
[39]
Delley, and D
B. Delley, and D. E. Ellis, J. Chem. Phys.76, 1949 (1982)
1949
-
[40]
O. F. Sankey, and D. J. Niklewski, Phys. Rev. B40, 3979 (1989)
1989
-
[41]
Delley, J
B. Delley, J. Chem. Phys.92, 508 (1990)
1990
-
[42]
A. P. Horsfield, Phys. Rev. B56, 6594 (1997)
1997
-
[43]
Koepernik, and H
K. Koepernik, and H. Eschrig, Phys. Rev. B59, 1743 (1999)
1999
-
[44]
J. M. Soler, E. Artacho, J. D. Gale, A. García, J. Junquera, P. Ordejón, and D. Sánchez-Portal, J. Phys. Condens. Matter14, 2745 (2002)
2002
-
[45]
Ozaki, Phys
T. Ozaki, Phys. Rev. B.67, 155108 (2003)
2003
-
[46]
Ozaki and H
T. Ozaki and H. Kino, Phys. Rev. B69, 195113 (2004)
2004
-
[47]
Ozaki and H
T. Ozaki and H. Kino, Phys. Rev. B72, 045121 (2005)
2005
-
[48]
V . Blum, R. Gehrke, F. Hanke, P. Havu, V . Havu, X. Ren, K. Reuter, and M. Scheffler, Comp. Phys. Comm.180, 2175 (2009)
2009
-
[49]
I. Y . Zhang, X. Ren, P. Rinke, V . Blum, and M. Scheffler, New. J. Phys.15, 123033 (2013)
2013
-
[50]
Sánchez-Portal, P
D. Sánchez-Portal, P. Ordejón, E. Artacho, and J. M. Soler, Int. J. Quantum Chem.65, 453 (1997)
1997
-
[51]
Motamarri and V
P. Motamarri and V . Gavini, Phys. Rev. B90, 115127 (2014)
2014
-
[52]
J.-H. Parq, E. Sevre, and S.-M. Lee, Int. J. of Comp. Appl.98, 20 (2014)
2014
-
[53]
von Barth, and L
U. von Barth, and L. Hedin, J. Phys. C: Solid State Phys.5, 1629 (1972)
1972
-
[54]
Kübler, K.-H
J. Kübler, K.-H. Höck, J. Sticht, and A. R. Williams, J. Phys. F: Met. Phys.18, 469 (1988)
1988
-
[55]
Sticht, K.-H
J. Sticht, K.-H. Höck, and J. Kübler, J. Phys.: Condens. Matter1, 8155 (1989)
1989
-
[56]
T. Oda, A. Pasquarello, and R. Car, Phys. Rev. Lett.80, 3622 (1998)
1998
-
[57]
L. S. Blackford, J. Choi, A. Cleary, E. D’Azevedo, J. Demmel, I. Dhillon, J. Dongarra, S. Hammarling, G. Henry, A. Petitet, K. Stanley, D. Walker, and R. C. Whaley,ScaLAPACK Users’ Guide(SIAM, Philadelphia, PA, 1997)
1997
-
[58]
https://developer.nvidia.com/cublas/ (accessed 12 May 2025)
2025
-
[59]
Auckenthaler, V
T. Auckenthaler, V . Blum, H.-J. Bungartz, T. Huckle, R. Johanni, L. Krämer, B. Lang, H. Lederer, and P. R. Willems, Parallel comput.37, 783 (2011)
2011
-
[60]
Marek, V
A. Marek, V . Blum, R. Johanni, V . Havu, B. Lang, T. Auckenthaler, A. Heinecke, H.-J. Bungartz, and H. Lederer, J. Phys.-Condens. Matter26, 213201 (2014)
2014
-
[61]
https://developer.nvidia.com/cusolver/ (accessed 12 May 2025)
2025
-
[62]
B. S. Atdaev, V . F. Grin, E. A. Salkov, and V . G. Chalaya, Inorg. Mater.,23, 1835 (1987)
1987
-
[63]
https://www.openmx-square.org/viewer/ (accessed 12 May 2025)
2025
-
[64]
J. P. Perdew, K. Burke, and M. Ernzerhof, Phys. Rev. Lett.77, 3865 (1996)
1996
-
[65]
H. Wang, Z. Duan, Z. Zhao, S. Wu, S. Zheng, Q. Li, X. Jiang, and S. Zhang, Proc. ACM SIGPLAN Symp. Principles Pract. Parallel Program.PPoPP ’25, 469 (2025)
2025
-
[66]
NVIDIA Corporation,cuSOLVER Library API Reference Guide, Release 12.9 (2025)
2025
-
[67]
Yamazaki, T
I. Yamazaki, T. Dong, R. Solcà, S. Tomov, J. Dongarra, and T. Schulthess, Concurrency Computat. Pract. Exper. 25, e3152 (2013)
2013
-
[68]
Haidar, P
A. Haidar, P. Luszczek, and J. Dongarra, Proc. GPU Technol. Conf. 2012, 1 (2012)
2012
-
[69]
Y . M. Tsai, P. Luszczek, and J. Dongarra, ICL-UTK Tech. Rep.1499(2021)
2021
-
[70]
Tisseur and J
F. Tisseur and J. Dongarra, LAPACK Working Note132(UT-CS-98-382) (1998)
1998
-
[71]
Gates, K
M. Gates, K. Akbudak, M. Al Farhan, A. Charara, J. Kurzak, D. Sukkari, A. YarKhan, and J. Dongarra, ICL Technical ReportICL-UT-19-07(2019)
2019
-
[72]
Pichon, A
G. Pichon, A. Haidar, M. Faverge, and J. Kurzak, inProceedings of the 2015 IEEE International Parallel and Distributed Processing Symposium (IPDPS’15)(IEEE, Hyderabad, India, 2015), pp. 1–8. 24 GPU Acceleration of Collinear and Noncollinear DFTA Preprint
2015
-
[73]
Huang, H
Z. Huang, H. Liu, and J. Liu, J. Eng. 2019,893(2019)
2019
-
[74]
Haidar, A
A. Haidar, A. Abdelfattah, M. Zounon, S. Tomov, and J. Dongarra, IEEE Trans. Parallel Distrib. Syst.29, 973 (2018)
2018
-
[75]
Goto and R
K. Goto and R. A. van de Geijn, ACM Trans. Math. Softw.34, 12 (2008)
2008
-
[76]
https://docs.nvidia.com/cuda/cublasmp/index.html (accessed 12 May 2025)
2025
-
[77]
P. Kus, A. Marek, and H. Lederer, inNumerical Mathematics and Advanced Applications ENUMATH 2017, edited by F. A. Radu, K. Kumar, I. Berre, J. M. Nordbotten, and I. S. Pop (Springer, Cham, 2019), pp. 123-131
2017
-
[78]
V . Yu, J. Moussa, P. Kus, A. Marek, P. Messmer, M. Yoon, H. Lederer, and V . Blum, Comput. Phys. Commun. 262, 107808 (2021). 25
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.