Trajectory Geometry of Transformer Representations Across Layers
Pith reviewed 2026-06-27 16:57 UTC · model grok-4.3
The pith
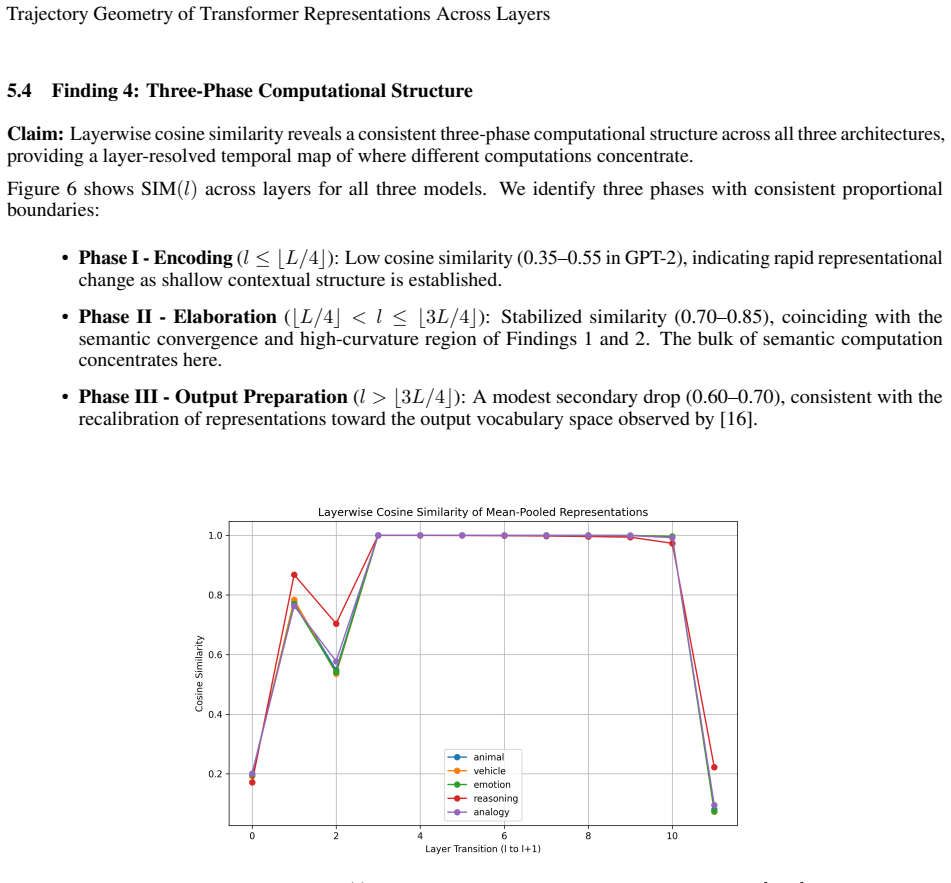
Layerwise cosine similarity reveals a universal three-phase structure in how transformer representations evolve.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
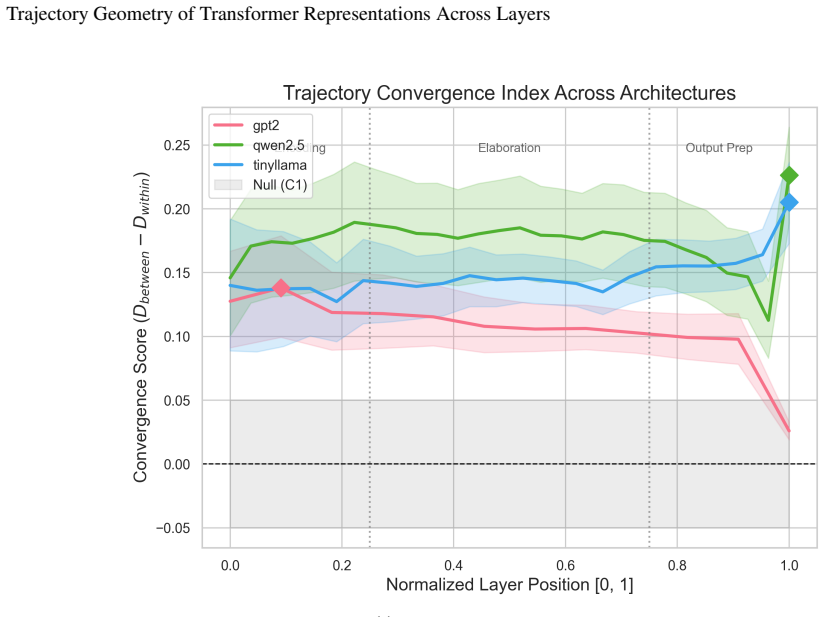
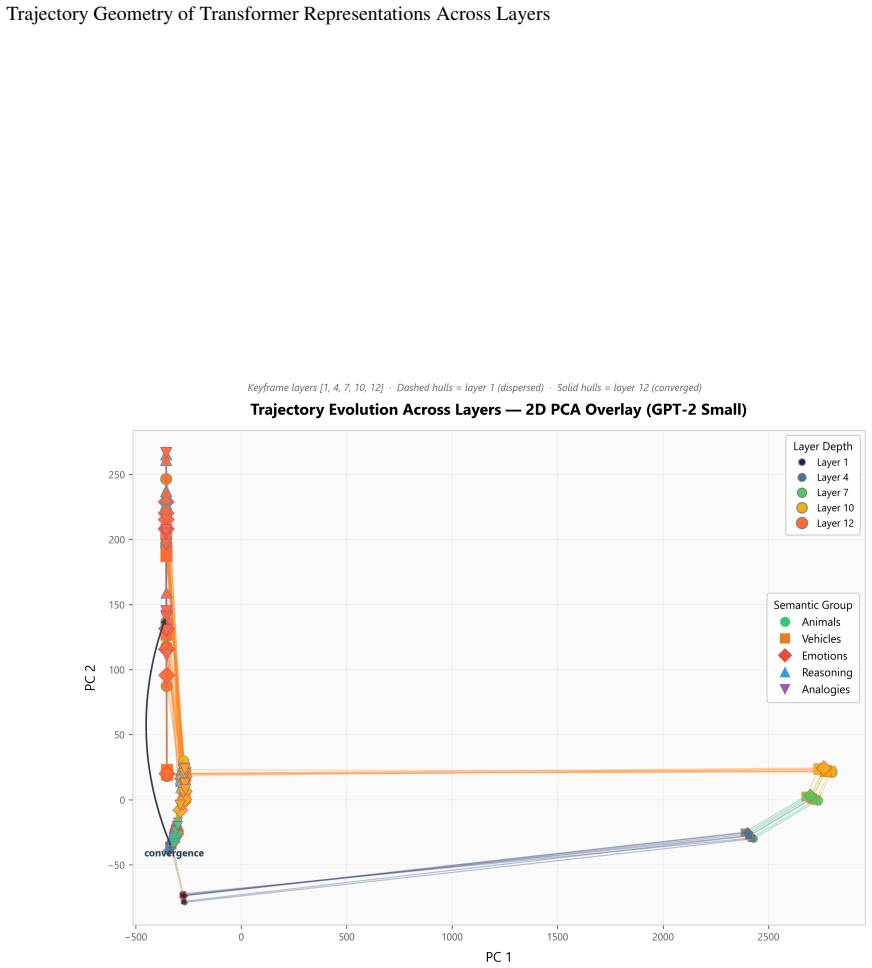
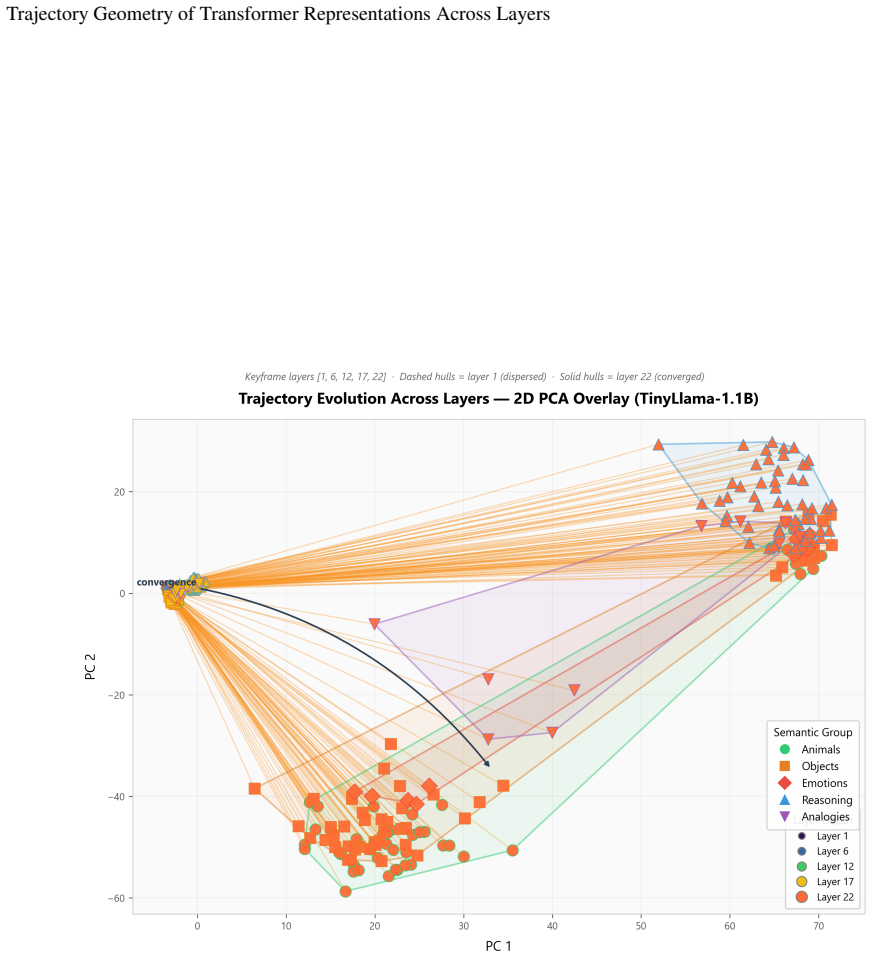
Viewing the transformer forward pass as a discrete population trajectory and measuring it with five ambient-space metrics shows that semantically related prompts converge in middle-to-late layers, reasoning tasks produce higher-curvature trajectories, ambiguous tokens cause representational bifurcation up to 5.6 times greater than controls, and layerwise cosine similarity exposes a consistent three-phase structure of encoding, elaboration, and output preparation across three model families.
What carries the argument
Layerwise cosine similarity computed on the sequence of layer activations, used to expose the three-phase trajectory structure.
If this is right
- Semantically related prompts converge significantly in middle-to-late layers.
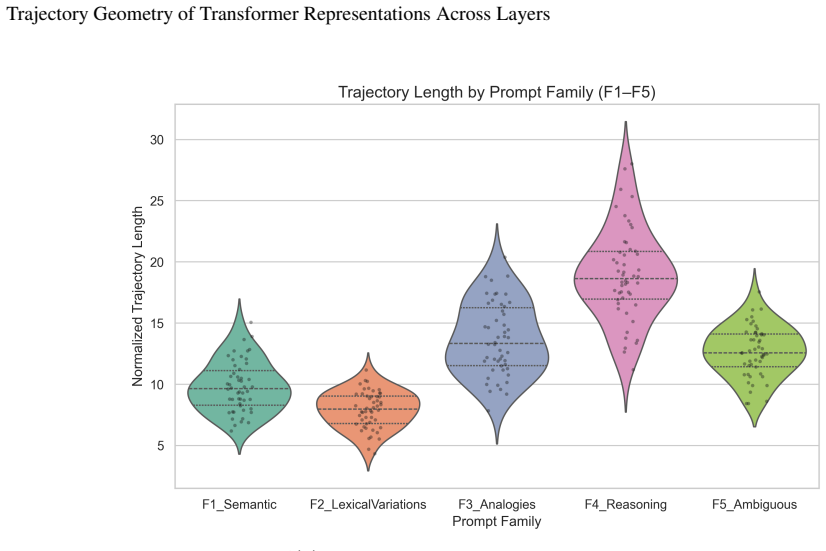
- Reasoning tasks produce trajectories of greater curvature than lexical variations.
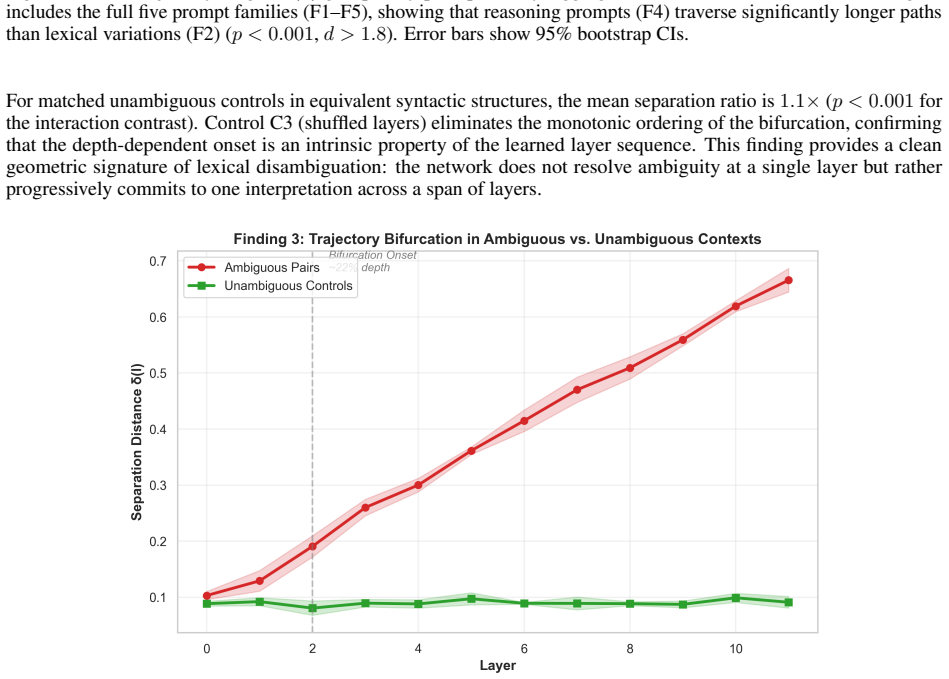
- Ambiguous tokens exhibit trajectory bifurcation with up to 5.6x representational separation by the final layer.
- The three-phase structure holds across GPT-2, TinyLlama, and Qwen2.5.
Where Pith is reading between the lines
- The same metrics could flag when a model is handling ambiguity by tracking whether bifurcation appears on new inputs.
- Curvature differences might serve as a task-agnostic indicator of computational load across prompt types.
- Re-running the pipeline on models fine-tuned for specific domains would test whether the three phases shift or remain fixed.
Load-bearing premise
The five metrics computed directly in ambient space capture the model's actual computational dynamics rather than incidental features of the embedding geometry or tokenization.
What would settle it
The three-phase pattern in layerwise cosine similarity fails to appear consistently across the three architectures, or the four reported effects remain after shuffled-layer and random-embedding controls are applied.
Figures



read the original abstract
Understanding how transformer representations evolve across layers, not merely what they encode, remains an open problem in mechanistic interpretability. We recast the transformer forward pass as a discrete population trajectory through a high-dimensional representation manifold, drawing on geometric tools from computational neuroscience. Rather than probing for pre-specified features, we characterize trajectory geometry using five metrics computed directly in the ambient space: trajectory length, curvature, a semantic convergence index, layerwise cosine similarity, and representational stability. Across three model families (GPT-2, TinyLlama, Qwen2.5) and five controlled prompt families, we report four findings. First, semantically related prompts converge significantly in middle-to-late layers (peak CI 0.41--0.58, p<0.001, Mann-Whitney U), consistent with attractor-like dynamics. Second, reasoning tasks produce trajectories of greater curvature than lexical variations (0.71--0.83 rad vs. 0.27--0.31 rad), suggesting curvature encodes computational complexity. Third, ambiguous tokens exhibit trajectory bifurcation with up to 5.6x representational separation by the final layer, absent in unambiguous controls. Fourth, layerwise cosine similarity reveals a universal three-phase structure: encoding, elaboration, and output preparation, consistent across all three architectures. All four effects vanish under shuffled-layer and random-embedding controls. We release a fully open-source, model-agnostic pipeline and argue that trajectory geometry constitutes a principled, probe-free lens for mechanistic interpretability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript recasts the transformer forward pass as a discrete trajectory through a high-dimensional representation manifold and computes five geometric metrics directly in ambient space (trajectory length, curvature, semantic convergence index, layerwise cosine similarity, representational stability). Across GPT-2, TinyLlama and Qwen2.5 on five prompt families it reports four main findings: semantically related prompts converge in middle-to-late layers (peak CI 0.41-0.58, p<0.001), reasoning tasks yield higher curvature than lexical ones (0.71-0.83 rad vs 0.27-0.31 rad), ambiguous tokens produce up to 5.6x representational separation, and layerwise cosine similarity exhibits a universal three-phase structure (encoding, elaboration, output preparation); all effects vanish under shuffled-layer and random-embedding controls. A model-agnostic open-source pipeline is released.
Significance. If the metrics can be shown to isolate computational dynamics rather than embedding geometry, the work supplies a probe-free, geometry-based lens for mechanistic interpretability together with an immediately usable open pipeline; the reported cross-architecture consistency would then constitute a concrete, falsifiable signature of layer-wise computation.
major comments (3)
- [Abstract] Abstract: the exact mathematical definitions (or equations) for curvature and the semantic convergence index are not supplied, yet the text reports precise numerical results (peak CI 0.41-0.58, p<0.001, curvature ranges 0.71-0.83 rad); without these formulas the statistical claims cannot be reproduced or verified.
- [Results (layerwise cosine similarity)] Results section on layerwise cosine similarity: the three-phase structure is obtained from direct ambient-space cosine similarity with no mention of per-layer centering, normalization, or dimensionality reduction; because the random-embedding control description leaves open whether initial embedding statistics are preserved, it remains possible that the phases are geometric artifacts rather than signatures of distinct computational stages.
- [Methods (controls)] Methods (controls subsection): the random-embedding control is stated to eliminate the reported effects, but the text does not specify whether the embedding matrix is replaced by an independent random matrix of the same shape while keeping the identical vocabulary and token-frequency distribution; if the latter properties are retained, the control does not isolate embedding geometry from layer-wise computation.
minor comments (2)
- [Abstract] Abstract: the five metrics are listed but no forward reference is given to the sections or equations that define them.
- [Results] Throughout: reported p-values and effect sizes are not accompanied by exact sample sizes, degrees of freedom, or full test statistics beyond the Mann-Whitney U label.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point by point below, with clarifications and commitments to revision where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the exact mathematical definitions (or equations) for curvature and the semantic convergence index are not supplied, yet the text reports precise numerical results (peak CI 0.41-0.58, p<0.001, curvature ranges 0.71-0.83 rad); without these formulas the statistical claims cannot be reproduced or verified.
Authors: We agree that the absence of explicit definitions in the abstract limits immediate reproducibility. In the revised manuscript we will insert concise mathematical definitions for both quantities (curvature as the angle between consecutive discrete velocity vectors; semantic convergence index as the mean pairwise cosine similarity across semantically related trajectories) directly into the abstract while respecting length limits. revision: yes
-
Referee: [Results (layerwise cosine similarity)] Results section on layerwise cosine similarity: the three-phase structure is obtained from direct ambient-space cosine similarity with no mention of per-layer centering, normalization, or dimensionality reduction; because the random-embedding control description leaves open whether initial embedding statistics are preserved, it remains possible that the phases are geometric artifacts rather than signatures of distinct computational stages.
Authors: The layerwise cosine similarity is deliberately computed in raw ambient space without centering, normalization or reduction in order to characterize the native geometry; we will add an explicit statement of this design choice and its rationale to the results section. For the random-embedding control we will expand the description to state that the embedding matrix is replaced by a random matrix of identical shape whose entries are sampled from a distribution matching the original mean and variance (while the vocabulary and prompt token frequencies are unchanged). This control is intended to demonstrate that the three-phase pattern requires the specific learned embedding geometry rather than generic high-dimensional properties. revision: yes
-
Referee: [Methods (controls)] Methods (controls subsection): the random-embedding control is stated to eliminate the reported effects, but the text does not specify whether the embedding matrix is replaced by an independent random matrix of the same shape while keeping the identical vocabulary and token-frequency distribution; if the latter properties are retained, the control does not isolate embedding geometry from layer-wise computation.
Authors: We will revise the methods section to give the precise specification requested: the learned embedding matrix is replaced by an independent random matrix of the same shape, with entries drawn from a normal distribution whose first two moments match those of the original embeddings, while the vocabulary and the token-frequency distribution induced by the prompt set are retained. We maintain that this construction isolates the contribution of the trained embedding geometry because the transformer weights and layer computations remain fixed; the fact that all reported effects disappear under this randomization indicates that the patterns arise from the interaction between the learned embeddings and the subsequent layers rather than from arbitrary embedding-space geometry alone. revision: yes
Circularity Check
No circularity: metrics are direct computations from activations; findings are empirical observations.
full rationale
The paper defines its five metrics (trajectory length, curvature, semantic convergence index, layerwise cosine similarity, representational stability) explicitly as quantities computed directly in the ambient space from layer activations in the transformer forward pass. The central claim of a universal three-phase structure is an empirical pattern observed in the layerwise cosine similarity values across models, with no equations, fitted parameters, or self-citations that reduce any result to its own inputs by construction. Controls (shuffled-layer, random-embedding) are external to the metric definitions. No load-bearing step matches any enumerated circularity pattern; the derivation chain consists of direct measurement and observation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The transformer forward pass can be recast as a discrete population trajectory through a high-dimensional representation manifold
- domain assumption The five listed metrics (trajectory length, curvature, semantic convergence index, layerwise cosine similarity, representational stability) computed directly in ambient space characterize the geometry of these trajectories
Reference graph
Works this paper leans on
-
[1]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[2]
In-context learning and induction heads
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Scott Johnston, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, a...
2022
-
[3]
A mathematical framework for transformer circuits.Transformer Circuits Thread, 2021
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah. A...
2021
-
[4]
BERT rediscovers the classical NLP pipeline
Ian Tenney, Dipanjan Das, and Ellie Pavlick. BERT rediscovers the classical NLP pipeline. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4593–4601, 2019. 12 Trajectory Geometry of Transformer Representations Across Layers
2019
-
[5]
What does BERT learn about the structure of language? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3651–3657, 2019
Ganesh Jawahar, Benoît Sagot, and Djamé Seddah. What does BERT learn about the structure of language? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3651–3657, 2019
2019
-
[6]
Computation through neural population dynamics.Annual Review of Neuroscience, 43:249–275, 2020
Saurabh Vyas, Matthew D Golub, David Sussillo, and Krishna V Shenoy. Computation through neural population dynamics.Annual Review of Neuroscience, 43:249–275, 2020
2020
-
[7]
Dimensionality reduction for large-scale neural recordings.Nature Neuroscience, 17(11):1500–1509, 2014
John P Cunningham and Byron M Yu. Dimensionality reduction for large-scale neural recordings.Nature Neuroscience, 17(11):1500–1509, 2014
2014
-
[8]
Language models are unsupervised multitask learners.OpenAI Blog, 1(8), 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners.OpenAI Blog, 1(8), 2019
2019
-
[9]
TinyLlama: An Open-Source Small Language Model
Peiyuan Zhang, Guangtao Zeng, Tianhao Wang, and Wei Lu. TinyLlama: An open-source small language model. arXiv preprint arXiv:2401.02385, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Qwen Team. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Locating and editing factual associations in GPT
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in GPT. InAdvances in Neural Information Processing Systems, volume 35, pages 17359–17372, 2022
2022
-
[12]
Transformer feed-forward layers are key-value memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. InConference on Empirical Methods in Natural Language Processing, pages 9484–9495, 2021
2021
-
[13]
Toy models of superposition.Transformer Circuits Thread, 2022
Nelson Elhage, Tom Henighan, Nicholas Joseph, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah. Toy models of superposition.Transformer C...
2022
-
[14]
Progress measures for grokking via mechanistic interpretability
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. Progress measures for grokking via mechanistic interpretability. InInternational Conference on Learning Representations, 2023
2023
-
[15]
Understanding intermediate layers using linear classifier probes
Guillaume Alain and Yoshua Bengio. Understanding intermediate layers using linear classifier probes. In International Conference on Learning Representations Workshop, 2017
2017
-
[16]
Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space
Mor Geva, Avi Caciularu, Kevin Wang, and Yoav Goldberg. Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space. InConference on Empirical Methods in Natural Language Processing, pages 30–45, 2022
2022
-
[17]
Interpreting GPT: The logit lens
nostalgebraist. Interpreting GPT: The logit lens. LessWrong, 2020
2020
-
[18]
Similarity of neural network representations revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. InInternational Conference on Machine Learning, pages 3519–3529, 2019
2019
-
[19]
The platonic representation hypothesis
Minyoung Huh, Brian Cheung, Tongzhou Wang, and Phillip Isola. The platonic representation hypothesis. In International Conference on Machine Learning, 2024
2024
-
[20]
Representational similarity analysis — connecting the branches of systems neuroscience.Frontiers in Systems Neuroscience, 2:4, 2008
Nikolaus Kriegeskorte, Marieke Mur, and Peter A Bandettini. Representational similarity analysis — connecting the branches of systems neuroscience.Frontiers in Systems Neuroscience, 2:4, 2008
2008
-
[21]
Cortical control of arm movements: A dynamical systems perspective.Annual Review of Neuroscience, 36:337–359, 2013
Krishna V Shenoy, Maneesh Sahani, and Mark M Churchland. Cortical control of arm movements: A dynamical systems perspective.Annual Review of Neuroscience, 36:337–359, 2013
2013
-
[22]
Flexible sensorimotor computations through rapid reconfiguration of cortical dynamics.Neuron, 98(5):1005–1019, 2018
Evan D Remington, Devika Narain, Eghbal A Hosseini, and Mehrdad Jazayeri. Flexible sensorimotor computations through rapid reconfiguration of cortical dynamics.Neuron, 98(5):1005–1019, 2018
2018
-
[23]
Neural networks and physical systems with emergent collective computational abilities.Proceed- ings of the National Academy of Sciences, 79(8):2554–2558, 1982
John J Hopfield. Neural networks and physical systems with emergent collective computational abilities.Proceed- ings of the National Academy of Sciences, 79(8):2554–2558, 1982
1982
-
[24]
Neural manifolds for the control of movement
Juan A Gallego, Matthew G Perich, Lee E Miller, and Sara A Solla. Neural manifolds for the control of movement. Neuron, 94(5):978–984, 2017
2017
-
[25]
Neural circuit dynamics for flexible sensorimotor mapping.Nature Neuroscience, 18(7):1025–1033, 2015
David Sussillo, Mark M Churchland, Matthew T Kaufman, and Krishna V Shenoy. Neural circuit dynamics for flexible sensorimotor mapping.Nature Neuroscience, 18(7):1025–1033, 2015
2015
-
[26]
SVCCA: Singular vector canonical correlation analysis for deep learning dynamics and interpretability
Maithra Raghu, Justin Gilmer, Jason Yosinski, and Jascha Sohl-Dickstein. SVCCA: Singular vector canonical correlation analysis for deep learning dynamics and interpretability. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[27]
Insights on representational similarity in neural networks with canonical correlation
Ari S Morcos, Maithra Raghu, and Samy Bengio. Insights on representational similarity in neural networks with canonical correlation. InAdvances in Neural Information Processing Systems, volume 31, 2018
2018
-
[28]
Prevalence of neural collapse during the terminal phase of deep learning training.Proceedings of the National Academy of Sciences, 117(40):24652–24663, 2020
Vardan Papyan, X Y Han, and David L Donoho. Prevalence of neural collapse during the terminal phase of deep learning training.Proceedings of the National Academy of Sciences, 117(40):24652–24663, 2020. 13 Trajectory Geometry of Transformer Representations Across Layers
2020
-
[29]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
Leland McInnes, John Healy, and James Melville. UMAP: Uniform manifold approximation and projection for dimension reduction.arXiv preprint arXiv:1802.03426, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[30]
RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[31]
Transformers: State-of-the-art natural language processing
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M Rush. Transformers: State-of-the-art ...
2020
-
[32]
A proposal on machine learning via dynamical systems.Communications in Mathematics and Statistics, 5(1):1–11, 2017
Weinan E. A proposal on machine learning via dynamical systems.Communications in Mathematics and Statistics, 5(1):1–11, 2017
2017
-
[33]
American Mathematical Society, Providence, RI, 2010
Herbert Edelsbrunner and John Harer.Computational Topology: An Introduction. American Mathematical Society, Providence, RI, 2010
2010
-
[34]
Linearity of relation decoding in transformer language models.International Conference on Learning Representations, 2024
Evan Hernandez, Kevin Meng, Vishaal Suresh, Usha Sharma, Martin Wattenberg, Jacob Andreas, and Yonatan Belinkov. Linearity of relation decoding in transformer language models.International Conference on Learning Representations, 2024
2024
-
[35]
Navigating the neural space in search of the neural code.Neuron, 93(5):1003– 1014, 2017
Mehrdad Jazayeri and Arash Afraz. Navigating the neural space in search of the neural code.Neuron, 93(5):1003– 1014, 2017
2017
-
[36]
Westview Press, Cambridge, MA, 1994
Steven H Strogatz.Nonlinear Dynamics and Chaos: With Applications to Physics, Biology, Chemistry, and Engineering. Westview Press, Cambridge, MA, 1994. Appendix The appendix contains: (A) extended per-model statistical results, (B) the complete prompt dataset, (C) trajec- tory animation frames, and (D) full reproducibility details. All raw outputs, CSVs, ...
1994
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.