A Unifying Framework for Concept-Based Representational Similarity
Pith reviewed 2026-06-27 17:09 UTC · model grok-4.3
The pith
Concept alignment decomposes into four distinct properties along two axes and requires joint optimization of all of them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
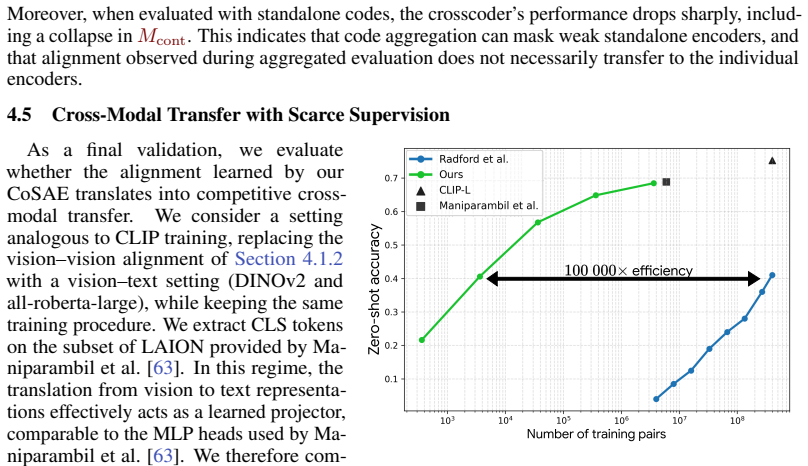
Alignment along the representation-to-concept axis and the instance-to-distribution axis produces four independent guarantees—instance-wise translation, distributional translation, instance-wise concept consistency, and distributional concept consistency. Existing methods each guarantee only a subset of these, and optimizing any one subset does not recover the remaining guarantees. Only a model that couples the objectives across both axes recovers all four simultaneously; purely unsupervised objectives leave instance-level matches unrecoverable, while anchoring the distributional objectives allows 0.1 percent paired data to restore instance-level alignment.
What carries the argument
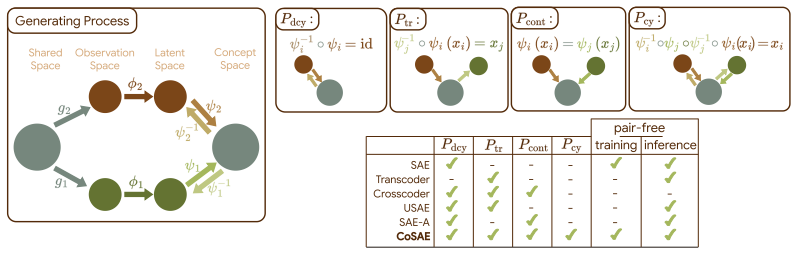
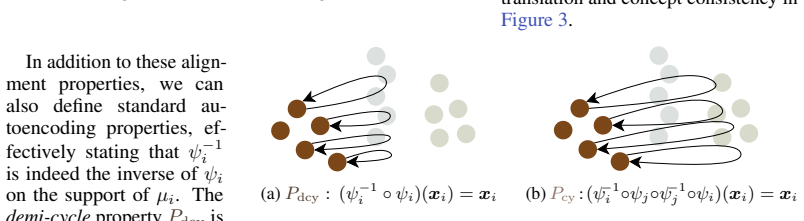
The two-axis decomposition (representations vs. concepts; instance-wise vs. distributional) that induces four alignment properties—instance-wise and distributional translation together with instance-wise and distributional concept consistency.
If this is right
- Optimizing one alignment property does not reliably recover the others.
- Purely unsupervised objectives fail to recover meaningful instance-level alignment.
- Joint enforcement of the four complementary properties is required for strong alignment across both axes.
- As little as 0.1 percent paired data recovers instance-level alignment when distributional objectives are anchored.
Where Pith is reading between the lines
- The decomposition could be tested on cross-modal settings such as vision-language models to check whether the same four properties remain independent.
- The benchmark might be extended to measure whether the four properties predict downstream task performance when representations are transferred.
- Additional axes, such as temporal or hierarchical structure, could be added if the current four properties leave certain misalignment cases unexplained.
- The finding that minimal paired data suffices under distributional anchoring suggests similar low-supervision regimes may work for other multi-objective alignment problems in representation learning.
Load-bearing premise
The two axes and the four properties they induce capture all relevant dimensions of alignment without missing important failure modes or alternative decompositions.
What would settle it
An experiment in which a single-objective method achieves high scores on all four properties simultaneously, or in which the benchmark reveals a systematic failure mode outside the four properties.
Figures


read the original abstract
Learned representations across models and modalities often exhibit striking structural similarities, suggesting shared underlying concept decompositions. However, concept alignment remains poorly defined: existing approaches optimize different objectives under the same terminology, obscuring what is actually aligned. We propose a unifying framework that decomposes alignment along two axes: what is aligned (representations vs. concepts) and at what level (instance-wise vs. distributional). This induces four corresponding properties -- instance-wise and distributional variants of translation and concept consistency -- and reveals precisely which of these guarantees existing methods provide. We further introduce \InterVenchA, an intervention-based benchmark that separately measures extraction quality, translation quality, and concept consistency. Through theory and experiments, we show that commonly assumed equivalences between alignment objectives fail in practice: optimizing one property does not reliably recover the others, and purely unsupervised objectives fail to recover meaningful instance-level alignment. We then propose the Coupled Sparse Autoencoder (CoSAE), which jointly enforces complementary alignment objectives. Strong alignment emerges only in this regime. Surprisingly, as little as 0.1\% paired data is sufficient to recover instance-level alignment when anchoring distributional objectives. Overall, our results show that concept alignment is fundamentally multi-objective: it must be defined, measured, and optimized as such.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that concept alignment between learned representations is poorly defined because existing methods optimize different objectives under the same name. It introduces a two-axis decomposition (representations vs. concepts; instance-wise vs. distributional) that induces four properties (instance-wise and distributional variants of translation and concept consistency). The framework is used to analyze which guarantees existing methods provide. The authors introduce the InterVenchA intervention-based benchmark and the CoSAE model, which jointly optimizes the complementary objectives. Experiments show that unsupervised objectives fail to recover instance-level alignment, that the four properties are not interchangeable, and that 0.1% paired data suffices when distributional objectives are anchored.
Significance. If the decomposition and empirical results hold, the work supplies a clear taxonomy for existing alignment techniques, demonstrates that single-objective optimization is insufficient, and offers both a diagnostic benchmark and a practical method that achieves strong alignment with minimal paired supervision. These contributions would help standardize evaluation and optimization in representational similarity and mechanistic interpretability.
major comments (3)
- [§3] §3 (two-axis decomposition): the manuscript presents the axes as inducing exactly four independent properties whose joint satisfaction is necessary, but provides no argument or test that the axes are exhaustive; dimensions such as hierarchical concept structure or causal intervention alignment are not ruled out, which directly affects whether the four properties must be optimized jointly.
- [§5] §5 (CoSAE and 0.1% paired-data result): the claim that anchoring distributional objectives allows instance-level alignment with 0.1% paired data is load-bearing for the multi-objective conclusion, yet the paper does not report ablation on the choice of distributional measure or on whether the result generalizes beyond the tested concept sets.
- [Table 2] Table 2 / InterVenchA results: the reported failures of unsupervised objectives are central to the claim that the properties are non-redundant, but the table does not include variance across random seeds or alternative unsupervised baselines, making it difficult to assess whether the failures are general or setup-specific.
minor comments (2)
- Notation for the four properties is introduced without an explicit summary table mapping each property to its axis combination; adding such a table would improve readability.
- The abstract states that 'commonly assumed equivalences between alignment objectives fail in practice' but does not cite the specific prior works that make those assumptions.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [§3] §3 (two-axis decomposition): the manuscript presents the axes as inducing exactly four independent properties whose joint satisfaction is necessary, but provides no argument or test that the axes are exhaustive; dimensions such as hierarchical concept structure or causal intervention alignment are not ruled out, which directly affects whether the four properties must be optimized jointly.
Authors: The two axes are chosen because they capture the primary ambiguities observed across existing alignment methods in the literature. We do not claim the decomposition is exhaustive; rather, it provides a minimal set of independent properties that existing techniques can be shown to satisfy or violate. Hierarchical structure and causal alignment can be viewed as special cases or extensions within the concept-consistency axis. In revision we will add an explicit scope paragraph acknowledging these additional dimensions and noting that the current framework focuses on the core instance/distributional distinction. revision: partial
-
Referee: [§5] §5 (CoSAE and 0.1% paired-data result): the claim that anchoring distributional objectives allows instance-level alignment with 0.1% paired data is load-bearing for the multi-objective conclusion, yet the paper does not report ablation on the choice of distributional measure or on whether the result generalizes beyond the tested concept sets.
Authors: The distributional measure used is the standard one employed in prior distributional-alignment literature. We agree that an ablation would strengthen the result. In the revised version we will add experiments that vary the distributional objective (MMD, Wasserstein distance, and correlation-based measures) and repeat the 0.1% paired-data protocol on two additional concept sets drawn from different domains. revision: yes
-
Referee: [Table 2] Table 2 / InterVenchA results: the reported failures of unsupervised objectives are central to the claim that the properties are non-redundant, but the table does not include variance across random seeds or alternative unsupervised baselines, making it difficult to assess whether the failures are general or setup-specific.
Authors: We will augment Table 2 with standard deviations computed across five random seeds. The unsupervised baselines already span the main families of methods; we will add one further linear-alignment baseline if space permits. The failures of unsupervised objectives were reproducible in our internal replication checks. revision: yes
Circularity Check
No circularity: framework decomposition and empirical disproof of equivalences are independent of self-referential inputs
full rationale
The paper proposes a two-axis decomposition (representations vs. concepts; instance-wise vs. distributional) that induces four properties, then uses theory plus a new intervention benchmark (InterVenchA) to show that optimizing one property does not recover the others and that unsupervised objectives fail at instance-level alignment. It further introduces CoSAE to jointly enforce objectives. None of these steps reduce by construction to fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations; the multi-objective conclusion follows directly from the proposed analysis and external experimental results rather than from re-deriving the inputs.
Axiom & Free-Parameter Ledger
invented entities (2)
-
InterVenchA
no independent evidence
-
CoSAE
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Similarity of neural network representations revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. InInternational conference on machine learning, pages 3519–3529. PMlR, 2019
2019
-
[2]
Revisiting model stitching to compare neural representations.Advances in neural information processing systems, 34:225–236, 2021
Yamini Bansal, Preetum Nakkiran, and Boaz Barak. Revisiting model stitching to compare neural representations.Advances in neural information processing systems, 34:225–236, 2021
2021
-
[3]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[4]
Lit: Zero-shot transfer with locked-image text tuning
Xiaohua Zhai, Xiao Wang, Basil Mustafa, Andreas Steiner, Daniel Keysers, Alexander Kolesnikov, and Lucas Beyer. Lit: Zero-shot transfer with locked-image text tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022
2022
-
[5]
Sigmoid loss for language image pre-training.Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 11975–11986, 2023
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training.Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 11975–11986, 2023
2023
-
[6]
Relations between two sets of variates.Biometrika, 28(3/4):321–377, 1936
Harold Hotelling. Relations between two sets of variates.Biometrika, 28(3/4):321–377, 1936. ISSN 00063444. URLhttp://www.jstor.org/stable/2333955
arXiv 1936
-
[7]
A kernel statistical test of independence.Advances in neural information processing systems, 20, 2007
Arthur Gretton, Kenji Fukumizu, Choon Teo, Le Song, Bernhard Sch¨olkopf, and Alex Smola. A kernel statistical test of independence.Advances in neural information processing systems, 20, 2007
2007
-
[8]
Svcca: Singular vector canonical correlation analysis for deep learning dynamics and interpretability.Advances in neural information processing systems, 30, 2017
Maithra Raghu, Justin Gilmer, Jason Yosinski, and Jascha Sohl-Dickstein. Svcca: Singular vector canonical correlation analysis for deep learning dynamics and interpretability.Advances in neural information processing systems, 30, 2017
2017
-
[9]
Grounding representation similarity through statistical testing.Advances in Neural Information Processing Systems, 34:1556–1568, 2021
Frances Ding, Jean-Stanislas Denain, and Jacob Steinhardt. Grounding representation similarity through statistical testing.Advances in Neural Information Processing Systems, 34:1556–1568, 2021
2021
-
[10]
Sparse autoencoders find highly interpretable features in language models.ArXiv e-print, 2023
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models.ArXiv e-print, 2023
2023
-
[11]
Towards monosemanticity: Decomposing language models with dictionary learning.Transformer Circuits Thread, 2023
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Con- erly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Zac Hatfield-Dodds, Alex Tamkin, Karina Nguyen, Brayden McLean, Josiah E Burke, Tristan Hume, Shan Carter, Tom Henighan, and ...
2023
-
[12]
A holistic approach to unifying automatic concept extraction and concept importance estimation.Advances in Neural Information Processing Systems (NeurIPS), 36: 54805–54818, 2023
Thomas Fel, Victor Boutin, Mazda Moayeri, Remi Cadene, Louis Bethune, Mathieu Chalvidal, and Thomas Serre. A holistic approach to unifying automatic concept extraction and concept importance estimation.Advances in Neural Information Processing Systems (NeurIPS), 36: 54805–54818, 2023
2023
-
[13]
Sparse crosscoders for cross-layer features and model diffing.Transformer Circuits Thread, 2024
Jack Lindsey, Adly Templeton, Jonathan Marcus, Thomas Conerly, Joshua Batson, and Christo- pher Olah. Sparse crosscoders for cross-layer features and model diffing.Transformer Circuits Thread, 2024
2024
-
[14]
Universal sparse autoencoders: Interpretable cross-model concept alignment.ArXiv e-print, 2025
Harrish Thasarathan, Julian Forsyth, Thomas Fel, Matthew Kowal, and Konstantinos Derpanis. Universal sparse autoencoders: Interpretable cross-model concept alignment.ArXiv e-print, 2025
2025
-
[15]
Cross-modal redundancy and the geometry of vision–language embeddings
Gr´egoire Dhimo¨ıla, Thomas Fel, Victor Boutin, and Agustin Martin Picard. Cross-modal redundancy and the geometry of vision–language embeddings. InThe Fourteenth International Conference on Learning Representations, 2026. 10
2026
-
[16]
Similarity of neural networks: A survey of functional and representational measures.Journal of Machine Learning Research, 25(87):1–77, 2024
Max Klabunde, Tobias Schumacher, Alexander H ¨agele, Markus Bernstein, Patrick van der Smagt, and Marcus M ¨artens. Similarity of neural networks: A survey of functional and representational measures.Journal of Machine Learning Research, 25(87):1–77, 2024
2024
-
[17]
Transcoders find interpretable llm feature circuits.Advances in Neural Information Processing Systems, 37:24375–24410, 2024
Jacob Dunefsky, Philippe Chlenski, and Neel Nanda. Transcoders find interpretable llm feature circuits.Advances in Neural Information Processing Systems, 37:24375–24410, 2024
2024
-
[18]
Adam Karvonen, Can Rager, Johnny Lin, Curt Tigges, Joseph Bloom, David Chanin, Yeu-Tong Lau, Eoin Farrell, Callum McDougall, Kola Ayonrinde, et al. Saebench: A comprehen- sive benchmark for sparse autoencoders in language model interpretability.arXiv preprint arXiv:2503.09532, 2025
arXiv 2025
-
[19]
Representational similarity analysis-connecting the branches of systems neuroscience.Frontiers in systems neuroscience, 2:249, 2008
Nikolaus Kriegeskorte, Marieke Mur, and Peter A Bandettini. Representational similarity analysis-connecting the branches of systems neuroscience.Frontiers in systems neuroscience, 2:249, 2008
2008
-
[20]
The platonic representation hypothesis.arXiv preprint arXiv:2405.07987, 2024
Minyoung Huh, Brian Cheung, Tongzhou Wang, and Phillip Isola. The platonic representation hypothesis.arXiv preprint arXiv:2405.07987, 2024
Pith/arXiv arXiv 2024
-
[21]
A Koepke, Daniil Zverev, Shiry Ginosar, and Alexei A Efros. Back into plato’s cave: Examining cross-modal representational convergence at scale.arXiv preprint arXiv:2604.18572, 2026
Pith/arXiv arXiv 2026
-
[22]
Revisiting the platonic representation hypothesis: An aristotelian view, 2026
Fabian Gr¨oger, Shuo Wen, and Maria Brbi´c. Revisiting the platonic representation hypothesis: An aristotelian view, 2026. URLhttps://arxiv.org/abs/2602.14486
Pith/arXiv arXiv 2026
-
[23]
David Bau, Bolei Zhou, Aditya Khosla, Aude Oliva, and Antonio Torralba. Network dissection: Quantifying interpretability of deep visual representations.Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 6541–6549, 2017
2017
-
[24]
Feature visualization.Distill, 2017
Chris Olah, Alexander Mordvintsev, and Ludwig Schubert. Feature visualization.Distill, 2017
2017
-
[25]
Gilpin, David Bau, Ben Z Yuan, Ayesha Bajwa, Michael Specter, and Lalana Kagal
Leilani H. Gilpin, David Bau, Ben Z Yuan, Ayesha Bajwa, Michael Specter, and Lalana Kagal. Explaining explanations: An overview of interpretability of machine learning.Proceedings of the IEEE International Conference on data science and advanced analytics (DSAA), pages 80–89, 2018
2018
-
[26]
Unlocking feature visualization for deeper networks with magnitude constrained optimization.Advances in Neural Information Processing Systems (NeurIPS), 2023
Thomas Fel, Thibaut Boissin, Victor Boutin, Agustin Picard, Paul Novello, Julien Colin, Drew Linsley, Tom Rousseau, R´emi Cad`ene, Laurent Gardes, and Thomas Serre. Unlocking feature visualization for deeper networks with magnitude constrained optimization.Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[27]
Visualizing and understanding convolutional networks
Matthew D Zeiler and Rob Fergus. Visualizing and understanding convolutional networks. Proceedings of the IEEE European Conference on Computer Vision (ECCV), pages 818–833, 2014
2014
-
[28]
Rise: Randomized input sampling for explanation of black-box models.Proceedings of the British Machine Vision Conference (BMVC), page 151, 2018
Vitali Petsiuk, Abir Das, and Kate Saenko. Rise: Randomized input sampling for explanation of black-box models.Proceedings of the British Machine Vision Conference (BMVC), page 151, 2018
2018
-
[29]
Axiomatic attribution for deep networks
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks. Proceedings of the International Conference on Machine Learning (ICML), pages 3319–3328, 2017
2017
-
[30]
Towards automatic concept- based explanations.Advances in Neural Information Processing Systems (NeurIPS), 32, 2019
Amirata Ghorbani, James Wexler, James Y Zou, and Been Kim. Towards automatic concept- based explanations.Advances in Neural Information Processing Systems (NeurIPS), 32, 2019
2019
-
[31]
Ruihan Zhang, Prashan Madumal, Tim Miller, Krista A Ehinger, and Benjamin IP Rubinstein. Invertible concept-based explanations for cnn models with non-negative concept activation vectors.Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 35(13):11682– 11690, 2021
2021
-
[32]
Toy models of superposition.Transformer Circuits Thread, 2022
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, Roger Grosse, Sam McCandlish, Jared Kaplan, Dario Amodei, Martin Wattenberg, and Christopher Olah. Toy models of superposition.Transformer Circuits Thread, 2022. 11
2022
-
[33]
Emergence of simple-cell receptive field properties by learning a sparse code for natural images.Nature, 381(6583):607–609, 1996
Bruno A Olshausen and David J Field. Emergence of simple-cell receptive field properties by learning a sparse code for natural images.Nature, 381(6583):607–609, 1996
1996
-
[34]
Sparse coding with an overcomplete basis set: A strategy employed by v1?Vision research, 37(23):3311–3325, 1997
Bruno A Olshausen and David J Field. Sparse coding with an overcomplete basis set: A strategy employed by v1?Vision research, 37(23):3311–3325, 1997
1997
-
[35]
Sparse coding of sensory inputs.Current Opin- ion in Neurobiology, 14(4):481–487, 2004
Bruno A Olshausen and David J Field. Sparse coding of sensory inputs.Current Opin- ion in Neurobiology, 14(4):481–487, 2004. ISSN 0959-4388. doi: https://doi.org/10. 1016/j.conb.2004.07.007. URL https://www.sciencedirect.com/science/article/pii/ S0959438804001035
2004
-
[36]
Efficient sparse coding algorithms
Honglak Lee, Alexis Battle, Rajat Raina, and Andrew Ng. Efficient sparse coding algorithms. Advances in Neural Information Processing Systems (NeurIPS), 19, 2006
2006
-
[37]
Beyond l1 sparse coding in v1.PLoS Computational Biology, 19(9):e1011459, 2023
Ilias Rentzeperis, Luca Calatroni, Laurent U Perrinet, and Dario Prandi. Beyond l1 sparse coding in v1.PLoS Computational Biology, 19(9):e1011459, 2023
2023
-
[38]
Extensions of lipschitz mappings into a hilbert space.Contemporary mathematics, 26(189-206):1, 1984
William B Johnson, Joram Lindenstrauss, et al. Extensions of lipschitz mappings into a hilbert space.Contemporary mathematics, 26(189-206):1, 1984
1984
-
[39]
Optimality of the johnson-lindenstrauss lemma
Kasper Green Larsen and Jelani Nelson. Optimality of the johnson-lindenstrauss lemma. In 2017 IEEE 58th annual symposium on foundations of computer science (FOCS), pages 633–638. IEEE, 2017
2017
-
[40]
Dictionaries for sparse representation modeling.Proceedings of the IEEE, 98(6):1045–1057, 2010
Ron Rubinstein, Alfred M Bruckstein, and Michael Elad. Dictionaries for sparse representation modeling.Proceedings of the IEEE, 98(6):1045–1057, 2010
2010
-
[41]
Springer International Publishing, 2010
Michael Elad.Sparse and redundant representations: from theory to applications in signal and image processing. Springer International Publishing, 2010
2010
-
[42]
Dictionary learning.IEEE Signal Processing Magazine, 28(2): 27–38, 2011
Ivana Toˇsi´c and Pascal Frossard. Dictionary learning.IEEE Signal Processing Magazine, 28(2): 27–38, 2011
2011
-
[43]
Springer, 2018
Bogdan Dumitrescu and Paul Irofti.Dictionary learning algorithms and applications. Springer, 2018
2018
-
[44]
Scaling and evaluating sparse autoencoders.Proceedings of the International Conference on Learning Representations (ICLR), 2025
Leo Gao, Tom Dupre la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. Scaling and evaluating sparse autoencoders.Proceedings of the International Conference on Learning Representations (ICLR), 2025
2025
-
[45]
Jumping ahead: Improving reconstruction fidelity with jumprelu sparse autoencoders.ArXiv e-print, 2024
Senthooran Rajamanoharan, Tom Lieberum, Nicolas Sonnerat, Arthur Conmy, Vikrant Varma, Janos Kramar, and Neel Nanda. Jumping ahead: Improving reconstruction fidelity with jumprelu sparse autoencoders.ArXiv e-print, 2024
2024
-
[46]
Batchtopk sparse autoencoders.ArXiv e-print, 2024
Bart Bussmann, Patrick Leask, and Neel Nanda. Batchtopk sparse autoencoders.ArXiv e-print, 2024
2024
-
[47]
Archetypal sae: Adaptive and stable dictionary learning for concept extraction in large vision models
Thomas Fel, Ekdeep Singh Lubana, Jacob S Prince, Matthew Kowal, Victor Boutin, Isabel Papadimitriou, Binxu Wang, Martin Wattenberg, Demba Ba, and Talia Konkle. Archetypal sae: Adaptive and stable dictionary learning for concept extraction in large vision models. Proceedings of the International Conference on Machine Learning (ICML), 2025
2025
-
[48]
Val´erie Costa, Thomas Fel, Ekdeep Singh Lubana, Bahareh Tolooshams, and Demba Ba. From flat to hierarchical: Extracting sparse representations with matching pursuit.arXiv preprint arXiv:2506.03093, 2025
arXiv 2025
-
[49]
The missing curve detectors of inceptionv1: Applying sparse autoencoders to inceptionv1 early vision.ArXiv e-print, 2024
Liv Gorton. The missing curve detectors of inceptionv1: Applying sparse autoencoders to inceptionv1 early vision.ArXiv e-print, 2024
2024
-
[50]
Into the rabbit hull: From task- relevant concepts in dino to minkowski geometry.Proceedings of the International Conference on Learning Representations (ICLR), 2026
Thomas Fel, Binxu Wang, Michael A Lepori, Matthew Kowal, Andrew Lee, Randall Balestriero, Sonia Joseph, Ekdeep S Lubana, Talia Konkle, Demba Ba, et al. Into the rabbit hull: From task- relevant concepts in dino to minkowski geometry.Proceedings of the International Conference on Learning Representations (ICLR), 2026. 12
2026
-
[51]
Unpacking sdxl turbo: Interpreting text-to-image models with sparse au- toencoders
Viacheslav Surkov, Chris Wendler, Mikhail Terekhov, Justin Deschenaux, Robert West, and Caglar Gulcehre. Unpacking sdxl turbo: Interpreting text-to-image models with sparse au- toencoders. InMechanistic Interpretability for Vision at CVPR 2025 (Non-proceedings Track), 2025
2025
-
[52]
Semi-supervised multimodal representation learning through a global workspace.IEEE Transactions on Neural Networks and Learning Systems, 36(5):7843–7857, 2024
Benjamin Devillers, L ´eopold Mayti ´e, and Rufin VanRullen. Semi-supervised multimodal representation learning through a global workspace.IEEE Transactions on Neural Networks and Learning Systems, 36(5):7843–7857, 2024
2024
-
[53]
Unpaired image-to-image translation using cycle-consistent adversarial networks
Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to-image translation using cycle-consistent adversarial networks. InProceedings of the IEEE international conference on computer vision, pages 2223–2232, 2017
2017
-
[54]
Unsupervised neural machine translation.arXiv preprint arXiv:1710.11041, 2017
Mikel Artetxe, Gorka Labaka, Eneko Agirre, and Kyunghyun Cho. Unsupervised neural machine translation.arXiv preprint arXiv:1710.11041, 2017
Pith/arXiv arXiv 2017
-
[55]
On the rate of convergence in wasserstein distance of the empirical measure.Probability theory and related fields, 162(3):707–738, 2015
Nicolas Fournier and Arnaud Guillin. On the rate of convergence in wasserstein distance of the empirical measure.Probability theory and related fields, 162(3):707–738, 2015
2015
-
[56]
Computational optimal transport.Foundations and Trends in Machine Learning, 2018
Gabriel Peyr´e and Marco Cuturi. Computational optimal transport.Foundations and Trends in Machine Learning, 2018
2018
-
[57]
Randall Balestriero and Yann LeCun. Lejepa: Provable and scalable self-supervised learning without the heuristics.arXiv preprint arXiv:2511.08544, 2025
Pith/arXiv arXiv 2025
-
[58]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghan, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2021
2021
-
[59]
Dinov2: Learning robust visual features without supervision.ArXiv e-print, 2023
Maxime Oquab, Timoth´ee Darcet, Th´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.ArXiv e-print, 2023
2023
-
[60]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, R´emi Louf, Morgan Funtowicz, et al. Huggingface’s transform- ers: State-of-the-art natural language processing.arXiv preprint arXiv:1910.03771, 2019
Pith/arXiv arXiv 1910
-
[61]
Reproducible scaling laws for contrastive language-image learning.Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2818–2829, 2023
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scaling laws for contrastive language-image learning.Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2818–2829, 2023
2023
-
[62]
Microsoft coco: Common objects in context.Proceedings of the IEEE European Conference on Computer Vision (ECCV), pages 740–755, 2014
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context.Proceedings of the IEEE European Conference on Computer Vision (ECCV), pages 740–755, 2014
2014
-
[63]
Harnessing frozen unimodal encoders for flexible multi- modal alignment
Mayug Maniparambil, Raiymbek Akshulakov, Yasser Abdelaziz Dahou Djilali, Sanath Narayan, Ankit Singh, and Noel E O’Connor. Harnessing frozen unimodal encoders for flexible multi- modal alignment. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 29847–29857, 2025
2025
-
[64]
Overcoming sparsity artifacts in crosscoders to interpret chat-tuning
Julian Minder, Cl´ement Dumas, Caden Juang, Bilal Chughtai, and Neel Nanda. Overcoming sparsity artifacts in crosscoders to interpret chat-tuning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum? id=yFdNygEryH
2025
-
[65]
Deep learning face attributes in the wild
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. InProceedings of the IEEE international conference on computer vision, pages 3730–3738, 2015
2015
-
[66]
Hashimoto, and Percy Liang
Shiori Sagawa*, Pang Wei Koh*, Tatsunori B. Hashimoto, and Percy Liang. Distributionally robust neural networks. InInternational Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=ryxGuJrFvS. 13
2020
-
[67]
Invariant risk mini- mization.ArXiv e-print, 2019
Martin Arjovsky, L´eon Bottou, Ishaan Gulrajani, and David Lopez-Paz. Invariant risk mini- mization.ArXiv e-print, 2019
2019
-
[68]
A kernel two-sample test.The journal of machine learning research, 13(1):723–773, 2012
Arthur Gretton, Karsten M Borgwardt, Malte J Rasch, Bernhard Sch ¨olkopf, and Alexander Smola. A kernel two-sample test.The journal of machine learning research, 13(1):723–773, 2012
2012
-
[69]
Learning transferable features with deep adaptation networks
Mingsheng Long, Yue Cao, Jianmin Wang, and Michael Jordan. Learning transferable features with deep adaptation networks. InInternational conference on machine learning, pages 97–105. PMLR, 2015
2015
-
[70]
Generative moment matching networks
Yujia Li, Kevin Swersky, and Rich Zemel. Generative moment matching networks. InInterna- tional conference on machine learning, pages 1718–1727. PMLR, 2015
2015
-
[71]
Demystifying mmd gans.arXiv preprint arXiv:1801.01401, 2018
Mikołaj Bi´nkowski, Danica J Sutherland, Michael Arbel, and Arthur Gretton. Demystifying mmd gans.arXiv preprint arXiv:1801.01401, 2018
Pith/arXiv arXiv 2018
-
[72]
Enhancing neural network interpretability with feature-aligned sparse autoencoders, 2024
Luke Marks, Alasdair Paren, David Krueger, and Fazl Barez. Enhancing neural network interpretability with feature-aligned sparse autoencoders, 2024. URL https://arxiv.org/ abs/2411.01220
arXiv 2024
-
[73]
Projecting assumptions: The duality between sparse autoencoders and concept geometry.ArXiv e-print, 2025
Sai Sumedh R Hindupur, Ekdeep Singh Lubana, Thomas Fel, and Demba Ba. Projecting assumptions: The duality between sparse autoencoders and concept geometry.ArXiv e-print, 2025
2025
-
[74]
Imagenet: A large-scale hierarchical image database.Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 248–255, 2009
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database.Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 248–255, 2009
2009
-
[75]
Laion-400m: Open dataset of clip-filtered 400 million image-text pairs.ArXiv e-print, 2021
Christoph Schuhmann, Richard Vencu, Romain Beaumont, Robert Kaczmarczyk, Clayton Mullis, Aarush Katta, Theo Coombes, Jenia Jitsev, and Aran Komatsuzaki. Laion-400m: Open dataset of clip-filtered 400 million image-text pairs.ArXiv e-print, 2021. 14 A Extended Related Work A.1 Unifying existing methods Figure 1 summarizes the different methods for concept e...
arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.