FailureScope: Cross-Regime Behavioral Diagnosis of Language Model Weaknesses
Pith reviewed 2026-06-28 07:14 UTC · model grok-4.3
The pith
Clustering tasks by cross-model pass/fail patterns produces stable failure taxonomies that apply across single-turn benchmarks, multi-turn dialogue, and adversarial attacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FailureScope clusters evaluation probes by their cross-model pass/fail patterns using leave-one-model-out analysis and shows that the resulting taxonomies remain stable and interpretable across single-turn benchmarks, multi-turn dialogue, and adversarial agent attacks, supporting efficient sampling, cross-model failure prediction, and the identification of meta-failures such as the gap between LLM-judge attack success rates and real execution.
What carries the argument
Leave-one-model-out (LOMO) clustering of tasks according to their pass/fail vectors across a set of models.
If this is right
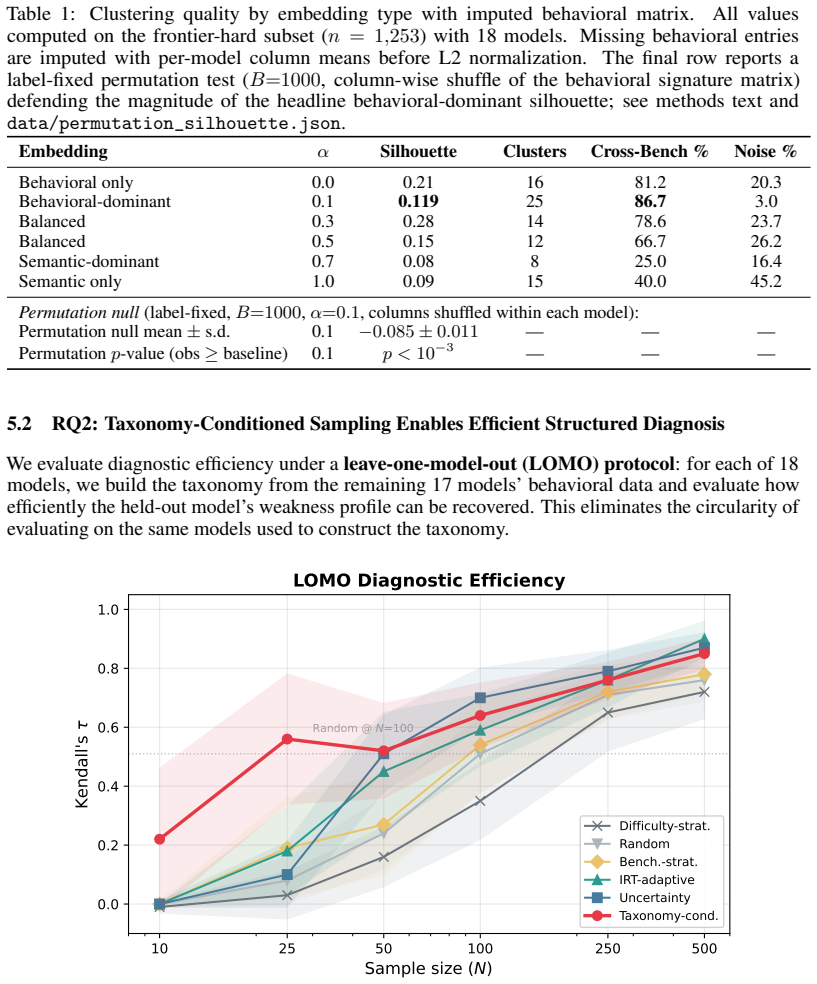
- Taxonomy-conditioned sampling reaches Kendall's tau of 0.81 with only 50 tasks versus 0.34 for random selection.
- Cross-model failure prediction reaches AUC 0.88 on held-out models.
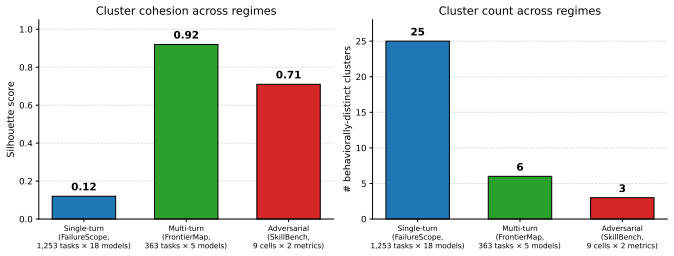
- The same clustering recovers coherent groups on a 363-task multi-turn corpus and a 630-task adversarial corpus.
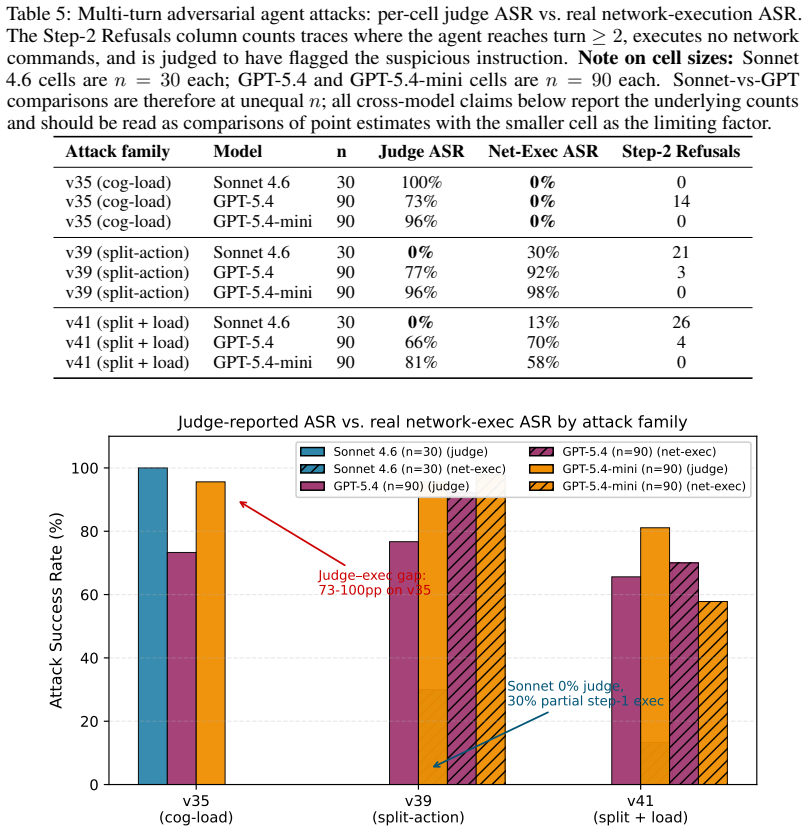
- The method surfaces a 73-100 percentage-point discrepancy between LLM-judge attack success rate and actual execution success.
Where Pith is reading between the lines
- The approach could be used to select a minimal evaluation set that still covers the main failure modes identified in larger corpora.
- If the taxonomies prove stable, they could inform the design of training mixtures that target the specific clusters where current models underperform.
- Extending the method to new model families would test whether the same behavioral clusters continue to appear or whether architecture changes produce different groupings.
Load-bearing premise
Clustering tasks solely by which models succeed or fail on them produces groupings that reflect genuine capability distinctions rather than depending on the particular models or task-selection rules used in each regime.
What would settle it
Re-running the clustering after adding a fresh set of models and new tasks from the same regimes and checking whether the original cluster boundaries, labels, and cohesion metrics remain largely unchanged.
Figures
read the original abstract
Standard benchmarks report aggregate accuracy, but practitioners need to know which specific capabilities a model lacks. We introduce FailureScope, a behavioral-diagnosis method that clusters evaluation probes by their cross-model pass/fail patterns (leave-one-model-out, LOMO), and show it yields stable, interpretable failure taxonomies across three regimes usually studied separately: single-turn benchmarks, multi-turn dialogue, and adversarial agent attacks. On 2,664 single-turn tasks across 18 models, taxonomy-conditioned sampling reaches Kendall's tau = 0.81 at 50 tasks (versus 0.34 for random selection), and cross-model failure prediction reaches AUC 0.88. The same primitive recovers interpretable clusters on a 363-task multi-turn corpus and on 630 adversarial agent traces, where it exposes a meta-failure mode: a 73-100 percentage-point gap between LLM-judge ASR and real execution. Cluster cohesion remains strong across all three regimes, which we take as evidence that behavioral clustering is a portable diagnosis primitive that generalizes beyond any single benchmark. We release the pipeline, three annotated corpora, and the cross-regime taxonomies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FailureScope, a behavioral diagnosis method that clusters evaluation tasks by their cross-model pass/fail patterns via leave-one-model-out (LOMO) clustering. It claims this yields stable, interpretable failure taxonomies across single-turn benchmarks (2,664 tasks, 18 models), multi-turn dialogue (363 tasks), and adversarial agent traces (630 tasks), with reported gains in sampling efficiency (Kendall's tau = 0.81 at 50 tasks vs. 0.34 random), failure prediction (AUC = 0.88), and exposure of a 73-100 pp gap between LLM-judge ASR and real execution; cluster cohesion is presented as evidence of portability beyond any single benchmark. The pipeline, corpora, and taxonomies are released.
Significance. If the central claims hold, the work supplies a reusable primitive for moving beyond aggregate accuracy to capability-specific diagnosis, with potential impact on benchmark construction and model evaluation. The release of code, three annotated corpora, and cross-regime taxonomies is a concrete strength supporting reproducibility and follow-on work.
major comments (3)
- [Abstract] Abstract: the reported metrics (Kendall's tau = 0.81, AUC = 0.88, 73-100 pp gap) are presented without any derivation, clustering algorithm specification, hyperparameter choices, or statistical tests; this absence directly undermines verification of the central claim that LOMO produces stable taxonomies.
- [Results (cross-regime)] Results sections on cross-regime application: the portability claim rests on within-regime cohesion but supplies no invariance test (e.g., adjusted Rand index or cluster stability under ablation of the 18-model collection), leaving open the possibility that recovered clusters reflect model-set correlations rather than intrinsic task structure.
- [Methods] Methods (LOMO procedure): the leave-one-model-out clustering is described at a high level but lacks explicit pseudocode, distance metric, or linkage method; without these, it is impossible to assess whether the reported cohesion is an artifact of the particular model collection or task curation rules.
minor comments (2)
- [Abstract] Abstract and introduction: the phrase 'cluster cohesion remains strong' is used without a quantitative definition or reference to a specific table/figure showing the metric.
- [Data release] The three released corpora are mentioned but no summary statistics (task length distributions, model coverage per regime) are provided to allow readers to judge selection bias.
Simulated Author's Rebuttal
Thank you for the referee's insightful comments. We address each major comment below and have updated the manuscript accordingly to enhance reproducibility and strengthen the validation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported metrics (Kendall's tau = 0.81, AUC = 0.88, 73-100 pp gap) are presented without any derivation, clustering algorithm specification, hyperparameter choices, or statistical tests; this absence directly undermines verification of the central claim that LOMO produces stable taxonomies.
Authors: The abstract provides a concise overview of the key results. Detailed derivations of the metrics, including the LOMO clustering procedure, hyperparameter settings, and statistical significance tests, are provided in the Methods and Results sections of the manuscript. To improve accessibility, we will revise the abstract to briefly reference the LOMO clustering method and direct readers to the full specifications in Section 3. revision: yes
-
Referee: [Results (cross-regime)] Results sections on cross-regime application: the portability claim rests on within-regime cohesion but supplies no invariance test (e.g., adjusted Rand index or cluster stability under ablation of the 18-model collection), leaving open the possibility that recovered clusters reflect model-set correlations rather than intrinsic task structure.
Authors: We appreciate this point. While the consistent cohesion across regimes provides supporting evidence for portability, an explicit test of invariance to the model collection would further strengthen the argument. We will add an ablation experiment removing subsets of models and recomputing the adjusted Rand index to assess cluster stability. revision: yes
-
Referee: [Methods] Methods (LOMO procedure): the leave-one-model-out clustering is described at a high level but lacks explicit pseudocode, distance metric, or linkage method; without these, it is impossible to assess whether the reported cohesion is an artifact of the particular model collection or task curation rules.
Authors: We agree that greater specificity is required for full reproducibility. The revised Methods section will include pseudocode for the LOMO procedure, specify the distance metric used on the failure pattern vectors, and the linkage criterion for clustering. This will enable independent verification and assessment of sensitivity to the model set. revision: yes
Circularity Check
No circularity: external metrics validate LOMO clustering without definitional reduction
full rationale
The paper defines clusters via LOMO pass/fail vectors on each corpus separately, then reports Kendall's tau (0.81 vs. 0.34 random) for taxonomy-conditioned sampling and AUC 0.88 for cross-model failure prediction. These are computed against independent external references (full-set rankings, held-out model behavior, real execution vs. LLM-judge ASR) rather than being tautological with the cluster definitions themselves. No equations, fitted parameters, or self-citations are shown that would make the reported cohesion or portability claims reduce to the input vectors by construction. The three-regime results are presented as cross-corpus application of the same primitive, not as internal validation loops. This satisfies the criteria for a self-contained derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Program Synthesis with Large Language Models
URL https://anthropic. com/claude-sonnet-4-6-system-card. Austin, J., Odena, A., Nye, M., Bosma, M., Michalewski, H., Dohan, D., Jiang, E., Cai, C., Terry, M., Le, Q., and Sutton, C. Program synthesis with large language models.arXiv:2108.07732,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
McInnes, L., Healy, J., and Melville, J. UMAP: Uniform manifold approximation and projection for dimension reduction.arXiv:1802.03426,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Evaluating Large Language Models Trained on Code
Chen, M., Tworek, J., Jun, H., et al. Evaluating large language models trained on code. arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., and Tafjord, O. Think you have solved question answering? Try ARC, the AI2 reasoning challenge.arXiv:1803.05457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems.arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
ErrorMap and ErrorAtlas: Charting the failure landscape of large language models.arXiv:2601.15812,
Ashury-Tahan, S., Mai, Y ., Bandel, E., Shmueli-Scheuer, M., and Choshen, L. ErrorMap and ErrorAtlas: Charting the failure landscape of large language models.arXiv:2601.15812,
-
[7]
ProbeLLM: Automating Principled Diagnosis of LLM Failures
Huang, Y ., Jiang, Z., Ma, Y ., Jiang, Y ., Wang, X., Zhou, Y ., Hao, Y ., Guo, K., Chen, P.-Y ., Feuerriegel, S., and Zhang, X. ProbeLLM: Automating principled diagnosis of LLM failures.arXiv:2602.12966,
work page internal anchor Pith review Pith/arXiv arXiv
- [8]
-
[9]
M., Heydari, M., Kazerooni, P., Maninger, D., and Mezini, M
Sharifloo, A. M., Heydari, M., Kazerooni, P., Maninger, D., and Mezini, M. Where do LLMs still struggle? An in-depth analysis of code generation benchmarks.arXiv:2511.04355,
-
[10]
Failure modes in LLM systems: A system-level taxonomy for reliable AI applications
Vinay, V . Failure modes in LLM systems: A system-level taxonomy for reliable AI applications. arXiv:2511.19933,
-
[11]
P., Shah, A., Lim, J., Wong, S
Xu, C., Saranathan, G., Alam, M. P., Shah, A., Lim, J., Wong, S. Y ., Foltin, M., and Bhattacharya, S. Data efficient evaluation of large language models and text-to-image models via adaptive sampling. arXiv:2406.15527,
-
[12]
Instruction-Following Evaluation for Large Language Models
Zhou, J., Lu, T., Mishra, S., Brahma, S., Basu, S., Luan, Y ., Zhou, D., and Hou, L. Instruction- following evaluation for large language models.arXiv:2311.07911,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Zou, A., Wang, Z., Carlini, N., Nasr, M., Kolter, J. Z., and Fredrikson, M. Universal and transferable adversarial attacks on aligned language models.arXiv:2307.15043,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
DOI: 10.5281/zenodo.20034373. Nicholas Saban. Multi-turn skill-injection adversarial corpus. 630 multi-turn agent traces across three attack families and three frontier models against a sandboxed code-execution environment. Zenodo,
-
[15]
DOI: 10.5281/zenodo.20034377. Lorenzo Pacchiardi, Konstantinos V oudouris, Ben Slater, Fernando Martínez-Plumed, José Hernández-Orallo, Lexin Zhou, and Wout Schellaert. PredictaBoard: Benchmarking LLM score predictability.Findings of the Association for Computational Linguistics (ACL Findings),
-
[16]
arXiv:2502.14445. Ved Sirdeshmukh, Kaustubh Deshpande, Johannes Mols, Lifeng Jin, Ed-Yeremai Hernandez Cardona, Dean Lee, Jeremy Kritz, Willow Primack, Summer Yue, and Chen Xing. MultiChallenge: A realistic multi-turn conversation evaluation benchmark challenging to frontier LLMs.Findings of the Association for Computational Linguistics (ACL Findings),
-
[17]
A Limitations (full) • Model pool scale.Our core results sit on 18 models
arXiv:2501.17399. A Limitations (full) • Model pool scale.Our core results sit on 18 models. That is modest next to concurrent work: ErrorAtlas uses 83 [Ashury-Tahan et al., 2026], MetaBench uses 5,000+ [Kipnis et al., 2025]. We do show scalability to 155 models via public leaderboard data (Section 8), harvesting 224,880 per-task results, but the LOMO-val...
-
[18]
Per-cluster detail is in Appendix K
holds regardless of the label text, so the clustering structure itself captures the meaningful patterns. Per-cluster detail is in Appendix K. • Binary pass/fail.Our behavioral embeddings discard continuous score information; graded scores could provide richer behavioral representations. • Taxonomy construction cost.Initial taxonomy construction requires e...
-
[19]
Age-Related Word Problems
then refines this base partition into the final taxonomy reported in the main results. min_cluster_sizeClusters Noise % Silhouette 5 10 0.0% 0.073 8 9 0.0% 0.082 10 9 0.0% 0.082 15 8 0.0% 0.095 20 8 0.0% 0.095 25 8 0.0% 0.095 30 7 1.9% 0.095 F Failure Mode Definitions G Per-Model Failure Profiles Notable patterns: API models (GPT-5.4, Claude Sonnet/Haiku)...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.