Towards the implementation of a quantum classifier
Pith reviewed 2026-06-27 16:01 UTC · model grok-4.3
The pith
A quantum circuit can be trained as a binary classifier for images and particle data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
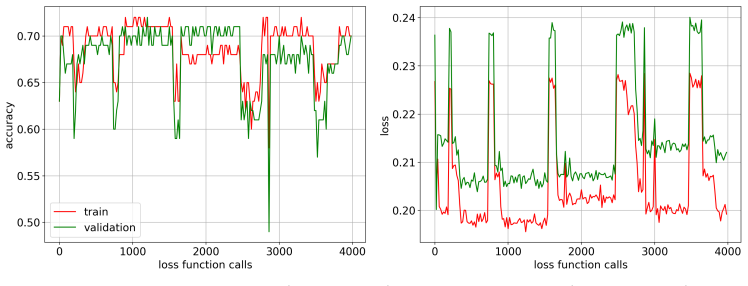
It is possible to build a binary quantum classifier with a quantum circuit. The construction proceeds by describing how to input data, defining a quantum circuit model Ansatz with trainable parameters and a loss function, and implementing multiple minimizers. The classifier is tested on the MNIST data set of handwritten zeros and ones and on data sets representing two different high-energy collisions, with and without pile-up, represented either as 32x32 images or six high-level features. By varying the number of layers and the size of the training set, the behavior of different minimizers is examined and the usual test metrics are computed; for the pile-up images the quantum results are pla
What carries the argument
The binary quantum classifier formed by data encoding, a trainable quantum circuit Ansatz, a loss function, and classical minimizers that adjust the parameters.
If this is right
- Varying the number of layers in the Ansatz changes how different minimizers perform on the MNIST task.
- Larger training sets and more layers help identify which minimizer works best for the collision data.
- On the pile-up images the quantum classifier yields results that can be compared directly with those of a small convolutional neural network.
- Standard metrics (ROC curve, AUC score, confusion matrix, test accuracy) quantify the classifier's behavior on both image and feature inputs.
Where Pith is reading between the lines
- The same encoding-plus-Ansatz pattern could be tried on other binary image or feature tasks where classical networks are already known to work.
- Observed limits in accuracy or training stability may indicate where deeper circuits or hybrid optimization would be needed next.
- Side-by-side tests against classical models on identical data sets make it possible to locate the data regimes in which quantum circuits might later show an advantage.
Load-bearing premise
The assumption that the chosen quantum circuit Ansatz with trainable parameters, when optimized by the selected minimizers on the given training sets, produces a model whose test-set metrics meaningfully reflect generalization rather than overfitting or optimizer-specific artifacts.
What would settle it
If repeated training runs on both the MNIST and collision data sets produce test accuracies that remain at chance level near 50 percent no matter how many layers or training samples are used, the claim that a functional binary quantum classifier has been built would be falsified.
Figures
















read the original abstract
In this work, we investigate the use of a quantum circuit as a binary classification model in the context of quantum machine learning. We call this model, binary quantum classifier. First, we describe fundamental concepts of quantum computing and introduce the computational tool used: Qibo, an open-source framework for efficient quantum simulations and quantum hardware control. Then, we describe how to design a binary quantum classifier for the classification of images and small arrays of variables by showing how to input data in the circuit, defining a quantum circuit model Ansatz with trainable parameters and a loss function, and implementing multiple minimizers. We test our quantum classifier with two data sets. The first one is the MNIST data set which is composed of handwritten digits (reduced to only handwritten zeros and handwritten ones for binary classification). We study the behavior of different minimizers by increasing the number of layers of the Ansatz. The second data set represents two different high energy collisions that can occur at colliders such as LHC (CERN). Due to in-time proton-proton interactions known as pile-up, we distinguish two different data sets: "without pile-up" and "with pile-up". These collisions can be represented by images of size 32x32 or by six high-level variables that we call features. By increasing the size of the training data set and the number of layers of the Ansatz, we search for the best minimizer. Splitting the data set in training set and test set, we compute: ROC curve, AUC score, confusion matrices and test set accuracy. For "with pile-up" images, we compare the results obtained with the quantum classifier with a small convolutional neural network. We conclude that is possible to build a binary quantum classifier with a quantum circuit and we highlight its performances and limitations in comparison with classical technologies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes the implementation of a binary quantum classifier using variational quantum circuits in the Qibo framework. It covers data encoding into qubits, a parameterized Ansatz circuit, loss function, and classical minimizers. Experiments are performed on MNIST (binary 0/1 classification) by varying Ansatz layers and on high-energy physics pile-up data (32x32 images and 6 features), reporting ROC curves, AUC scores, confusion matrices, and test accuracy after train/test splits. A comparison to a small CNN is included for pile-up images. The conclusion states that a binary quantum classifier can be built and its performances/limitations versus classical methods can be highlighted.
Significance. If the reported test metrics are shown to reflect genuine generalization rather than optimization artifacts, the work provides a concrete open-source demonstration of variational quantum classification on both benchmark and domain-specific datasets, including direct comparison to a classical CNN. The use of Qibo for both simulation and potential hardware control is a practical strength.
major comments (3)
- [Experimental results (MNIST and pile-up sections)] The experimental sections on MNIST and pile-up data report ROC/AUC/accuracy after varying Ansatz layer count and training-set size, but provide no error bars, no mention of multiple random seeds or runs, and no details on train/test split ratios or preprocessing steps. This makes it impossible to assess whether the metrics demonstrate robust performance or are sensitive to specific choices.
- [Results on varying Ansatz layers and training-set size] When increasing the number of Ansatz layers (a free parameter listed in the work), the paper does not report whether test-set metrics degrade or plateau, nor any regularization, early stopping, or explicit overfitting checks. This directly affects the ability to claim that the metrics highlight genuine limitations versus classical methods rather than training-set idiosyncrasies.
- [CNN comparison paragraph] The CNN comparison for 'with pile-up' images is presented without details on the CNN architecture depth, training procedure, or hyperparameter search, preventing a fair assessment of the quantum classifier's relative performance.
minor comments (2)
- [Methods description] Notation for the Ansatz circuit and encoding is introduced but could be clarified with an explicit circuit diagram or pseudocode for reproducibility.
- [Abstract and conclusion] The abstract and conclusion use 'we highlight its performances and limitations' but the text does not explicitly discuss what the observed limitations are beyond the raw metrics.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help improve the clarity and robustness of our work. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Experimental results (MNIST and pile-up sections)] The experimental sections on MNIST and pile-up data report ROC/AUC/accuracy after varying Ansatz layer count and training-set size, but provide no error bars, no mention of multiple random seeds or runs, and no details on train/test split ratios or preprocessing steps. This makes it impossible to assess whether the metrics demonstrate robust performance or are sensitive to specific choices.
Authors: We agree that error bars from multiple runs and explicit details on splits and preprocessing would strengthen the presentation. The original experiments used single runs owing to the high computational cost of variational quantum circuit simulations on the available hardware. We will add the train/test split ratios (80/20 for MNIST and 70/30 for the pile-up datasets) and preprocessing steps (pixel normalization to [0,1] and flattening for feature-based inputs) to the revised manuscript. We will also add a limitations paragraph noting the lack of multiple random seeds. revision: partial
-
Referee: [Results on varying Ansatz layers and training-set size] When increasing the number of Ansatz layers (a free parameter listed in the work), the paper does not report whether test-set metrics degrade or plateau, nor any regularization, early stopping, or explicit overfitting checks. This directly affects the ability to claim that the metrics highlight genuine limitations versus classical methods rather than training-set idiosyncrasies.
Authors: We will revise the relevant sections to include test-set AUC and accuracy as functions of Ansatz depth, allowing readers to observe any plateauing or degradation. No regularization or early stopping was applied in the reported runs; we will state this explicitly and discuss its implications for interpreting the comparison with classical methods. revision: yes
-
Referee: [CNN comparison paragraph] The CNN comparison for 'with pile-up' images is presented without details on the CNN architecture depth, training procedure, or hyperparameter search, preventing a fair assessment of the quantum classifier's relative performance.
Authors: We will expand the CNN comparison paragraph to specify the architecture (two convolutional layers with 3x3 filters followed by max-pooling and a dense layer), training details (Adam optimizer, 20 epochs, batch size 32), and note that hyperparameters were selected via limited manual tuning rather than grid search. revision: yes
Circularity Check
No circularity: empirical implementation with standard train/test evaluation
full rationale
The paper presents an empirical study of a variational quantum circuit for binary classification on MNIST and particle-physics data. It encodes data, defines an Ansatz with trainable parameters, selects a loss, runs classical minimizers, and reports ROC/AUC/accuracy on held-out test sets after varying layers and training size. No derivation chain exists that reduces a claimed result to its own fitted inputs by construction; test metrics are computed on data splits independent of the optimization objective. Self-citations (e.g., to Qibo) are incidental and not load-bearing for the performance claims. The work therefore contains no self-definitional, fitted-input-called-prediction, or self-citation-load-bearing steps.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of Ansatz layers
- trainable parameters in Ansatz
axioms (1)
- domain assumption Quantum circuits can be simulated classically via Qibo for the circuit depths used.
Reference graph
Works this paper leans on
-
[1]
Andrew Arrasmith et al.Effect of barren plateaus on gradient-free op- timization. 2020. arXiv:2011.12245 [quant-ph]
arXiv 2020
-
[2]
Jet substructure classification in high-energy physics with deep neural networks
Pierre Baldi et al. “Jet substructure classification in high-energy physics with deep neural networks”. In:Physical Review D93.9 (May 2016). issn: 2470-0029.doi:10 . 1103 / physrevd . 93 . 094034.url:http : //dx.doi.org/10.1103/PhysRevD.93.094034
-
[3]
Jet substructure as a new Higgs search channel at the LHC
Jonathan M Butterworth et al. “Jet substructure as a new Higgs search channel at the LHC”. eng. In:Physical review letters100 (2008).issn: 0031-9007
2008
-
[4]
Higher order derivatives of quantum neural networks with barren plateaus
M Cerezo and Patrick J Coles. “Higher order derivatives of quantum neural networks with barren plateaus”. eng. In:Quantum Science and Technology6.3 (2021).issn: 2058-9565
2021
-
[5]
Predicting the stock price of frontier mar- kets using machine learning and modified Black–Scholes Option pricing model
Reaz Chowdhury et al. “Predicting the stock price of frontier mar- kets using machine learning and modified Black–Scholes Option pricing model”. eng. In:Physica A555 (2020).issn: 0378-4371
2020
-
[6]
Combarro.A Practical Introduction to Quantum Computing: From Qubits to Quantum Machine Learning and Beyond.url:https: //indico.cern.ch/event/970903/
El` ıas F. Combarro.A Practical Introduction to Quantum Computing: From Qubits to Quantum Machine Learning and Beyond.url:https: //indico.cern.ch/event/970903/
-
[7]
Qibo: a framework for quantum simulation with hardware acceleration
Stavros Efthymiou et al. “Qibo: a framework for quantum simulation with hardware acceleration”. In: (2020). arXiv:2009.01845 [quant-ph]
arXiv 2020
-
[8]
The role of machine and deep learning in modern medical physics
Issam El Naqa and Shiva Das. “The role of machine and deep learning in modern medical physics”. In:Medical Physics47.5 (2020), e125– e126.doi:https : / / doi . org / 10 . 1002 / mp . 14088. eprint:https : //aapm.onlinelibrary.wiley.com/doi/pdf/10.1002/mp.14088. url:https://aapm.onlinelibrary.wiley.com/doi/abs/10.1002/ mp.14088. [9]Google Research, Google ...
-
[9]
A fast quantum mechanical algorithm for database search
Lov Grover. “A fast quantum mechanical algorithm for database search”. eng. In:Proceedings of the twenty-eighth annual ACM symposium on theory of computing. ACM, 1996, pp. 212–219.isbn: 0897917855
1996
-
[10]
Supervised learning with quantum-enhanced feature spaces
Vojtˇ ech Havl´ ıˇ cek et al. “Supervised learning with quantum-enhanced feature spaces”. In:Nature567.7747 (Mar. 2019), pp. 209–212.issn: 1476-4687.doi:10.1038/s41586-019-0980-2.url:http://dx.doi. org/10.1038/s41586-019-0980-2. [12]IBM Research, IBM Quantum Experience.url:https://www.ibm. com/quantum-computing/. [13]Intel Corporation, Intel Quantum Compu...
work page doi:10.1038/s41586-019-0980-2.url:http://dx.doi 2019
-
[11]
Quantum chemistry as a benchmark for near-term quantum computers
Alexander J McCaskey et al. “Quantum chemistry as a benchmark for near-term quantum computers”. eng. In:npj quantum information5.1 (2019), pp. 1–8.issn: 2056-6387
2019
-
[12]
Increased emotional engagement in game-based learning – A machine learning approach on facial emotion detection data
Manuel Ninaus et al. “Increased emotional engagement in game-based learning – A machine learning approach on facial emotion detection data”. eng. In:Computers and education142 (2019), pp. 103641–.issn: 0360-1315
2019
-
[13]
John Preskill. “Quantum Computing in the NISQ era and beyond”. In: Quantum2 (Aug. 2018), p. 79.issn: 2521-327X.doi:10.22331/q- 2018-08-06-79.url:http://dx.doi.org/10.22331/q-2018-08- 06-79. [17]Qibo.url:https://qibo.readthedocs.io. [18]Rigetti, Rigetti Computing.url:https://www.rigetti.com. [19]ScikitMNIST data-set.url:https://scikit- learn.org/stable/ mo...
work page doi:10.22331/q- 2018
-
[14]
Algorithms for quantum computation: discrete logarithms and factoring
P.W Shor. “Algorithms for quantum computation: discrete logarithms and factoring”. eng. In:Proceedings 35th Annual Symposium on Foun- dations of Computer Science. IEEE Comput. Soc. Press, 1994, pp. 124– 134.isbn: 0818665807. [22]The MNIST database.url:http://yann.lecun.com/exdb/mnist/. 56
1994
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.