Robustness Verification of Recurrent Neural Networks with Abstraction Refinement
Pith reviewed 2026-06-27 10:14 UTC · model grok-4.3
The pith
Abstraction refinement at selected RNN timesteps removes dominant relaxation errors to certify more robust inputs than pure bound propagation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
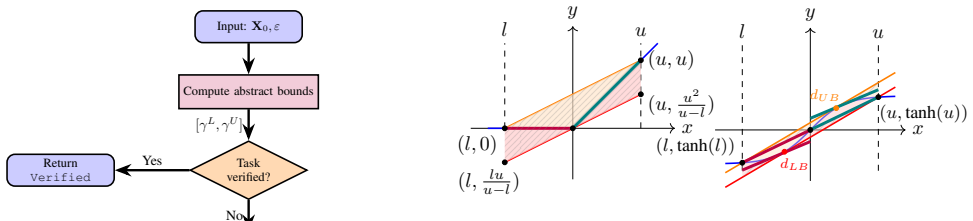
The central claim is that an abstraction-refinement loop for RNNs, which partitions pre-activation intervals crossing zero and applies tighter linear envelopes on each branch, combined with a SHAP-guided ordering that refines only the timesteps whose hidden states contribute most to the verification objective, produces both higher verification success rates and larger certified robustness margins on CIFAR-10 and MNIST stroke benchmarks than abstraction alone.
What carries the argument
The SHAP-guided timestep selection that ranks hidden states by their contribution to the verification objective and refines only the highest-ranked ones in temporal order.
If this is right
- More inputs previously marked unverified become certified as robust without changing the underlying network.
- The certified robustness margin reported for each input increases because the refined branches produce strictly tighter linear bounds.
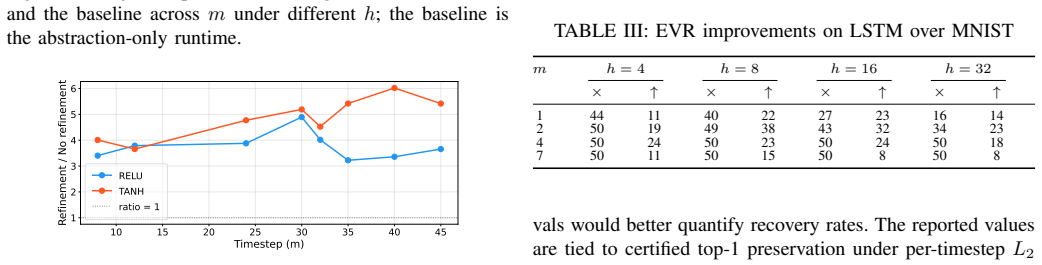
- ReLU networks and tanh networks exhibit different runtime-versus-tightness trade-offs under the same refinement budget.
- The method remains sound: every certified input is still guaranteed robust even after the added splits.
Where Pith is reading between the lines
- The same selective-refinement pattern could be applied to other sequential models whose bound propagation also accumulates error over many steps.
- If the ranking step can be made faster or parallelized, the approach would scale to longer sequences that current full-refinement methods cannot handle.
- The reported margin improvements suggest that downstream tasks relying on certified robustness, such as safe trajectory planning, would receive stronger guarantees from the refined verifier.
Load-bearing premise
The feature-attribution ranking correctly identifies the timesteps whose refinement removes the largest share of accumulated error without overlooking other timesteps whose refinement would be needed to close the proof.
What would settle it
Run the same verification queries with the SHAP ranking replaced by random or uniform timestep selection; if the success rate and margin tightness show no consistent gain over the abstraction-only baseline, the selective-refinement claim does not hold.
Figures




read the original abstract
Certified local robustness verification for recurrent neural networks (RNNs) is challenging because approximation errors introduced by nonlinear relaxations can propagate through recurrent connections and accumulate over time. As a result, scalable linear bound propagation methods often become overly conservative and fail to certify inputs that are in fact robust, especially when many pre-activation intervals cross zero. We propose an abstraction-refinement framework for RNN verification that partitions such intervals to remove the dominant relaxation error: on each refined branch, ReLU becomes exact, and smooth activations such as tanh and sigmoid admit substantially tighter linear envelopes. To control the combinatorial cost of splitting in long sequences, we introduce a SHAP-guided timestep selection strategy that ranks hidden states by their contribution to the verification objective and refines only the most critical timesteps in temporal order. Experiments on CIFAR10 and MNIST stroke benchmarks demonstrate consistent improvements in verification success and robustness-margin tightness over abstraction-only baselines, while exposing clear runtime trade-offs between ReLU and tanh models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that an abstraction-refinement framework for RNN robustness verification can mitigate accumulated relaxation errors from nonlinear activations by partitioning intervals (making ReLU exact and tightening envelopes for tanh/sigmoid) and that a SHAP-guided strategy for selecting which timesteps to refine controls the combinatorial explosion in long sequences. Experiments on CIFAR10 and MNIST stroke benchmarks are said to show consistent gains in verification success rate and robustness-margin tightness versus abstraction-only baselines, with noted runtime trade-offs between ReLU and tanh models.
Significance. If the central claims hold, the work would provide a practical, scalable technique for certified verification of recurrent networks by trading off refinement cost against bound tightness in a targeted way. The use of external benchmarks (CIFAR10/MNIST stroke) and explicit runtime trade-off reporting are strengths that allow direct comparison to prior abstraction methods.
major comments (2)
- [SHAP-guided timestep selection strategy] The SHAP-guided timestep selection strategy (described in the method section) rests on the unverified assumption that local linear attributions around a background distribution correctly rank hidden states by total propagated error through recurrent connections; no analysis, sensitivity check, or counter-example is provided showing that small per-step errors amplified by the weight matrix are not under-ranked. This is load-bearing for the claim of consistent improvements, as an incomplete ranking would make the reported gains on the stroke benchmarks potentially dataset-specific rather than general.
- [Experiments on CIFAR10 and MNIST stroke benchmarks] The experimental claims of 'consistent improvements in verification success and robustness-margin tightness' lack the quantitative tables, error bars, or per-model breakdowns needed to assess effect size and statistical significance; the abstract states positive outcomes but the manuscript must supply the actual success rates, margin values, and runtime numbers for the ReLU vs. tanh comparison to support the central empirical claim.
minor comments (2)
- Notation for the linear envelopes and the verification objective should be introduced with explicit equations early in the method section to make the refinement step reproducible.
- The abstract would benefit from one or two concrete numbers (e.g., success-rate delta or average margin improvement) to give readers an immediate sense of the gains.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and describe the corresponding revisions.
read point-by-point responses
-
Referee: The SHAP-guided timestep selection strategy (described in the method section) rests on the unverified assumption that local linear attributions around a background distribution correctly rank hidden states by total propagated error through recurrent connections; no analysis, sensitivity check, or counter-example is provided showing that small per-step errors amplified by the weight matrix are not under-ranked. This is load-bearing for the claim of consistent improvements, as an incomplete ranking would make the reported gains on the stroke benchmarks potentially dataset-specific rather than general.
Authors: We acknowledge that the manuscript does not contain a formal sensitivity analysis or counter-examples validating the SHAP ranking under recurrent amplification. The SHAP values are nevertheless computed directly against the verification objective, which incorporates the propagated effects of the weight matrices. The observed improvements on the reported benchmarks provide empirical support for the heuristic. In revision we will add a limitations discussion of the local-linear approximation together with a small-scale comparison against gradient-based and random timestep selection on a subset of instances. revision: partial
-
Referee: The experimental claims of 'consistent improvements in verification success and robustness-margin tightness' lack the quantitative tables, error bars, or per-model breakdowns needed to assess effect size and statistical significance; the abstract states positive outcomes but the manuscript must supply the actual success rates, margin values, and runtime numbers for the ReLU vs. tanh comparison to support the central empirical claim.
Authors: We agree that the current version lacks the requested quantitative detail. The revised manuscript will include comprehensive tables reporting verification success rates, mean robustness margins with standard deviations, and runtime figures for both ReLU and tanh models on the CIFAR10 and MNIST stroke benchmarks, allowing direct assessment of effect sizes and statistical significance. revision: yes
Circularity Check
No circularity: method is an independent algorithmic contribution validated on external benchmarks
full rationale
The paper presents an abstraction-refinement framework for RNN robustness verification, using SHAP-guided timestep selection to prioritize refinements. No equations, parameters, or claims in the provided text reduce the reported improvements to quantities defined by fitted inputs, self-definitions, or self-citation chains. The central claims rely on the algorithmic procedure and empirical results on CIFAR10/MNIST stroke benchmarks, which are external to the method itself. This is a self-contained algorithmic proposal without load-bearing reductions to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Linear relaxations exist for ReLU, tanh, and sigmoid, and become exact or substantially tighter once pre-activation intervals are partitioned to exclude zero crossings.
Forward citations
Cited by 1 Pith paper
-
ConcoLixir: Reactive LLM Discovery Oracles for Python Concolic Testing
ConcoLixir uses a reactive LLM oracle to improve line coverage in Python concolic testing by 8.6 to 17 percentage points on synthetic, real-world, and library targets.
Reference graph
Works this paper leans on
-
[1]
Sequence to sequence learn- ing with neural networks,
I. Sutskever, O. Vinyals, and Q. V . Le, “Sequence to sequence learn- ing with neural networks,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2014, pp. 3104–3112
2014
-
[2]
Speech recognition with deep recurrent neural networks,
A. Graves, A.-r. Mohamed, and G. Hinton, “Speech recognition with deep recurrent neural networks,” inProc. IEEE Int. Conf. Acoust., Speech Signal Process. (ICASSP), 2013, pp. 6645–6649
2013
-
[3]
Stock market’s price movement prediction with lstm neural networks,
D. M. Nelson, A. C. Pereira, and R. A. de Oliveira, “Stock market’s price movement prediction with lstm neural networks,” inProc. Int. Joint Conf. Neural Netw. (IJCNN), 2017, pp. 1419–1426
2017
-
[4]
Social lstm: Human trajectory prediction in crowded spaces,
A. Alahi, K. Goel, V . Ramanathan, A. Robicquet, L. Fei-Fei, and S. Savarese, “Social lstm: Human trajectory prediction in crowded spaces,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2016, pp. 961–971
2016
-
[5]
Intriguing properties of neural networks,
C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Good- fellow, and R. Fergus, “Intriguing properties of neural networks,” arXiv:1312.6199, 2013
Pith/arXiv arXiv 2013
-
[6]
Explaining and harnessing adversarial examples,
I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,” inProc. Int. Conf. Learn. Represent. (ICLR), 2015
2015
-
[7]
Fooling lidar perception via adversarial trajectory perturbation,
Y . Jia, J. Lu, J. Goswami, H. Li, X. Li, and B. Zhao, “Fooling lidar perception via adversarial trajectory perturbation,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2021, pp. 7898–7907
2021
-
[8]
Popqorn: Quantifying robustness of recurrent neural networks,
C.-Y . Ko, D. Gopinath, M. Shih, C. Pasareanu, and S. Khurshid, “Popqorn: Quantifying robustness of recurrent neural networks,” inProc. Int. Conf. Mach. Learn. (ICML), 2019, pp. 3468–3477
2019
-
[9]
Towards an effective and interpretable refinement approach for dnn verification,
J. Li, G. Bai, L. H. Pham, and J. Sun, “Towards an effective and interpretable refinement approach for dnn verification,” inProc. IEEE Int. Conf. Softw. Qual., Rel., Security (QRS). IEEE, 2023, pp. 569–580
2023
-
[10]
Recognition of whiteboard notes: Online, offline and combination,
M. Liwicki, A. Graves, H. Bunke, and J. Schmidhuber, “Recognition of whiteboard notes: Online, offline and combination,” inSer. Mach. Percept. Artif. Intell., vol. 75. World Scientific, 2012, pp. 1–13
2012
-
[11]
Axiomatic attribution for deep networks,
M. Sundararajan, A. Taly, and Q. Yan, “Axiomatic attribution for deep networks,” 2017. [Online]. Available: https://arxiv.org/abs/1703.01365
Pith/arXiv arXiv 2017
-
[12]
Towards deep learning models resistant to adversarial attacks,
A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards deep learning models resistant to adversarial attacks,”arXiv:1706.06083, 2017
Pith/arXiv arXiv 2017
-
[13]
Ai2: Safety and robustness certification of neural networks with abstract interpretation,
T. Gehr, M. Mirman, D. Drachsler-Cohen, P. Tsankov, S. Chaudhuri, and M. Vechev, “Ai2: Safety and robustness certification of neural networks with abstract interpretation,” inProc. IEEE Symp. Secur. Privacy (SP), 2018, pp. 3–18
2018
-
[14]
Efficient neural network robustness certification with general activation functions,
H. Z. Zhang, T.-W. Weng, P.-Y . Chen, C.-J. Xu, and C.-J. Hsieh, “Efficient neural network robustness certification with general activation functions,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2018, pp. 4939–4948
2018
-
[15]
Fast and precise certification of neural networks,
G. Singh, T. Gehr, M. P ¨uschel, and M. Vechev, “Fast and precise certification of neural networks,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2018, pp. 10 802–10 813
2018
-
[16]
An abstract domain for certifying neural networks,
G. Singh, T. Gehr, M. Mirman, M. P ¨uschel, and M. Vechev, “An abstract domain for certifying neural networks,” inProc. ACM Program. Lang. (POPL), vol. 3, no. POPL, 2019, pp. 1–30
2019
-
[17]
Reluplex: An efficient smt solver for verifying deep neural networks,
G. Katz, C. Barrett, D. L. Dill, K. Julian, and M. J. Kochenderfer, “Reluplex: An efficient smt solver for verifying deep neural networks,” inProc. Int. Conf. Comput. Aided Verification (CAV). Springer, 2017, pp. 97–117
2017
-
[18]
The marabou framework for verification and analysis of deep neural networks,
——, “The marabou framework for verification and analysis of deep neural networks,” inProc. Int. Conf. Comput. Aided Verification (CAV). Springer, 2019, pp. 443–452
2019
-
[19]
Cert-rnn: Towards certifying the robustness of recurrent neural networks,
M. Du, H. Zhang, S. Wang, H. Jin, and C.-J. Hsieh, “Cert-rnn: Towards certifying the robustness of recurrent neural networks,” inProc. IEEE Symp. Secur. Privacy (SP), 2021, pp. 968–985
2021
-
[20]
Rnn-guard: Certified robustness against adversarial examples in recurrent neural networks,
T. Guo, K. Xu, H. Zhang, and D. Lin, “Rnn-guard: Certified robustness against adversarial examples in recurrent neural networks,” inProc. Int. Conf. Learn. Represent. (ICLR), 2021
2021
-
[21]
Certified robustness to pro- grammable transformations in lstms,
B. Paulsen, J. Wang, and C. Wang, “Certified robustness to pro- grammable transformations in lstms,” inProc. Eur. Symp. Res. Comput. Security (ESORICS). Springer, 2020, pp. 562–582
2020
-
[22]
Diffrnn: Differential verification of recurrent neural networks,
S. Mohammadinejad, B. Paulsen, J. V . Deshmukh, and C. Wang, “Diffrnn: Differential verification of recurrent neural networks,” in FORMATS, 2021
2021
-
[23]
Verification of recurrent neural networks using star reachability,
S. Bak, C. Liu, and T. Johnson, “Verification of recurrent neural networks using star reachability,” inProc. Int. Conf. Comput. Aided Verification (CAV). Springer, 2020, pp. 341–363
2020
-
[24]
Branch and bound for piecewise linear neural network verification,
R. Bunel, J. M. Lu, I. Turkaslan, P. H. Torr, P. Kohli, and M. P. Kumar, “Branch and bound for piecewise linear neural network verification,”J. Mach. Learn. Res., vol. 21, no. 42, pp. 1–39, 2020
2020
-
[25]
Beta-crown: Efficient bound propagation with per-neuron split constraints for neural network verification,
S. Wang, H. Zhang, K. Xu, X. Chen, D. Lin, S. Jana, J. Z. Kolter, and E. Wong, “Beta-crown: Efficient bound propagation with per-neuron split constraints for neural network verification,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2021
2021
-
[26]
Improved branch and bound for neural network verification via lagrangian decomposition,
A. De Palma, R. Bunel, A. Desmaison, K. Dvijotham, P. Kohli, P. H. Torr, and M. P. Kumar, “Improved branch and bound for neural network verification via lagrangian decomposition,”arXiv:2104.06718, 2021
arXiv 2021
-
[27]
Scalable neural network verification with branch-and-bound inferred cutting planes,
D. Zhou, C. Brix, G. A. Hanasusanto, and H. Zhang, “Scalable neural network verification with branch-and-bound inferred cutting planes,” in NeurIPS, 2024
2024
-
[28]
Scalable polyhedral verification of recurrent neural networks,
W. Ryou, J. Chen, M. Balunovic, G. Singh, A. Dan, and M. Vechev, “Scalable polyhedral verification of recurrent neural networks,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2020
2020
-
[29]
Neural network verification with branch-and-bound for general nonlinearities,
Z. Shi, Q. Jin, Z. Kolter, S. Jana, C.-J. Hsieh, and H. Zhang, “Neural network verification with branch-and-bound for general nonlinearities,” inTACAS, 2025
2025
-
[30]
Marble: Model-based robustness analysis of stateful deep learning systems,
X. Sun, H. Kazemi, Z. Xu, and C. Wang, “Marble: Model-based robustness analysis of stateful deep learning systems,” inProc. 37th IEEE/ACM Int. Conf. Autom. Softw. Eng. (ASE), 2022, pp. 1–13
2022
-
[31]
A unified approach to interpreting model predictions,
S. M. Lundberg and S.-I. Lee, “A unified approach to interpreting model predictions,” inProc. Adv. Neural Inf. Process. Syst., 2017, pp. 4765– 4774
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.