Let's Ask Gauss: Improved One-Run Privacy Auditing
Pith reviewed 2026-06-27 09:46 UTC · model grok-4.3
The pith
Canary-aligned signals in DP-SGD sum to an asymptotic Gaussian that supports tighter one-run privacy lower bounds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the white-box DP-SGD setting, canary-aligned signals naturally form a sequence of random variables whose normalized sum is asymptotically Gaussian. Leveraging this distributional perspective, the authors develop a DP-auditing framework that leads to tighter privacy lower bounds from a single training run.
What carries the argument
The asymptotic Gaussian distribution of the normalized sum of canary-aligned signals, which converts the observed sequence into a statistical test for membership leakage.
If this is right
- One training run yields a continuous leakage statistic instead of a binary decision, raising the lower bound on observed privacy loss.
- The same run can be reused for multiple canaries without additional training cost.
- Auditing no longer requires choosing an arbitrary threshold that discards signal magnitude.
- The framework applies directly to any white-box DP-SGD implementation that records per-example gradients or losses aligned with inserted canaries.
Where Pith is reading between the lines
- The same Gaussian-sum construction could be applied to other iterative mechanisms whose per-step signals meet Lindeberg-type conditions.
- If the Gaussian approximation holds at moderate sample sizes, the method could be adapted to black-box settings by treating model outputs as proxy signals.
- Empirical checks on very large models would test whether the required weak-dependence conditions remain realistic.
Load-bearing premise
The canary-aligned signals satisfy the dependence and moment conditions needed for their normalized sum to converge to a Gaussian.
What would settle it
Collect the per-step canary signals from a DP-SGD run, normalize their sum, and test whether the empirical distribution deviates from Gaussian at a rate inconsistent with the claimed convergence.
Figures

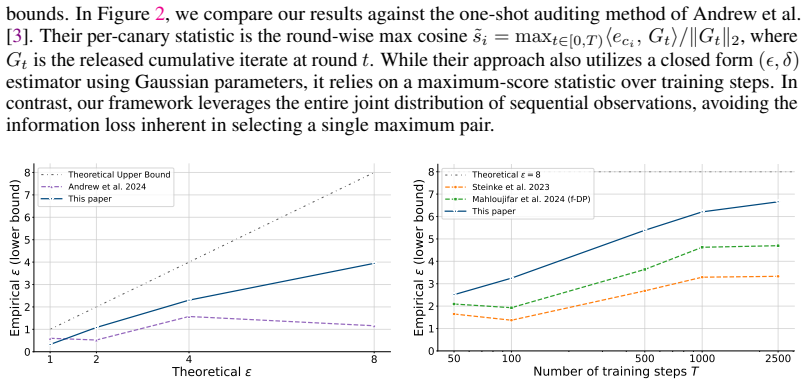
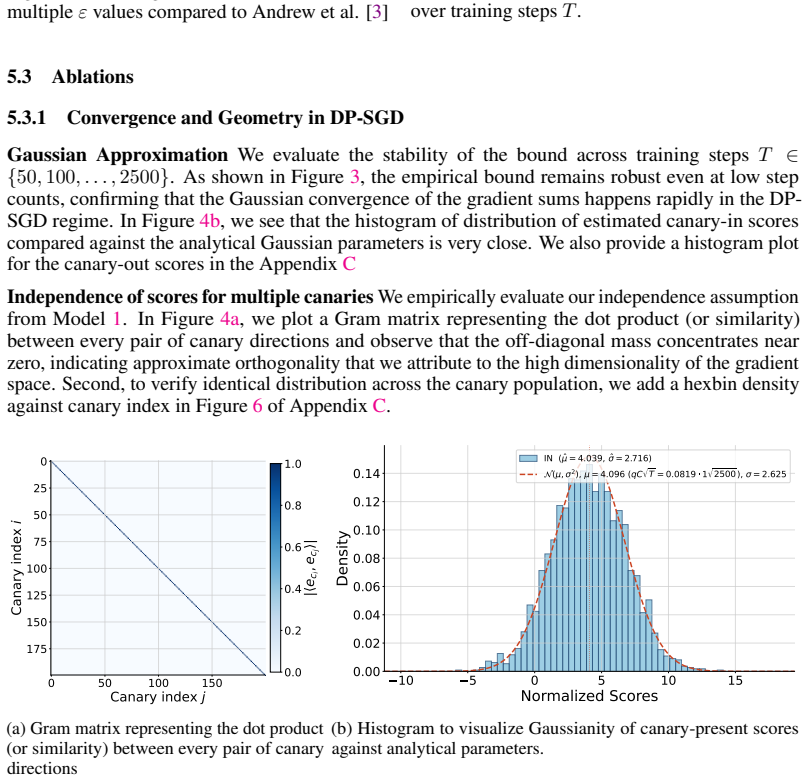


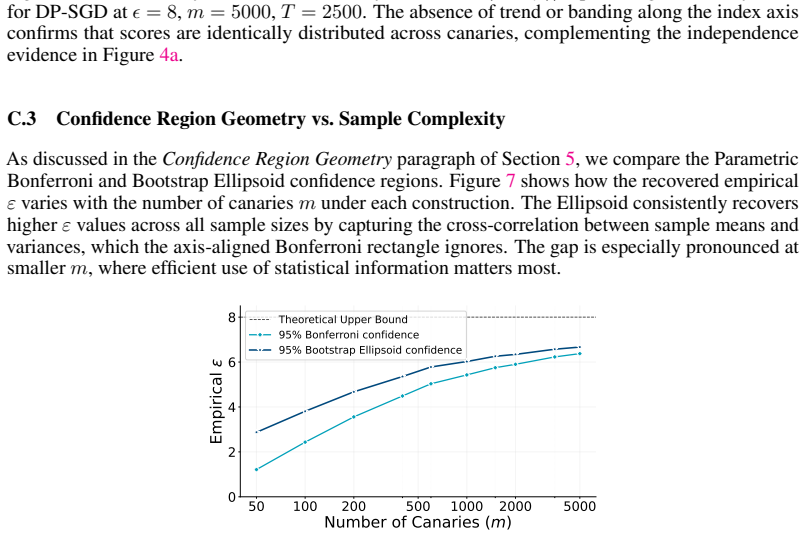
read the original abstract
Privacy auditing provides an important safeguard by estimating the actual information leaked by a model, thus ensuring that theoretical privacy guarantees hold in practice. We study empirical privacy auditing for differentially private (DP) machine learning, focusing on efficient one-run methods for mechanisms such as DP-SGD. Prior one-run approaches threshold training examples or "canaries" into binary membership guesses, which discards useful information. We show that, in the white-box DP-SGD setting, canary-aligned signals naturally form a sequence of random variables whose normalized sum is asymptotically Gaussian. Leveraging this distributional perspective, we develop a DP-auditing framework that leads to tighter privacy lower bounds from a single training run.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in the white-box DP-SGD setting, canary-aligned signals form a sequence of random variables whose normalized sum converges asymptotically to a Gaussian distribution. Building on this property, the authors develop a one-run auditing framework that extracts more information than binary canary thresholding, yielding tighter empirical privacy lower bounds from a single training run.
Significance. If the asymptotic Gaussian claim is rigorously established, the work would improve the practicality of privacy auditing for DP mechanisms by reducing the number of required runs while increasing bound tightness. The approach leverages distributional information rather than discarding it via thresholding, which is a clear methodological advance if the CLT application holds.
major comments (2)
- [Abstract] Abstract: The central claim that 'canary-aligned signals naturally form a sequence of random variables whose normalized sum is asymptotically Gaussian' is asserted without derivation or verification that the sequence satisfies the conditions (weak dependence, Lindeberg-type) of a CLT theorem applicable to the dependent gradient updates in DP-SGD. This distributional property is load-bearing for the entire auditing framework and the resulting tighter bounds.
- [Auditing framework] The auditing procedure (developed from the Gaussian perspective) relies on tail probabilities or quantiles of the limiting normal; without an explicit argument that dependence induced by shared parameters and noise schedule does not violate the required conditions, the privacy lower bounds lack justification.
minor comments (2)
- [Introduction] Notation for the canary-aligned signal sequence and its variance normalization should be introduced with explicit definitions early in the manuscript to improve readability.
- [Abstract] The abstract mentions 'tighter privacy lower bounds' but does not quantify the improvement relative to prior one-run methods; a brief comparison table or statement would help.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying the need for stronger justification of the asymptotic Gaussianity claim, which underpins our one-run auditing approach. We address the two major comments point by point below and will revise the manuscript to provide the requested derivations.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'canary-aligned signals naturally form a sequence of random variables whose normalized sum is asymptotically Gaussian' is asserted without derivation or verification that the sequence satisfies the conditions (weak dependence, Lindeberg-type) of a CLT theorem applicable to the dependent gradient updates in DP-SGD. This distributional property is load-bearing for the entire auditing framework and the resulting tighter bounds.
Authors: We agree that an explicit verification of the CLT conditions is required. The manuscript sketches the argument by noting that per-step noise additions are independent and that gradient contributions are bounded, but it does not fully check weak dependence or Lindeberg conditions for the dependent sequence induced by parameter sharing. We will add a new subsection that applies a CLT for weakly dependent sequences (e.g., via mixing coefficients decaying with the noise schedule) and verifies the Lindeberg condition using uniform moment bounds on the per-step canary-aligned signals. revision: yes
-
Referee: [Auditing framework] The auditing procedure (developed from the Gaussian perspective) relies on tail probabilities or quantiles of the limiting normal; without an explicit argument that dependence induced by shared parameters and noise schedule does not violate the required conditions, the privacy lower bounds lack justification.
Authors: The auditing bounds are derived from the limiting normal quantiles under the assumption that the normalized sum converges in distribution. We will expand the auditing framework section with an explicit argument that the dependence structure (shared parameters across steps and the fixed noise schedule) satisfies the conditions of a suitable CLT for triangular arrays of dependent random variables; specifically, we will bound the covariance terms using the fact that canary alignment isolates contributions and that later steps dominate due to the noise decay. This will directly justify the tail probabilities used for the tighter lower bounds. revision: yes
Circularity Check
No circularity: CLT-based Gaussian claim is external to inputs
full rationale
The paper states that canary-aligned signals 'naturally form a sequence of random variables whose normalized sum is asymptotically Gaussian' and builds the auditing framework on this property. This rests on an application of the central limit theorem to the signals under the DP-SGD mechanism, which is an external theorem rather than a self-definition, fitted parameter renamed as prediction, or self-citation chain. No equations or steps in the provided text reduce the privacy lower bounds to the inputs by construction, and no load-bearing self-citations or ansatzes are present. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The sequence of canary-aligned signals in white-box DP-SGD satisfies conditions for the central limit theorem, so their normalized sum is asymptotically Gaussian.
Reference graph
Works this paper leans on
-
[1]
Goodfellow, H
Martín Abadi, Andy Chu, Ian J. Goodfellow, H. Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. Deep learning with differential privacy. InProceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, pages 308–318. ACM, 2016. 1, 3, 14
2016
-
[2]
Kymatio: Scattering transforms in python.Journal of Machine Learning Research, 21(60):1–6, 2020
Mathieu Andreux, Tomás Angles, Georgios Exarchakis, Roberto Leonarduzzi, Gaspar Rochette, Louis Thiry, John Zarka, Stéphane Mallat, Joakim Andén, Eugene Belilovsky, et al. Kymatio: Scattering transforms in python.Journal of Machine Learning Research, 21(60):1–6, 2020. 8
2020
-
[3]
Brendan McMahan, and Vinith M
Galen Andrew, Peter Kairouz, Sewoong Oh, Alina Oprea, H. Brendan McMahan, and Vinith M. Suriyakumar. One-shot empirical privacy estimation for federated learning. InThe Twelfth International Conference on Learning Representations (ICLR), 2024. 2, 3, 4, 5, 9
2024
-
[4]
Nearly tight black- box auditing of differentially private machine learning
Meenatchi Sundaram Muthu Selva Annamalai and Emiliano De Cristofaro. Nearly tight black- box auditing of differentially private machine learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. 4
2024
-
[5]
General-purpose f-DP estimation and auditing in a black-box setting.CoRR, abs/2502.07066,
Önder Askin, Holger Dette, Martin Dunsche, Tim Kutta, Yun Lu, Yu Wei, and Vassilis Zikas. General-purpose f-DP estimation and auditing in a black-box setting.CoRR, abs/2502.07066,
-
[6]
Privacy amplification by subsampling: Tight analyses via couplings and divergences
Borja Balle, Gilles Barthe, and Marco Gaboardi. Privacy amplification by subsampling: Tight analyses via couplings and divergences. InAdvances in Neural Information Processing Systems, volume 31, pages 6280–6290, 2018. 3
2018
-
[7]
The secret sharer: Evaluating and testing unintended memorization in neural networks
Nicholas Carlini, Chang Liu, Úlfar Erlingsson, Jernej Kos, and Dawn Song. The secret sharer: Evaluating and testing unintended memorization in neural networks. In28th USENIX security symposium (USENIX security 19), pages 267–284, 2019. 1, 4
2019
-
[8]
Berger.Statistical Inference
George Casella and Roger L. Berger.Statistical Inference. Duxbury, 2002. 7
2002
-
[9]
Hubert Chan, Elaine Shi, and Dawn Song
T.-H. Hubert Chan, Elaine Shi, and Dawn Song. Private and continual release of statistics.ACM Transactions on Information and System Security, 14(3):1–24, 2011. 1
2011
-
[10]
Calibrating noise to sensitivity in private data analysis
Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam Smith. Calibrating noise to sensitivity in private data analysis. InTheory of Cryptography, volume 3876 ofLecture Notes in Computer Science, pages 265–284. Springer, 2006. 1, 2
2006
-
[11]
The algorithmic foundations of differential privacy.Founda- tions and Trends in Theoretical Computer Science, 2014
Cynthia Dwork and Aaron Roth. The algorithmic foundations of differential privacy.Founda- tions and Trends in Theoretical Computer Science, 2014. 1
2014
-
[12]
Tibshirani.An Introduction to the Bootstrap
Bradley Efron and Robert J. Tibshirani.An Introduction to the Bootstrap. Chapman and Hall/CRC, 1994. 7
1994
-
[13]
Auditing differentially private machine learning: How private is private sgd?Advances in Neural Information Processing Systems, 33:22205–22216, 2020
Matthew Jagielski, Jonathan Ullman, and Alina Oprea. Auditing differentially private machine learning: How private is private sgd?Advances in Neural Information Processing Systems, 33:22205–22216, 2020. 1, 4
2020
-
[14]
Practical and private (deep) learning without sampling or shuffling
Peter Kairouz, Brendan McMahan, Shuang Song, Om Thakkar, Abhradeep Thakurta, and Zheng Xu. Practical and private (deep) learning without sampling or shuffling. InInternational Conference on Machine Learning, pages 5213–5225. PMLR, 2021. 2, 8
2021
-
[15]
How well can differential privacy be audited in one run?arXiv preprint arXiv:2503.07199, 2025
Amit Keinan, Moshe Shenfeld, and Katrina Ligett. How well can differential privacy be audited in one run?arXiv preprint arXiv:2503.07199, 2025. 4
arXiv 2025
-
[16]
Harnessing large-language models to generate private synthetic text, 2024
Alexey Kurakin, Natalia Ponomareva, Umar Syed, Liam MacDermed, and Andreas Terzis. Harnessing large-language models to generate private synthetic text, 2024. 1
2024
-
[17]
The matrix mechanism: Optimizing linear counting queries under differential privacy.The VLDB Journal, 24(6):757–781, 2015
Chao Li, Gerome Miklau, Michael Hay, Andrew McGregor, and Vibhor Rastogi. The matrix mechanism: Optimizing linear counting queries under differential privacy.The VLDB Journal, 24(6):757–781, 2015. 1 11
2015
-
[18]
Enhancing one-run privacy auditing with quantile regression-based membership inference
Terrance Liu, Matteo Boglioni, Yiwei Fu, Shengyuan Hu, Pratiksha Thaker, and Zhiwei Steven Wu. Enhancing one-run privacy auditing with quantile regression-based membership inference. arXiv preprint arXiv:2506.15349, 2025. 4
arXiv 2025
-
[19]
Yun Lu, Malik Magdon-Ismail, Yu Wei, and Vassilis Zikas. The normal distributions indis- tinguishability spectrum and its application to privacy-preserving machine learning.arXiv preprint arXiv:2309.01243, 2023. Preliminary version to appear at the Theory and Practice of Differential Privacy (TPDP) 2026 workshop. 2, 3
Pith/arXiv arXiv 2023
-
[20]
Eureka: A general framework for black-box differential privacy estimators
Yun Lu, Malik Magdon-Ismail, Yu Wei, and Vassilis Zikas. Eureka: A general framework for black-box differential privacy estimators. In2024 IEEE Symposium on Security and Privacy (SP), pages 913–931. IEEE, 2024. 1, 4
2024
-
[21]
CANIFE: Crafting canaries for empirical privacy measurement in federated learning
Samuel Maddock, Alexandre Sablayrolles, and Pierre Stock. CANIFE: Crafting canaries for empirical privacy measurement in federated learning. InThe Eleventh International Conference on Learning Representations (ICLR), 2023. 4
2023
-
[22]
Auditing f-differential privacy in one run
Saeed Mahloujifar, Luca Melis, and Kamalika Chaudhuri. Auditing f-differential privacy in one run. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 42615–42641. PMLR, 2025. 2, 3, 4, 5, 8, 10
2025
-
[23]
Graphical-model based estimation and inference for differential privacy
Ryan McKenna, Daniel Sheldon, and Gerome Miklau. Graphical-model based estimation and inference for differential privacy. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 4435–4444. PMLR, 2019. 1
2019
-
[24]
Tight auditing of differentially private machine learning
Milad Nasr, Jamie Hayes, Thomas Steinke, Borja Balle, Florian Tramèr, Matthew Jagielski, Nicholas Carlini, and Andreas Terzis. Tight auditing of differentially private machine learning. In32nd USENIX Security Symposium (USENIX Security 23), pages 1631–1648. USENIX Association, 2023. 1, 3, 4
2023
-
[25]
Ad- versary instantiation: Lower bounds for differentially private machine learning
Milad Nasr, Shuang Songi, Abhradeep Thakurta, Nicolas Papernot, and Nicholas Carlin. Ad- versary instantiation: Lower bounds for differentially private machine learning. In2021 IEEE Symposium on security and privacy (SP), pages 866–882. IEEE, 2021. 1, 4
2021
-
[26]
Classical-type limit theorems for sums of independent random variables
Valentin V Petrov. Classical-type limit theorems for sums of independent random variables. In Limit theorems of probability theory, pages 1–24. Springer, 2000. 16
2000
-
[27]
Springer Science & Business Media,
Valentin V Petrov.Sums of independent random variables. Springer Science & Business Media,
-
[28]
Membership inference attacks against machine learning models
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. Membership inference attacks against machine learning models. In2017 IEEE symposium on security and privacy (SP), pages 3–18. IEEE, 2017. 4
2017
-
[29]
Privacy auditing with one (1) training run
Thomas Steinke, Milad Nasr, and Matthew Jagielski. Privacy auditing with one (1) training run. InAdvances in Neural Information Processing Systems, volume 36, 2023. 1, 2, 3, 4, 5, 8, 10
2023
-
[30]
DP-CGAN: Differentially private synthetic data and label generation
Reihaneh Torkzadehmahani, Peter Kairouz, and Benedict Paten. DP-CGAN: Differentially private synthetic data and label generation. In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 98–104. IEEE Computer Society, 2019. 1
2019
-
[31]
Privacy audit as bits transmission: (Im)possibilities for audit by one run
Zihang Xiang, Tianhao Wang, and Di Wang. Privacy audit as bits transmission: (Im)possibilities for audit by one run. In34th USENIX Security Symposium (USENIX Security 25). USENIX Association, 2025. 2, 4, 5
2025
-
[32]
Tight privacy audit in one run.CoRR, abs/2509.08704, 2025
Zihang Xiang, Tianhao Wang, Hanshen Xiao, Yuan Tian, and Di Wang. Tight privacy audit in one run.CoRR, abs/2509.08704, 2025. 2, 4
arXiv 2025
-
[33]
Privacy risk in machine learning: Analyzing the connection to overfitting
Samuel Yeom, Irene Giacomelli, Matt Fredrikson, and Somesh Jha. Privacy risk in machine learning: Analyzing the connection to overfitting. In2018 IEEE 31st computer security foundations symposium (CSF), pages 268–282. IEEE, 2018. 4 12
2018
-
[34]
PATE-GAN: Generating synthetic data with differential privacy guarantees
Jinsung Yoon, James Jordon, and Mihaela van der Schaar. PATE-GAN: Generating synthetic data with differential privacy guarantees. InInternational Conference on Learning Representa- tions, 2019. 1
2019
-
[35]
Bayesian estimation of differential privacy
Santiago Zanella-Béguelin, Lukas Wutschitz, Shruti Tople, Ahmed Salem, Victor Rühle, Andrew Paverd, Mohammad Naseri, Boris Köpf, and Daniel Jones. Bayesian estimation of differential privacy. InProceedings of the 40th International Conference on Machine Learning (ICML),
-
[36]
PrivSyn: Differentially private data synthesis
Zhikun Zhang, Tianhao Wang, Ninghui Li, Jean Honorio, Michael Backes, Shibo He, Jiming Chen, and Yang Zhang. PrivSyn: Differentially private data synthesis. In30th USENIX Security Symposium (USENIX Security 21). USENIX Association, 2021. 1 13 A White-box DP-SGD Transcript Algorithm 2White-box DP-SGD transcript, following the clipped-and-noised DP-SGD upda...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.