Where Computation Lives Inside TabPFN: Causal Localisation of Attention Head Function
Pith reviewed 2026-06-27 07:17 UTC · model grok-4.3
The pith
TabPFN computation concentrates in one attention head whose peak layer shifts with task complexity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
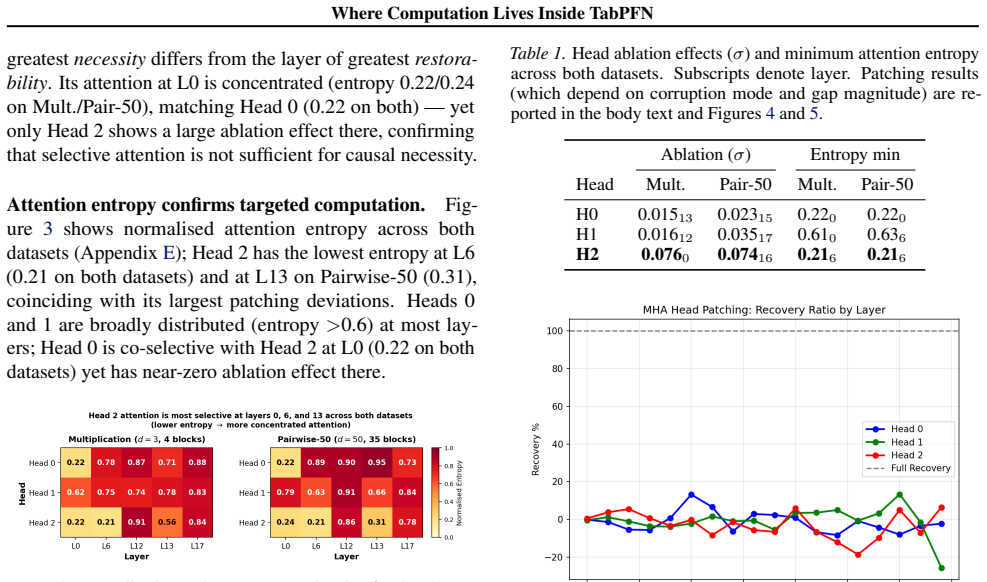
One feature-wise attention head in TabPFN 2.5 exhibits causal necessity that is two to five times greater than that of the other heads at its peak layer; the layer at which this dominance occurs shifts across regression tasks of different complexity, while the remaining heads display symmetric profiles concentrated in later layers. Convergent measurements from activation patching, ablation, and attention entropy locate the computationally active layers of the dominant head, and contrastive activation steering fails to generalize because task structure is carried by context-dependent attention.
What carries the argument
Activation patching that replaces the output of a single attention head with its value from a different forward pass and measures the resulting change in the model's prediction.
If this is right
- A single head accounts for the bulk of causal effect at its peak layer across the tested tasks.
- The layer carrying this dominant effect changes when the regression problem varies in complexity.
- The other heads show matching behavior concentrated in later layers.
- Contrastive activation steering does not transfer across samples because attention patterns encode task information in a context-dependent way.
Where Pith is reading between the lines
- If the same head-dominance pattern appears on real-world tabular data, then model editing or pruning efforts could focus compute on the dominant head without retraining the full network.
- The observed failure of steering to generalize points to a broader difference in how in-context learning works in tabular transformers compared with language models.
- Applying the same patching protocol to classification tasks would test whether the single-head dominance and layer-shift pattern is specific to regression.
Load-bearing premise
The two synthetic regression datasets together with the activation patching procedure accurately measure the true causal contributions of individual heads without artifacts introduced by the patching method or the choice of data.
What would settle it
Running the same activation patching protocol on a collection of real tabular regression datasets and finding that no head reaches two-to-five times the causal effect of the others at any layer would falsify the dominance claim.
Figures




read the original abstract
We present the first causal mechanistic analysis of a tabular foundation model, investigating how TabPFN 2.5's feature wise attention heads distribute computation across layers. Using activation patching, ablation, and attention entropy across two synthetic regression datasets, we find clear temporal specialisation: one head's causal necessity dominates that of the others by 2 to 5 times at peak layer, with its dominant layer shifting across tasks of different complexity, while the remaining heads exhibit symmetric late layer profiles. Attention entropy and patching provide convergent evidence for the computationally active layers of the dominant head. We additionally investigate inference time steerability via contrastive activation steering, which fails to transfer across samples. We attribute this result to TabPFN's in context learning mechanism, which encodes task structure through context dependent attention rather than the stable parametric directions that make steering tractable in language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the first causal mechanistic analysis of TabPFN 2.5's feature-wise attention heads, using activation patching, ablation, and attention entropy on two synthetic regression datasets. It reports that one head's causal necessity dominates the others by 2-5 times at its peak layer (with the peak shifting by task complexity), while remaining heads show symmetric late-layer profiles; convergent evidence from entropy and patching is cited for the dominant head's active layers. Contrastive activation steering is shown to fail to transfer across samples, which the authors attribute to TabPFN's context-dependent attention in in-context learning rather than stable parametric directions.
Significance. If the patching results hold after controls, this would be a valuable first mechanistic study of a tabular foundation model, extending interpretability methods beyond language models and highlighting how in-context learning organizes computation differently. The convergent evidence from multiple techniques and the falsifiable claim about steering failure are strengths that could guide future work on tabular model internals.
major comments (2)
- [Methods (activation patching experiments)] Activation patching subsection: no controls are described for patching-induced artifacts (e.g., random ablation baselines, same-task vs. cross-task patching, or entropy-matched controls). This is load-bearing for the central claim of 2-5x dominance and layer shifts, as the skeptic correctly notes that patching on small synthetic regressions can alter downstream patterns via distribution shift unrelated to the original heads.
- [Results (causal necessity and layer profiles)] Results on head dominance and layer profiles: the 2-5x causal necessity ratio and symmetric late-layer profiles are stated without the underlying metric definition, error bars, dataset statistics, or robustness checks. This prevents evaluation of whether the reported asymmetry reflects genuine specialization.
minor comments (1)
- [Abstract] Abstract lacks any quantitative details, error bars, or dataset descriptions, which hinders immediate assessment even though the full text is referenced.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will incorporate revisions to strengthen the experimental controls and reporting of results.
read point-by-point responses
-
Referee: [Methods (activation patching experiments)] Activation patching subsection: no controls are described for patching-induced artifacts (e.g., random ablation baselines, same-task vs. cross-task patching, or entropy-matched controls). This is load-bearing for the central claim of 2-5x dominance and layer shifts, as the skeptic correctly notes that patching on small synthetic regressions can alter downstream patterns via distribution shift unrelated to the original heads.
Authors: We agree that the absence of explicit controls for patching artifacts is a limitation. In the revised manuscript we will add random ablation baselines, same-task versus cross-task patching comparisons, and entropy-matched controls. These will be reported alongside the original results to demonstrate that the 2-5x dominance and layer shifts are not artifacts of distribution shift. revision: yes
-
Referee: [Results (causal necessity and layer profiles)] Results on head dominance and layer profiles: the 2-5x causal necessity ratio and symmetric late-layer profiles are stated without the underlying metric definition, error bars, dataset statistics, or robustness checks. This prevents evaluation of whether the reported asymmetry reflects genuine specialization.
Authors: We will expand the results section to define the causal necessity metric explicitly, report error bars (across seeds and datasets), include dataset statistics, and add robustness checks such as alternative patching strengths and cross-validation of the dominance ratio. These changes will allow direct evaluation of the reported asymmetry. revision: yes
Circularity Check
No circularity: empirical analysis without derivations or self-referential reductions
full rationale
The paper conducts an empirical mechanistic interpretability study via activation patching, ablation, and entropy measurements on two synthetic regression datasets. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. Claims rest on experimental observations of head dominance and steering failure rather than any chain that reduces by construction to its own inputs. The analysis is self-contained against external benchmarks of model behavior.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Pearl , year=
J. Pearl , year=. Causality , publisher=
-
[2]
2025 , howpublished =
2025
-
[3]
2017 , publisher=
Elements of causal inference: foundations and learning algorithms , author=. 2017 , publisher=
2017
-
[4]
Noda, Ryunosuke and Ichikawa, Daisuke and Shibagaki, Yugo , title =. Scientific Reports , year =. doi:10.1038/s41598-024-73898-4 , url =
-
[5]
Dyikanov, Daniiar and Zaitsev, Aleksandr and Vasileva, Tatiana and Wang, Iris and Sokolov, Arseniy A. and Bolshakov, Evgenii S. and et al. , title =. Cancer Cell , year =. doi:10.1016/j.ccell.2024.04.008 , url =
-
[6]
Alzakari, Saud A. and Aldrees, Abdullah and Umer, Muhammad Fahad and Cascone, Luca and Innab, Nader and Ashraf, Imran , title =. SLAS Technology , year =. doi:10.1016/j.slast.2024.100203 , url =
-
[7]
Karabacak, Mert and Schupper, Alexander and Carr, Matthew and Margetis, Konstantinos , title =. Asian Spine Journal , year =. doi:10.31616/asj.2024.0048 , url =
-
[8]
European Actuarial Journal , year =
Brauer, Alexej , title =. European Actuarial Journal , year =. doi:10.1007/s13385-024-00388-2 , url =
-
[9]
Proceedings of the 2024 International Conference on Green Energy, Computing and Sustainable Technology (GECOST) , year =
Chu, Jasmin Ze Kee and Than, Joel Chia Ming and Jo, Hudyjaya Siswoyo , title =. Proceedings of the 2024 International Conference on Green Energy, Computing and Sustainable Technology (GECOST) , year =
2024
-
[10]
Nguyen, Hoang , title =
-
[11]
Early fault classification in rotating machinery with limited data using tabpfn
Magad. Early Fault Classification in Rotating Machinery With Limited Data Using. IEEE Sensors Journal , year =. doi:10.1109/JSEN.2023.3331100 , url =
-
[12]
Minimal Supervision, Maximum Accuracy: TabPFN for Microcontroller Performance Prediction , booktitle =
Bellarmino, Nicol. Minimal Supervision, Maximum Accuracy: TabPFN for Microcontroller Performance Prediction , booktitle =. 2025 , doi =
2025
-
[13]
Underground Space , year =
He, Ping and Cao, Zhanlin and Di, Honggui and Shen, Guangxin and Zhou, Shunhua , title =. Underground Space , year =
-
[14]
2025 , doi =
Chen, Bowen and Xiong, Zhuo and Zhao, Yongchun and Zhang, Junying , title =. 2025 , doi =
2025
-
[15]
The Journal of Physical Chemistry C , year =
Sharma, Sandeep and others , title =. The Journal of Physical Chemistry C , year =. doi:10.1021/acs.jpcc.5c03868 , url =
-
[16]
2025 , note =
Sharma, Sandeep , title =. 2025 , note =
2025
-
[17]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[18]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[19]
M. J. Kearns , title =
-
[20]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[21]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[22]
Suppressed for Anonymity , author=
-
[23]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[24]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[25]
Advances in Neural Information Processing Systems , year=
Why do tree-based models still outperform deep learning on tabular data? , author=. Advances in Neural Information Processing Systems , year=
-
[26]
Advances in Neural Information Processing Systems , volume=
Revisiting Deep Learning Models for Tabular Data , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
International Conference on Learning Representations , year =
TabPFN: A transformer that solves small tabular classification problems in a second , author =. International Conference on Learning Representations , year =
-
[28]
Accurate predictions on small data with a tabular foundation model , author =. Nature , year =. doi:10.1038/s41586-024-08328-6 , publisher =
-
[29]
Interpretable Machine Learning for TabPFN , ISBN=
Rundel, David and Kobialka, Julius and von Crailsheim, Constantin and Feurer, Matthias and Nagler, Thomas and Rügamer, David , year=. Interpretable Machine Learning for TabPFN , ISBN=. doi:10.1007/978-3-031-63797-1_23 , booktitle=
-
[30]
2024 , eprint=
The Linear Representation Hypothesis and the Geometry of Large Language Models , author=. 2024 , eprint=
2024
-
[31]
2023 , eprint=
Explainability for Large Language Models: A Survey , author=. 2023 , eprint=
2023
-
[32]
2020 , note =
nostalgebraist , title =. 2020 , note =
2020
-
[33]
Probing Classifiers: Promises, Shortcomings, and Advances
Belinkov, Yonatan , title =. Computational Linguistics , volume =. 2022 , month =. doi:10.1162/coli_a_00422 , url =
work page internal anchor Pith review doi:10.1162/coli_a_00422 2022
-
[34]
2025 , eprint=
A Closer Look at TabPFN v2: Understanding Its Strengths and Extending Its Capabilities , author=. 2025 , eprint=
2025
-
[35]
2022 , eprint=
In-context Learning and Induction Heads , author=. 2022 , eprint=
2022
-
[36]
2023 , eprint=
In-Context Learning Creates Task Vectors , author=. 2023 , eprint=
2023
-
[37]
2024 , eprint=
Function Vectors in Large Language Models , author=. 2024 , eprint=
2024
-
[38]
2018 , eprint=
Understanding intermediate layers using linear classifier probes , author=. 2018 , eprint=
2018
-
[39]
2021 , eprint=
Probing Classifiers: Promises, Shortcomings, and Advances , author=. 2021 , eprint=
2021
-
[40]
2025 , eprint=
Exploring Representations and Interventions in Time Series Foundation Models , author=. 2025 , eprint=
2025
-
[41]
2023 , eprint=
Locating and Editing Factual Associations in GPT , author=. 2023 , eprint=
2023
-
[42]
2024 , eprint=
How to use and interpret activation patching , author=. 2024 , eprint=
2024
-
[43]
2025 , eprint=
Grinsztajn, L\'. 2025 , eprint=
2025
-
[44]
2023 , eprint=
Steering Language Models With Activation Engineering , author=. 2023 , eprint=
2023
-
[45]
Panickssery, Nina and Gabrieli, Nick and Schulz, Julian and Tong, Meg and Hubinger, Evan and Turner, Alexander Matt , year=. Steering. 2312.06681 , archivePrefix=
-
[46]
2026 , eprint=
In Search of Grandmother Cells: Tracing Interpretable Neurons in Tabular Representations , author=. 2026 , eprint=
2026
-
[47]
Proceedings of the 42nd International Conference on Machine Learning , series =
Which Attention Heads Matter for In-Context Learning? , author =. Proceedings of the 42nd International Conference on Machine Learning , series =. 2025 , publisher =
2025
-
[48]
Transformer Circuits Thread , year=
A Mathematical Framework for Transformer Circuits , author=. Transformer Circuits Thread , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.