Exposure Bias as Epistemic Underidentification in Recursive Forecasting
Pith reviewed 2026-06-27 07:47 UTC · model grok-4.3
The pith
Recursive forecasting under partial observability is an epistemic underidentification problem, not only a distribution shift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under partial observability or state truncation, recursive rollout is an epistemic underidentification problem. Even with deterministic latent dynamics, one-step Bayes supervision identifies behavior only on observed contexts and need not identify the deployed recursive predictor once rollout queries self-generated induced states whose correct local targets are not determined by numeric state alone.
What carries the argument
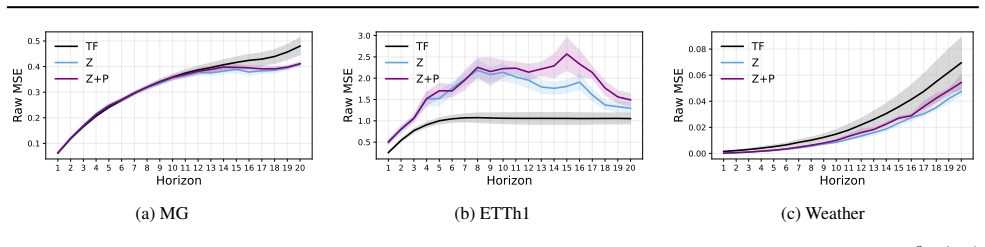
Induced states (model-generated states visited during rollout) and provenance variables (additional history encodings), which together decompose induced-state error into teacher-forcing/rollout mismatch, representation-class approximation, and provenance information gaps.
If this is right
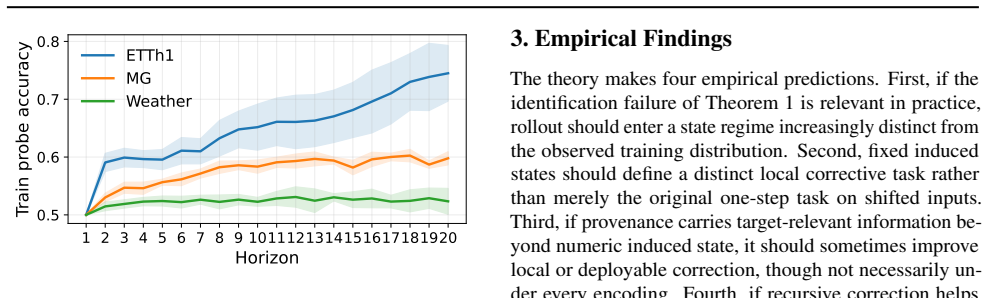
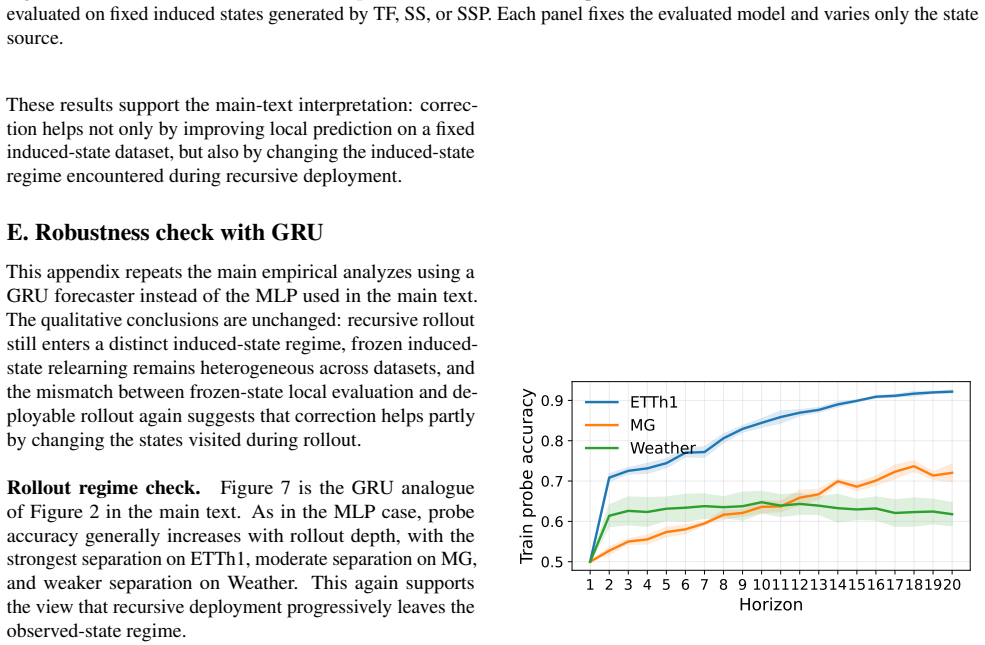
- Rollout enters a distinct induced-state regime separate from the observed training contexts.
- Fixed induced states define a distinct local corrective task from standard teacher-forcing correction.
- Closed-loop performance gains can arise from changing which induced states are visited, not solely from local adaptation.
- A binary provenance encoding enables conditional further gains via provenance-aware correction.
Where Pith is reading between the lines
- The same underidentification logic could be tested in autoregressive models outside forecasting, such as sequence generation with incomplete context.
- Explicit measurement of provenance gaps during rollout could guide new training objectives that simulate self-generated states more directly.
- The distinction between observed and induced states suggests examining whether similar gaps appear in reinforcement learning policies trained on partial observations.
Load-bearing premise
One-step Bayes supervision on observed contexts is insufficient to identify the correct local targets for self-generated induced states during rollout.
What would settle it
An experiment in which the one-step supervised predictor achieves identical performance on rollout queries as a predictor given full provenance information would falsify the underidentification claim.
Figures






read the original abstract
Recursive multi-step forecasting is usually framed as distribution shift: models are trained on observed histories but deployed on their own predictions. We show this framing is incomplete by proving that, under partial observability or state truncation, recursive rollout is also an epistemic underidentification problem. Even with deterministic latent dynamics, one-step Bayes supervision identifies behavior only on observed contexts and need not identify the deployed recursive predictor once rollout queries self-generated induced states whose correct local targets are not determined by numeric state alone. We formalize this with induced states $Z$ and provenance variables $P$, and derive a decomposition of induced-state error into teacher-forcing/rollout mismatch, representation--class approximation, and provenance information gaps. Empirically, we show that rollout enters a distinct induced-state regime, that fixed induced states define a distinct local corrective task, and that closed-loop gains arise not only from local adaptation but also from changing the induced states visited during rollout. Using a simple binary provenance encoding, provenance-aware correction can further improve performance, though gains are conditional rather than uniform. These results recast exposure bias as reasoning under self-induced epistemic uncertainty.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that exposure bias in recursive multi-step forecasting is incompletely framed as distribution shift; under partial observability or state truncation it is also an epistemic underidentification problem. Even with deterministic latent dynamics, one-step Bayes supervision on observed contexts need not identify the correct local targets for self-generated induced states Z during rollout, because those targets depend on provenance variables P not recoverable from numeric state alone. The work formalizes this via induced states Z and provenance P, derives a decomposition of induced-state error into teacher-forcing/rollout mismatch, representation-class approximation, and provenance information gaps, and reports empirical results showing that rollout enters a distinct induced-state regime, that fixed induced states define a distinct local corrective task, and that a simple binary provenance encoding yields conditional closed-loop gains.
Significance. If the formal decomposition and empirical regime distinctions hold, the reframing supplies a useful conceptual distinction between distribution shift and epistemic underidentification, together with an explicit three-term error decomposition that could inform targeted corrections. The observation that closed-loop gains arise in part from altering the induced states visited during rollout, rather than solely from local adaptation, is a concrete and potentially actionable insight. The conditional improvement from provenance-aware correction illustrates one practical direction for addressing the provenance gap.
major comments (2)
- [§3] §3 (formalization and proof): The central claim that one-step Bayes supervision identifies behavior only on observed contexts and need not identify the recursive predictor on induced states Z rests on showing that correct local targets are not determined by numeric state alone; the derivation must explicitly demonstrate that the provenance-gap term remains nonzero even under deterministic latent dynamics, otherwise the underidentification result reduces to a restatement of partial observability.
- [§4] §4 (empirical results): The claims that 'rollout enters a distinct induced-state regime' and that 'provenance-aware correction can further improve performance' are load-bearing for the practical significance of the framing; without reported quantitative metrics, dataset specifications, model architectures, or statistical comparisons against standard teacher-forcing baselines, the magnitude and reliability of these effects cannot be assessed.
minor comments (2)
- [Abstract] Abstract: the phrase 'using a simple binary provenance encoding' is introduced without indicating the underlying forecasting task or base model, which would help readers contextualize the conditional gains.
- [Notation] Notation: the distinction between induced states Z and provenance variables P would benefit from a short illustrative example immediately after their introduction to improve readability for readers unfamiliar with the provenance framing.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. Below we respond point by point to the two major comments. We agree that both points identify areas where the manuscript can be strengthened and will revise accordingly.
read point-by-point responses
-
Referee: [§3] §3 (formalization and proof): The central claim that one-step Bayes supervision identifies behavior only on observed contexts and need not identify the recursive predictor on induced states Z rests on showing that correct local targets are not determined by numeric state alone; the derivation must explicitly demonstrate that the provenance-gap term remains nonzero even under deterministic latent dynamics, otherwise the underidentification result reduces to a restatement of partial observability.
Authors: We agree that the derivation would benefit from an explicit step isolating the provenance-gap term under deterministic dynamics. The current argument already separates P from the numeric state Z by definition (P encodes history or context not recoverable from the observed variables alone), but we will add a short lemma or expanded paragraph in §3 that constructs the gap explicitly: even when the latent dynamics are deterministic, the correct local target for a given induced state Z depends on the value of P, which cannot be recovered from Z. This will be inserted before the error decomposition to make the nonzero gap under determinism fully transparent. revision: yes
-
Referee: [§4] §4 (empirical results): The claims that 'rollout enters a distinct induced-state regime' and that 'provenance-aware correction can further improve performance' are load-bearing for the practical significance of the framing; without reported quantitative metrics, dataset specifications, model architectures, or statistical comparisons against standard teacher-forcing baselines, the magnitude and reliability of these effects cannot be assessed.
Authors: The empirical section reports performance differences and regime distinctions on concrete tasks, but we accept that the presentation would be stronger with additional quantitative detail. In the revision we will expand §4 to include: (i) exact numerical metrics (error values, deltas) in tables, (ii) full dataset names, sizes, and preprocessing steps, (iii) model architecture and hyperparameter specifications, and (iv) direct statistical comparisons against teacher-forcing baselines with confidence intervals or significance tests. These additions will allow readers to assess magnitude and reliability directly. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's central argument is a theoretical decomposition of rollout error into teacher-forcing mismatch, representation-class approximation, and provenance information gaps, formalized via induced states Z and provenance variables P. This decomposition follows directly from the definitions of partial observability and self-generated states without any reduction to fitted parameters, self-citations, or ansatzes that presuppose the target result. No equations equate a 'prediction' to its own inputs by construction, and the epistemic underidentification claim is presented as a logical consequence of deterministic latent dynamics failing to determine local targets on induced states. The derivation is self-contained against external benchmarks and does not rely on load-bearing self-citation chains.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Even with deterministic latent dynamics, one-step supervision need not identify the recursive predictor on induced states
- domain assumption Partial observability or state truncation creates provenance information gaps
invented entities (2)
-
induced states Z
no independent evidence
-
provenance variables P
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Deployment-Side Adaptiveness in Multi-Horizon Volatility Forecasting
Validation-based selection of inference-time rollout rules for multi-output volatility forecasters yields low-cost improvements over default MIMO deployment and recovers much of ensemble benefit at lower cost.
Reference graph
Works this paper leans on
-
[1]
Realities: The Cost of MSE-Optimal Forecasting Under Conditional Uncertainty , author=
Expectations vs. Realities: The Cost of MSE-Optimal Forecasting Under Conditional Uncertainty , author=. arXiv preprint arXiv:2606.04342 , year=
-
[2]
arXiv preprint arXiv:1810.09136 , year=
Do deep generative models know what they don't know? , author=. arXiv preprint arXiv:1810.09136 , year=
-
[3]
arXiv preprint arXiv:1511.05101 , year=
How (not) to train your generative model: Scheduled sampling, likelihood, adversary? , author=. arXiv preprint arXiv:1511.05101 , year=
-
[4]
Advances in neural information processing systems , volume=
Scheduled sampling for sequence prediction with recurrent neural networks , author=. Advances in neural information processing systems , volume=
-
[5]
Neural computation , volume=
A learning algorithm for continually running fully recurrent neural networks , author=. Neural computation , volume=. 1989 , publisher=
1989
-
[6]
Advances in neural information processing systems , volume=
Professor forcing: A new algorithm for training recurrent networks , author=. Advances in neural information processing systems , volume=
-
[7]
Proceedings of the fourteenth international conference on artificial intelligence and statistics , pages=
A reduction of imitation learning and structured prediction to no-regret online learning , author=. Proceedings of the fourteenth international conference on artificial intelligence and statistics , pages=. 2011 , organization=
2011
-
[8]
arXiv preprint arXiv:1511.06732 , year=
Sequence level training with recurrent neural networks , author=. arXiv preprint arXiv:1511.06732 , year=
-
[9]
Chaos, Solitons & Fractals , volume=
Robustness of LSTM neural networks for multi-step forecasting of chaotic time series , author=. Chaos, Solitons & Fractals , volume=. 2020 , publisher=
2020
-
[10]
Chaos, Solitons & Fractals , volume=
Forecasting of noisy chaotic systems with deep neural networks , author=. Chaos, Solitons & Fractals , volume=. 2021 , publisher=
2021
-
[11]
arXiv preprint arXiv:2210.08959 , year=
Flipped classroom: Effective teaching for time series forecasting , author=. arXiv preprint arXiv:2210.08959 , year=
-
[12]
Physica D: Nonlinear Phenomena , volume=
Learning on predictions: Fusing training and autoregressive inference for long-term spatiotemporal forecasts , author=. Physica D: Nonlinear Phenomena , volume=. 2024 , publisher=
2024
-
[13]
International Conference on Artificial Intelligence and Statistics , pages=
Robust probabilistic time series forecasting , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2022 , organization=
2022
-
[14]
Advances in neural information processing systems , volume=
Predictive representations of state , author=. Advances in neural information processing systems , volume=
-
[15]
arXiv preprint arXiv:1207.4167 , year=
Predictive state representations: A new theory for modeling dynamical systems , author=. arXiv preprint arXiv:1207.4167 , year=
-
[16]
Journal of Machine Learning Research , volume=
Approximate information state for approximate planning and reinforcement learning in partially observed systems , author=. Journal of Machine Learning Research , volume=
-
[17]
Machine learning , volume=
Aleatoric and epistemic uncertainty in machine learning: An introduction to concepts and methods , author=. Machine learning , volume=. 2021 , publisher=
2021
-
[18]
Advances in neural information processing systems , volume=
What uncertainties do we need in bayesian deep learning for computer vision? , author=. Advances in neural information processing systems , volume=
-
[19]
Data Mining and Knowledge Discovery , volume=
Stratify: unifying multi-step forecasting strategies , author=. Data Mining and Knowledge Discovery , volume=. 2025 , publisher=
2025
-
[20]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[21]
IEEE transactions on neural networks and learning systems , volume=
A bias and variance analysis for multistep-ahead time series forecasting , author=. IEEE transactions on neural networks and learning systems , volume=. 2015 , publisher=
2015
-
[22]
arXiv preprint arXiv:2511.11461 , year=
Epistemic Error Decomposition for Multi-step Time Series Forecasting: Rethinking Bias-Variance in Recursive and Direct Strategies , author=. arXiv preprint arXiv:2511.11461 , year=
-
[23]
Proceedings of the 3rd Workshop on Neural Generation and Translation , pages=
Generalization in generation: A closer look at exposure bias , author=. Proceedings of the 3rd Workshop on Neural Generation and Translation , pages=
-
[24]
arXiv preprint arXiv:2402.08373 , year=
Time-series classification for dynamic strategies in multi-step forecasting , author=. arXiv preprint arXiv:2402.08373 , year=
-
[25]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Improving multi-step prediction of learned time series models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.