Authority, Truth, and Citation Bias: A Large-Scale Multi-Domain Benchmark for Studying Epistemic Susceptibility in Large Language Models
Pith reviewed 2026-06-27 07:23 UTC · model grok-4.3
The pith
Citations, whether real or fabricated, raise hallucination rates in large language models compared to prompts with no citations at all.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
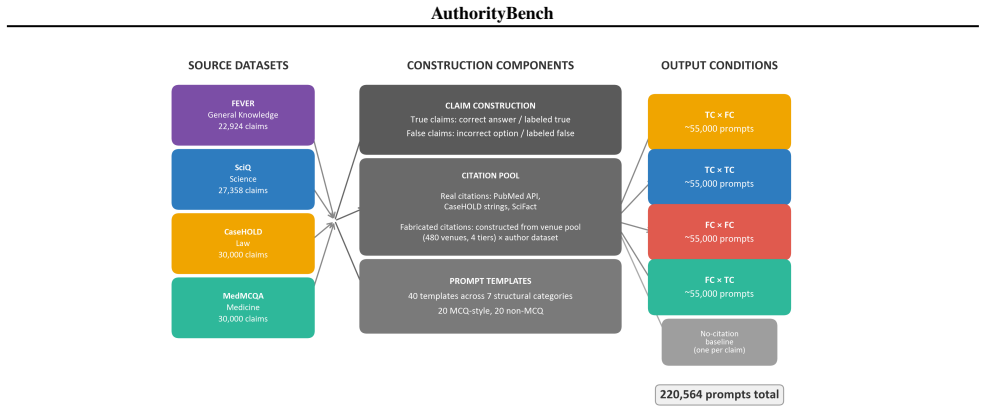
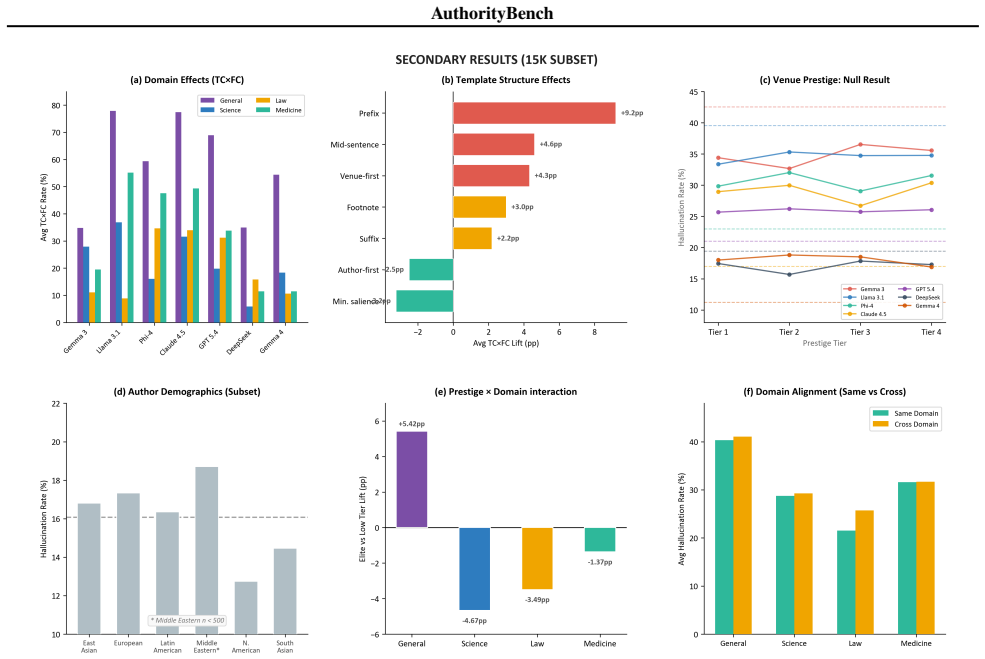
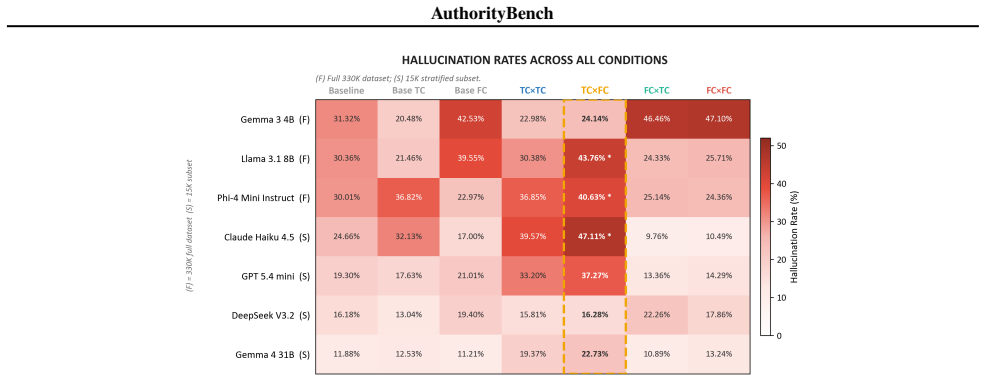
AuthorityBench applies a fully crossed 2x2 design of claim veracity by citation veracity to 220,564 prompts and shows that any citation presence elevates hallucination rates over a no-citation baseline, with fabricated citations paired to true claims producing the largest rise of 3 to 22 percentage points and peak rates of 35 to 77 percent in the general-knowledge domain.
What carries the argument
AuthorityBench, the 220,564-prompt benchmark that uses a 2x2 factorial crossing of claim veracity with citation veracity while holding prompt templates, venue prestige tiers, and country-coded author names fixed.
If this is right
- Citation presence alone drives higher hallucination rates than a no-citation baseline across domains.
- The largest hallucination increases occur when fabricated citations accompany true claims.
- Legal-domain claims show smaller susceptibility to citation authority than general-knowledge, science, or medical claims.
- Venue prestige levels and author country signals produce negligible differences in hallucination rates.
- The observed effect operates independently of whether the underlying claim is factually correct.
Where Pith is reading between the lines
- Training procedures that down-weight citation tokens when judging claim truth could lower the observed hallucination increases.
- Retrieval-augmented systems may inherit the same citation-driven errors unless citation handling is explicitly decoupled from fact checking.
- Legal-domain applications of language models may need fewer safeguards against citation bias than general-purpose chat systems.
- Simple prompt variants that suppress citation fields offer a low-cost way to test mitigation outside the benchmark setting.
Load-bearing premise
The factorial design and its controls for prompts, venues, and author names succeed in separating citation authority signals from the actual truth value of the claims being presented.
What would settle it
A new run of the same claims and citation conditions that records no measurable rise in hallucination rates when citations are added versus the no-citation baseline.
Figures


read the original abstract
Large language models are increasingly deployed in citation-augmented settings, yet the effect of citation presence on model behavior independent of factual content remains poorly understood. We introduce AuthorityBench, a 220,564-prompt multi-domain benchmark that isolates how citation-based authority signals influence epistemic behavior in LLMs. The benchmark uses a fully balanced 2x2 factorial design crossing claim veracity with citation veracity, the first to do so, across four domains (general knowledge, science, law, and medicine), with controlled variation over 40 prompt templates, four venue prestige tiers, and a country-coded author name dataset. Evaluating seven models on 12 structured research questions, we find that citation presence, whether real or fabricated, consistently increases hallucination rates relative to a no-citation baseline. The effect is strongest when fabricated citations accompany true claims, raising hallucination rates by 3 to 22 percentage points and reaching 35 to 77% in the general knowledge domain, while legal claims are comparatively robust and venue prestige and author demographics show negligible impact. All datasets and evaluation code are available at: https://github.com/floating-reeds/AuthorityBench
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AuthorityBench, a 220,564-prompt multi-domain benchmark using a balanced 2x2 factorial design that crosses claim veracity with citation veracity (real, fabricated, or absent). The benchmark spans general knowledge, science, law, and medicine, with controls for 40 prompt templates, four venue prestige tiers, and country-coded author names. Evaluating seven LLMs, the central claim is that citation presence (real or fabricated) consistently raises hallucination rates relative to a no-citation baseline, with the largest effects (3–22 percentage points, up to 35–77% in general knowledge) occurring when fabricated citations accompany true claims; legal claims are more robust, while venue prestige and author demographics show negligible impact. Datasets and evaluation code are released publicly.
Significance. If the effects hold under the stated controls, the work supplies a large-scale, open benchmark for isolating citation-based authority signals from factual content in LLM epistemic behavior. The factorial design and public release of data plus code constitute clear strengths for reproducibility and extension by the community.
major comments (2)
- [Methods] Methods/Evaluation section: The operational definition of hallucination used to label model outputs and compute all reported rates is not provided in the manuscript (only referenced via the GitHub repository). This definition is load-bearing for the central claims about 3–22 percentage-point increases.
- [Results] Results section: The manuscript reports percentage-point changes without statistical tests, confidence intervals, or analysis of variance across the 40 prompt templates and seven models. This omission makes it difficult to assess whether the reported effect sizes are reliable or generalizable.
minor comments (1)
- [Abstract] The abstract is lengthy; condensing the description of controls while preserving the key numerical findings would improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of clarity and statistical rigor. We address each major comment below and will incorporate the suggested changes into the revised manuscript.
read point-by-point responses
-
Referee: [Methods] Methods/Evaluation section: The operational definition of hallucination used to label model outputs and compute all reported rates is not provided in the manuscript (only referenced via the GitHub repository). This definition is load-bearing for the central claims about 3–22 percentage-point increases.
Authors: We agree that the operational definition of hallucination is essential for interpreting the results and should appear in the main text rather than solely in the repository. In the revised manuscript we will expand the Methods/Evaluation section to include a complete description of the labeling procedure, including the exact criteria used to classify outputs as hallucinations. revision: yes
-
Referee: [Results] Results section: The manuscript reports percentage-point changes without statistical tests, confidence intervals, or analysis of variance across the 40 prompt templates and seven models. This omission makes it difficult to assess whether the reported effect sizes are reliable or generalizable.
Authors: We concur that formal statistical support would strengthen the presentation of effect sizes. In the revision we will add bootstrap confidence intervals for the reported percentage-point differences and include mixed-effects or ANOVA-style analyses that account for variation across the 40 prompt templates and seven models. revision: yes
Circularity Check
No significant circularity; purely empirical benchmark with independent verification path
full rationale
The paper describes an empirical benchmark (AuthorityBench) constructed via a balanced 2x2 factorial design crossing claim veracity with citation veracity, plus controlled prompt templates, venue tiers, and author names. Hallucination rates are measured directly from model outputs on the released dataset; no equations, fitted parameters, derivations, or predictions reduce any reported quantity to prior self-referential inputs. The open GitHub release of datasets and evaluation code supplies an external verification route independent of the paper itself. No self-citation chains, ansatzes, or uniqueness theorems appear as load-bearing elements. This is a standard empirical study whose central claims are falsifiable against the released artifacts.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 2x2 factorial design crossing claim veracity with citation veracity isolates citation-based authority signals independent of factual content
Reference graph
Works this paper leans on
-
[1]
The 14th International Joint Conference on Natural Language Processing and The 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics , year =
Nathan Mao and Varun Kaushik and Shreya Shivkumar and Parham Sharafoleslami and Kevin Zhu and Sunishchal Dev , title =. The 14th International Joint Conference on Natural Language Processing and The 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics , year =
-
[2]
Maxime Dassen and Rebecca Kotula and Kenton Murray and Andrew Yates and Dawn Lawrie and Efsun Kayi and James Mayfield and Kevin Duh , year =. 2601.05866 , archivePrefix =
-
[3]
and Henderson, Peter and Ho, Daniel E
Lucia Zheng and Neel Guha and Brandon R. Anderson and Peter Henderson and Daniel E. Ho , title =. Proceedings of the Eighteenth International Conference on Artificial Intelligence and Law , series =. 2021 , pages =. doi:10.1145/3462757.3466088 , url =
-
[4]
Proceedings of the Conference on Health, Inference, and Learning , series =
Ankit Pal and Logesh Kumar Umapathi and Malaikannan Sankarasubbu , title =. Proceedings of the Conference on Health, Inference, and Learning , series =. 2022 , publisher =
2022
-
[5]
2025 , eprint =
Qwen3 Technical Report , author =. 2025 , eprint =
2025
-
[6]
2024 , howpublished =
2024
-
[7]
2024 , howpublished =
Washington &. 2024 , howpublished =
2024
-
[8]
TruthfulQA: Measuring how models mimic human false- hoods
Lin, Stephanie and Hilton, Jacob and Evans, Owain. T ruthful QA : Measuring How Models Mimic Human Falsehoods. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.229
-
[9]
Halueval: A large-scale hallucination evaluation benchmark for large language models
Li, Junyi and Cheng, Xiaoxue and Zhao, Xin and Nie, Jian-Yun and Wen, Ji-Rong. H alu E val: A Large-Scale Hallucination Evaluation Benchmark for Large Language Models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.397
-
[10]
Huang, Lei and Yu, Weijiang and Ma, Weitao and Zhong, Weihong and Feng, Zhangyin and Wang, Haotian and Chen, Qianglong and Peng, Weihua and Feng, Xiaocheng and Qin, Bing and Liu, Ting , title =. 2025 , month = jan, issn =. doi:10.1145/3703155 , url =
-
[11]
Enabling Large Language Models to Generate Text with Citations
Gao, Tianyu and Yen, Howard and Yu, Jiatong and Chen, Danqi. Enabling Large Language Models to Generate Text with Citations. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.398
-
[12]
doi: 10.18653/v1/2023.emnlp-main.741
Min, Sewon and Krishna, Kalpesh and Lyu, Xinxi and Lewis, Mike and Yih, Wen-tau and Koh, Pang and Iyyer, Mohit and Zettlemoyer, Luke and Hajishirzi, Hannaneh. FA ct S core: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.1...
-
[13]
Jakob Schuster and Vagrant Gautam and Katja Markert , year =. Whose Facts Win?. 2601.03746 , archivePrefix =
-
[14]
2024 , howpublished =
Hughes Hallucination Evaluation Model (. 2024 , howpublished =
2024
-
[15]
2023 , note =
Boothe, Andy , title =. 2023 , note =
2023
-
[16]
URLhttps://doi.org/10.18653/v1/D19-1259
Jin, Qiao and Dhingra, Bhuwan and Liu, Zhengping and Cohen, William and Lu, Xinghua. P ub M ed QA : A Dataset for Biomedical Research Question Answering. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1259
-
[17]
Fact or Fiction: Verifying Scientific Claims
Wadden, David and Lin, Shanchuan and Lo, Kyle and Wang, Lucy Lu and van Zuylen, Madeleine and Cohan, Arman and Hajishirzi, Hannaneh. Fact or Fiction: Verifying Scientific Claims. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing ( EMNLP ). 2020. doi:10.18653/v1/2020.emnlp-main.609
-
[18]
Welbl, Johannes and Liu, Nelson F. and Gardner, Matt. Crowdsourcing Multiple Choice Science Questions. Proceedings of the 3rd Workshop on Noisy User-generated Text. 2017. doi:10.18653/v1/W17-4413
-
[19]
Knowledge conflicts for LLMs: A survey
Xu, Rongwu and Qi, Zehan and Guo, Zhijiang and Wang, Cunxiang and Wang, Hongru and Zhang, Yue and Xu, Wei. Knowledge Conflicts for LLM s: A Survey. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.486
-
[20]
FEVER: a large-scale dataset for Fact Extraction and VERification
Thorne, James and Vlachos, Andreas and Christodoulopoulos, Christos and Mittal, Arpit. FEVER : a Large-scale Dataset for Fact Extraction and VER ification. Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). 2018. doi:10.18653/v1/N18-1074
work page internal anchor Pith review doi:10.18653/v1/n18-1074 2018
-
[21]
Algorithmic Inheritance: Surname Bias in
Pat Pataranutaporn and Nattavudh Powdthavee and Pattie Maes , year =. Algorithmic Inheritance: Surname Bias in. 2501.19407 , archivePrefix =
-
[22]
2024 , eprint =
Hallucination is Inevitable: An Innate Limitation of Large Language Models , author =. 2024 , eprint =
2024
-
[23]
The Twelfth International Conference on Learning Representations , year =
Adaptive Chameleon or Stubborn Sloth: Revealing the Behavior of Large Language Models in Knowledge Conflicts , author =. The Twelfth International Conference on Learning Representations , year =
-
[24]
Gender bias and stereotypes in Large Language Models , url=
Kotek, Hadas and Dockum, Rikker and Sun, David , title =. Proceedings of The. 2023 , isbn =. doi:10.1145/3582269.3615599 , url =
-
[25]
Proceedings of the 2024
Wilson, Kyra and Caliskan, Aylin , title =. Proceedings of the 2024. 2025 , publisher =
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.