Understanding Truncated Positional Encodings for Graph Neural Networks
Pith reviewed 2026-06-27 07:07 UTC · model grok-4.3
The pith
Truncating positional encodings for graph neural networks makes different families unequal in expressive power.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under uniform truncation to the first k components, spectral positional encodings (Laplacian eigenspaces, effective resistance) are no longer stronger than the 1-WL test, while walk-based encodings (adjacency powers) retain higher power, breaking the equivalence that exists for complete versions. Different truncated spectral families, including k-harmonic distances, also differ from one another in expressive power.
What carries the argument
Uniform truncation of positional encoding vectors to the first k entries, compared by how much they increase a GNN's ability to distinguish non-isomorphic graphs.
If this is right
- Truncated spectral positional encodings match the distinction power of the 1-WL test.
- Walk-based truncated encodings remain strictly stronger than the 1-WL test.
- Even within the spectral family, different truncation choices such as k-harmonic distances produce distinct expressive powers.
- Combining truncated encodings from multiple families improves empirical performance over any single family.
Where Pith is reading between the lines
- The choice of which family to truncate may matter more than the choice of k itself.
- Theoretical guarantees written for complete encodings cannot be assumed to carry over to the versions actually used in deployed models.
- Designers may need family-specific rules for choosing k rather than a single shared value.
Load-bearing premise
The analysis assumes the same truncation parameter k applies to every family and that the GNN processes the resulting vectors in comparable ways when distinguishing graphs.
What would settle it
Two graphs that the 1-WL test cannot separate, yet a GNN equipped only with the first k Laplacian eigenvectors as positional encodings can separate.
Figures


read the original abstract
Positional encodings (PEs) enhance the power of graph neural networks (GNNs), both theoretically and empirically. Two of the most popular families of PEs - spectral (e.g., Laplacian eigenspaces, effective resistance) and walk-based (polynomials of the adjacency matrix) - are theoretically equivalent in expressive power, with expressivity between the 1-WL and 3-WL tests. However, this equivalence assumes the GNN uses the "complete" version of these PEs, which requires $O(n^3)$ time and space complexity. Instead, practitioners commonly use truncated variants of these encodings, such as the first $k$ eigenspaces or powers of the adjacency matrix. However, the theoretical properties of these truncated PEs are unknown. In this work, we initiate the study of these truncated PEs. Theoretically, we show that, under truncation, several families of PEs are fundamentally different in expressive power. As a corollary, we show that truncated spectral PEs are no longer stronger than the 1-WL test. We also study a family of spectral PEs, the $k$-harmonic distances, to highlight the differences in expressive power of even closely related truncated PEs. Finally, we experimentally show that a mix of truncated PEs is preferable to any single family on real-world datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that complete spectral and walk-based positional encodings (PEs) are equivalent in expressive power (between 1-WL and 3-WL), but their truncated versions (first k eigenspaces vs. first k powers of A) are not; specifically, truncated spectral PEs drop to at most 1-WL power. It further distinguishes even closely related spectral families such as k-harmonic distances and shows empirically that mixing truncated PEs outperforms any single family on real-world datasets.
Significance. If the distinctions survive scrutiny, the work supplies the first systematic comparison of truncation effects on PE expressivity and supplies a concrete reason why practitioners should not treat all truncated PEs as interchangeable. The experimental finding that mixtures help is practically useful; the theoretical separation between families under truncation is a clear advance over the existing complete-PE equivalence results.
major comments (3)
- [§3] §3 (theoretical analysis of truncated spectral PEs): the reduction to ≤1-WL relies on the claim that the k-truncated Laplacian eigenvectors supply no more distinguishing power than degree sequences. The argument appears to treat the truncation parameter k as directly comparable across families, yet the skeptic correctly notes that k eigenvectors (each a global vector) and k walk powers (local polynomials) do not necessarily deliver equivalent information budgets to a downstream message-passing GNN; a counter-example or explicit embedding-dimension normalization is needed to make the expressivity ordering load-bearing.
- [§4] §4 (k-harmonic distances): the separation between truncated Laplacian eigenspaces and k-harmonic distances is presented as evidence that even closely related spectral families diverge under truncation. The proof sketch should explicitly state the GNN architecture and the precise WL test used after the PE is concatenated; without that, it is unclear whether the observed difference is intrinsic or an artifact of how the PE vectors are fed into the same update function.
- [Experiments] Experimental section (real-world datasets): the claim that 'a mix of truncated PEs is preferable' is supported only by aggregate accuracy numbers. The paper should report per-dataset ablation tables that isolate the contribution of each family at the same k and the same total embedding dimension; otherwise the mixture benefit could be explained by increased feature dimensionality rather than complementary expressivity.
minor comments (2)
- [§2] Notation: the manuscript alternates between 'truncated to k' and 'first k' without a single definition; a short paragraph in §2 clarifying the exact matrix or vector that is retained for each family would remove ambiguity.
- [Figures] Figure captions: several plots compare different PE families but do not state the fixed k or the GNN depth used; adding these parameters to every caption would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to strengthen the theoretical and experimental sections.
read point-by-point responses
-
Referee: [§3] §3 (theoretical analysis of truncated spectral PEs): the reduction to ≤1-WL relies on the claim that the k-truncated Laplacian eigenvectors supply no more distinguishing power than degree sequences. The argument appears to treat the truncation parameter k as directly comparable across families, yet the skeptic correctly notes that k eigenvectors (each a global vector) and k walk powers (local polynomials) do not necessarily deliver equivalent information budgets to a downstream message-passing GNN; a counter-example or explicit embedding-dimension normalization is needed to make the expressivity ordering load-bearing.
Authors: We agree that direct comparison of truncation parameter k requires normalization. In the revision we will fix the total PE embedding dimension to the same value d across all families and add a concrete counter-example showing that, even at equal dimension, truncated spectral PEs fail to distinguish certain non-isomorphic graphs that truncated walk-based PEs can distinguish. This will make the ≤1-WL claim rigorous. revision: yes
-
Referee: [§4] §4 (k-harmonic distances): the separation between truncated Laplacian eigenspaces and k-harmonic distances is presented as evidence that even closely related spectral families diverge under truncation. The proof sketch should explicitly state the GNN architecture and the precise WL test used after the PE is concatenated; without that, it is unclear whether the observed difference is intrinsic or an artifact of how the PE vectors are fed into the same update function.
Authors: We will revise the proof sketch in §4 to explicitly state the GNN architecture (standard MPNN with sum aggregation and MLP updates) and the WL test (1-WL) used after PE concatenation. This will confirm the separation is intrinsic to the truncated families. revision: yes
-
Referee: [Experiments] Experimental section (real-world datasets): the claim that 'a mix of truncated PEs is preferable' is supported only by aggregate accuracy numbers. The paper should report per-dataset ablation tables that isolate the contribution of each family at the same k and the same total embedding dimension; otherwise the mixture benefit could be explained by increased feature dimensionality rather than complementary expressivity.
Authors: We agree that aggregate numbers are insufficient. The revision will add per-dataset ablation tables comparing each family and their mixtures at identical k and identical total embedding dimension, isolating the contribution of complementary expressivity. revision: yes
Circularity Check
No circularity; theoretical distinctions derived independently
full rationale
The paper's core claims rest on new theoretical analysis of truncated positional encodings under the WL hierarchy. The abstract and provided context show no self-definitional reductions, no fitted parameters renamed as predictions, and no load-bearing self-citations that collapse the argument to prior unverified work by the same authors. The distinction between spectral and walk-based truncations, and the corollary that truncated spectral PEs fall to 1-WL, are presented as fresh results rather than rearrangements of inputs. The uniform-k assumption is an explicit modeling choice whose consequences are analyzed, not smuggled in via definition or citation chain. This is a standard case of a self-contained theoretical contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard definitions and properties of the Weisfeiler-Lehman hierarchy and spectral graph theory hold.
Reference graph
Works this paper leans on
-
[1]
Black, M., Lin, L., Wong, W.-K., and Nayyeri, A
URL https://openreview.net/forum? id=i80OPhOCVH2. Black, M., Lin, L., Wong, W.-K., and Nayyeri, A. Bi- harmonic distance of graphs and its higher-order vari- ants: Theoretical properties with applications to cen- trality and clustering. InForty-first International Con- ference on Machine Learning, 2024a. URL https: //openreview.net/forum?id=3pxMIjB9QK. Bl...
-
[2]
Jambulapati, A
URL https://openreview.net/forum? id=xAqcJ9XoTf. Jambulapati, A. and Sidford, A. Ultrasparse ultrasparsifiers and faster laplacian system solvers.ACM Transactions on Algorithms, 21(3):1–49, 2025. Jameson, G. J. O. Counting zeros of generalised poly- nomials: Descartes’ rule of signs and laguerre’s ex- tensions.The Mathematical Gazette, 90:223 – 234,
2025
-
[3]
Johnson and Joram Lindenstrauss
URL https://api.semanticscholar. org/CorpusID:17184843. Johnson, W. and Lindenstrauss, J. Extensions of lipschitz maps into a hilbert space.Contemporary Mathematics, 26:189–206, 01 1984. doi: 10.1090/conm/026/737400. Klein, D. J. and Randi´c, M. Resistance distance.Journal of Mathematical Chemistry, 12(1):81–95, Dec 1993. ISSN 1572-8897. doi: 10.1007/BF01...
-
[4]
Lim, D., Robinson, J
SIAM, 2018. Lim, D., Robinson, J. D., Zhao, L., Smidt, T., Sra, S., Maron, H., and Jegelka, S. Sign and basis invariant networks for spectral graph representation learning. InThe Eleventh International Conference on Learning Representations,
2018
-
[5]
Ma, L., Lin, C., Lim, D., Romero-Soriano, A., Dokania, P
URL https://openreview.net/forum? id=Q-UHqMorzil. Ma, L., Lin, C., Lim, D., Romero-Soriano, A., Dokania, P. K., Coates, M., Torr, P., and Lim, S.-N. Graph in- ductive biases in transformers without message passing. In Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., and Scarlett, J. (eds.),Proceedings of the 40th International Conference on...
-
[6]
Rampasek, L., Galkin, M., Dwivedi, V
URL https://openreview.net/forum? id=S1ldO2EFPr. Rampasek, L., Galkin, M., Dwivedi, V . P., Luu, A. T., Wolf, G., and Beaini, D. Recipe for a general, pow- erful, scalable graph transformer. In Oh, A. H., Agarwal, A., Belgrave, D., and Cho, K. (eds.),Advances in Neural Information Processing Systems, 2022. URL https: //openreview.net/forum?id=lMMaNf6oxKM....
Pith/arXiv arXiv 2022
-
[7]
Zhou, J., Zhou, C., Wang, X., Li, P., and Zhang, M
URL https://openreview.net/forum? id=kmugaw9Kfq. Zhou, J., Zhou, C., Wang, X., Li, P., and Zhang, M. Towards stable, globally expressive graph representations with laplacian eigenvectors.arXiv preprint arXiv:2410.09737, 2024. Zopf, M. 1-wl expressiveness is (almost) all you need, 2022. URLhttps://arxiv.org/abs/2202.10156. 11 Understanding Truncated Positi...
Pith/arXiv arXiv 2024
-
[8]
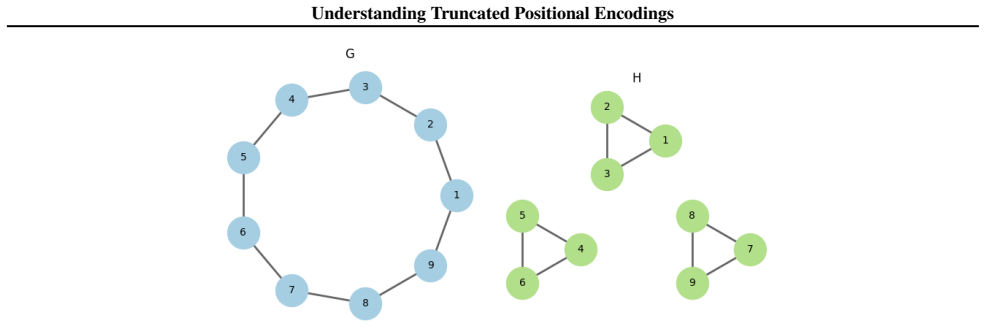
We construct a pair of squared Euclidean distances matrices and prove they are indistinguishable by the WL test
-
[9]
We prove that these distance matrices are the effective resistance matrices of a pair of weighted graphs
-
[10]
We are able to prove Item 1 analytically
We prove that these two graphs are indistinguishable by the WL test on their weighted adjacency matrices. We are able to prove Item 1 analytically. For Items 2 and 3, we use symbolic software to perform a computer-aided proof. These steps involving taking a matrix pseudoinverse, which can be hard to reason about mathematically but can by checked with a si...
2017
-
[11]
and would prove that resistance-WL is strong than shortest-path-distance-WL. Conjecture B.2.There exist a pair of unweighted graphs G and H such that G and H are indistinguishable by the resistance WL test, but they are distinguishable by the shortest-path-distance WL test. C. Truncated Walk Encodings Lemma C.1((Lehman et al., 2017, Corollary 10.3.3)).Let...
2017
-
[12]
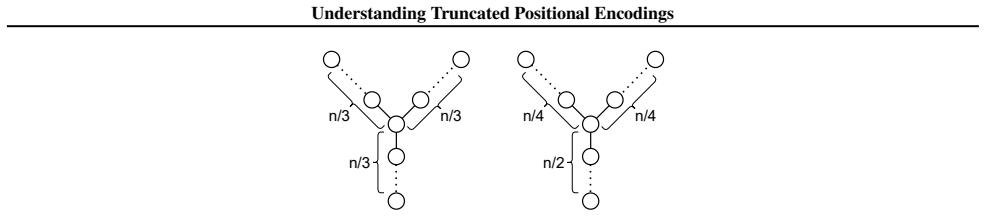
Nodes that are distancer < kfrom a leaf of a tree The k-hop neighborhoods of these nodes are the node connected to a path of lengthr(the path connecting the node to the leaf) and a path of lengthk
-
[13]
Nodes that are distancer < kfrom the root The k-hop neighborhoods of these nodes are the node connected to a path of lengthkand a path of lengthrconnected to two paths of lengthk−r
-
[14]
Nodes that are distance> kfrom both a leaf and the root The k-hop neighborhood of these nodes are the node con- nected to two paths of lengthk. As k <⌊ n 8 ⌋, there are no nodes of that are both distance < k to a leaf and a root, as the distance between any leaf and a root in either tree is n 4 For any 0< r < k , in both graphs, there are three nodes of d...
arXiv 2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.