Decision-Driven Geosteering Under Uncertainty: A Unified Framework for Sequential Decision Optimization
Pith reviewed 2026-06-27 03:10 UTC · model grok-4.3
The pith
A framework integrates particle filtering with reinforcement learning for uncertainty-aware geosteering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
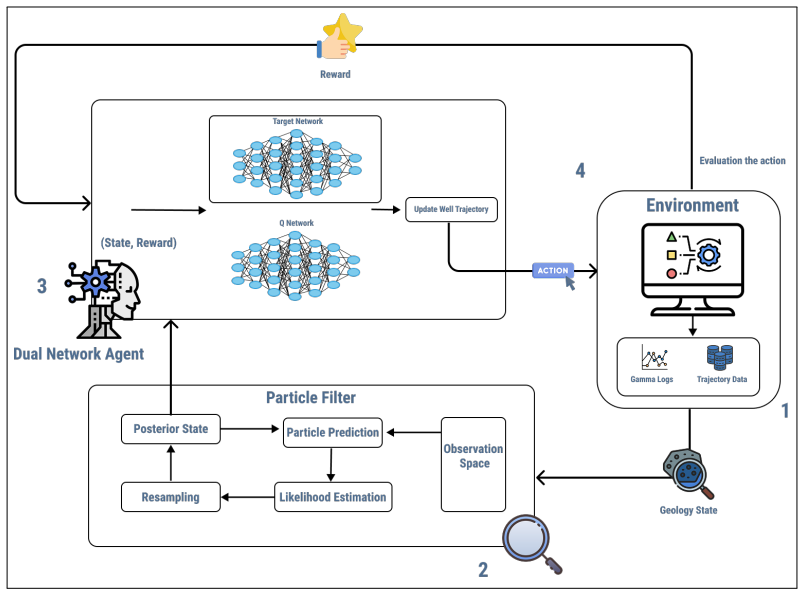
This work presents an uncertainty-aware geosteering framework that tightly integrates particle filtering for probabilistic subsurface interpretation with value-based reinforcement learning for sequential decision-making. Geological uncertainty ahead of the drill bit is represented explicitly through a particle filter, enabling belief-informed control rather than deterministic trajectory correction. The framework couples PF belief updates with belief-informed decision policies and evaluates three decision-making options under identical uncertainty representations: an interpretable Approximate Dynamic Programming scheme, a Deep Q-learning baseline, and a Dual Deep Reinforcement Learning archit
What carries the argument
Particle filter belief updates coupled with belief-informed decision policies from reinforcement learning methods.
If this is right
- Alternative decision policies can be evaluated under identical geological realizations, operational limits, and reward definitions.
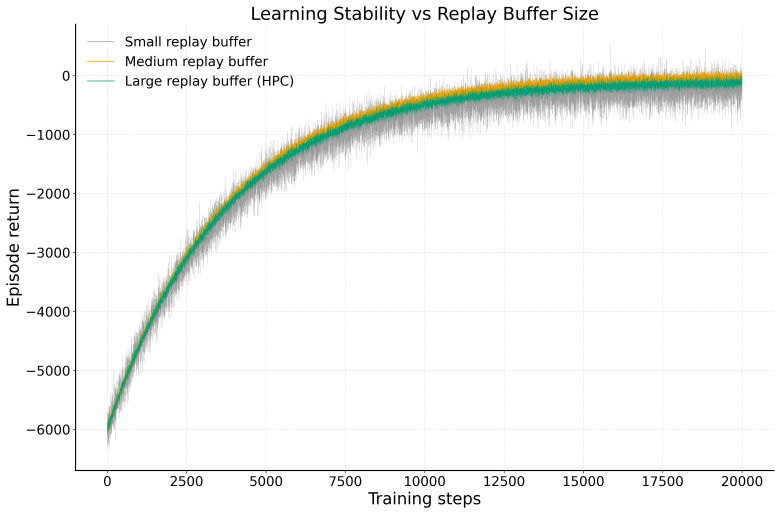
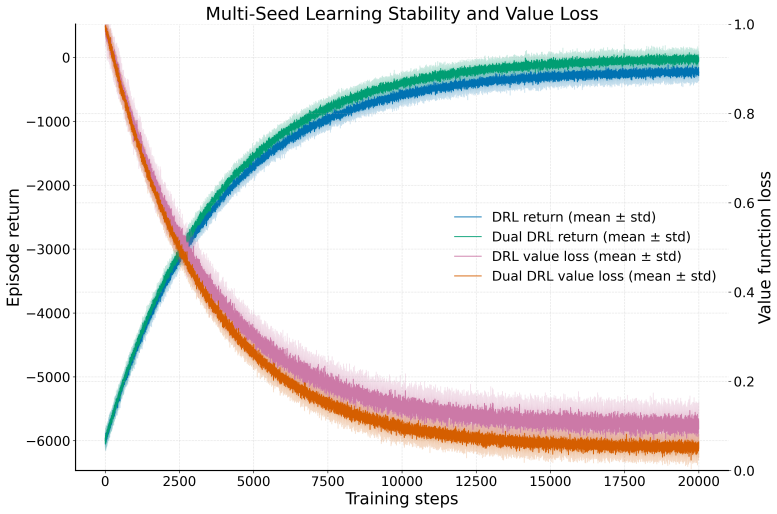
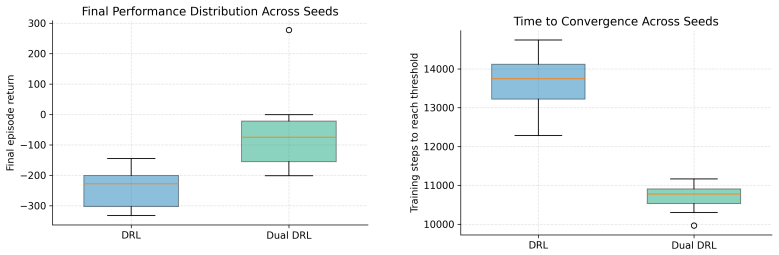
- Policy behavior can be assessed using stability-oriented metrics that quantify steering smoothness as uncertainty evolves.
- The framework supports validation in an industrial geosteering simulator with realistic measurement noise and drilling constraints.
- Controlled comparisons focus on how policies behave throughout the drilling process rather than only final trajectory outcomes.
Where Pith is reading between the lines
- The approach may generalize to other sequential control problems where partial observations update beliefs over time, such as robotic exploration or resource extraction planning.
- Stability metrics could highlight cases where smooth policies reduce operational risks even if final placement is similar.
- Using dueling architectures and target networks in the Dual DRL suggests the method could handle higher-dimensional state spaces in more complex geological settings.
Load-bearing premise
Geological uncertainty ahead of the drill bit can be represented explicitly through a particle filter that enables belief-informed control.
What would settle it
A direct comparison in the industrial simulator between the proposed belief-informed policies and a deterministic trajectory correction method, measuring differences in cumulative reward or final well placement under the same noise conditions, would test the central claim.
Figures
read the original abstract
Geosteering requires navigating a well trajectory through an unknown geological configuration, while sequentially updating decisions based on indirect measurements acquired during drilling. This work presents an uncertainty-aware geosteering framework that tightly integrates particle filtering for probabilistic subsurface interpretation with value-based reinforcement learning for sequential decision-making. Geological uncertainty ahead of the drill bit is represented explicitly through a particle filter (PF), enabling belief-informed control rather than deterministic trajectory correction. The framework couples PF belief updates with belief-informed decision policies and evaluates three decision-making options that operate under identical uncertainty representations: an interpretable Approximate Dynamic Programming (ADP) scheme, a Deep Q-learning baseline, and a Dual Deep Reinforcement Learning (Dual DRL) architecture trained with a target Q-network scheme for stability, using a dueling (value/advantage) decomposition for Q-value parameterization. Beyond final placement performance, we assess policy behavior using stability-oriented metrics that quantify steering smoothness over time, providing additional operational insight into how decision policies respond as uncertainty evolves. The framework is integrated with an API for validation within an industrial geosteering simulator under realistic measurement noise and drilling constraints. Using identical geological realizations, operational limits, and reward definitions across methods, the experiments provide a controlled and high-fidelity evaluation of how alternative decision policies behave throughout the drilling process, rather than evaluating performance solely from the final well trajectory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an uncertainty-aware geosteering framework that couples particle filtering for explicit probabilistic representation of subsurface geology with value-based reinforcement learning. It performs a controlled comparison of three belief-informed policies (ADP, DQN, and Dual DRL with target networks and dueling decomposition) inside an industrial simulator, using identical geological realizations, measurement noise, drilling constraints, and reward definitions, while evaluating both final well placement and steering smoothness metrics.
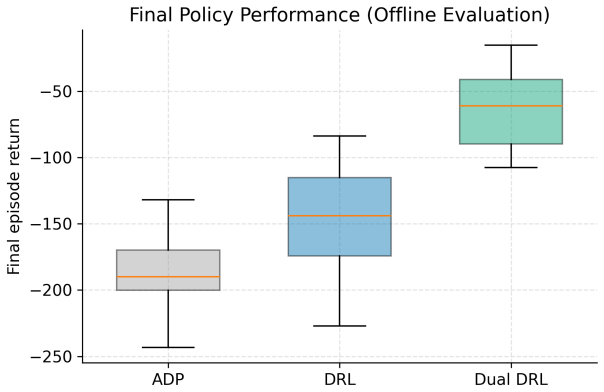
Significance. If the reported results hold, the work supplies a reproducible, high-fidelity protocol for comparing decision policies under shared uncertainty representations, which addresses a practical need in drilling operations. The explicit use of particle-filter beliefs rather than deterministic corrections, the stability-oriented metrics, and the fixed experimental conditions across methods are clear strengths. The integration with an industrial API further supports applicability.
minor comments (3)
- [§3.2] §3.2 (or equivalent methods section): the precise mapping from the particle-filter belief (set of particles) to the state vector supplied to the Q-networks is described at a high level; an explicit equation or pseudocode example would clarify how the belief is encoded without loss of information.
- [Table 2] Table 2 (or results table): the reported smoothness metric values lack units or normalization details; adding these would make the operational interpretation of the stability-oriented metrics unambiguous.
- The abstract states that the framework 'tightly integrates' PF and RL, yet the manuscript does not discuss sensitivity of the policies to the number of particles; a brief ablation on particle count would strengthen the robustness claim.
Simulated Author's Rebuttal
We thank the referee for the constructive summary and positive evaluation of the manuscript's contributions, including the controlled comparison protocol, explicit particle-filter uncertainty representation, and integration with the industrial simulator. The recommendation for minor revision is noted. No specific major comments were raised in the report.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents an application framework integrating particle filtering (for explicit uncertainty representation via belief states) with value-based RL policies (ADP, DQN, Dual DRL) for sequential geosteering decisions. The central claim is a controlled empirical comparison of these policies under identical particle-filter beliefs, simulator realizations, noise, constraints, and rewards. No load-bearing step reduces by construction to a fitted parameter, self-definition, or self-citation chain; the evaluation protocol is externally falsifiable via the industrial simulator and does not rely on internal uniqueness theorems or ansatzes from prior author work. This is a standard integration/comparison study with independent content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
K. Kullawan, R. Bratvold, J. Bickel, A decision analytic approach to geosteering operations, SPE Drilling & Completion 29 (03 2014). doi:10.2118/167433-PA
-
[2]
Kullawan, R
K. Kullawan, R. Bratvold, J. Bickel, Sequential geosteering decisions for optimization of real-time well placement, Journal of Petroleum Science and Engineering 165 (2018) 90–104
2018
-
[3]
S. Alyaev, E. Suter, R. B. Bratvold, A. Hong, X. Luo, K. Fos- sum, A decision support system for multi-target geosteering, Jour- nal of Petroleum Science and Engineering 183 (2019) 106381. doi:10.1016/j.petrol.2019.106381. URLhttp://dx.doi.org/10.1016/j.petrol.2019.106381
-
[4]
The Ensemble Kalman Filter: theoretical formulation and practical implementation,
G. Evensen, The ensemble kalman filter: theoretical formulation and practical implementation, Ocean Dynamics 53 (4) (2003) 343–367. doi:10.1007/s10236-003-0036-9. URLhttps://doi.org/10.1007/s10236-003-0036-9
-
[5]
Alyaev, K
S. Alyaev, K. Fossum, H. Djecta, J. Tveranger, A. Elsheikh, Distinguish workflow: a new paradigm of dynamic well placement using generative machine learning, in: ECMOR 2024, Vol. 2024, European Association of Geoscientists & Engineers, 2024, pp. 1–16
2024
-
[6]
R. S. Sutton, A. G. Barto, Reinforcement Learning: An Introduction, 2nd Edition, The MIT Press, 2018. URLhttp://incompleteideas.net/book/the-book-2nd.html
2018
-
[7]
doi:https://doi.org/10.1016/j.geoen.2025.214304
Optimal sequential decision-making in geosteer- ing: A reinforcement learning approach (2026). doi:https://doi.org/10.1016/j.geoen.2025.214304
-
[8]
V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wier- stra, M. A. Riedmiller, Playing atari with deep reinforcement learning, CoRR abs/1312.5602 (2013). arXiv:1312.5602. URLhttp://arxiv.org/abs/1312.5602
Pith/arXiv arXiv 2013
-
[9]
D. R. A. Veettil, K. Clark, Bayesian geosteering using sequen- tial monte carlo methods, Petrophysics 61 (1) (2020) 99–111. doi:10.30632/PJV61N1-2020a4. 27
-
[10]
R. B. Muhammad, A. Srivastava, S. Alyaev, R. B. Bratvold, D. M. Tartakovsky, High-precision geosteering via reinforcement learning and particle filters (2024). arXiv:2402.06377. URLhttps://arxiv.org/abs/2402.06377
arXiv 2024
-
[11]
R. B. Muhammad, Y. Cheraghi, S. Alyaev, A. Srivastava, R. B. Bratvold, Geosteering robot powered by multiple prob- abilistic interpretation and artificial intelligence: Bench- marking against human experts, SPE Journal (2025) 1– 15arXiv:https://onepetro.org/SJ/article-pdf/doi/10.2118/218444- PA/4407193/spe-218444-pa.pdf, doi:10.2118/218444-PA. URLhttps://...
-
[12]
H. E. Djecta, S. Alyaev, K. Fossum, R. B. Bratvold, R. B. Muhammad, A. Srivastava, Uncertainty-aware well placement: Simulator-verified dual-network reinforcement learning approach meets particle filters, in: M. Paszynski, A. S. Barnard, Y. J. Zhang(Eds.), Computational Science – ICCS 2025 Workshops, Springer Nature Switzerland, Cham, 2025, pp. 188–202
2025
-
[13]
Z.Wang, T.Schaul, M.Hessel, H.vanHasselt, M.Lanctot, N.deFreitas, Dueling network architectures for deep reinforcement learning (2016). arXiv:1511.06581. URLhttps://arxiv.org/abs/1511.06581
Pith/arXiv arXiv 2016
-
[14]
Shelton, Balancing multiple sources of reward in reinforcement learn- ing, in: T
C. Shelton, Balancing multiple sources of reward in reinforcement learn- ing, in: T. Leen, T. Dietterich, V. Tresp (Eds.), Advances in Neural Information Processing Systems, Vol. 13, MIT Press, 2000, p. 12
2000
-
[15]
P. M. Djurić, M. F. Bugallo, Particle filtering for high-dimensional sys- tems, in: 2013 5th IEEE International Workshop on Computational Advances in Multi-Sensor Adaptive Processing (CAMSAP), 2013, pp. 352–355. doi:10.1109/CAMSAP.2013.6714080
-
[16]
Chen, A tutorial on kernel density estimation and recent advances (2017)
Y.-C. Chen, A tutorial on kernel density estimation and recent advances (2017). arXiv:1704.03924. URLhttps://arxiv.org/abs/1704.03924
Pith/arXiv arXiv 2017
-
[17]
M. Arslan, I. Kucukdemiral, M. Farrag, Development of a nonlinear pre- dictive controller for mitigation of motion sickness in autonomous vehi- 28 cles through multi-objective control of lateral and roll dynamics, Results in Engineering 25 (Mar. 2025). doi:10.1016/j.rineng.2024.103816
-
[18]
I. D. Denisenko, I. A. Kuvaev, I. B. Uvarov, O. E. Kushmantzev, A. I. Toporov, Automated geosteering while drilling using machine learning. case studies, in: SPE Russian Petroleum Technology Conference?, SPE, 2020, p. D023S009R004
2020
-
[19]
URLhttps://api.solo.cloud/
RogiiInc., SoloRESTAPIDocumentation, accessed: 2025-02-11(2025). URLhttps://api.solo.cloud/
2025
-
[20]
L.Chen, K.Lu, A.Rajeswaran, K.Lee, A.Grover, M.Laskin, P.Abbeel, A. Srinivas, I. Mordatch, Decision transformer: Reinforcement learning via sequence modeling (2021). arXiv:2106.01345. URLhttps://arxiv.org/abs/2106.01345
Pith/arXiv arXiv 2021
-
[21]
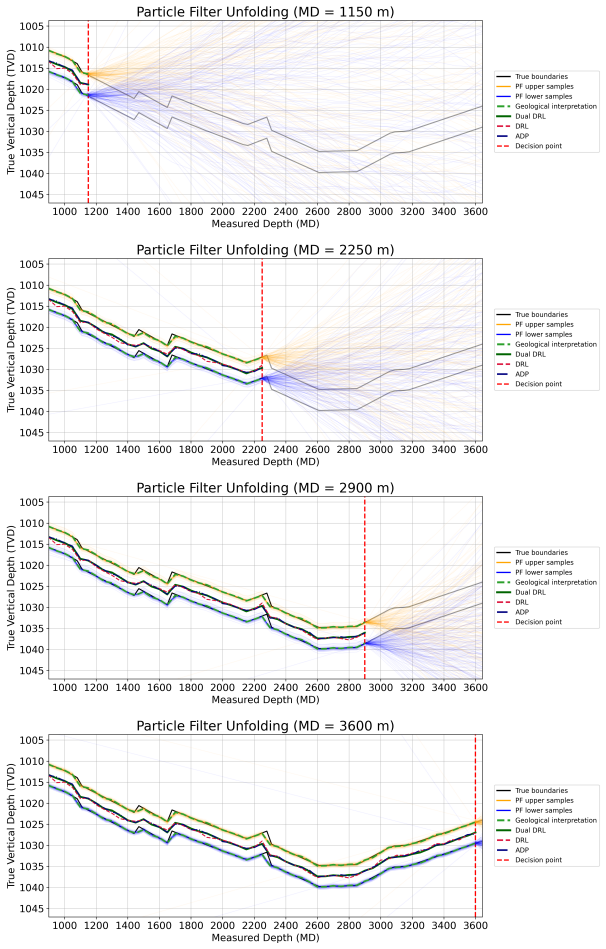
H. E. DJECTA, S. Alyaev, K. Fossum, R. B. Bratvold, D. Sui, Geosteer- ing through the lens of decision transformers: Toward embodied se- quence decision-making, in: NeurIPS 2025 Workshop on Embodied World Models for Decision Making, 2025, p. 12. URLhttps://openreview.net/forum?id=QXLWeLJ0ub 29 Figure 7: Particle-filter unfolding at four representative dec...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.