Rethinking Dataset Distillation for Classification: Do Distilled Sets Outperform Coresets?
Pith reviewed 2026-06-27 01:43 UTC · model grok-4.3
The pith
Dataset distillation methods match or fall short of coreset selection on large image classification tasks while costing more to build.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
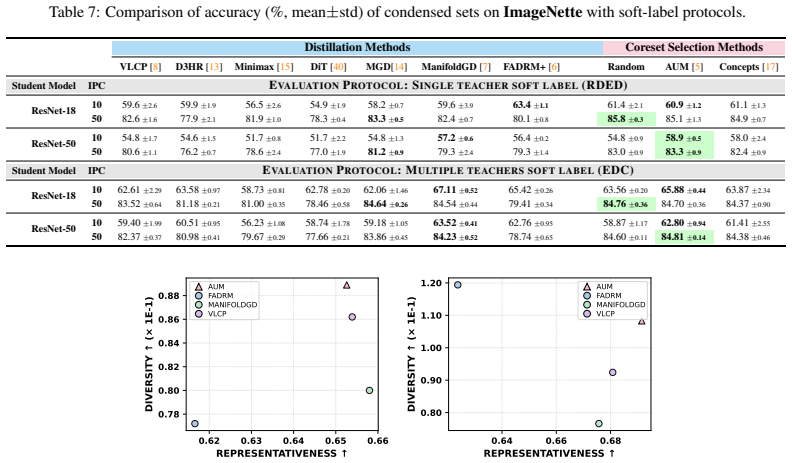
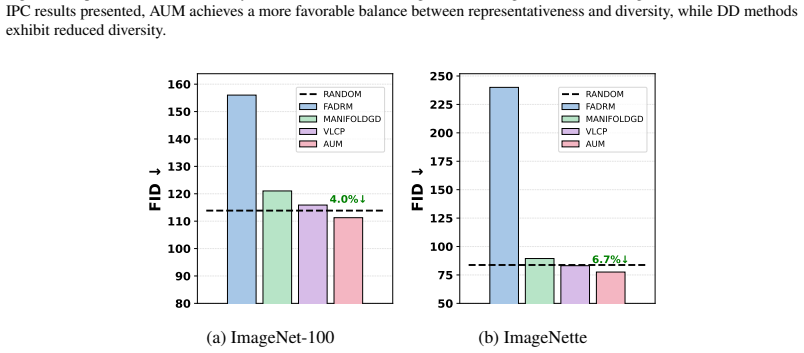
Through standardized benchmarks of seven state-of-the-art dataset distillation methods against three coreset strategies on ImageNet-1K, ImageNet100, and ImageNette using three training protocols, the work establishes that leading distillation approaches achieve accuracy comparable to or lower than coresets on large-scale datasets, incur substantially higher construction costs, and deliver inferior representativeness, diversity, and quality compared to coresets, while some distillation methods fail to beat random subsets.
What carries the argument
Direct head-to-head comparison of seven SOTA dataset distillation methods versus three coreset strategies under three fixed training protocols, measured by accuracy, construction cost, and metrics for data distribution coverage.
If this is right
- Some dataset distillation methods underperform even random subsets of real data.
- Current leading distillation techniques remain comparable to or worse than coresets in final model accuracy on large datasets.
- Dataset distillation requires substantially higher computational cost to construct the condensed set than coreset selection.
- Coresets consistently provide better coverage, diversity, and quality relative to the original data distribution.
Where Pith is reading between the lines
- If the pattern holds across more settings, practitioners may prefer coreset selection over distillation for practical data reduction in classification.
- The results suggest testing whether the expressiveness advantage claimed for synthetic samples survives when total compute for construction is held fixed.
- Extending the same standardized comparison to non-image tasks or other modalities could show whether the relative performance is domain-specific.
Load-bearing premise
The three chosen coreset strategies and three training protocols fairly represent typical use cases without favoring one method through implementation details or dataset effects.
What would settle it
A state-of-the-art distillation method achieving clearly higher accuracy than the best coreset at lower total construction cost on ImageNet-1K under identical training conditions would contradict the central result.
Figures







read the original abstract
Dataset distillation (DD) has emerged as a prominent approach in data centric machine learning, aiming to synthesize compact training sets for efficient training by compressing the information in large datasets into a small number of synthetic samples. However, DD methods are often evaluated under inconsistent evaluation protocols, ranging from standard ERM to single/multi-teacher supervision, making it difficult to isolate the effectiveness of distilled data from evaluation. Moreover, many prior methods claim that DD outperforms data pruning approaches such as coreset selection (CS), based on the assumption that restricting condensed datasets to subsets of real samples fundamentally limits their expressiveness. In this work, we critically evaluate DD methods through large-scale experiments using standardized datasets and evaluation protocols to assess their intrinsic effectiveness. We benchmark seven state-of-the-art (SOTA) DD methods on ImageNet-1K, ImageNet100, and ImageNette, using three widely adopted training protocols against three CS strategies. Our results show that while some DD methods fail to outperform even simple random subsets, the SOTA DD approaches are comparable to or worse than coresets on large-scale datasets and incur a substantially higher cost for construction. Beyond accuracy, we also evaluate the representativeness, diversity, and quality of condensed sets, and find that coresets consistently achieve better coverage of the original data distribution. These findings highlight the limited practical advantages of current DD methods and show that coresets remain competitive and are often a more computationally efficient alternative for data-centric learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that under standardized evaluation protocols, state-of-the-art dataset distillation (DD) methods do not outperform coreset selection (CS) methods on large-scale datasets including ImageNet-1K, ImageNet-100, and ImageNette. Benchmarking seven SOTA DD methods against three CS strategies with three training protocols shows that some DD methods fail to beat random subsets, SOTA DD is comparable to or worse than CS while incurring higher construction costs, and coresets achieve better coverage, representativeness, diversity, and quality of the condensed sets. The work emphasizes inconsistent prior protocols as motivation for the standardized comparison.
Significance. If the empirical results hold, the paper would provide a valuable large-scale re-evaluation of DD's practical advantages over simpler selection methods, potentially redirecting data-centric ML research toward computationally efficient alternatives. Strengths include the scale of experiments on ImageNet-1K, use of multiple protocols and additional metrics beyond accuracy, and direct comparison that addresses prior claims of DD superiority based on expressiveness assumptions.
major comments (1)
- [Abstract] Abstract: The central claim that the three training protocols allow assessment of the 'intrinsic effectiveness' of distilled data (and thus that SOTA DD is comparable/worse than CS) requires that these protocols match the supervision regimes (e.g., multi-teacher or custom distillation losses) under which the seven DD methods originally demonstrated superiority. The manuscript acknowledges inconsistent prior protocols but provides no explicit verification or details that the chosen protocols include those regimes; without this, performance gaps may reflect protocol mismatch rather than the distilled sets themselves being less expressive than selected real samples.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. Below we respond to the major comment.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the three training protocols allow assessment of the 'intrinsic effectiveness' of distilled data (and thus that SOTA DD is comparable/worse than CS) requires that these protocols match the supervision regimes (e.g., multi-teacher or custom distillation losses) under which the seven DD methods originally demonstrated superiority. The manuscript acknowledges inconsistent prior protocols but provides no explicit verification or details that the chosen protocols include those regimes; without this, performance gaps may reflect protocol mismatch rather than the distilled sets themselves being less expressive than selected real samples.
Authors: We appreciate the referee highlighting this point. Our three protocols (standard ERM, single-teacher, and multi-teacher supervision) were selected precisely because they represent the most common evaluation regimes appearing across the DD literature; they are detailed in Section 3.2. The goal of the work is to isolate the quality of the distilled sets themselves under a single, consistent evaluation framework rather than to reproduce each method's original (and mutually inconsistent) training procedure. This standardization is what enables the head-to-head comparison with coreset methods. That said, we agree that an explicit cross-reference would remove any ambiguity. We will add a table in the revised manuscript that maps each of the seven DD methods to the supervision regime(s) used in its original paper and indicates which of our three protocols align with it. revision: yes
Circularity Check
No circularity: purely empirical benchmarking on external public datasets
full rationale
The paper performs direct head-to-head accuracy, diversity, and cost comparisons of seven DD methods against three CS strategies on ImageNet-1K, ImageNet-100, and ImageNette under three fixed training protocols. No equations, parameter fits, or first-principles derivations are present; all reported outcomes are measured quantities from independent runs on public benchmarks. Self-citations, if any, are limited to prior method descriptions and do not bear the central claim. The work is therefore self-contained against external data and scores 0.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard i.i.d. train/test splits and ERM training assumptions hold for the ImageNet variants used.
Reference graph
Works this paper leans on
-
[1]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Beyond neural scaling laws: beating power law scaling via data pruning.Advances in Neural Information Processing Systems, 35:19523–19536, 2022
Ben Sorscher, Robert Geirhos, Shashank Shekhar, Surya Ganguli, and Ari Morcos. Beyond neural scaling laws: beating power law scaling via data pruning.Advances in Neural Information Processing Systems, 35:19523–19536, 2022
2022
-
[4]
Datacomp-lm: In search of the next generation of training sets for language models.Advances in Neural Information Processing Systems, 37:14200–14282, 2024
Jeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Matt Jordan, Samir Yitzhak Gadre, Hritik Bansal, Etash Guha, Sedrick Scott Keh, Kushal Arora, et al. Datacomp-lm: In search of the next generation of training sets for language models.Advances in Neural Information Processing Systems, 37:14200–14282, 2024
2024
-
[5]
Identifying mislabeled data using the area under the margin ranking
Geoff Pleiss et al. Identifying mislabeled data using the area under the margin ranking. In NeurIPS, 2020
2020
-
[6]
Fadrm: Fast and accurate data residual matching for dataset distillation
Jiacheng Cui, Xinyue Bi, Yaxin Luo, Xiaohan Zhao, Jiacheng Liu, and Zhiqiang Shen. Fadrm: Fast and accurate data residual matching for dataset distillation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[7]
Mani- foldgd: Training-free hierarchical manifold guidance for diffusion-based dataset distillation
Ayush Roy, Wei-Yang Alex Lee, Rudrasis Chakraborty, and Vishnu Suresh Lokhande. Mani- foldgd: Training-free hierarchical manifold guidance for diffusion-based dataset distillation. arXiv preprint arXiv:2602.23295, 2026
-
[8]
Dataset distillation via vision-language category prototype
Yawen Zou, Guang Li, Duo Su, Zi Wang, Jun Yu, and Chao Zhang. Dataset distillation via vision-language category prototype. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[9]
Ping Liu and Jiawei Du. The evolution of dataset distillation: Toward scalable and generalizable solutions.arXiv preprint arXiv:2502.05673, 2025
-
[10]
Dataset distillation in the era of large-scale data: Methods, analysis, and future directions.Authorea Preprints, 2025
Xinyi Shang, Peng Sun, Zhiqiang Shen, Tao Lin, and Jing-Hao Xue. Dataset distillation in the era of large-scale data: Methods, analysis, and future directions.Authorea Preprints, 2025
2025
-
[11]
Coresets for data-efficient training of machine learning models
Baharan Mirzasoleiman, Jeff Bilmes, and Jure Leskovec. Coresets for data-efficient training of machine learning models. InInternational Conference on Machine Learning, pages 6950–6960. PMLR, 2020. 10
2020
-
[12]
Deepcore: A comprehensive library for coreset selection in deep learning
Chengcheng Guo, Bo Zhao, and Yanbing Bai. Deepcore: A comprehensive library for coreset selection in deep learning. InInternational Conference on Database and Expert Systems Applications, pages 181–195. Springer, 2022
2022
-
[13]
Taming diffusion for dataset distillation with high representativeness
Lin Zhao, Yushu Wu, Xinru Jiang, Jianyang Gu, Yanzhi Wang, Xiaolin Xu, Pu Zhao, and Xue Lin. Taming diffusion for dataset distillation with high representativeness. InForty-second International Conference on Machine Learning
-
[14]
Chan Santiago, Praveen Tirupattur, Gaurav Kumar Nayak, Gaowen Liu, and Mubarak Shah
Jeffrey A. Chan Santiago, Praveen Tirupattur, Gaurav Kumar Nayak, Gaowen Liu, and Mubarak Shah. MGD 3: Mode-guided dataset distillation using diffusion models. InProceedings of the 42nd International Conference on Machine Learning (ICML), 2025
2025
-
[15]
Efficient dataset distillation via minimax diffusion
Jianyang Gu, Saeed Vahidian, Vyacheslav Kungurtsev, Haonan Wang, Wei Jiang, Yang You, and Yiran Chen. Efficient dataset distillation via minimax diffusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[16]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[17]
Coreset selection via llm-based concept bottlenecks.arXiv preprint arXiv:2502.16733, 2025
Akshay Mehra, Trisha Mittal, Subhadra Gopalakrishnan, and Joshua Kimball. Coreset selection via llm-based concept bottlenecks.arXiv preprint arXiv:2502.16733, 2025
-
[18]
On the diversity and realism of distilled dataset: An efficient dataset distillation paradigm, 2024
Peng Sun, Bei Shi, Daiwei Yu, and Tao Lin. On the diversity and realism of distilled dataset: An efficient dataset distillation paradigm, 2024
2024
-
[19]
Elucidating the design space of dataset condensation.arXiv preprint arXiv:2404.13733, 2024
Shitong Shao, Zikai Zhou, Huanran Chen, and Zhiqiang Shen. Elucidating the design space of dataset condensation.arXiv preprint arXiv:2404.13733, 2024
-
[20]
D^4: Dataset distillation via disentangled diffusion model
Duo Su, Junjie Hou, Weizhi Gao, Yingjie Tian, and Bowen Tang. D^4: Dataset distillation via disentangled diffusion model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5809–5818, June 2024
2024
-
[21]
Task-specific generative dataset distillation with difficulty-guided sampling
Mingzhuo Li, Guang Li, Jiafeng Mao, Linfeng Ye, Takahiro Ogawa, and Miki Haseyama. Task-specific generative dataset distillation with difficulty-guided sampling. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, 2025
2025
-
[22]
Fast-dit: Fast diffusion models with transformers
Chuanyang Jin and Saining Xie. Fast-dit: Fast diffusion models with transformers. https: //github.com/chuanyangjin/fast-DiT, 2024
2024
-
[23]
Generalized large-scale data condensation via various backbone and statistical matching, 2024
Shitong Shao, Zeyuan Yin, Muxin Zhou, Xindong Zhang, and Zhiqiang Shen. Generalized large-scale data condensation via various backbone and statistical matching, 2024
2024
-
[24]
Squeeze, recover and relabel: Dataset condensation at imagenet scale from a new perspective.Advances in Neural Information Processing Systems, 36:73582–73603, 2023
Zeyuan Yin, Eric Xing, and Zhiqiang Shen. Squeeze, recover and relabel: Dataset condensation at imagenet scale from a new perspective.Advances in Neural Information Processing Systems, 36:73582–73603, 2023
2023
-
[25]
Dataset condensation with gradient matching
Bo Zhao, Konda Reddy Mopuri, and Hakan Bilen. Dataset condensation with gradient matching. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[26]
Dataset distillation by matching training trajectories
George Cazenavette, Tongzhou Wang, Antonio Torralba, Alexei A Efros, and Jun-Yan Zhu. Dataset distillation by matching training trajectories. InProceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition, pages 4750–4759, 2022
2022
-
[27]
Mariya Toneva et al. An empirical study of example forgetting during deep neural network learning.arXiv preprint arXiv:1812.05159, 2018
-
[28]
Cody Coleman et al. Selection via proxy: Efficient data selection for deep learning.arXiv preprint arXiv:1906.11829, 2019
-
[29]
A label is worth a thousand images in dataset distillation.Advances in Neural Information Processing Systems, 37:131946–131971, 2024
Tian Qin, Zhiwei Deng, and David Alvarez-Melis. A label is worth a thousand images in dataset distillation.Advances in Neural Information Processing Systems, 37:131946–131971, 2024
2024
-
[30]
Dd-ranking: Rethinking the evaluation of dataset distillation.arXiv preprint arXiv:2505.13300, 2025
Zekai Li, Xinhao Zhong, Samir Khaki, Zhiyuan Liang, Yuhao Zhou, Mingjia Shi, Ziqiao Wang, Xuanlei Zhao, Wangbo Zhao, Ziheng Qin, et al. Dd-ranking: Rethinking the evaluation of dataset distillation.arXiv preprint arXiv:2505.13300, 2025. 11
-
[31]
Xinhao Zhong, Shuoyang Sun, Xulin Gu, Chenyang Zhu, Bin Chen, and Yaowei Wang. Rectified decoupled dataset distillation: A closer look for fair and comprehensive evaluation.arXiv preprint arXiv:2509.19743, 2025
-
[32]
Rethinking dataset distillation: Hard truths about soft labels
Priyam Dey, Aditya Sahdev, Sunny Bhati, Konda Reddy Mopuri, and Venkatesh Babu Radhakr- ishnan. Rethinking dataset distillation: Hard truths about soft labels. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 178–187, 2026
2026
-
[33]
Unifying Dataset Pruning and Distillation for Efficient Large-scale Compression
Lingao Xiao, Songhua Liu, Yang He, and Xinchao Wang. Rethinking large-scale dataset compression: Shifting focus from labels to images.arXiv preprint arXiv:2502.06434, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Coverage-centric coreset selection for high pruning rates.arXiv preprint arXiv:2210.15809, 2022
Haizhong Zheng, Rui Liu, Fan Lai, and Atul Prakash. Coverage-centric coreset selection for high pruning rates.arXiv preprint arXiv:2210.15809, 2022
-
[35]
Elfs: Enhancing label-free coreset selection via clustering-based pseudo-labeling
Haizhong Zheng, Elisa Tsai, Yifu Lu, Jiachen Sun, Brian R Bartoldson, Bhavya Kailkhura, and Atul Prakash. Elfs: Enhancing label-free coreset selection via clustering-based pseudo-labeling. arXiv preprint arXiv:2406.04273, 2024
-
[36]
Dataset condensation with distribution matching
Bo Zhao and Hakan Bilen. Dataset condensation with distribution matching. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 6514–6523, 2023
2023
-
[37]
Imagenet: A large- scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
2009
-
[38]
Contrastive multiview coding
Yonglong Tian, Dilip Krishnan, and Phillip Isola. Contrastive multiview coding. InEuropean conference on computer vision, pages 776–794. Springer, 2020
2020
-
[39]
Imagenette: A smaller subset of 10 easily classified classes from imagenet
Jeremy Howard. Imagenette: A smaller subset of 10 easily classified classes from imagenet. https://github.com/fastai/imagenette, April 2019. Accessed: 2019
2019
-
[40]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[41]
Synthesizing informative training samples with gan, 2022
Bo Zhao and Hakan Bilen. Synthesizing informative training samples with gan, 2022
2022
-
[42]
Active Learning for Convolutional Neural Networks: A Core-Set Approach
Ozan Sener and Silvio Savarese. Active learning for convolutional neural networks: A core-set approach.arXiv preprint arXiv:1708.00489, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[43]
Turning big data into tiny data: Constant-size coresets for k-means.SIAM Journal on Computing, 2020
Dan Feldman et al. Turning big data into tiny data: Constant-size coresets for k-means.SIAM Journal on Computing, 2020
2020
-
[44]
Understanding black-box predictions via influence functions
Pang Wei Koh and Percy Liang. Understanding black-box predictions via influence functions. InICML, 2017
2017
-
[45]
Gradmatch: Gradient matching based data subset selection
Krishnateja Killamsetty et al. Gradmatch: Gradient matching based data subset selection. In ICML, 2021
2021
-
[46]
Krishnateja Killamsetty, Alexandre V Evfimievski, Tejaswini Pedapati, Kiran Kate, Lucian Popa, and Rishabh Iyer. Milo: Model-agnostic subset selection framework for efficient model training and tuning.arXiv preprint arXiv:2301.13287, 2023
-
[47]
Provable data subset selection for efficient neural networks training
Murad Tukan, Samson Zhou, Alaa Maalouf, Daniela Rus, Vladimir Braverman, and Dan Feldman. Provable data subset selection for efficient neural networks training. InInternational Conference on Machine Learning, pages 34533–34555. PMLR, 2023
2023
-
[48]
Grad-match: Gradient matching based data subset selection for efficient deep model training
Krishnateja Killamsetty, Sivasubramanian Durga, Ganesh Ramakrishnan, Abir De, and Rishabh Iyer. Grad-match: Gradient matching based data subset selection for efficient deep model training. InInternational Conference on Machine Learning, pages 5464–5474. PMLR, 2021. 12 Appendix We present an additional details of DD and CS methods, followed by details of t...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.