Learning from Your Own Mistakes: Constructing Learnable Micro-Reflective Trajectories for Self-Distillation
Pith reviewed 2026-06-26 21:28 UTC · model grok-4.3
The pith
TAPO constructs micro-reflective trajectories from a model's own errors to improve self-distillation beyond KL alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
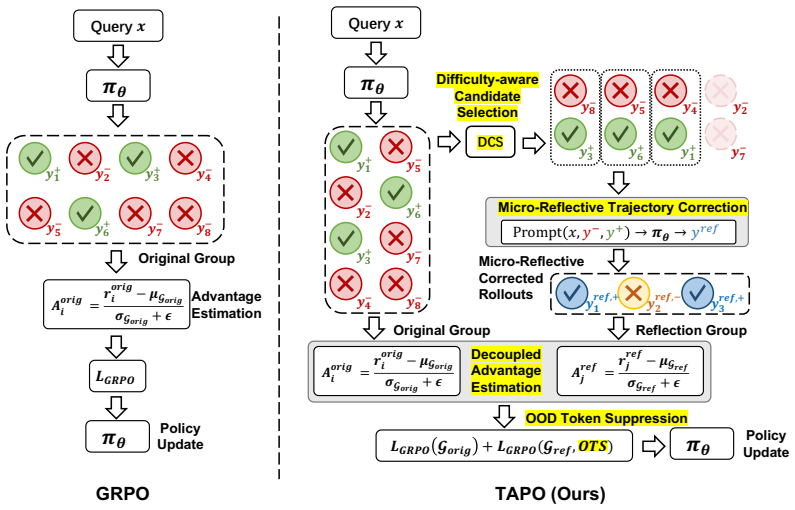
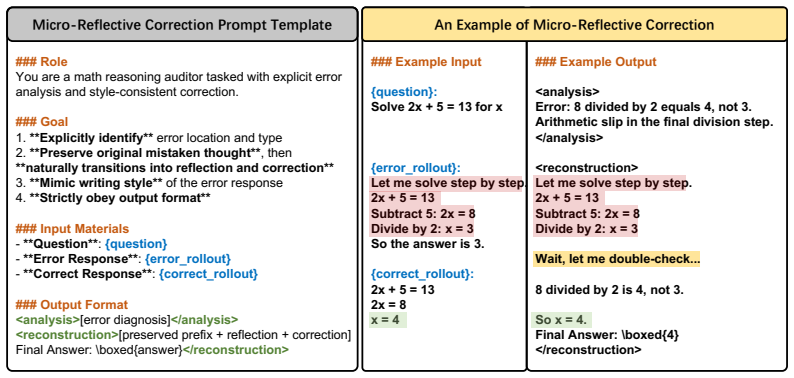
TAPO advances self-distillation by constructing micro-reflective corrections that retain the model's erroneous reasoning prefix up to the point of failure and then append a natural-language diagnosis plus corrected reasoning guided by a correct reference from the same sampling group. Because each such trajectory remains anchored in the learner's own prefixes and solutions, the corrective signal preserves the on-policy distribution more closely than position-wise KL alignment. Difficulty-aware candidate selection and decoupled advantage estimation are used to integrate these trajectories without gradient contamination from the inserted corrections.
What carries the argument
Micro-reflective trajectories that retain the learner's erroneous prefix and insert a diagnosis plus correction from a same-group correct rollout.
If this is right
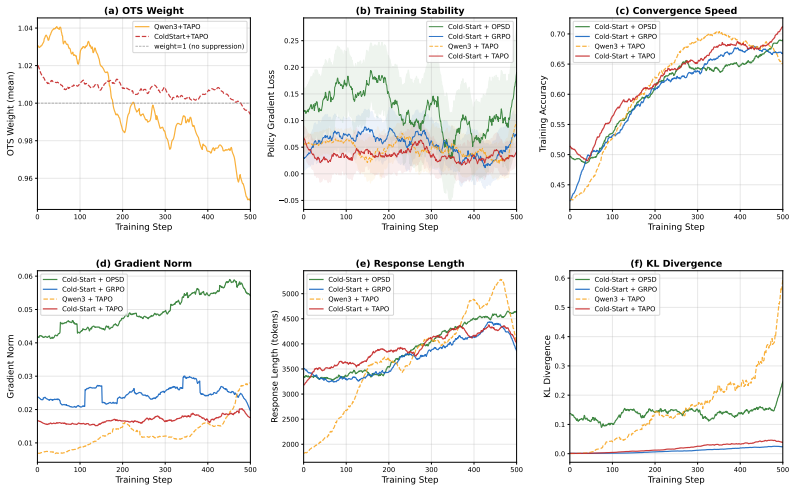
- TAPO produces consistent improvements over GRPO under identical training steps on AIME 2024, AIME 2025, and HMMT 2025.
- The method strengthens both first-pass reasoning accuracy and error-correction effectiveness.
- Difficulty-aware selection at the capability boundary yields higher-quality corrective trajectories.
- Decoupled advantage estimation prevents the inserted corrections from contaminating the policy gradient.
Where Pith is reading between the lines
- The same micro-reflective construction could be tested on non-mathematical reasoning domains such as code generation or multi-step planning to check whether the on-policy preservation benefit generalizes.
- If the distribution-preservation claim holds, similar prefix-anchored insertions might reduce the volume of diverse sampling required in other RLHF pipelines.
- One could measure whether the inserted diagnoses improve the model's ability to self-diagnose errors on held-out queries without any further training.
Load-bearing premise
Micro-reflective trajectories anchored in the learner's own erroneous prefixes preserve the on-policy distribution to a greater extent than position-wise KL alignment, enabling effective learning without gradient contamination from the inserted corrections.
What would settle it
Running the same number of training steps on AIME 2024, AIME 2025, and HMMT 2025 and finding no consistent improvement for TAPO over GRPO, or measuring higher KL divergence between the trained policy and the original sampling distribution under TAPO than under standard GRPO.
Figures
read the original abstract
Self-distillation improves reasoning in large language models by using the model's own rollouts as training signal, typically through implicit logit-level alignment that minimizes KL divergence toward a privileged target distribution. However, because this supervision is generated via uncontrolled sampling, it provides no diagnostic insight into the model's specific errors or corrective guidance for its individual failure patterns. Consequently, the model learns to imitate a privileged distribution rather than receiving fine-grained corrections that pinpoint where and why its reasoning fails. In this paper, we propose Trajectory-Augmented Policy Optimization (TAPO), which advances self-distillation from implicit distributional alignment to explicit trajectory construction. During RL training, the model produces both correct and incorrect rollouts to the same query, and TAPO leverages this contrastive structure to construct micro-reflective corrections, new training trajectories that retain the model's erroneous reasoning up to the point of failure, then insert a natural-language diagnosis and corrected reasoning guided by a correct reference from the same sampling group. Since each trajectory is anchored in the learner's own prefix and solutions, the corrective signal preserves the model's on-policy distribution to a greater extent than the position-wise alignment imposed by KL-based methods. To integrate these trajectories, TAPO introduces difficulty-aware candidate selection at the model's capability boundary and decoupled advantage estimation to prevent gradient contamination. Experiments on AIME 2024, AIME 2025, and HMMT 2025 show that TAPO achieves consistent improvements over GRPO under the same number of training steps. Further analysis demonstrates that TAPO strengthens both first-pass reasoning and error-correction effectiveness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Trajectory-Augmented Policy Optimization (TAPO) for improving self-distillation in large language models. Instead of implicit logit-level KL alignment, TAPO constructs micro-reflective trajectories during RL training by retaining the model's own erroneous reasoning prefixes up to failure points, then inserting natural-language diagnoses and corrected reasoning drawn from correct rollouts in the same sampling group. It adds difficulty-aware candidate selection at the capability boundary and decoupled advantage estimation to avoid gradient contamination. Experiments claim consistent gains over GRPO on AIME 2024, AIME 2025, and HMMT 2025 under identical training steps, with additional analysis on first-pass reasoning and error correction.
Significance. If the central claims hold after verification, the work could meaningfully advance self-distillation methods by shifting from distributional imitation to explicit, learner-anchored corrections. The contrastive use of correct/incorrect rollouts and the focus on preserving on-policy properties via prefix anchoring represent a concrete technical direction worth exploring for reasoning tasks.
major comments (3)
- [Experiments and results] The headline claim of consistent improvements over GRPO on AIME 2024/2025 and HMMT 2025 is presented without any reported details on baselines, number of runs, statistical tests, variance, or implementation hyperparameters. This prevents evaluation of whether the gains are reliable or attributable to the proposed components.
- [Method (trajectory construction and advantage estimation)] The core assumption that micro-reflective insertions (anchored in the learner's erroneous prefixes) preserve the on-policy distribution more faithfully than position-wise KL alignment is load-bearing for the claimed advantage, yet the manuscript provides no direct measurement of distribution shift such as KL divergence between original and augmented trajectories, nor ablations isolating the decoupled advantage estimator.
- [Method (decoupled advantage estimation)] No verification is supplied that the inserted natural-language diagnosis segments do not introduce off-policy tokens capable of contaminating the advantage signal; this directly affects whether the decoupled estimator successfully prevents gradient issues as asserted.
minor comments (2)
- [Abstract] The abstract would be strengthened by including the magnitude of reported gains and a one-sentence description of the benchmarks.
- [Method] Notation and equations for difficulty-aware selection and the decoupled advantage estimator should be presented explicitly if not already done, to allow reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below with clarifications and commitments to strengthen the manuscript where gaps exist.
read point-by-point responses
-
Referee: [Experiments and results] The headline claim of consistent improvements over GRPO on AIME 2024/2025 and HMMT 2025 is presented without any reported details on baselines, number of runs, statistical tests, variance, or implementation hyperparameters. This prevents evaluation of whether the gains are reliable or attributable to the proposed components.
Authors: We agree that the experimental reporting is insufficient for assessing reliability. In the revised manuscript we will add a dedicated experimental details subsection reporting: exact GRPO and TAPO hyperparameters (learning rate, sampling temperature, group size), results aggregated over 5 independent runs with means and standard deviations, paired statistical tests, and variance across seeds. These additions will directly address concerns about reproducibility and attribution to the proposed components. revision: yes
-
Referee: [Method (trajectory construction and advantage estimation)] The core assumption that micro-reflective insertions (anchored in the learner's erroneous prefixes) preserve the on-policy distribution more faithfully than position-wise KL alignment is load-bearing for the claimed advantage, yet the manuscript provides no direct measurement of distribution shift such as KL divergence between original and augmented trajectories, nor ablations isolating the decoupled advantage estimator.
Authors: The referee is correct that direct empirical support for reduced distribution shift is missing. We will add KL divergence measurements (computed on a held-out set of queries between original rollouts and TAPO-augmented trajectories) and a new ablation table isolating the decoupled advantage estimator by comparing full TAPO against a variant that uses standard advantage estimation. These results will be included in the revised experiments section. revision: yes
-
Referee: [Method (decoupled advantage estimation)] No verification is supplied that the inserted natural-language diagnosis segments do not introduce off-policy tokens capable of contaminating the advantage signal; this directly affects whether the decoupled estimator successfully prevents gradient issues as asserted.
Authors: We acknowledge the absence of explicit verification. In revision we will add an analysis quantifying the policy probability of inserted diagnosis tokens under the original model (showing they derive from same-group correct rollouts and remain within on-policy range) together with gradient-norm comparisons before and after decoupling. This will substantiate that the estimator mitigates contamination. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and description present TAPO as a method that constructs micro-reflective trajectories anchored in the model's own prefixes and uses decoupled advantage estimation, with the on-policy preservation claim stated as a design rationale rather than a derived quantity. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The reported gains over GRPO are framed as empirical outcomes from experiments on AIME/HMMT benchmarks, not as results forced by definition or prior self-referential theorems. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On-policy distillation of language models: Learning from self-generated mistakes
Agarwal, R., Vieillard, N., Zhou, Y ., Stanczyk, P., Ramos Garea, S., Geist, M., and Bachem, O. On-policy distillation of language models: Learning from self-generated mistakes. InInternational Conference on Learning Representations, volume 2024, pp. 21246–21263,
2024
-
[2]
Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
-
[3]
16 Cui, F., Li, S., and Li, J. A brief overview: On-policy self-distillation in large language models.arXiv preprint arXiv:2605.18141,
-
[4]
Gulcehre, C., Paine, T. L., Srinivasan, S., Konyushkova, K., Weerts, L., Sharma, A., Siddhant, A., Ahern, A., Wang, M., Gu, C., et al. Reinforced self-training (rest) for language modeling.arXiv preprint arXiv:2308.08998,
-
[5]
Guo, D., Yang, D., Zhang, H., Song, J., Wang, P., Zhu, Q., Xu, R., Zhang, R., Ma, S., Bi, X., et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
-
[6]
Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
-
[7]
and Chang, K
Huang, J. and Chang, K. C.-C. Towards reasoning in large language models: A survey. InFindings of the association for computational linguistics: ACL 2023, pp. 1049–1065,
2023
-
[8]
D., Singh, A., Baumli, K., Iqbal, S., Bishop, C., Roelofs, R., et al
Kumar, A., Zhuang, V ., Agarwal, R., Su, Y ., Co-Reyes, J. D., Singh, A., Baumli, K., Iqbal, S., Bishop, C., Roelofs, R., et al. Training language models to self-correct via reinforcement learning.arXiv preprint arXiv:2409.12917,
-
[9]
Let’s verify step by step
Lightman, H., Kosaraju, V ., Burda, Y ., Edwards, H., Baker, B., Lee, T., Leike, J., Schulman, J., Sutskever, I., and Cobbe, K. Let’s verify step by step. InInternational Conference on Learning Representations, volume 2024, pp. 39578–39601,
2024
-
[10]
Lv, B., Liu, N., Tang, C., Liu, X., Yu, Y ., and Luo, P. Specfuse: Ensembling large language models via next-segment prediction.arXiv preprint arXiv:2412.07380, 2024a. Lv, B., Liu, X., Wei, K., Luo, P., and Yu, Y . Taekd: Teacher assistant enhanced knowledge distillation for closed-source multilingual neural machine translation. InProceedings of the 2024 ...
arXiv 2024
-
[11]
Mroueh, Y . Reinforcement learning with verifiable rewards: Grpo’s effective loss, dynamics, and success amplification.arXiv preprint arXiv:2503.06639,
-
[12]
Qi, P., Zhou, X., Liu, Z., Pang, T., Du, C., Lin, M., and Lee, W. S. Rethinking the trust region in llm reinforcement learning.arXiv preprint arXiv:2602.04879,
-
[13]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
17 Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
-
[14]
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024.URL https://arxiv. org/abs/2402.03300, 2(3):5,
Pith/arXiv arXiv 2024
-
[15]
Experiential reinforcement learning
Shi, T., Chen, S., Jiang, B., Song, L., Yang, L., and Zhao, J. Experiential reinforcement learning. arXiv preprint arXiv:2602.13949,
-
[16]
Reflexion: Language agents with verbal reinforcement learning, 2023.URL https://arxiv
Shinn, N., Cassano, F., Berman, E., Gopinath, A., Narasimhan, K., and Yao, S. Reflexion: Language agents with verbal reinforcement learning, 2023.URL https://arxiv. org/abs/2303.11366, 8,
Pith/arXiv arXiv 2023
-
[17]
Wen, X., Liu, Z., Zheng, S., Ye, S., Wu, Z., Wang, Y ., Xu, Z., Liang, X., Li, J., Miao, Z., et al. Reinforcement learning with verifiable rewards implicitly incentivizes correct reasoning in base llms.arXiv preprint arXiv:2506.14245,
-
[18]
Qwen3 technical report.arXiv preprint arXiv:2505.09388,
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
-
[19]
Yao, J., Zhou, X., Qi, P., Lee, W. S., Bo, L., and Pang, T. Rethinking the divergence regularization in llm rl.arXiv preprint arXiv:2606.09821,
-
[20]
Towards better chain-of-thought prompting strategies: A survey.arXiv preprint arXiv:2310.04959,
Yu, Z., He, L., Wu, Z., Dai, X., and Chen, J. Towards better chain-of-thought prompting strategies: A survey.arXiv preprint arXiv:2310.04959,
-
[21]
Yuan, Z., Yuan, H., Li, C., Dong, G., Lu, K., Tan, C., Zhou, C., and Zhou, J. Scaling relationship on learning mathematical reasoning with large language models.arXiv preprint arXiv:2308.01825,
-
[22]
Zhang, M., Liu, Y ., Lin, S., Yang, X., Dai, Q., Luo, C., Jiang, W., Hou, P., Zeng, A., Geng, X., et al. Towards on-policy sft: Distribution discriminant theory and its applications in llm training.arXiv preprint arXiv:2602.12222,
-
[23]
Automatic chain of thought prompting in large language models.arXiv preprint arXiv:2210.03493,
Zhang, Z., Zhang, A., Li, M., and Smola, A. Automatic chain of thought prompting in large language models.arXiv preprint arXiv:2210.03493,
-
[24]
Zhao, S., Xie, Z., Liu, M., Huang, J., Pang, G., Chen, F., and Grover, A. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734, 2026a. Zhao, W. X., Zhou, K., Li, J., Tang, T., Dong, Z., Hou, Y ., Zhang, B., Min, Y ., Zhang, J., Liu, P., et al. A survey of large language models.Frontiers of Computer...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.