Geometric and Stochastic Analysis of Discontinuities in Sparse Mixture-of-Experts
Pith reviewed 2026-06-26 21:18 UTC · model grok-4.3
The pith
Sparse mixture-of-experts maps are discontinuous at surfaces classified by order, with lower-order sets dominating volume and random diffusion paths hitting order-1 surfaces first almost surely.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Discontinuity surfaces in SMoE are partitioned by order; asymptotic volume estimates show lower-order surfaces dominate, diffusion paths encounter an order-1 surface first almost surely with finite-time bounds, and occupation times quantify exposure to each order; a direct smoothing operator then enforces continuity while keeping added cost small.
What carries the argument
Order classification of discontinuity surfaces by number of tied experts, combined with measure-theoretic slicing for volume asymptotics and diffusion-process first-hit analysis for stochastic encounter probabilities.
If this is right
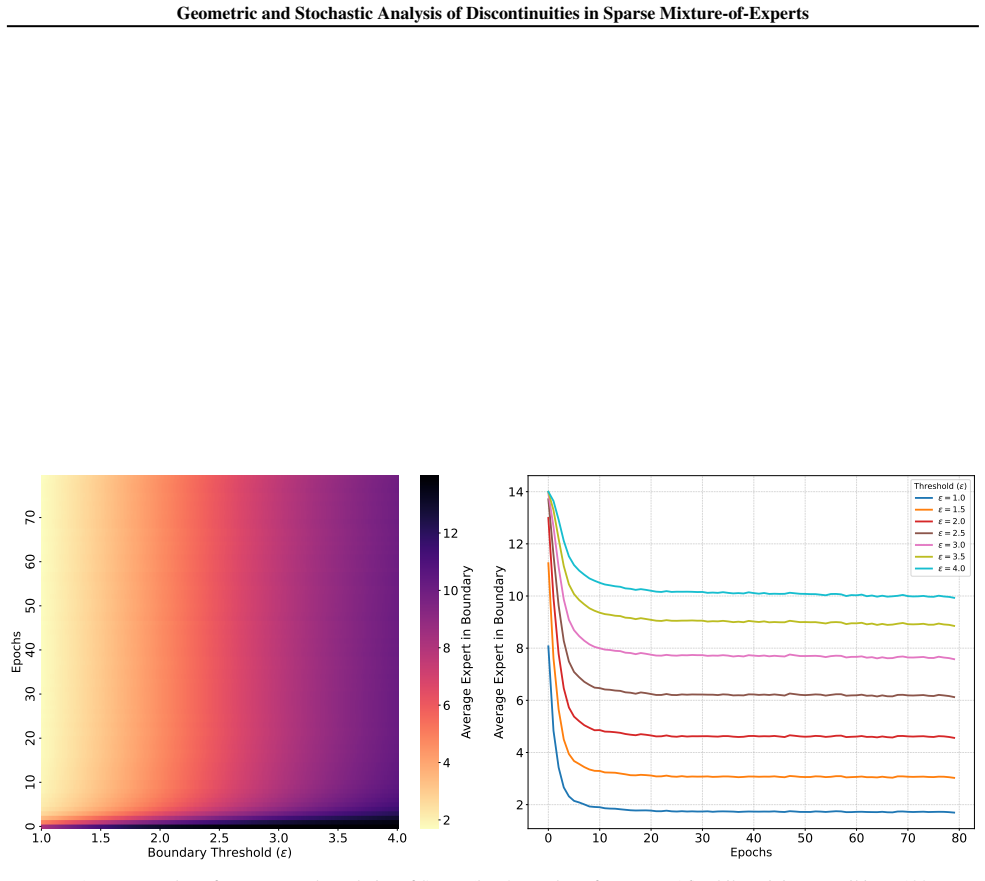
- Inputs lie near lower-order discontinuities with higher probability than near higher-order ones.
- The proposed smoothing operator can be inserted into any existing SMoE without architectural change.
- Added computation stays bounded because only a vanishing fraction of inputs lie near high-order surfaces.
- Continuity enforcement yields measurable gains on downstream language and vision tasks.
Where Pith is reading between the lines
- The same order-based volume argument may apply to other conditional-computation schemes that use top-k selection.
- Smoothing near discontinuities could alter gradient statistics during training in ways not examined here.
- If diffusion modeling is replaced by other perturbation distributions, the first-hit ordering might shift.
Load-bearing premise
Input perturbations can be modeled as a diffusion process whose paths meet the discontinuity surfaces in the way required for the first-hit and occupation-time derivations.
What would settle it
A numerical check that either the relative volume of higher-order discontinuity sets fails to vanish or that sampled diffusion paths hit higher-order surfaces before order-1 surfaces at rates exceeding the derived bounds.
Figures

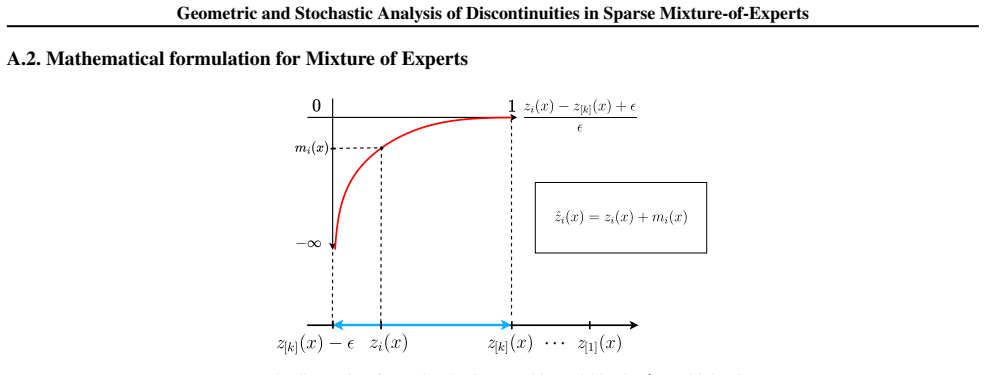
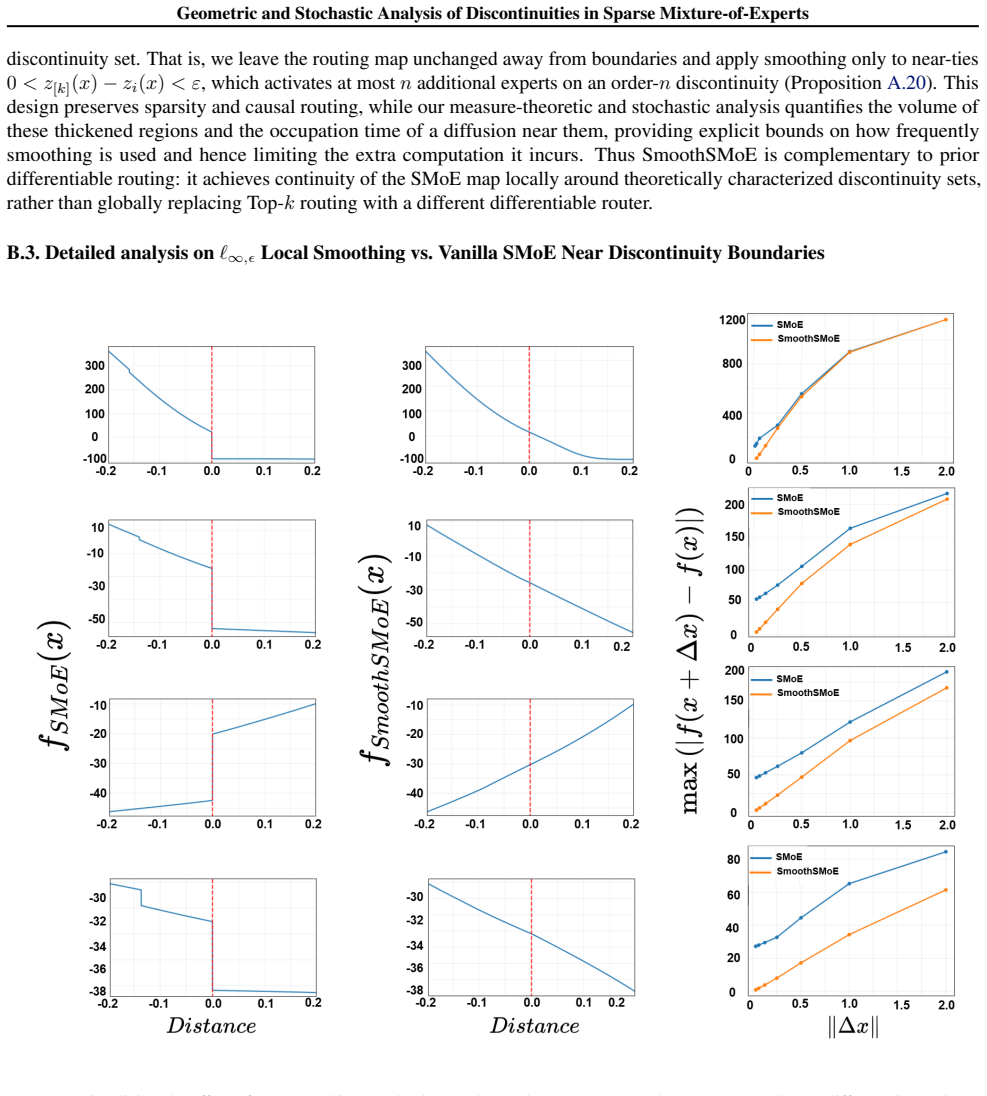

read the original abstract
Sparse Mixture-of-Experts (SMoE) architectures are now widely deployed in state-of-the-art language and vision models, where conditional routing allows scaling to very large networks. However, this very Top-$k$ expert selection that enables conditional routing also renders the SMoE map inherently discontinuous. In the vicinity of these discontinuity surfaces, even inputs that are arbitrarily close may activate substantially different sets of experts resulting in significantly different outputs. In this work we give a rigorous geometric and stochastic analysis of these discontinuities. We first classify them by order, determined by the number of tied experts at a switching event. Using measure-theoretic slicing arguments, we establish asymptotic volume estimates for the thickened discontinuity surfaces, showing that lower-order discontinuity sets dominate, whereas higher-order ones occupy a vanishingly small relative volume. Next, modeling random perturbations in the input space via a diffusion process, we prove that the path eventually encounter a discontinuity, and moreover that the first hit almost surely occurs on an order-1 discontinuity with explicit finite-time probability bounds. We further derive occupation-time bounds that quantify the duration the random path spend in the neighborhoods of each discontinuity order. These theoretical results imply that inputs are more likely to lie near lower order discontinuities. Motivated by this insight, we propose a simple smoothing mechanism that can be directly applied to existing SMoEs, softly incorporating experts near discontinuities; our analysis guarantees that the added computational overhead remains small while providing localized smoothing near discontinuities, and experiments across language and vision tasks show that smoothing not only enforces continuity of the SMoE map but also enhances empirical performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to deliver a rigorous geometric and stochastic analysis of discontinuities in Sparse Mixture-of-Experts (SMoE) models. Discontinuities are classified by order according to the number of tied experts at a switching event. Measure-theoretic slicing arguments establish that lower-order discontinuity sets dominate asymptotically in volume while higher-order sets occupy vanishing relative volume. Modeling input perturbations as a diffusion process, the work proves that paths encounter discontinuities almost surely, with the first hit occurring on an order-1 discontinuity and with explicit finite-time probability bounds; occupation-time bounds are also derived. These results motivate a simple smoothing mechanism that softly incorporates nearby experts near discontinuities, with guarantees of small overhead, and experiments on language and vision tasks are reported to show both enforced continuity and improved empirical performance.
Significance. If the derivations hold, the geometric volume estimates and stochastic first-hit/occupation results would supply a principled foundation for analyzing and mitigating discontinuities in widely deployed SMoE architectures. The measure-theoretic slicing and diffusion-based hitting-time analysis constitute non-trivial technical contributions when complete; the proposed smoothing carries direct practical implications for continuity and efficiency. Reproducible code or explicit parameter-free derivations are not mentioned, but the falsifiable predictions on volume dominance and hitting probabilities would be a strength if verified.
major comments (2)
- [Stochastic analysis section] Stochastic analysis section (diffusion modeling of perturbations): the assumption that random input perturbations are represented by a diffusion process whose paths encounter discontinuities in the manner required for the first-hit and occupation-time results is introduced without justification that it approximates the actual distribution of perturbations encountered by deployed SMoE models. This modeling choice is load-bearing for the almost-sure statements and the quantitative finite-time bounds; if the process is not Brownian or the local input geometry differs, the claims do not transfer.
- [Empirical evaluation] Empirical evaluation: the abstract states that smoothing 'enhances empirical performance' on language and vision tasks, yet the experiments are unspecified (no datasets, model sizes, baselines, metrics, or statistical details are referenced). This undermines assessment of whether the smoothing mechanism delivers the claimed gains and whether the overhead remains small in practice.
minor comments (2)
- Notation for Top-k routing and expert selection should be introduced with a clear definition early in the manuscript to avoid ambiguity when discussing tied experts and discontinuity orders.
- The abstract refers to 'explicit finite-time probability bounds' and 'occupation-time bounds'; the main text should include a dedicated statement of these bounds with equation numbers for easy reference.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of major revision. We address each major comment below with clarifications and proposed changes to the manuscript.
read point-by-point responses
-
Referee: [Stochastic analysis section] Stochastic analysis section (diffusion modeling of perturbations): the assumption that random input perturbations are represented by a diffusion process whose paths encounter discontinuities in the manner required for the first-hit and occupation-time results is introduced without justification that it approximates the actual distribution of perturbations encountered by deployed SMoE models. This modeling choice is load-bearing for the almost-sure statements and the quantitative finite-time bounds; if the process is not Brownian or the local input geometry differs, the claims do not transfer.
Authors: We acknowledge that the diffusion-process modeling of perturbations is introduced as a modeling choice without an extended discussion of its fidelity to real deployed perturbations. In the revised version we will add a new subsection in the stochastic analysis section that (i) motivates Brownian motion as a standard local approximation for small random input noise (with citations to prior neural-network perturbation literature), (ii) states the modeling assumptions explicitly, and (iii) discusses limitations and possible extensions to other Itô processes. This will make the scope and transferability of the almost-sure and finite-time claims transparent. revision: yes
-
Referee: [Empirical evaluation] Empirical evaluation: the abstract states that smoothing 'enhances empirical performance' on language and vision tasks, yet the experiments are unspecified (no datasets, model sizes, baselines, metrics, or statistical details are referenced). This undermines assessment of whether the smoothing mechanism delivers the claimed gains and whether the overhead remains small in practice.
Authors: The full manuscript contains a detailed experimental section (Section 5) that specifies the datasets, model scales, baselines, metrics, and statistical protocol. To address the referee’s concern about the abstract, we will revise the abstract to include a concise statement of the evaluation setting and main empirical outcomes, and we will add an explicit forward reference to Section 5. We will also ensure that all numerical claims about overhead and performance gains are accompanied by the corresponding experimental details in the main text. revision: yes
Circularity Check
No significant circularity; derivations are independent measure-theoretic and stochastic arguments
full rationale
The paper derives asymptotic volume estimates via measure-theoretic slicing and first-hit/occupation-time bounds via diffusion-process modeling of perturbations. These steps invoke standard tools from geometric measure theory and stochastic processes without any reduction to fitted parameters, self-citations, or author-specific ansatzes. The diffusion modeling choice is an explicit modeling assumption rather than a self-referential construction, leaving the central claims self-contained against external mathematical benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard properties of diffusion processes on Euclidean space and measure-theoretic slicing arguments hold without additional restrictions.
Reference graph
Works this paper leans on
-
[1]
URL https://openreview.net/forum? id=w1hwFUb_81. 9 Geometric and Stochastic Analysis of Discontinuities in Sparse Mixture-of-Experts Chen, Y .-C., Li, L., Yu, L., El Kholy, A., Ahmed, F., Gan, Z., Cheng, Y ., and Liu, J. Uniter: Universal image-text representation learning. In Vedaldi, A., Bischof, H., Brox, T., and Frahm, J.-M. (eds.),Computer Vision – E...
Pith/arXiv arXiv 2020
-
[2]
Training Compute-Optimal Large Language Models
URL https://openreview.net/forum? id=T26f9z2rEe. Han, X., Ren, T., Nguyen, T., Nguyen, K., Ghosh, J., and Ho, N. Designing robust transformers using robust kernel density estimation. In Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., and Levine, S. (eds.),Advances 10 Geometric and Stochastic Analysis of Discontinuities in Sparse Mixture-of-Expe...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1162/neco.1991.3.1.79 2023
-
[3]
cc/paper_files/paper/2019/file/ c74d97b01eae257e44aa9d5bade97baf-Paper
URL https://proceedings.neurips. cc/paper_files/paper/2019/file/ c74d97b01eae257e44aa9d5bade97baf-Paper. pdf. Mahoney, M. Large text compression benchmark,
2019
-
[4]
Efficient large-scale language model training on gpu clusters using megatron-lm,
URL https://mattmahoney.net/dc/ text.html. Merity, S., Xiong, C., Bradbury, J., and Socher, R. Pointer sentinel mixture models. InInternational Conference on Learning Representations, 2017. URL https:// openreview.net/forum?id=Byj72udxe. Muqeeth, M., Liu, H., and Raffel, C. Soft merging of experts with adaptive routing, 2024. URL https://arxiv. org/abs/23...
-
[5]
URL https://openreview.net/forum? id=B1ckMDqlg. Tan, H. and Bansal, M. Lxmert: Learning cross-modality encoder representations from transformers, 2019. URL https://arxiv.org/abs/1908.07490. Teo, R. and Nguyen, T. M. Unveiling the hidden structure of self-attention via kernel principal component analy- sis. InThe Thirty-eighth Annual Conference on Neural I...
arXiv 2019
-
[6]
cc/paper_files/paper/2017/file/ 3f5ee243547dee91fbd053c1c4a845aa-Paper
URL https://proceedings.neurips. cc/paper_files/paper/2017/file/ 3f5ee243547dee91fbd053c1c4a845aa-Paper. pdf. Venkateswara, H., Eusebio, J., Chakraborty, S., and Pan- chanathan, S. Deep hashing network for unsupervised do- main adaptation. In2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5385–5394,
2017
-
[7]
Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., and Bow- man, S
doi: 10.1109/CVPR.2017.572. Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., and Bow- man, S. GLUE: A multi-task benchmark and analysis plat- form for natural language understanding. In Linzen, T., Chrupała, G., and Alishahi, A. (eds.),Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and In- terpreting Neural Networks for NLP, pp. 353–35...
-
[8]
A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference
URL https://openreview.net/forum? id=4D0f16Vwc3. Warstadt, A., Singh, A., and Bowman, S. R. Neural network acceptability judgments.Transactions of the Association for Computational Linguistics, 7:625–641, 2019. doi: 10. 1162/tacl a 00290. URL https://aclanthology. org/Q19-1040/. Williams, A., Nangia, N., and Bowman, S. A broad- coverage challenge corpus f...
work page internal anchor Pith review doi:10.18653/v1/n18-1101 2019
-
[9]
findings-acl.71/
URL https://aclanthology.org/2022. findings-acl.71/. Zhou, Y ., Lei, T., Liu, H., Du, N., Huang, Y ., Zhao, V ., Dai, A. M., Le, Q. V ., Laudon, J., et al. Mixture-of- experts with expert choice routing.Advances in Neural Information Processing Systems, 35:7103–7114, 2022. 12 Geometric and Stochastic Analysis of Discontinuities in Sparse Mixture-of-Expert...
2022
-
[10]
The number of experts is smaller than the input dimension(M < D)
-
[11]
sgn(b)B b2 1 2 , α −sgn(a)B a2 1 2 , α # . Substituting back yields the exact formula λD Tϵ(Hm)∩B D(0, R) = ωD−1RD 2
The number of experts activated is positive and less than the full set of available expert(1≤k < M). 3.W g ∈R M×D has full row rank. RemarkA.1.On the space RM×D we define the product measure λM×D induced by the row measures λW (i) . If each λW (i) is absolutely continuous with respect to the Lebesgue measure λD or has the Lebesgue measure itself, it follo...
2011
-
[12]
Relate the measure of theϵ–thickeningλ D Tϵ(Γ(r) J )∩B R to the base measure of the sliceλ d Γ(r) J ∩B R
-
[13]
Derive the asymptotics of a single thickened slice using definition ofα J,r: λD Tϵ(Γ(r) J )∩B D(0, R) =ω D−r ωr αJ,r ϵr RD−r +O(ϵ rRD−r−1)
-
[14]
Estimate overlaps between distinct thickeningsT ϵ(Γ(r) J )andT ϵ(Γ(r) J ′ )forJ̸=J ′, showing they are bounded by O(ϵ r+1RD−r−1)
-
[15]
We are now ready to state and prove the main theorem
Assemble the contributions of all slicesJ∈ J r to obtain Ur(R) =λ D Tϵ(Γ(r))∩B D(0, R) , and then compare the casesr=nandr=mto deduce the asymptotic ratio Un(R) Um(R) . We are now ready to state and prove the main theorem. Theorem A.18(Ratio of ϵ-thickening of order-n discontinuity vs. ϵ-thickening of order-m discontinuity).Fix integers 1≤m, n < Dandϵ >0....
-
[16]
Derive the fiber decomposition of a sliceΓ (r) J ⊂S (r) J in the subspaceS (r) J
-
[17]
Establish explicit two–sided bounds for the measure of the ℓ∞–tube λD T (∞) ϵ (Γ(r) J )∩B R in terms of the subspace volumeλ d(Γ(r) J ∩B D(0, R))
-
[18]
Reduce to base volumes in the subspace by evaluating λd(Γ(r) J ∩B D(0, R)) and derive the asymptotic expansion of λD(T (∞) ϵ (Γ(r) J )∩B D(0, R))
-
[19]
Control overlaps between distinct tubes T (∞) ϵ (Γ(r) J ) and T (∞) ϵ (Γ(r) J ′ ) for J̸=J ′, showing their contribution is O(ϵ r+1RD−r−1)
-
[20]
walls” partitioning the space where one active and one inactive expert swap. Higher-order sets correspond to intersections of several such walls, forming “edges
Derive the asymptotic measure of the unionS J∈J r T (∞) ϵ (Γ(r) J ) for fixed r, and then compare Un(R) and Um(R) to obtain the asymptotic ratio Un(R) Um(R) . 31 Geometric and Stochastic Analysis of Discontinuities in Sparse Mixture-of-Experts Theorem A.19(Weighted union– ℓ∞ tube ratio for orders n vs. m).Fix integers 1≤m, n < D and ϵ >0 . For each r∈ {m,...
2024
-
[21]
This dataset contains 9,991 examples of dimension(3,224,224)and 7 classes
PACS (Li et al., 2017) comprises four domains: art, cartoons, photos, sketches. This dataset contains 9,991 examples of dimension(3,224,224)and 7 classes
2017
-
[22]
This dataset contains 10,729 examples of dimension(3,224,224)and 5 classes
VLCS (Fang et al., 2013) comprises photographic domains: Caltech101, LabelMe, SUN09, VOC2007. This dataset contains 10,729 examples of dimension(3,224,224)and 5 classes
2013
-
[23]
This dataset contains 15,588 examples of dimension(3,224,224)and 65 classes
Office-Home (Venkateswara et al., 2017) includes domains: art, clipart, product, real. This dataset contains 15,588 examples of dimension(3,224,224)and 65 classes
2017
-
[24]
This dataset contains 24,788 examples of dimension(3,224,224)and 10 classes
TerraIncognita (Beery et al., 2018) contains photographs of wild animals taken by camera traps at locations: L100, L38, L43, L46. This dataset contains 24,788 examples of dimension(3,224,224)and 10 classes
2018
-
[25]
This dataset contains 586,575 examples of size(3,224,224)and 345 classes
DomainNet (Peng et al., 2019) has six domains: clipart, infograph, painting, quickdraw, real, sketch. This dataset contains 586,575 examples of size(3,224,224)and 345 classes. We follow the standard DomainBed evaluation protocol using train-domain validation. For each test domain, we train on the remaining domains and use the left-out domain for validatio...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.