Compositionality Emerges in a Narrow Depth-Connectivity Regime: Architecture Constraints and Solution Manifolds
Pith reviewed 2026-06-26 18:21 UTC · model grok-4.3
The pith
Compositionality in neural networks arises only in a narrow depth and specific sparse connectivity regime.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
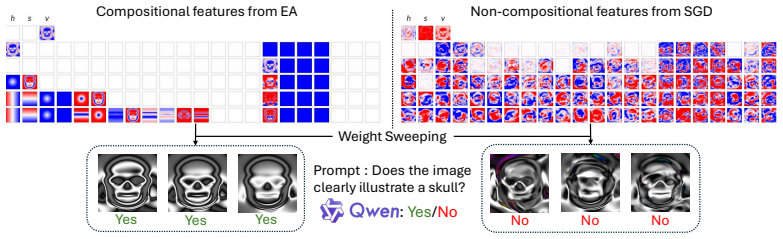
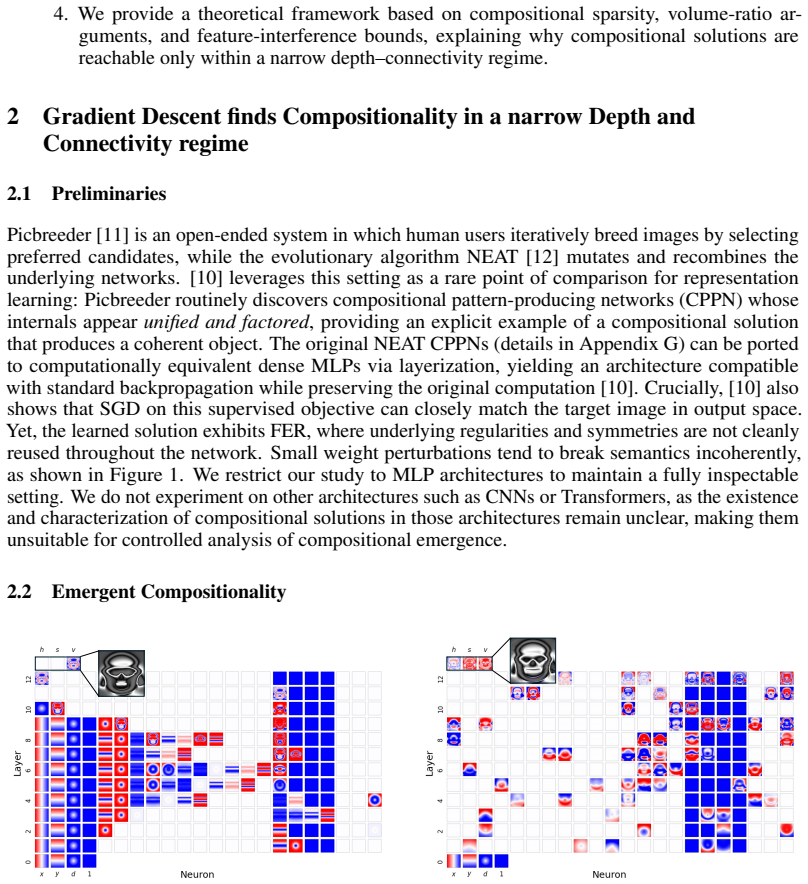
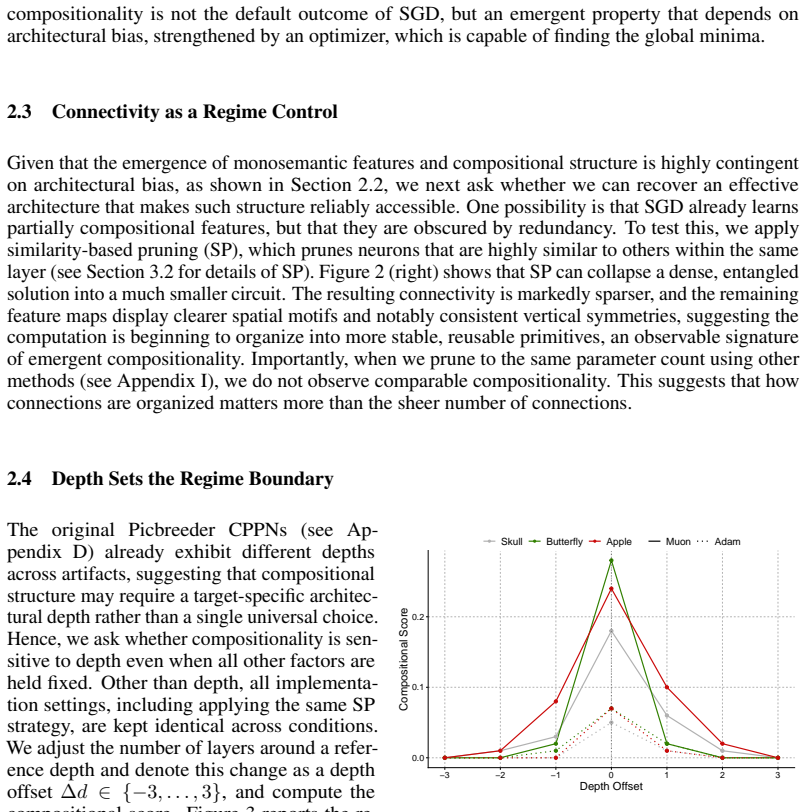
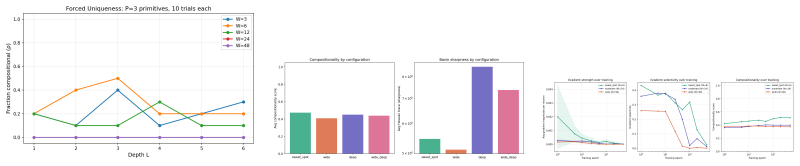
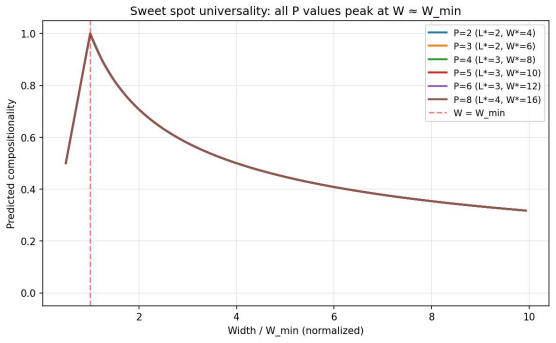
Compositionality emerges in a narrow connectivity-depth sweet spot. Along the connectivity axis it appears only in certain specifically sparse networks and depends on which connections remain rather than on weight sparsity alone. Along the depth axis it emerges inside a narrow, target-dependent regime, peaking at particular depths while both shallower and deeper networks fail. When either condition is violated, gradient descent silently converges to fractured solutions. The findings are supported by similarity-based pruning to recover compositional connectivity, a heuristic depth predictor, and a theoretical framework of compositional sparsity, volume-ratio arguments, and feature-interferenc
What carries the argument
The narrow depth-connectivity regime that constrains reachable solution manifolds, identified through compositional sparsity, volume-ratio arguments, and feature-interference bounds.
If this is right
- Gradient descent reaches compositional solutions only when both the depth and the specific connectivity pattern satisfy the narrow regime.
- Violating either the depth or connectivity condition causes convergence to fractured rather than compositional solutions.
- Similarity-based pruning can recover the connectivity pattern that permits compositional solutions.
- A heuristic depth predictor can locate the depths at which compositionality is most likely for a given target.
- The theoretical framework of compositional sparsity, volume ratios, and feature-interference bounds accounts for the limited reachability of compositional manifolds.
Where Pith is reading between the lines
- The regime may explain why standard architectures trained end-to-end often fail to exhibit strong compositionality even when the task admits it.
- Task-specific depth selection or connectivity search could be used to steer training toward compositional solutions without changing the optimizer.
- Different tasks likely possess different optimal depths inside the regime, requiring per-target tuning rather than a universal depth choice.
Load-bearing premise
The observed failure to reach compositional solutions outside the narrow regime is caused by architecture constraints on depth and specific connectivity rather than by optimization dynamics, data distribution, or initialization.
What would settle it
Demonstrating compositional internal structure in networks whose depth or connectivity lies outside the identified narrow regime would falsify the central claim.
Figures






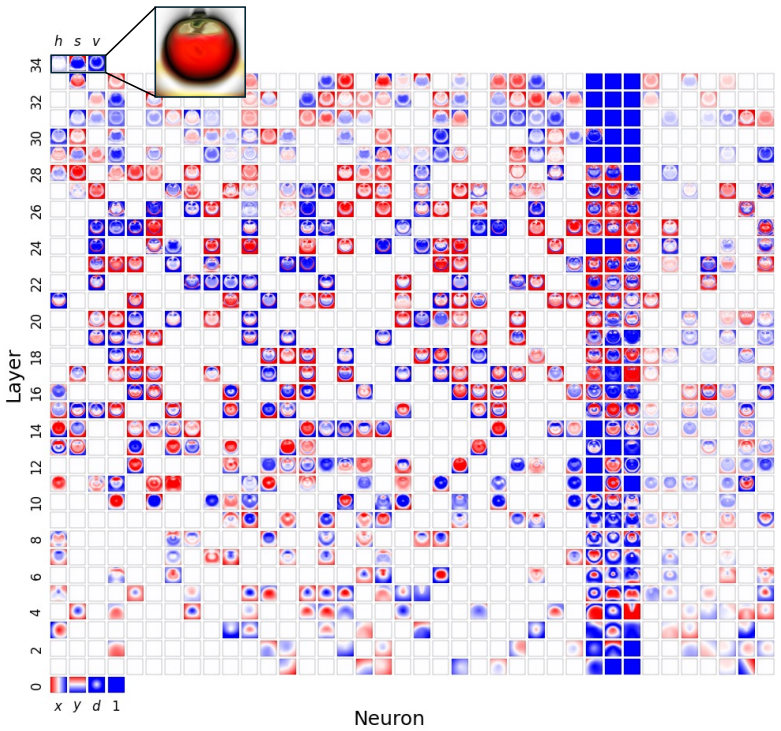

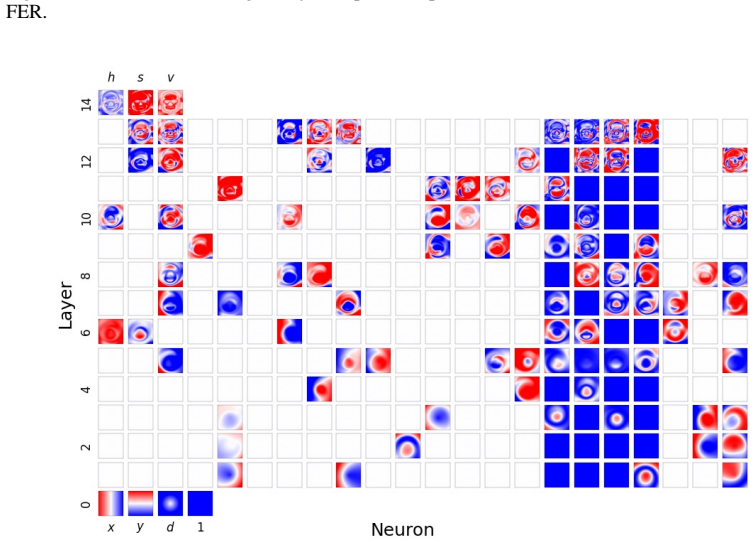


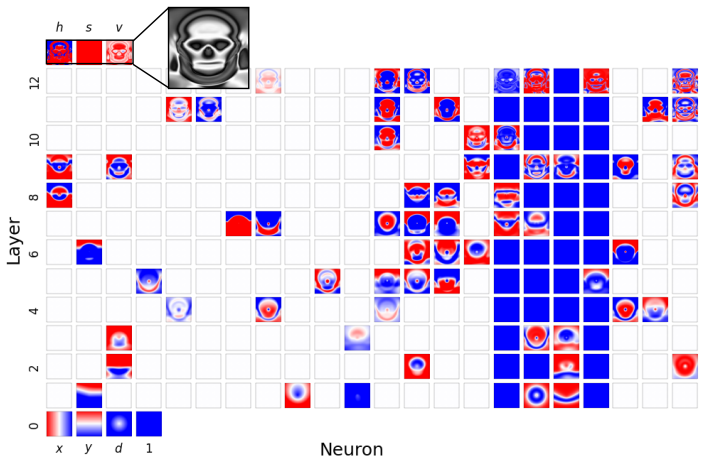


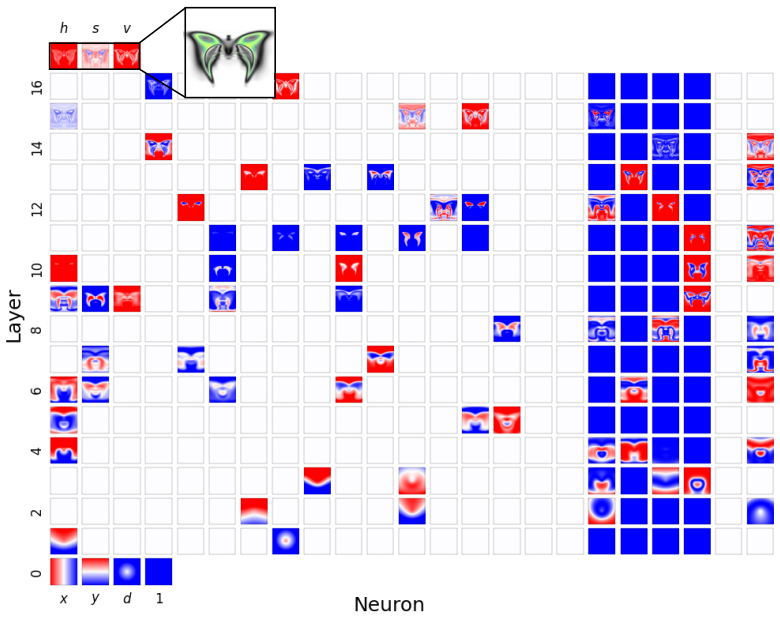
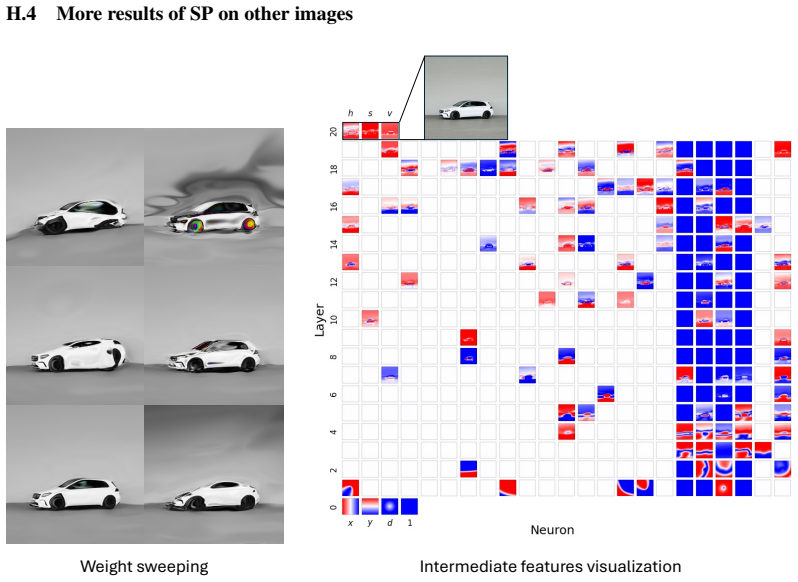
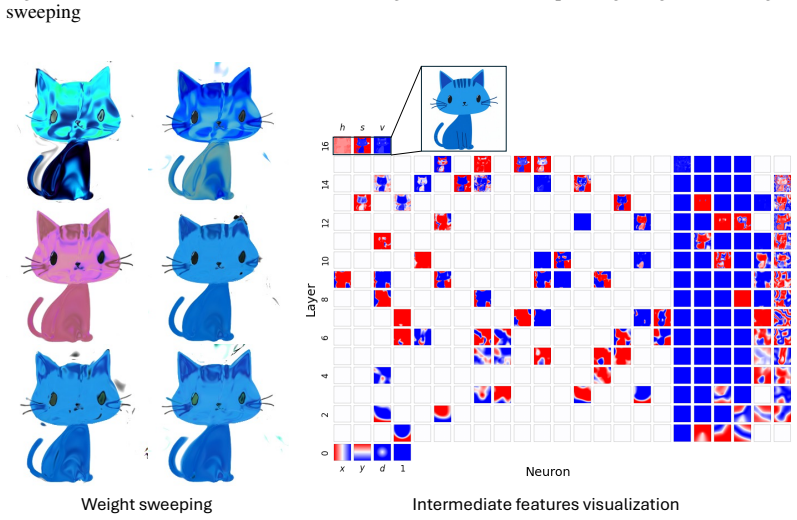
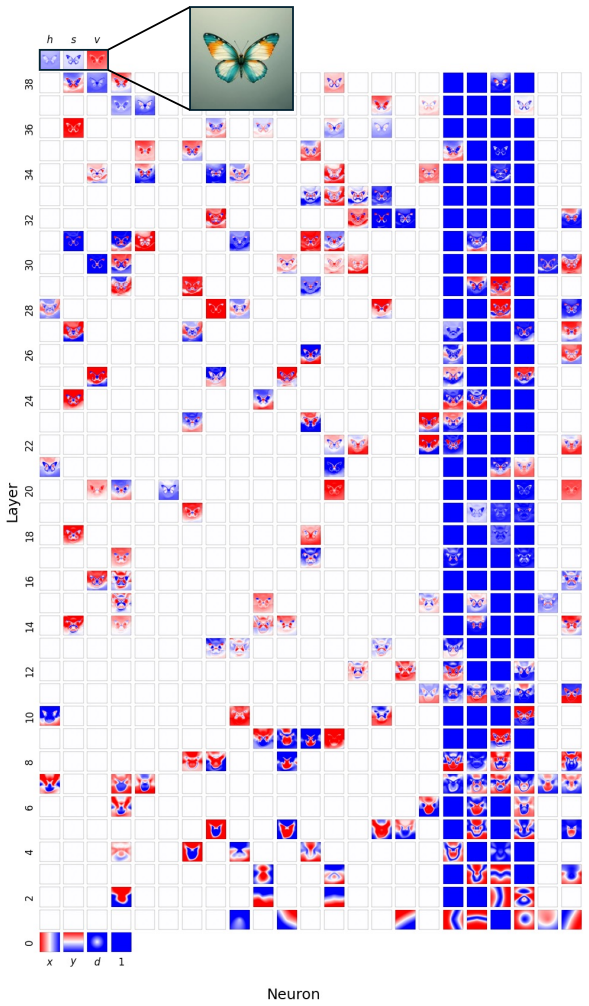
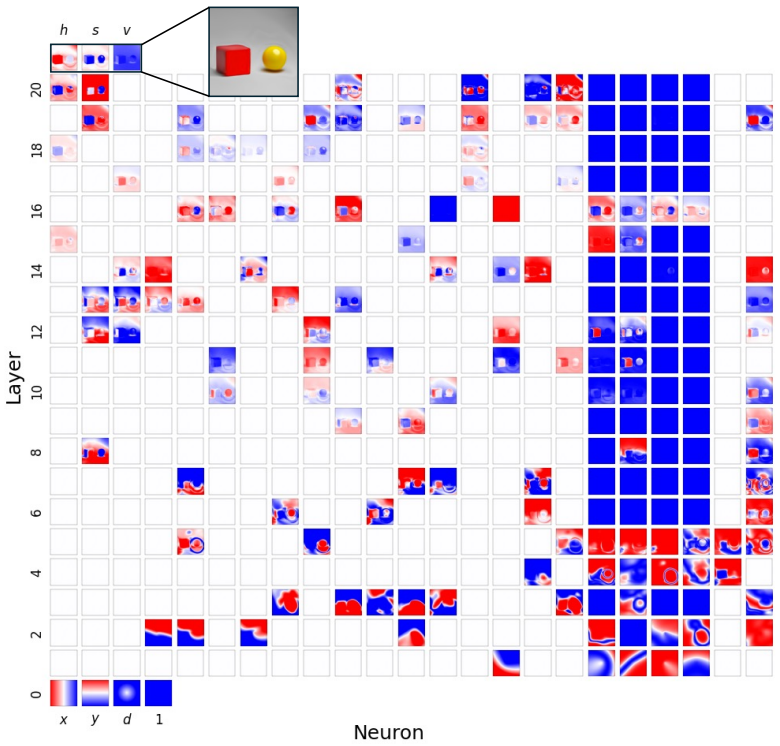

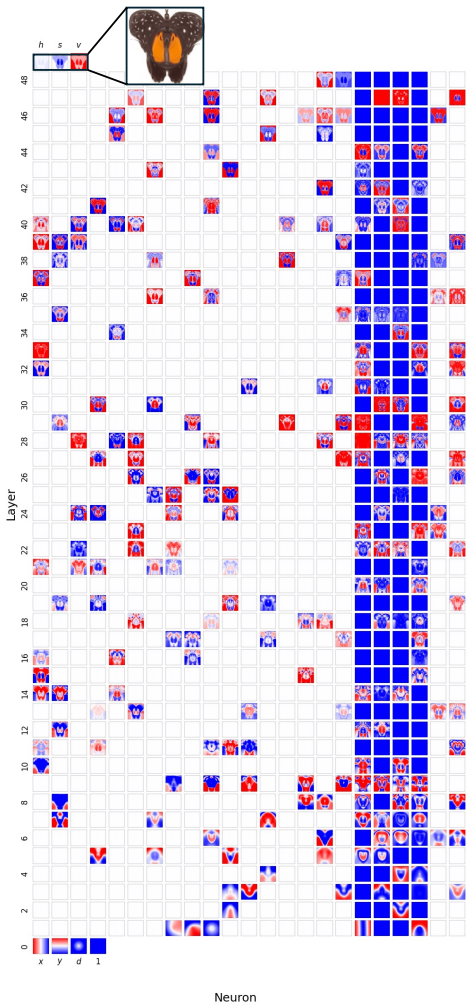


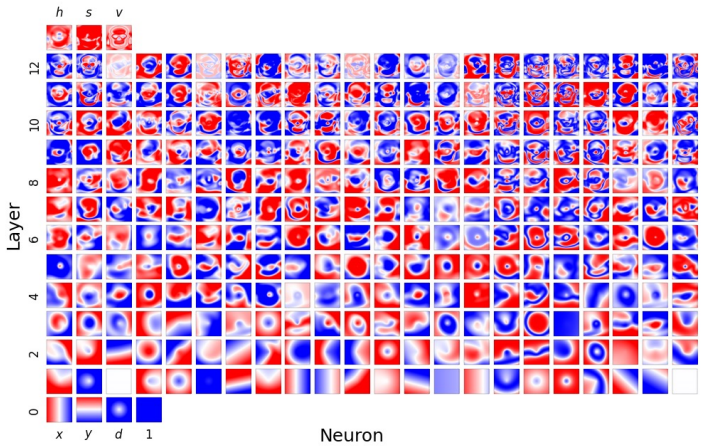
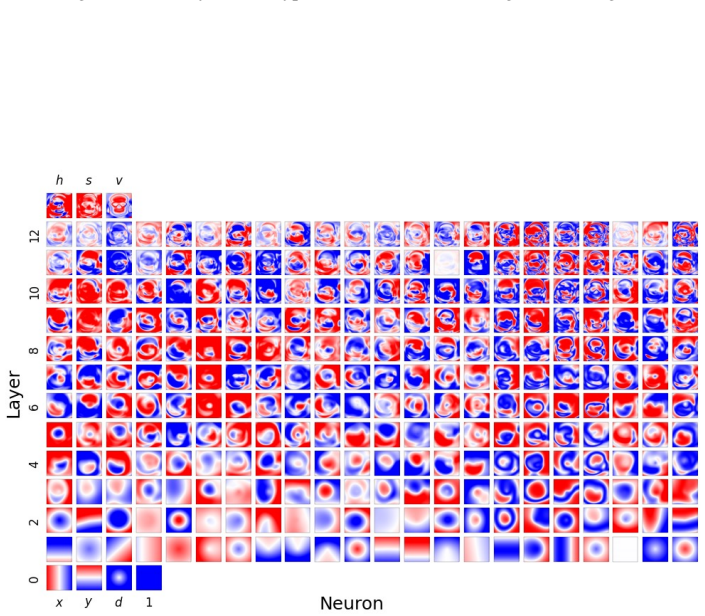

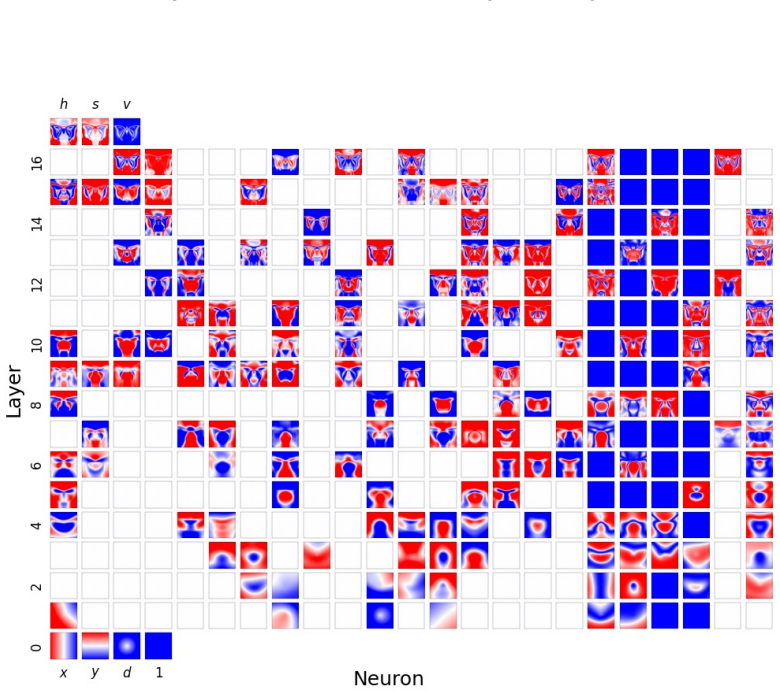



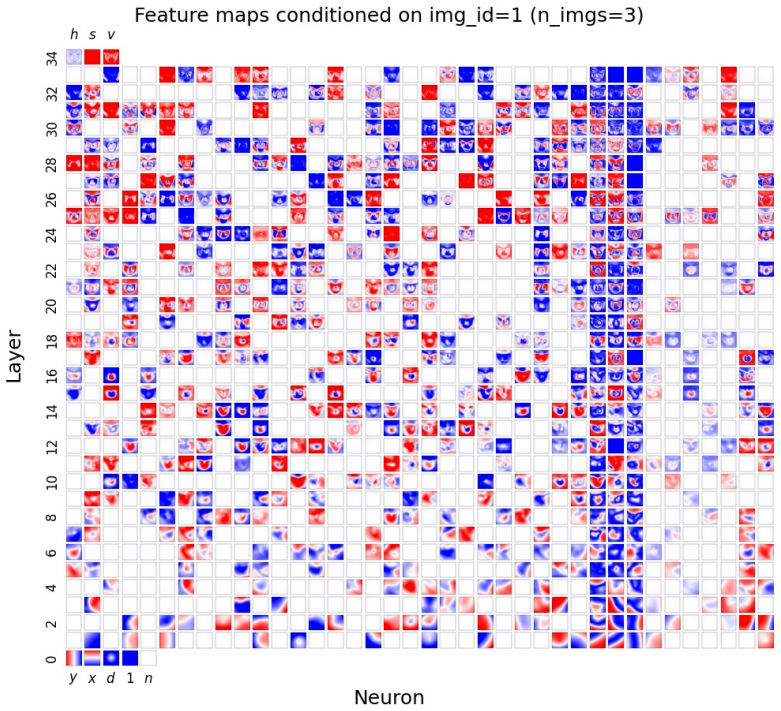
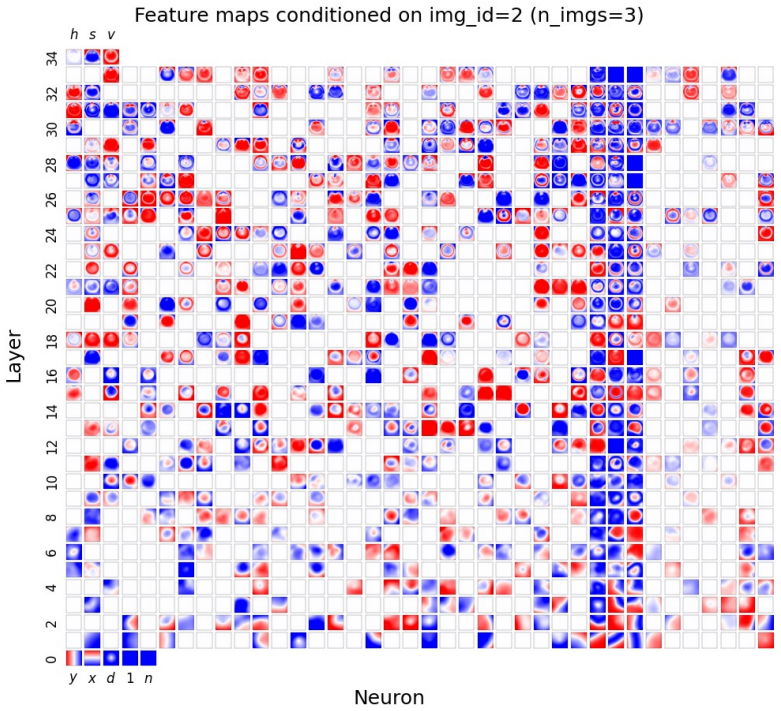
read the original abstract
Compositionality is believed to be the foundation for generalization, enabling models to reuse meaningful primitives in novel combinations. Yet, models trained with standard gradient-based optimization rarely, and often only weakly, exhibit compositional internal structure, and it remains unclear how or why such compositionality forms. In this work, we show that compositionality emerges in a narrow connectivity-depth sweet spot. Along the connectivity axis, compositionality only appears in some specifically sparse networks, heavily depends on which connections remain rather than on weights' sparsity alone. Along the depth axis, compositionality emerges within a narrow, target-dependent regime, peaking at specific depths, while both shallower and deeper networks fail. When either the depth or connectivity condition is violated, gradient descent silently converges to fractured solutions rather than compositional ones. To discover and exploit this emergence, we introduce (i) similarity-based pruning (SP) to recover compositional connectivity and (ii) a heuristic depth predictor to estimate where compositionality is most likely to appear. Finally, we support these empirical findings with a theoretical framework based on compositional sparsity, volume-ratio arguments, and feature-interference bounds, explaining why compositional solutions are reachable only in a narrow depth-connectivity regime.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that compositionality emerges in neural networks only within a narrow depth-connectivity regime: specific sparse connectivity patterns (not mere weight sparsity) along the connectivity axis, and a narrow target-dependent depth range (peaking at specific depths, failing for shallower or deeper nets) along the depth axis. Outside this regime, gradient descent converges to fractured non-compositional solutions. The authors introduce similarity-based pruning (SP) to recover compositional connectivity and a heuristic depth predictor, and support the findings with a theoretical framework based on compositional sparsity, volume-ratio arguments, and feature-interference bounds.
Significance. If the central claim holds, the work identifies architecture constraints that control reachability of compositional solutions under gradient descent, offering both an explanation for why such structure is rare and practical methods (SP and depth heuristic) to induce it. The empirical discovery of the narrow regime combined with the theoretical framing could guide architecture design for compositional generalization tasks.
major comments (2)
- [Theoretical Framework] Theoretical Framework section: the compositional sparsity, volume-ratio arguments, and feature-interference bounds are invoked to explain why compositional solutions are reachable only inside the narrow regime. However, these primarily bound manifold measure or interference; they do not derive that gradient-descent trajectories have no connecting paths to compositional solutions outside the regime or that the dynamics are forced into fractured attractors. The 'unreachability' direction therefore rests on extrapolation from observed empirical failures rather than a direct consequence of the bounds.
- [Experiments] Empirical results on depth axis (abstract and §Experiments): the claim that both shallower and deeper networks fail to reach compositional solutions is central, yet the manuscript does not report controls that isolate architecture constraints from optimization dynamics, data distribution, or initialization effects. Without such isolation, the narrow-regime conclusion remains vulnerable to the alternative that the failures are optimization artifacts rather than manifold unreachability.
minor comments (2)
- The description of similarity-based pruning (SP) would benefit from an explicit algorithm box or pseudocode to clarify how 'which connections remain' are selected versus random or magnitude-based sparsity.
- Notation for 'fractured solutions' is used without a formal definition; a short paragraph relating it to the volume-ratio or interference quantities would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below, clarifying the scope of our theoretical results and committing to additional experimental controls where appropriate.
read point-by-point responses
-
Referee: [Theoretical Framework] Theoretical Framework section: the compositional sparsity, volume-ratio arguments, and feature-interference bounds are invoked to explain why compositional solutions are reachable only inside the narrow regime. However, these primarily bound manifold measure or interference; they do not derive that gradient-descent trajectories have no connecting paths to compositional solutions outside the regime or that the dynamics are forced into fractured attractors. The 'unreachability' direction therefore rests on extrapolation from observed empirical failures rather than a direct consequence of the bounds.
Authors: We agree that the theoretical framework (compositional sparsity, volume-ratio arguments, and feature-interference bounds) establishes that compositional solution manifolds have larger relative measure and lower interference inside the identified regime, thereby making such solutions more accessible under gradient descent. The framework does not, however, derive a rigorous statement that no connecting paths exist in parameter space outside the regime or that the dynamics are provably trapped in fractured attractors. The unreachability claim outside the regime is therefore supported primarily by the empirical evidence of consistent convergence to fractured solutions across multiple depths, connectivities, and tasks. In revision we will explicitly distinguish the theoretical support for preferential reachability inside the regime from the empirical observation of unreachability outside it. revision: partial
-
Referee: [Experiments] Empirical results on depth axis (abstract and §Experiments): the claim that both shallower and deeper networks fail to reach compositional solutions is central, yet the manuscript does not report controls that isolate architecture constraints from optimization dynamics, data distribution, or initialization effects. Without such isolation, the narrow-regime conclusion remains vulnerable to the alternative that the failures are optimization artifacts rather than manifold unreachability.
Authors: We acknowledge that the current experiments do not include exhaustive ablations that fully isolate depth and connectivity constraints from optimizer hyperparameters, initialization distributions, or data variations. While we observe the same narrow-regime pattern across multiple random seeds, datasets, and architectures, additional targeted controls would strengthen the architectural interpretation. We will add such controls (varying learning-rate schedules, initialization scales, and data subsampling while fixing depth/connectivity) in the revised manuscript. revision: yes
Circularity Check
No circularity detected; derivation remains self-contained
full rationale
The provided abstract and context describe empirical results on compositionality in a narrow depth-connectivity regime, supported by a theoretical framework of compositional sparsity, volume-ratio arguments, and feature-interference bounds. No equations, self-citations, fitted parameters renamed as predictions, or self-definitional steps are exhibited in the text. The theory is presented as explanatory support for the observed regime rather than reducing to the inputs by construction. Without quotable reductions matching the enumerated patterns, the central claim does not collapse into tautology or self-reference.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2505.00661 , year=
Andrew K Lampinen, Arslan Chaudhry, Stephanie CY Chan, Cody Wild, Diane Wan, Alex Ku, Jörg Bornschein, Razvan Pascanu, Murray Shanahan, and James L McClelland. On the generalization of language models from in-context learning and finetuning: a controlled study. arXiv preprint arXiv:2505.00661, 2025
-
[2]
Lukas Berglund, Meg Tong, Max Kaufmann, Mikita Balesni, Asa Cooper Stickland, Tomasz Korbak, and Owain Evans. The reversal curse: Llms trained on" a is b" fail to learn" b is a". arXiv preprint arXiv:2309.12288, 2023
-
[3]
Visually prompted benchmarks are surprisingly fragile.ArXiv, abs/2512.17875, 2025
Haiwen Feng, Long Lian, Lisa Dunlap, Jiahao Shu, Xudong Wang, Renhao Wang, Trevor Darrell, Alane Suhr, and Angjoo Kanazawa. Visually prompted benchmarks are surprisingly fragile.ArXiv, abs/2512.17875, 2025
-
[4]
Mingjie Xu, Jinpeng Chen, Yuzhi Zhao, Jason Chun Lok Li, Yue Qiu, Zekang Du, Mengyang Wu, Pingping Zhang, Kun Li, Hongzheng Yang, et al. Vp-bench: A comprehensive benchmark for visual prompting in multimodal large language models.arXiv preprint arXiv:2511.11438, 2025
-
[5]
T2i-compbench: A compre- hensive benchmark for open-world compositional text-to-image generation.Advances in Neural Information Processing Systems, 36:78723–78747, 2023
Kaiyi Huang, Kaiyue Sun, Enze Xie, Zhenguo Li, and Xihui Liu. T2i-compbench: A compre- hensive benchmark for open-world compositional text-to-image generation.Advances in Neural Information Processing Systems, 36:78723–78747, 2023
2023
-
[6]
T2i- compbench++: An enhanced and comprehensive benchmark for compositional text-to-image generation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Kaiyi Huang, Chengqi Duan, Kaiyue Sun, Enze Xie, Zhenguo Li, and Xihui Liu. T2i- compbench++: An enhanced and comprehensive benchmark for compositional text-to-image generation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[7]
Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
2023
-
[8]
arXiv preprint arXiv:2512.16853 , year=
Amita Kamath, Kai-Wei Chang, Ranjay Krishna, Luke Zettlemoyer, Yushi Hu, and Marjan Ghazvininejad. Geneval 2: Addressing benchmark drift in text-to-image evaluation.arXiv preprint arXiv:2512.16853, 2025
-
[9]
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, et al. Toy models of superposition.arXiv preprint arXiv:2209.10652, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [10]
-
[11]
Picbreeder: evolving pictures collaboratively online
Jimmy Secretan, Nicholas Beato, David B D Ambrosio, Adelein Rodriguez, Adam Campbell, and Kenneth O Stanley. Picbreeder: evolving pictures collaboratively online. InProceedings of the SIGCHI conference on human factors in computing systems, pages 1759–1768, 2008. 10
2008
-
[12]
Efficient evolution of neural network topologies
Kenneth O Stanley and Risto Miikkulainen. Efficient evolution of neural network topologies. In Proceedings of the 2002 Congress on Evolutionary Computation. CEC’02 (Cat. No. 02TH8600), volume 2, pages 1757–1762. IEEE, 2002
2002
-
[13]
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
Jonathan Frankle and Michael Carbin. The lottery ticket hypothesis: Finding sparse, trainable neural networks.arXiv preprint arXiv:1803.03635, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
A Simple and Effective Pruning Approach for Large Language Models
Mingjie Sun, Zhuang Liu, Anna Bair, and J Zico Kolter. A simple and effective pruning approach for large language models.arXiv preprint arXiv:2306.11695, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Llm-pruner: On the structural pruning of large language models.Advances in neural information processing systems, 36:21702–21720, 2023
Xinyin Ma, Gongfan Fang, and Xinchao Wang. Llm-pruner: On the structural pruning of large language models.Advances in neural information processing systems, 36:21702–21720, 2023
2023
-
[16]
David A. Danhofer, Davide D’Ascenzo, Rafael Dubach, and Tomaso A. Poggio. Position: A theory of deep learning must include compositional sparsity.ArXiv, abs/2507.02550, 2025
-
[17]
On large-batch training for deep learning: Generalization gap and sharp minima
Nitish Shirish Keskar, Dheevatsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy, and Ping Tak Peter Tang. On large-batch training for deep learning: Generalization gap and sharp minima. InInternational Conference on Learning Representations, 2017
2017
-
[18]
Three Factors Influencing Minima in SGD
Stanisław Jastrz˛ ebski, Zachary Kenton, Devansh Arpit, Nicolas Ballas, Asja Fischer, Yoshua Bengio, and Amos Storkey. Three factors influencing minima in sgd.arXiv preprint arXiv:1711.04623, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[19]
Sharpness-aware min- imization for efficiently improving generalization
Pierre Foret, Ariel Kleiner, Hossein Mobahi, and Behnam Neyshabur. Sharpness-aware min- imization for efficiently improving generalization. InInternational Conference on Learning Representations
-
[20]
Gintare Karolina Dziugaite and Daniel M Roy. Computing nonvacuous generalization bounds for deep (stochastic) neural networks with many more parameters than training data.arXiv preprint arXiv:1703.11008, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
Muon: An optimizer for hidden layers in neural networks, 2024
Keller Jordan, Yuchen Jin, Vlado Boza, Jiacheng You, Franz Cesista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks, 2024
2024
-
[22]
The MIT press, 2017
Jonas Peters, Dominik Janzing, and Bernhard Schölkopf.Elements of causal inference: founda- tions and learning algorithms. The MIT press, 2017
2017
-
[23]
Can subnetwork structure be the key to out-of-distribution generalization? InInternational conference on machine learning, pages 12356–12367
Dinghuai Zhang, Kartik Ahuja, Yilun Xu, Yisen Wang, and Aaron Courville. Can subnetwork structure be the key to out-of-distribution generalization? InInternational conference on machine learning, pages 12356–12367. PMLR, 2021
2021
-
[24]
A rational analysis of rule-based concept learning.Cognitive science, 32(1):108–154, 2008
Noah D Goodman, Joshua B Tenenbaum, Jacob Feldman, and Thomas L Griffiths. A rational analysis of rule-based concept learning.Cognitive science, 32(1):108–154, 2008
2008
-
[25]
Categorial compositionality: A category theory explana- tion for the systematicity of human cognition.PLoS computational biology, 6(7):e1000858, 2010
Steven Phillips and William H Wilson. Categorial compositionality: A category theory explana- tion for the systematicity of human cognition.PLoS computational biology, 6(7):e1000858, 2010
2010
-
[26]
Reduce, reuse, recycle: Compositional generation with energy-based diffusion models and mcmc
Yilun Du, Conor Durkan, Robin Strudel, Joshua B Tenenbaum, Sander Dieleman, Rob Fergus, Jascha Sohl-Dickstein, Arnaud Doucet, and Will Sussman Grathwohl. Reduce, reuse, recycle: Compositional generation with energy-based diffusion models and mcmc. InInternational conference on machine learning, pages 8489–8510. PMLR, 2023
2023
-
[27]
Sam Spilsbury and Alexander Ilin. Compositional generalization in grounded language learning via induced model sparsity.arXiv preprint arXiv:2207.02518, 2022
-
[28]
Ablating concepts in text-to-image diffusion models
Nupur Kumari, Bingliang Zhang, Sheng-Yu Wang, Eli Shechtman, Richard Zhang, and Jun-Yan Zhu. Ablating concepts in text-to-image diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22691–22702, 2023
2023
-
[29]
Eyes wide shut? exploring the visual shortcomings of multimodal llms
Shengbang Ton g, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. Eyes wide shut? exploring the visual shortcomings of multimodal llms. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9568–9578, 2024. 11
2024
-
[30]
Does clip bind concepts? probing compositionality in large image models
Martha Lewis, Nihal Nayak, Peilin Yu, Jack Merullo, Qinan Yu, Stephen Bach, and Ellie Pavlick. Does clip bind concepts? probing compositionality in large image models. InFindings of the Association for Computational Linguistics: EACL 2024, pages 1487–1500, 2024
2024
-
[31]
Tian Yun, Usha Bhalla, Ellie Pavlick, and Chen Sun. Do vision-language pretrained models learn primitive concepts.arXiv preprint arXiv:2203.17271, 3(5):6, 2022
-
[32]
Break it down: Evidence for structural compositionality in neural networks.Advances in Neural Information Processing Systems, 36:42623–42660, 2023
Michael Lepori, Thomas Serre, and Ellie Pavlick. Break it down: Evidence for structural compositionality in neural networks.Advances in Neural Information Processing Systems, 36:42623–42660, 2023
2023
-
[33]
Com- positional generalization from first principles.Advances in Neural Information Processing Systems, 36:6941–6960, 2023
Thaddäus Wiedemer, Prasanna Mayilvahanan, Matthias Bethge, and Wieland Brendel. Com- positional generalization from first principles.Advances in Neural Information Processing Systems, 36:6941–6960, 2023
2023
-
[34]
Optimal brain damage.Advances in neural information processing systems, 2, 1989
Yann LeCun, John Denker, and Sara Solla. Optimal brain damage.Advances in neural information processing systems, 2, 1989
1989
-
[35]
Optimal brain surgeon and general network pruning
Babak Hassibi, David G Stork, and Gregory J Wolff. Optimal brain surgeon and general network pruning. InIEEE international conference on neural networks, pages 293–299. IEEE, 1993
1993
-
[36]
Learning efficient convolutional networks through network slimming
Zhuang Liu, Jianguo Li, Zhiqiang Shen, Gao Huang, Shoumeng Yan, and Changshui Zhang. Learning efficient convolutional networks through network slimming. InProceedings of the IEEE international conference on computer vision, pages 2736–2744, 2017
2017
-
[37]
Depgraph: Towards any structural pruning
Gongfan Fang, Xinyin Ma, Mingli Song, Michael Bi Mi, and Xinchao Wang. Depgraph: Towards any structural pruning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16091–16101, 2023
2023
-
[38]
Gradient-free structured pruning with unla- beled data
Azade Nova, Hanjun Dai, and Dale Schuurmans. Gradient-free structured pruning with unla- beled data. InInternational Conference on Machine Learning, pages 26326–26341. PMLR, 2023
2023
-
[39]
Learning both weights and connections for efficient neural network.Advances in neural information processing systems, 28, 2015
Song Han, Jeff Pool, John Tran, and William Dally. Learning both weights and connections for efficient neural network.Advances in neural information processing systems, 28, 2015
2015
-
[40]
Why random pruning is all we need to start sparse
Advait Harshal Gadhikar, Sohom Mukherjee, and Rebekka Burkholz. Why random pruning is all we need to start sparse. InInternational Conference on Machine Learning, pages 10542–10570. PMLR, 2023
2023
-
[41]
Sparsity may cry: Let us fail (current) sparse neural networks together! InThe Eleventh International Conference on Learning Representations
Shiwei Liu, Tianlong Chen, Zhenyu Zhang, Xuxi Chen, Tianjin Huang, AJAY KUMAR JAISW AL, and Zhangyang Wang. Sparsity may cry: Let us fail (current) sparse neural networks together! InThe Eleventh International Conference on Learning Representations
-
[42]
Coreset-based neural network compression
Abhimanyu Dubey, Moitreya Chatterjee, and Narendra Ahuja. Coreset-based neural network compression. InProceedings of the European Conference on Computer Vision (ECCV), pages 454–470, 2018
2018
-
[43]
Pruning convolutional neural networks for resource efficient inference
Pavlo Molchanov, Stephen Tyree, Tero Karras, Timo Aila, and Jan Kautz. Pruning convolutional neural networks for resource efficient inference. InInternational Conference on Learning Representations, 2017
2017
-
[44]
Rethinking the role of scale for in-context learning: An interpretability-based case study at 66 billion scale
Hritik Bansal, Karthik Gopalakrishnan, Saket Dingliwal, Sravan Bodapati, Katrin Kirchhoff, and Dan Roth. Rethinking the role of scale for in-context learning: An interpretability-based case study at 66 billion scale. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11833–11856, 2023
2023
-
[45]
Deja vu: Contextual sparsity for efficient llms at inference time
Zichang Liu, Jue Wang, Tri Dao, Tianyi Zhou, Binhang Yuan, Zhao Song, Anshumali Shrivas- tava, Ce Zhang, Yuandong Tian, Christopher Re, et al. Deja vu: Contextual sparsity for efficient llms at inference time. InInternational Conference on Machine Learning, pages 22137–22176. PMLR, 2023
2023
-
[46]
Neurons in large language models: Dead, n-gram, positional
Elena V oita, Javier Ferrando, and Christoforos Nalmpantis. Neurons in large language models: Dead, n-gram, positional. InFindings of the Association for Computational Linguistics: ACL 2024, pages 1288–1301, 2024. 12
2024
-
[47]
Movement pruning: Adaptive sparsity by fine-tuning.Advances in neural information processing systems, 33:20378–20389, 2020
Victor Sanh, Thomas Wolf, and Alexander Rush. Movement pruning: Adaptive sparsity by fine-tuning.Advances in neural information processing systems, 33:20378–20389, 2020
2020
-
[48]
Soft threshold weight reparameterization for learnable sparsity
Aditya Kusupati, Vivek Ramanujan, Raghav Somani, Mitchell Wortsman, Prateek Jain, Sham Kakade, and Ali Farhadi. Soft threshold weight reparameterization for learnable sparsity. In International conference on machine learning, pages 5544–5555. PMLR, 2020
2020
-
[49]
Rethinking the value of network pruning
Zhuang Liu, Mingjie Sun, Tinghui Zhou, Gao Huang, and Trevor Darrell. Rethinking the value of network pruning. InInternational Conference on Learning Representations, 2019
2019
-
[50]
A three-regime model of network pruning
Yefan Zhou, Yaoqing Yang, Arin Chang, and Michael W Mahoney. A three-regime model of network pruning. InInternational Conference on Machine Learning, pages 42790–42809. PMLR, 2023
2023
-
[51]
Comparing rewinding and fine-tuning in neural network pruning
Alex Renda, Jonathan Frankle, and Michael Carbin. Comparing rewinding and fine-tuning in neural network pruning. InInternational Conference on Learning Representations, 2020
2020
-
[52]
Concepts and compositionality: in search of the brain’s language of thought.Annual review of psychology, 71(1):273–303, 2020
Steven M Frankland and Joshua D Greene. Concepts and compositionality: in search of the brain’s language of thought.Annual review of psychology, 71(1):273–303, 2020
2020
-
[53]
Compositional clustering in task structure learning
Nicholas T Franklin and Michael J Frank. Compositional clustering in task structure learning. PLoS computational biology, 14(4):e1006116, 2018
2018
-
[54]
Compositional visual generation with composable diffusion models
Nan Liu, Shuang Li, Yilun Du, Antonio Torralba, and Joshua B Tenenbaum. Compositional visual generation with composable diffusion models. InEuropean conference on computer vision, pages 423–439. Springer, 2022
2022
-
[55]
Unsupervised learning of compositional energy concepts.Advances in Neural Information Processing Systems, 34:15608–15620, 2021
Yilun Du, Shuang Li, Yash Sharma, Josh Tenenbaum, and Igor Mordatch. Unsupervised learning of compositional energy concepts.Advances in Neural Information Processing Systems, 34:15608–15620, 2021
2021
-
[56]
Guangyue Xu, Parisa Kordjamshidi, and Joyce Chai. Prompting large pre-trained vision- language models for compositional concept learning.arXiv preprint arXiv:2211.05077, 2022
-
[57]
Mert Yuksekgonul, Federico Bianchi, Pratyusha Kalluri, Dan Jurafsky, and James Zou. When and why vision-language models behave like bags-of-words, and what to do about it?arXiv preprint arXiv:2210.01936, 2022
-
[58]
Emanuele Bugliarello and Desmond Elliott. The role of syntactic planning in compositional image captioning.arXiv preprint arXiv:2101.11911, 2021
-
[59]
Colin Conwell and Tomer Ullman. Testing relational understanding in text-guided image generation.arXiv preprint arXiv:2208.00005, 2022
-
[60]
arXiv preprint arXiv:2212.10015 (2022)
Tejas Gokhale, Hamid Palangi, Besmira Nushi, Vibhav Vineet, Eric Horvitz, Ece Kamar, Chitta Baral, and Yezhou Yang. Benchmarking spatial relationships in text-to-image generation.arXiv preprint arXiv:2212.10015, 2022
-
[61]
Winoground: Probing vision and language models for visio-linguistic compositionality
Tristan Thrush, Ryan Jiang, Max Bartolo, Amanpreet Singh, Adina Williams, Douwe Kiela, and Candace Ross. Winoground: Probing vision and language models for visio-linguistic compositionality. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5238–5248, 2022
2022
-
[62]
Measuring compositionality in representation learning
Jacob Andreas, Marco Baroni, Alexis Conneau, Douwe Kiela, Holger Schwenk, Loïc Barrault, Antoine Bordes, Jacob Devlin, Alona Fyshe, Leila Wehbe, et al. Measuring compositionality in representation learning. InInternational conference on learning representations, volume 375, pages 2227–2237. Association for Computational Linguistics, 2019
2019
-
[63]
Generalization without systematicity: On the compositional skills of sequence-to-sequence recurrent networks
Brenden Lake and Marco Baroni. Generalization without systematicity: On the compositional skills of sequence-to-sequence recurrent networks. InInternational conference on machine learning, pages 2873–2882. PMLR, 2018. 13
2018
-
[64]
Clevr: A diagnostic dataset for compositional language and elementary visual reasoning
Justin Johnson, Bharath Hariharan, Laurens Van Der Maaten, Li Fei-Fei, C Lawrence Zitnick, and Ross Girshick. Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2901–2910, 2017
2017
-
[65]
Lukas Schott, Julius V on Kügelgen, Frederik Träuble, Peter Gehler, Chris Russell, Matthias Bethge, Bernhard Schölkopf, Francesco Locatello, and Wieland Brendel. Visual representation learning does not generalize strongly within the same domain.arXiv preprint arXiv:2107.08221, 2021
-
[66]
Benchmark- ing compositionality with formal languages
Josef Valvoda Naomi Saphra Jonathan Rawski and Adina Williams Ryan Cotterell. Benchmark- ing compositionality with formal languages. 2022
2022
-
[67]
Conceptmix: A compositional image generation benchmark with controllable difficulty.Advances in Neural Information Processing Systems, 37:86004–86047, 2024
Xindi Wu, Dingli Yu, Yangsibo Huang, Olga Russakovsky, and Sanjeev Arora. Conceptmix: A compositional image generation benchmark with controllable difficulty.Advances in Neural Information Processing Systems, 37:86004–86047, 2024
2024
-
[68]
Importance estimation for neural network pruning
Pavlo Molchanov, Arun Mallya, Stephen Tyree, Iuri Frosio, and Jan Kautz. Importance estimation for neural network pruning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11264–11272, 2019
2019
-
[69]
Structured pruning learns compact and accurate models
Mengzhou Xia, Zexuan Zhong, and Danqi Chen. Structured pruning learns compact and accurate models. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1513–1528, 2022
2022
-
[70]
Song Han, Huizi Mao, and William J Dally. Deep compression: Compressing deep neural net- works with pruning, trained quantization and huffman coding.arXiv preprint arXiv:1510.00149, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[71]
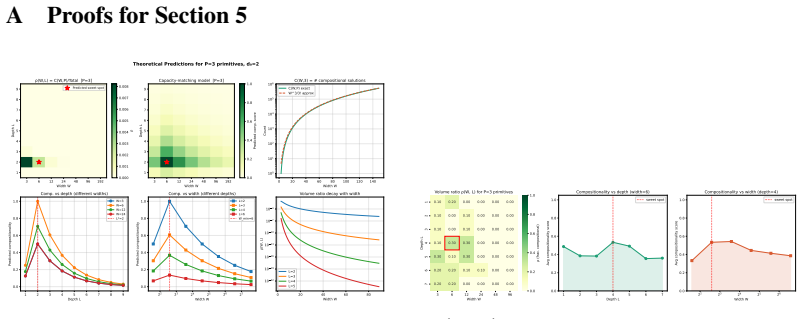
Mansheej Paul, Feng Chen, Brett W Larsen, Jonathan Frankle, Surya Ganguli, and Gintare Karolina Dziugaite. Unmasking the lottery ticket hypothesis: What’s encoded in a winning ticket’s mask?arXiv preprint arXiv:2210.03044, 2022. 14 A Proofs for Section 5 3 6 12 24 48 96 192 Width W 1 2 3 4 5 6 7 8 9Depth L (W,L) = C(W,P)/T otal [P=3] Predicted sweet spot ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.