On the Variance of Temporal Difference Learning and its Reduction Using Control Variates
Pith reviewed 2026-06-26 17:37 UTC · model grok-4.3
The pith
Temporal difference learning asymptotically bounds its variance from above by Monte Carlo estimators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
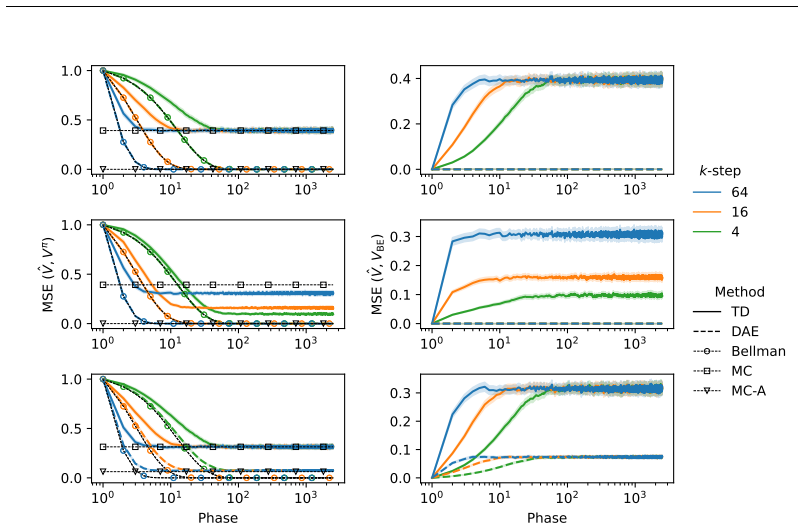
In the phased setting with tabular representation, TD learning aggregates over a larger number of independent trajectories, which bounds its asymptotic variance from above by that of Monte Carlo estimators. Shorter horizons reduce variance for fixed samples. Direct Advantage Estimation, viewed as regression-adjusted control variate, achieves a strictly tighter variance bound than TD in the large-sample limit.
What carries the argument
Aggregation over multiple trajectories in phased TD updates, combined with regression-adjusted control variates in Direct Advantage Estimation.
If this is right
- TD variance is asymptotically at most that of MC for the same number of samples.
- Shorter horizon TD updates incur less variance than longer ones under fixed sample count.
- DAE provides a tighter variance upper bound than standard TD in large samples.
- Control variates can be applied to advantage estimation to reduce variance beyond TD.
Where Pith is reading between the lines
- These bounds may suggest ways to design hybrid estimators that combine TD and MC strengths in practice.
- If the aggregation insight holds, it could guide variance analysis in non-tabular or online settings.
- The control variate view opens questions about optimal regression adjustments for other RL estimators.
Load-bearing premise
The analysis holds only in the phased setting with tabular representation, and may not extend if this is violated.
What would settle it
Run simulations comparing asymptotic variance of TD and MC estimators in a non-tabular function approximation setting; if TD variance exceeds MC, the bound does not hold universally.
Figures


read the original abstract
We analyze the variance of temporal difference (TD) learning using the phased setting with tabular representation, and show that one of the mechanisms behind its ability to reduce variance is by effectively aggregating over a larger number of independent trajectories. Based on this insight, we demonstrate that (1) the variance of TD is asymptotically bounded from above by Monte Carlo (MC) estimators, and (2) shorter horizon updates incurs less variance for a fixed number of samples. Beyond TD, we show that Direct Advantage Estimation (DAE), a method for estimating the advantage function, can be seen as a type of regression-adjusted control variate, which achieves a tighter bound on the variance compared to TD in the large-sample limit. Finally, we numerically illustrate the behaviors of these estimators with carefully designed environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes the variance of temporal difference (TD) learning in the phased episodic tabular setting. It argues that TD aggregates over a larger number of independent trajectories than Monte Carlo (MC) estimators, yielding an asymptotic upper bound on TD variance by MC variance. It further claims that shorter-horizon updates incur less variance for fixed samples, and introduces Direct Advantage Estimation (DAE) as a regression-adjusted control variate achieving a strictly tighter large-sample variance bound than TD. Derivations and numerical illustrations in designed environments support these claims.
Significance. If the derivations hold, the work supplies a concrete mechanistic account of variance reduction in TD via explicit trajectory counting and positions DAE as an improvement through control variates. The phased tabular protocol permits precise algebra that would be unavailable in continuing or function-approximation regimes; the paper appropriately restricts its claims to this setting, so the skeptic's transfer concern does not apply. The explicit counting argument and the regression-adjusted control-variate view are the main contributions.
minor comments (2)
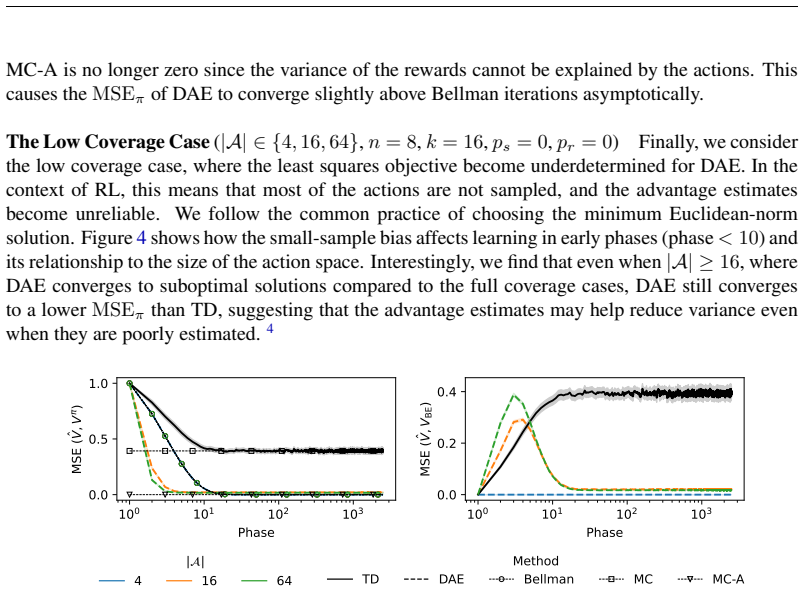
- The abstract states that numerical illustrations use 'carefully designed environments,' but the main text should include a brief table or paragraph summarizing the environment parameters (horizon lengths, transition probabilities) used for each figure so that the variance comparisons can be reproduced from the description alone.
- Notation for the phased estimator (e.g., the definition of the per-phase sample count) appears in the main derivation but is not restated in the theorem statements; adding a short 'Notation' subsection before §3 would improve readability.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the manuscript, accurate summary of the contributions, and recommendation to accept. We are pleased that the phased tabular analysis and the control-variate perspective on DAE were viewed as the main contributions.
Circularity Check
No significant circularity; bounds derived directly from phased tabular estimator definitions
full rationale
The paper's central results follow from explicit variance calculations on the TD and MC estimators under the phased episodic tabular protocol, with the aggregation insight obtained by counting independent trajectories per state and the DAE comparison obtained by direct regression-adjusted control-variate algebra. No parameter is fitted to data and then renamed as a prediction, no self-citation supplies a load-bearing uniqueness theorem, and no ansatz is smuggled in; the derivations remain self-contained within the stated setting and do not reduce to their inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Analysis restricted to phased setting with tabular representation
Reference graph
Works this paper leans on
-
[1]
Anderson, Z
E. Anderson, Z. Bai, C. Bischof, S. Blackford, J. Demmel, J. Dongarra, J. Du Croz, A. Greenbaum, S. Hammarling, A. McKenney, and D. Sorensen. LAPACK Users' Guide . Society for Industrial and Applied Mathematics, Philadelphia, PA, third edition, 1999. ISBN 0-89871-447-8
1999
-
[2]
Stochastic simulation: algorithms and analysis, volume 57
S ren Asmussen and Peter W Glynn. Stochastic simulation: algorithms and analysis, volume 57. Springer, 2007
2007
-
[3]
Residual algorithms: Reinforcement learning with function approximation
Leemon Baird. Residual algorithms: Reinforcement learning with function approximation. In Machine Learning Proceedings 1995, pp.\ 30--37. Elsevier, 1995
1995
-
[4]
A finite time analysis of temporal difference learning with linear function approximation
Jalaj Bhandari, Daniel Russo, and Raghav Singal. A finite time analysis of temporal difference learning with linear function approximation. In Conference on learning theory, pp.\ 1691--1692. PMLR, 2018
2018
-
[5]
JAX : composable transformations of P ython+ N um P y programs, 2018
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake Vander P las, Skye Wanderman- M ilne, and Qiao Zhang. JAX : composable transformations of P ython+ N um P y programs, 2018. URL http://github.com/jax-ml/jax
2018
-
[6]
Linear least-squares algorithms for temporal difference learning
Steven J Bradtke and Andrew G Barto. Linear least-squares algorithms for temporal difference learning. Machine learning, 22 0 (1): 0 33--57, 1996
1996
-
[7]
An l2 convergence theorem for random affine mappings
Robert M Burton and Uwe R \"o sler. An l2 convergence theorem for random affine mappings. Journal of applied probability, 32 0 (1): 0 183--192, 1995
1995
-
[8]
On the statistical benefits of temporal difference learning
David Cheikhi and Daniel Russo. On the statistical benefits of temporal difference learning. In International Conference on Machine Learning, pp.\ 4269--4293. PMLR, 2023
2023
-
[9]
Finite sample analyses for td (0) with function approximation
Gal Dalal, Bal \'a zs Sz \"o r \'e nyi, Gugan Thoppe, and Shie Mannor. Finite sample analyses for td (0) with function approximation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32, 2018
2018
-
[10]
Policy evaluation with temporal differences: A survey and comparison
Christoph Dann, Gerhard Neumann, and Jan Peters. Policy evaluation with temporal differences: A survey and comparison. The Journal of Machine Learning Research, 15 0 (1): 0 809--883, 2014
2014
-
[11]
Regression-based methods for using control variates in monte carlo experiments
Russell Davidson and James G MacKinnon. Regression-based methods for using control variates in monte carlo experiments. Journal of Econometrics, 54 0 (1-3): 0 203--222, 1992
1992
-
[12]
Variance reduction techniques for gradient estimates in reinforcement learning
Evan Greensmith, Peter L Bartlett, and Jonathan Baxter. Variance reduction techniques for gradient estimates in reinforcement learning. Journal of Machine Learning Research, 5 0 (9), 2004
2004
-
[13]
Optimality of lstd and its relation to mc
Steffen Grunewalder, Sepp Hochreiter, and Klaus Obermayer. Optimality of lstd and its relation to mc. In 2007 International Joint Conference on Neural Networks, pp.\ 338--343. IEEE, 2007
2007
-
[14]
J. M. Hammersley and D. C. Handscomb. Monte Carlo Methods. Springer Netherlands, 1964. ISBN 9789400958197. doi:10.1007/978-94-009-5819-7. URL http://dx.doi.org/10.1007/978-94-009-5819-7
-
[15]
Charles R. Harris, K. Jarrod Millman, St \' e fan J. van der Walt, Ralf Gommers, Pauli Virtanen, David Cournapeau, Eric Wieser, Julian Taylor, Sebastian Berg, Nathaniel J. Smith, Robert Kern, Matti Picus, Stephan Hoyer, Marten H. van Kerkwijk, Matthew Brett, Allan Haldane, Jaime Fern \' a ndez del R \' i o, Mark Wiebe, Pearu Peterson, Pierre G \' e rard-M...
-
[16]
Finite-sample convergence rates for q-learning and indirect algorithms
Michael Kearns and Satinder Singh. Finite-sample convergence rates for q-learning and indirect algorithms. Advances in neural information processing systems, 11, 1998
1998
-
[17]
Bias-variance error bounds for temporal difference updates
Michael J Kearns and Satinder Singh. Bias-variance error bounds for temporal difference updates. In COLT, pp.\ 142--147, 2000
2000
-
[18]
Agnostic notes on regression adjustments to experimental data: Reexamining freedman's critique
Winston Lin. Agnostic notes on regression adjustments to experimental data: Reexamining freedman's critique. The Annals of Applied Statistics, pp.\ 295--318, 2013
2013
-
[19]
Art B. Owen. Monte Carlo theory, methods and examples. https://artowen.su.domains/mc/, 2013
2013
-
[20]
Lsqr: An algorithm for sparse linear equations and sparse least squares
Christopher C Paige and Michael A Saunders. Lsqr: An algorithm for sparse linear equations and sparse least squares. ACM Transactions on Mathematical Software (TOMS), 8 0 (1): 0 43--71, 1982
1982
-
[21]
Skill or luck? return decomposition via advantage functions
Hsiao-Ru Pan and Bernhard Sch \"o lkopf. Skill or luck? return decomposition via advantage functions. arXiv preprint arXiv:2402.12874, 2024
arXiv 2024
-
[22]
u rtler, Alexander Neitz, and Bernhard Sch \
Hsiao-Ru Pan, Nico G \"u rtler, Alexander Neitz, and Bernhard Sch \"o lkopf. Direct advantage estimation. Advances in Neural Information Processing Systems, 35: 0 11869--11880, 2022
2022
-
[23]
Markov decision processes: discrete stochastic dynamic programming
Martin L Puterman. Markov decision processes: discrete stochastic dynamic programming. John Wiley & Sons, 2014
2014
-
[24]
The variance of discounted markov decision processes
Matthew J Sobel. The variance of discounted markov decision processes. Journal of Applied Probability, 19 0 (4): 0 794--802, 1982
1982
-
[25]
Learning to predict by the methods of temporal differences
Richard S Sutton. Learning to predict by the methods of temporal differences. Machine learning, 3 0 (1): 0 9--44, 1988
1988
-
[26]
Introduction to reinforcement learning
Richard S Sutton, Andrew G Barto, et al. Introduction to reinforcement learning. 1998
1998
-
[27]
Policy gradient methods for reinforcement learning with function approximation
Richard S Sutton, David McAllester, Satinder Singh, and Yishay Mansour. Policy gradient methods for reinforcement learning with function approximation. Advances in neural information processing systems, 12, 1999
1999
-
[28]
Algorithms for Reinforcement Learning
Csaba Szepesvari. Algorithms for Reinforcement Learning. Morgan & Claypool Publishers, 2010
2010
-
[29]
Analysis of temporal-diffference learning with function approximation
John Tsitsiklis and Benjamin Van Roy. Analysis of temporal-diffference learning with function approximation. Advances in neural information processing systems, 9, 1996
1996
-
[30]
Pauli Virtanen, Ralf Gommers, Travis E. Oliphant, Matt Haberland, Tyler Reddy, David Cournapeau, Evgeni Burovski, Pearu Peterson, Warren Weckesser, Jonathan Bright, St \'e fan J. van der Walt , Matthew Brett, Joshua Wilson, K. Jarrod Millman, Nikolay Mayorov, Andrew R. J. Nelson, Eric Jones, Robert Kern, Eric Larson, C J Carey, \.I lhan Polat, Yu Feng, Er...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.