Hierarchical Pooling for Sheaf Neural Networks
Pith reviewed 2026-06-26 17:46 UTC · model grok-4.3
The pith
HiSP pools stalk-valued features in sheaf neural networks by projecting onto low-frequency eigenmodes of local sheaf Laplacians within graph partitions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
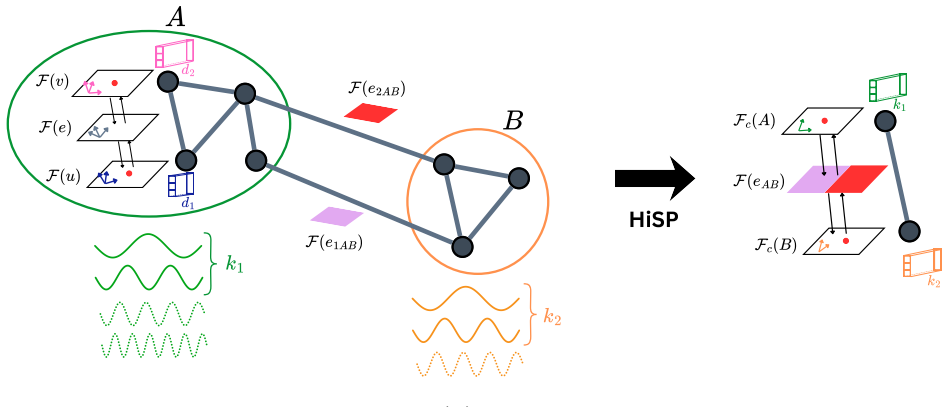
Given a partition of the graph, HiSP constructs each coarse stalk by projecting fine stalk-valued features onto the low-frequency eigenmodes of the cluster-internal sheaf Laplacian, allowing the fine sheaf energy to be represented on the coarse space through a Galerkin operator.
What carries the argument
Projection of fine stalk-valued features onto the low-frequency eigenmodes of the cluster-internal sheaf Laplacian, which defines the cochain-level prolongation map and Galerkin operator for coarsening.
If this is right
- The resulting coarse sheaves can be used directly inside sheaf diffusion layers to build deeper hierarchical SNNs.
- Truncation loss and realization loss can be measured separately to diagnose where coarsening quality degrades.
- The layer supports lifted sheaf Laplacians and batched graphs, allowing direct use in standard GNN libraries.
- The same projection idea supplies a sheaf-consistent alternative to scalar or vector pooling operations on graphs.
Where Pith is reading between the lines
- The separation into truncation and realization losses may help decide how many eigenmodes to retain for a given partition quality.
- The approach could be tested on graphs that already possess natural multi-scale structure to check whether the preserved restriction relations improve downstream task accuracy.
- Similar local spectral projections might be adapted to other cochain-based or higher-order geometric models beyond sheaves.
Load-bearing premise
A supplied graph partition together with low-frequency eigenmode selection will keep the essential compatibility relations encoded in the restriction maps while keeping truncation and realization losses acceptable.
What would settle it
Compute the difference between the fine sheaf energy and its Galerkin projection onto the coarse stalks for a concrete graph and sheaf; if the error stays large even when many modes are kept, the central construction does not preserve the sheaf structure as claimed.
Figures

read the original abstract
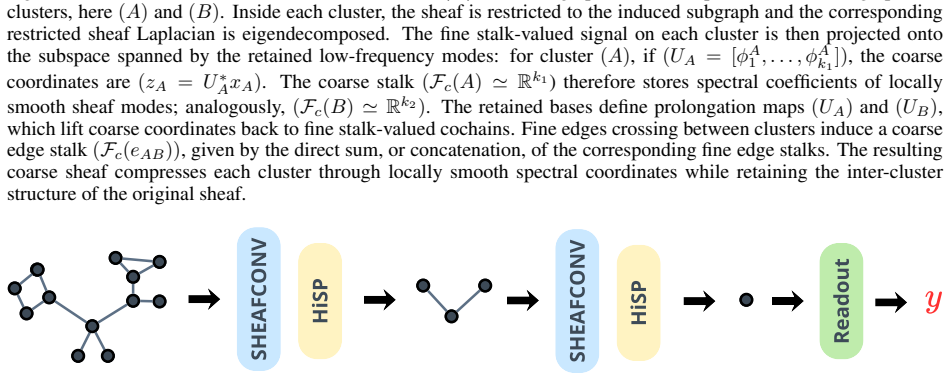
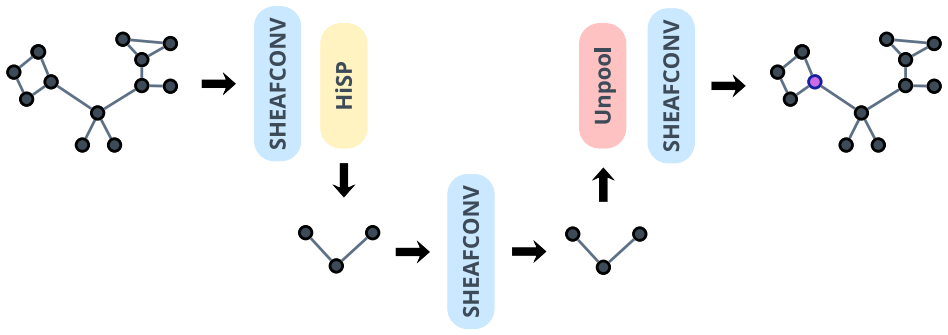
Sheaf Neural Networks (SNNs) generalize Graph Neural Networks (GNNs) by replacing scalar node signals with stalk-valued signals and by using restriction maps to measure compatibility across edges. Unlike standard graph diffusion, which encourages neighboring node features to become similar, sheaf diffusion promotes consistency through the restriction maps and can therefore model more general relationships between neighboring nodes. However, existing sheaf neural architectures mainly operate at a fixed graph resolution and do not provide a principled pooling mechanism for building hierarchical representations. In this paper, we introduce Hierarchical Sheaf Pool (HiSP), a sheaf-aware pooling framework based on local spectral coarsening. Given a partition of the graph, HiSP constructs each coarse stalk by projecting fine stalk-valued features onto the low-frequency eigenmodes of the cluster-internal sheaf Laplacian. These local modes define a cochain-level prolongation map, which allows the fine sheaf energy to be represented on the coarse space through a Galerkin operator. We further analyze the approximation induced by coarsening by separating truncation loss, due to discarded local modes, from realization loss, due to representing the projected operator as a coarse sheaf. Finally, we implement HiSP as a GNN pooling layer compatible with SNNs and provide a PyG implementation supporting batching, lifted sheaf Laplacians, and hierarchical architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Hierarchical Sheaf Pool (HiSP), a sheaf-aware pooling framework for Sheaf Neural Networks based on local spectral coarsening. Given a graph partition, each coarse stalk is obtained by projecting fine stalk-valued features onto the low-frequency eigenmodes of the cluster-internal sheaf Laplacian; these modes define a cochain-level prolongation map that represents the fine sheaf energy on the coarse space via a Galerkin operator. The induced approximation is analyzed by decomposing the error into truncation loss (discarded modes) and realization loss (coarse-sheaf representation of the projected operator). HiSP is implemented as a PyG-compatible GNN pooling layer supporting batching, lifted sheaf Laplacians, and hierarchical architectures.
Significance. If the central claims hold, HiSP would supply the first principled hierarchical pooling mechanism for SNNs, enabling multi-resolution sheaf-based models beyond fixed-resolution architectures. The explicit separation of truncation and realization losses and the provision of a reproducible PyG implementation (with batching support) are concrete strengths that would aid adoption and further development.
major comments (2)
- [§3] §3 (method): The prolongation map and Galerkin operator are defined using only the induced sheaf Laplacian on each cluster subgraph. Restriction maps on edges that cross partition cuts are never incorporated into any local Laplacian; therefore the construction cannot automatically guarantee that cross-boundary compatibility relations are preserved in the coarse cochain space.
- [§4] §4 (error analysis): The decomposition into truncation loss and realization loss is stated to bound the approximation error, yet neither term is shown to control the additional consistency error that arises when restriction maps across cut edges are omitted from the local spectral projections. This gap directly affects the claim that the coarse representation faithfully captures the original sheaf energy.
minor comments (2)
- Notation for the lifted sheaf Laplacian and the precise definition of the Galerkin operator should be given explicitly with equation numbers rather than described only conceptually.
- The abstract states that experimental results and a PyG implementation are provided, but the manuscript text supplied contains no tables, figures, or numerical validation of the claimed approximation quality.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments on the local nature of the coarsening and the scope of the error bounds are well-taken. We address each major comment below and will revise the manuscript to incorporate clarifications and additional discussion.
read point-by-point responses
-
Referee: [§3] §3 (method): The prolongation map and Galerkin operator are defined using only the induced sheaf Laplacian on each cluster subgraph. Restriction maps on edges that cross partition cuts are never incorporated into any local Laplacian; therefore the construction cannot automatically guarantee that cross-boundary compatibility relations are preserved in the coarse cochain space.
Authors: We agree that HiSP constructs the prolongation map and Galerkin operator exclusively from the induced sheaf Laplacian on each cluster subgraph, omitting restriction maps on edges that cross partition boundaries. This is an intentional design decision to enable efficient, parallel local spectral coarsening that supports batching and lifted Laplacians in the PyG implementation. Cross-boundary compatibility relations continue to be enforced by the global sheaf diffusion operators applied in subsequent SNN layers. Nevertheless, the local projection does not automatically preserve all cross-boundary compatibilities, and we will add an explicit discussion of this scope and its implications for hierarchical sheaf representations in the revised §3. revision: yes
-
Referee: [§4] §4 (error analysis): The decomposition into truncation loss and realization loss is stated to bound the approximation error, yet neither term is shown to control the additional consistency error that arises when restriction maps across cut edges are omitted from the local spectral projections. This gap directly affects the claim that the coarse representation faithfully captures the original sheaf energy.
Authors: The error analysis separates truncation loss (discarded high-frequency modes) from realization loss (coarse-sheaf representation of the projected operator) and bounds the local approximation error within each cluster. We acknowledge that these terms do not control the additional consistency error induced by the omission of cross-cut restriction maps. The claim that the coarse representation captures the original sheaf energy should therefore be understood as applying to the local energy captured by the Galerkin operator. In the revision we will qualify the statements in §4, clarify the scope of the bounds, and add a remark on the role of subsequent global layers in mitigating cross-boundary consistency effects. revision: yes
Circularity Check
No significant circularity; HiSP applies standard spectral coarsening to existing SNN sheaf Laplacians
full rationale
The derivation constructs coarse stalks by projecting fine features onto low-frequency eigenmodes of each cluster's induced sheaf Laplacian and represents the energy via a Galerkin operator. This is a direct, non-circular transfer of classical local spectral coarsening and Galerkin projection (standard in numerical PDEs and graph Laplacians) onto the already-defined sheaf Laplacian from prior SNN literature. The separation of truncation loss from realization loss is an analytical accounting step, not a self-referential definition or fitted prediction. No load-bearing premise reduces to a self-citation chain, ansatz smuggled via citation, or uniqueness theorem imported from the authors' own prior work. The framework remains self-contained against external spectral-graph benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sheaf structures are defined via stalks and restriction maps that measure compatibility across edges.
Reference graph
Works this paper leans on
-
[1]
Kipf and Max Welling
Thomas N. Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. InInter- national Conference on Learning Representations, 2017. URLhttps://openreview.net/forum?id= SJU4ayYgl
2017
-
[2]
Toward a spectral theory of cellular sheaves.Journal of Applied and Compu- tational Topology, 3(4):315–358, 2019
Jakob Hansen and Robert Ghrist. Toward a spectral theory of cellular sheaves.Journal of Applied and Compu- tational Topology, 3(4):315–358, 2019
2019
-
[3]
Sheaf neural networks.arXiv preprint arXiv:2012.06333, 2020
Jakob Hansen and Thomas Gebhart. Sheaf neural networks.arXiv preprint arXiv:2012.06333, 2020
arXiv 2012
-
[4]
Neural sheaf diffusion: A topological perspective on heterophily and oversmoothing in gnns.Advances in Neural Information Processing Systems, 35:18527–18541, 2022
Cristian Bodnar, Francesco Di Giovanni, Benjamin Chamberlain, Pietro Lio, and Michael Bronstein. Neural sheaf diffusion: A topological perspective on heterophily and oversmoothing in gnns.Advances in Neural Information Processing Systems, 35:18527–18541, 2022
2022
-
[5]
Sheaf neural networks with connection laplacians
Federico Barbero, Cristian Bodnar, Haitz S ´aez de Oc´ariz Borde, Michael Bronstein, Petar Veliˇckovi´c, and Pietro Li`o. Sheaf neural networks with connection laplacians. InTopological, Algebraic and Geometric Learning Workshops 2022, pages 28–36. PMLR, 2022
2022
-
[6]
Sheaf attention networks
Federico Barbero, Cristian Bodnar, Haitz S ´aez de Oc ´ariz Borde, and Pietro Lio. Sheaf attention networks. In NeurIPS 2022 Workshop on Symmetry and Geometry in Neural Representations, 2022
2022
-
[7]
Alessio Borgi, Fabrizio Silvestri, and Pietro Li`o. Polynomial neural sheaf diffusion: A spectral filtering approach on cellular sheaves.arXiv preprint arXiv:2512.00242, 2025
Pith/arXiv arXiv 2025
-
[8]
Joint diffusion processes as an inductive bias in sheaf neural networks
Ferran Hernandez Caralt, Guillermo Bern ´ardez Gil, Iulia Duta, Pietro Li `o, and Eduard Alarc ´on Cot. Joint diffusion processes as an inductive bias in sheaf neural networks. InProceedings of the Geometry-grounded Representation Learning and Generative Modeling Workshop (GRaM), volume 251 ofProceedings of Machine Learning Research, pages 249–263. PMLR, ...
2024
-
[9]
Cooperative sheaf neural networks.arXiv preprint arXiv:2507.00647, 2025
Andr ´e Ribeiro, Ana Luiza Ten ´orio, Juan Belieni, Amauri H Souza, and Diego Mesquita. Cooperative sheaf neural networks.arXiv preprint arXiv:2507.00647, 2025
arXiv 2025
-
[10]
Hierarchical graph representation learning with differentiable pooling.Advances in neural information processing systems, 31, 2018
Zhitao Ying, Jiaxuan You, Christopher Morris, Xiang Ren, Will Hamilton, and Jure Leskovec. Hierarchical graph representation learning with differentiable pooling.Advances in neural information processing systems, 31, 2018
2018
-
[11]
Understanding pooling in graph neural networks.IEEE transactions on neural networks and learning systems, 35(2):2708–2718, 2022
Daniele Grattarola, Daniele Zambon, Filippo Maria Bianchi, and Cesare Alippi. Understanding pooling in graph neural networks.IEEE transactions on neural networks and learning systems, 35(2):2708–2718, 2022
2022
-
[12]
Maxcutpool: differentiable feature-aware maxcut for pooling in graph neural networks, 2025
Carlo Abate and Filippo Maria Bianchi. Maxcutpool: differentiable feature-aware maxcut for pooling in graph neural networks, 2025. URLhttps://openreview.net/forum?id=xlbXRJ2XCP
2025
-
[13]
SIAM, 2000
William L Briggs, Van Emden Henson, and Steve F McCormick.A multigrid tutorial. SIAM, 2000
2000
-
[14]
Academic press, 2001
Ulrich Trottenberg, Cornelius W Oosterlee, and Anton Schuller.Multigrid methods. Academic press, 2001
2001
-
[15]
Heterogeneous sheaf neural networks.arXiv preprint arXiv:2409.08036, 2024
Luke Braithwaite, Alessio Borgi, Gabriele Onorato, Kristjan Tarantelli, Francesco Restuccia, Fabrizio Silvestri, and Pietro Li`o. Heterogeneous sheaf neural networks.arXiv preprint arXiv:2409.08036, 2024
Pith/arXiv arXiv 2024
-
[16]
David I Shuman, Sunil K Narang, Pascal Frossard, Antonio Ortega, and Pierre Vandergheynst. The emerging field of signal processing on graphs: Extending high-dimensional data analysis to networks and other irregular domains.IEEE signal processing magazine, 30(3):83–98, 2013
2013
-
[17]
A tutorial on spectral clustering.Statistics and computing, 17(4):395–416, 2007
Ulrike V on Luxburg. A tutorial on spectral clustering.Statistics and computing, 17(4):395–416, 2007
2007
-
[18]
Graph convolutional networks with eigenpooling
Yao Ma, Suhang Wang, Charu C Aggarwal, and Jiliang Tang. Graph convolutional networks with eigenpooling. InProceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, pages 723–731, 2019
2019
-
[19]
Cambridge university press, 2012
Roger A Horn and Charles R Johnson.Matrix analysis. Cambridge university press, 2012
2012
-
[20]
Weighted graph cuts without eigenvectors a multilevel approach.IEEE transactions on pattern analysis and machine intelligence, 29(11):1944–1957, 2007
Inderjit S Dhillon, Yuqiang Guan, and Brian Kulis. Weighted graph cuts without eigenvectors a multilevel approach.IEEE transactions on pattern analysis and machine intelligence, 29(11):1944–1957, 2007
1944
-
[21]
Torch geometric pool: the pytorch library for pooling in graph neural networks, 2026
Carlo Abate, Ivan Marisca, and Filippo Maria Bianchi. Torch geometric pool: the pytorch library for pooling in graph neural networks, 2026. URLhttps://arxiv.org/abs/2512.12642. 15 Appendix A Additional Background on Cellular Sheaves This appendix expands the basic definitions from Section 2.1 and records several facts used throughout the paper. A.1 Block ...
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.