Learning through Internalization
Pith reviewed 2026-06-26 17:40 UTC · model grok-4.3
The pith
A simplified one-layer transformer first masters parity with chain-of-thought tokens then internalizes the computation into its weights as tokens are removed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For the task of learning parities, a simplified one-layer transformer provably first learns the target with explicit CoT supervision and then internalizes the autoregressive generation as CoT tokens are progressively removed, learning to directly compute the parity. This task is computationally hard to learn from data without CoT supervision.
What carries the argument
Internalization of chain-of-thought tokens, the process by which the model transitions from generating explicit reasoning tokens to encoding the required computation directly in its weights.
If this is right
- Internalization turns an otherwise intractable learning problem into a tractable one by first using explicit supervision.
- Different classes of semiautomata exhibit different degrees of resistance to internalization.
- Successful internalization is accompanied by a measurable drop in out-of-distribution accuracy.
- The same dynamics relate to the positive distribution shift effect during training.
Where Pith is reading between the lines
- Gradual token removal schedules could be tuned to accelerate internalization on other sequence tasks.
- Out-of-distribution degradation may serve as a practical signal that internalization has occurred.
- The mechanism might generalize to larger transformers on arithmetic or logical reasoning benchmarks.
- If internalization scales, it offers a route to compact models that no longer need to emit intermediate reasoning steps.
Load-bearing premise
The provable behavior on the parity task with the simplified one-layer transformer captures the general internalization mechanism for semiautomata simulation.
What would settle it
An experiment in which the same one-layer transformer, after progressive CoT removal, still produces incorrect parity answers or reverts to needing explicit tokens at inference time.
Figures

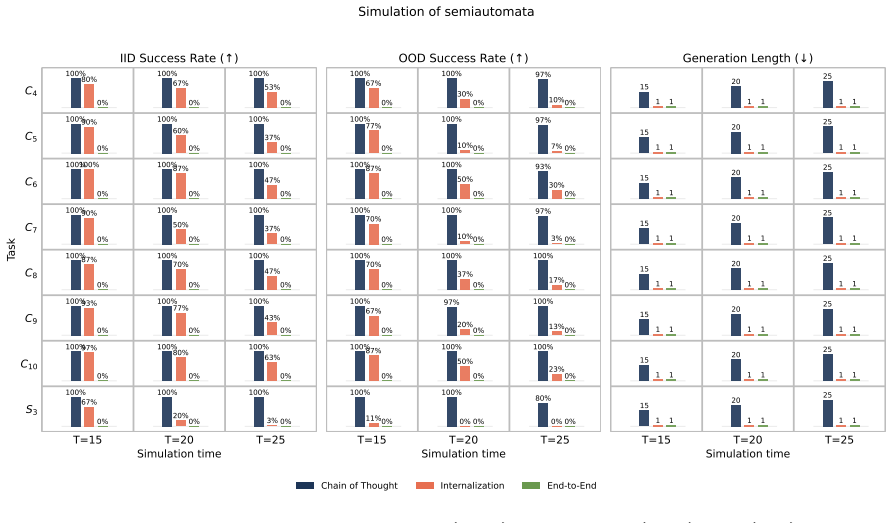
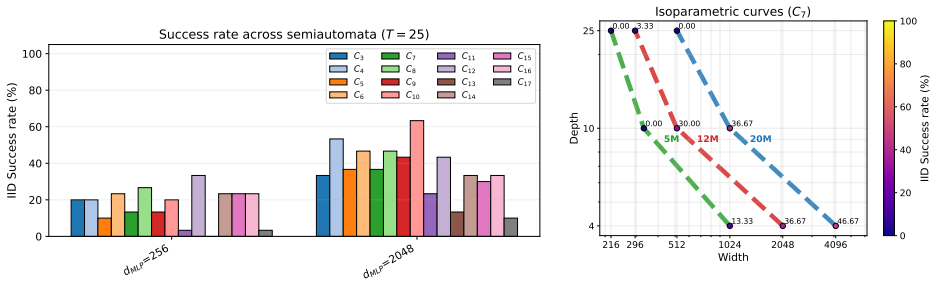



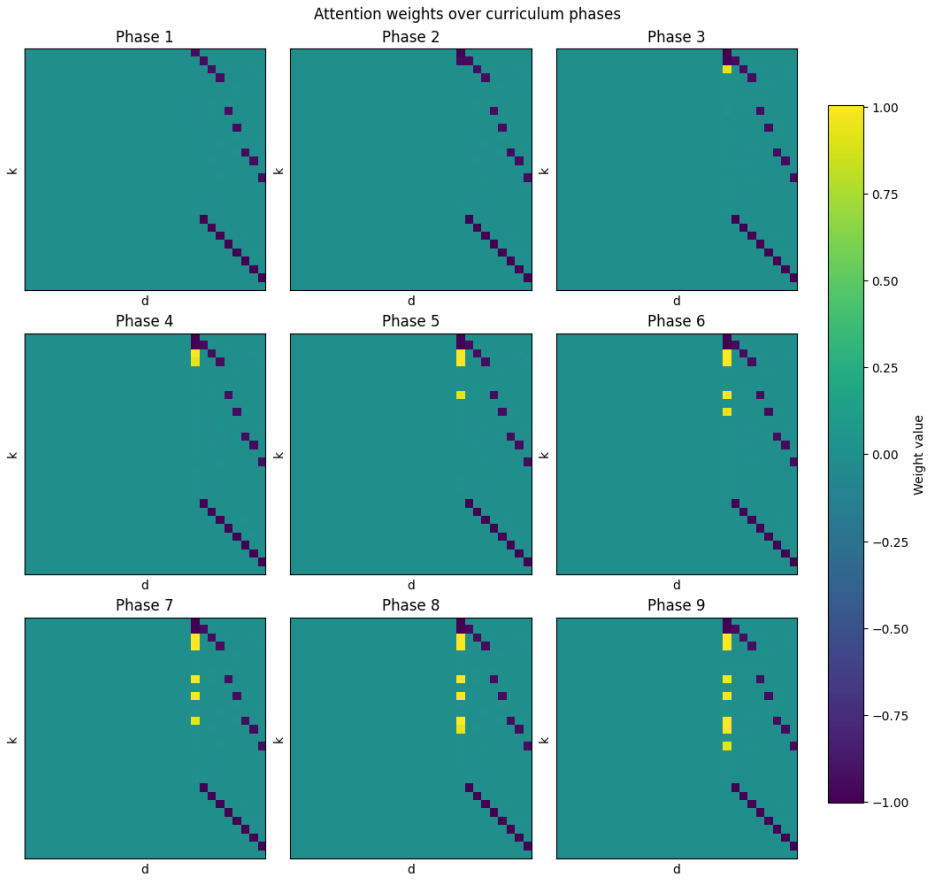

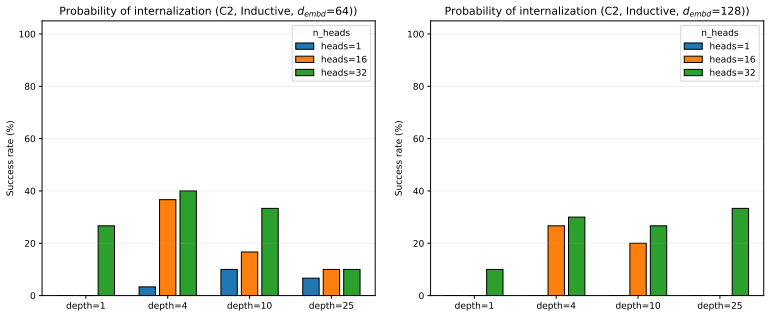
read the original abstract
We study internalization processes, by which neural-network-based systems absorb an explicit computational procedure into their own weights, and how they facilitate learning. We investigate how transformers internalize the simulation of semiautomata by internalizing chain-of-thought (CoT) tokens, which classes of semiautomata are harder to internalize, and expose the flip side of internalization, that is, a progressive degradation of out-of-distribution performance. We then provide the first provable analysis of successful internalization: for the task of learning parities, we show that a simplified one-layer transformer provably first learns the target with explicit CoT supervision and then internalizes the autoregressive generation as CoT tokens are progressively removed, learning to directly compute the parity. This task is computationally hard to learn from data without CoT supervision. Finally, we discuss how learning through internalization relates to the \textit{Positive Distribution Shift} phenomenon recently introduced by~\citet{Med+26}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript studies internalization in transformers, whereby explicit chain-of-thought (CoT) procedures for simulating semiautomata are absorbed into model weights. It examines which classes of semiautomata are harder to internalize and identifies a progressive degradation in out-of-distribution performance as a flip side. The central contribution is a provable result showing that a simplified one-layer transformer on the parity task first learns the target under explicit CoT supervision and then internalizes the computation as CoT tokens are progressively removed, enabling direct parity computation without CoT; the paper notes that parity is hard to learn from data alone and relates the phenomenon to the authors' prior Positive Distribution Shift result.
Significance. If the provable internalization result holds, the work supplies a concrete, machine-checkable example of how CoT supervision can bootstrap learning of a computationally hard task and then be absorbed, which is a clear strength. The explicit connection to Positive Distribution Shift and the identification of OOD degradation provide testable predictions. The narrow scope (one-layer transformer, parity task) is stated, so the result functions as a controlled case study rather than a general theory.
minor comments (2)
- The abstract and introduction should include a brief pointer to the specific hardness result for parity without CoT (e.g., a standard reference or short argument) to make the contrast with the internalization result self-contained.
- Notation for the progressive removal of CoT tokens and the transition to direct computation should be defined once in a dedicated subsection before the proof, to improve readability for readers unfamiliar with the semiautomata framing.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work, the recognition of the provable internalization result on parities as a controlled case study, and the recommendation for minor revision. No major comments were raised in the report.
Circularity Check
No significant circularity identified
full rationale
The paper's central claim is a new provable result showing that a simplified one-layer transformer first learns parities under explicit CoT supervision and then internalizes the computation as tokens are removed. This is presented as independent of the self-cited Med+26 Positive Distribution Shift work, which appears only in a final discussion section relating the two phenomena. No load-bearing self-citation, self-definitional step, fitted input renamed as prediction, or ansatz smuggling is present in the stated derivation; the narrow scope of the result is explicitly acknowledged, leaving the proof self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Juno Kim and Taiji Suzuki , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2410.08633 , eprinttype =. 2410.08633 , timestamp =
-
[2]
Ash and Surbhi Goel and Akshay Krishnamurthy and Cyril Zhang , title =
Bingbin Liu and Jordan T. Ash and Surbhi Goel and Akshay Krishnamurthy and Cyril Zhang , title =. The Eleventh International Conference on Learning Representations,
-
[3]
From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step
Yuntian Deng and Yejin Choi and Stuart M. Shieber , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2405.14838 , eprinttype =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2405.14838 2024
-
[4]
2026 , eprint=
Positive Distribution Shift as a Framework for Understanding Tractable Learning , author=. 2026 , eprint=
2026
-
[5]
Samuel , title =
Arthur L. Samuel , title =
-
[6]
Lillicrap and Fan Hui and Laurent Sifre and George van den Driessche and Thore Graepel and Demis Hassabis , title =
David Silver and Julian Schrittwieser and Karen Simonyan and Ioannis Antonoglou and Aja Huang and Arthur Guez and Thomas Hubert and Lucas Baker and Matthew Lai and Adrian Bolton and Yutian Chen and Timothy P. Lillicrap and Fan Hui and Laurent Sifre and George van den Driessche and Thore Graepel and Demis Hassabis , title =. Nat. , volume =
-
[7]
Shieber , title =
Yuntian Deng and Kiran Prasad and Roland Fernandez and Paul Smolensky and Vishrav Chaudhary and Stuart M. Shieber , title =. CoRR , volume =. 2023 , doi =
2023
-
[8]
Itamar Shoshani and Ohad Shamir , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2501.00817 , eprinttype =
-
[9]
Learning High-Degree Parities: The Crucial Role of the Initialization , booktitle =
Emmanuel Abbe and Elisabetta Cornacchia and Jan Hazla and Donald Kougang. Learning High-Degree Parities: The Crucial Role of the Initialization , booktitle =
-
[10]
A Theory of Learning with Autoregressive Chain of Thought , booktitle =
Nirmit Joshi and Gal Vardi and Adam Block and Surbhi Goel and Zhiyuan Li and Theodor Misiakiewicz and Nathan Srebro , editor =. A Theory of Learning with Autoregressive Chain of Thought , booktitle =
-
[11]
Gomez and Lukasz Kaiser and Illia Polosukhin , editor =
Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin , editor =. Attention is All you Need , booktitle =
-
[12]
Kearns , title =
Michael J. Kearns , title =. J
-
[13]
Failures of Gradient-Based Deep Learning , booktitle =
Shai Shalev. Failures of Gradient-Based Deep Learning , booktitle =
-
[14]
Towards a theory of model distillation , journal =
Enric Boix. Towards a theory of model distillation , journal =. 2024 , eprinttype =
2024
-
[15]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Finite state automata inside transformers with chain-of-thought: A mechanistic study on state tracking , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[16]
CoRR , volume =
Ping Yu and Jing Xu and Jason Weston and Ilia Kulikov , title =. CoRR , volume =
-
[17]
2026 , eprint=
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models , author=. 2026 , eprint=
2026
-
[18]
2026 , eprint=
On-Policy Context Distillation for Language Models , author=. 2026 , eprint=
2026
-
[19]
Foundations of computational mathematics , volume=
User-friendly tail bounds for sums of random matrices , author=. Foundations of computational mathematics , volume=. 2012 , publisher=
2012
-
[20]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Implicit reasoning in transformers is reasoning through shortcuts , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[21]
Valiant , title =
Leslie G. Valiant , title =. Commun
-
[22]
Kearns and Leslie G
Michael J. Kearns and Leslie G. Valiant , title =. J
-
[23]
arXiv preprint arXiv:2412.06769 , year=
Training Large Language Models to Reason in a Continuous Latent Space , author=. arXiv preprint arXiv:2412.06769 , year=
-
[24]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , year=
CODI: Compressing Chain-of-Thought into Continuous Space via Self-Distillation , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , year=
2025
-
[25]
arXiv preprint arXiv:2412.13171 , year=
Compressed Chain of Thought: Efficient Reasoning Through Dense Representations , author=. arXiv preprint arXiv:2412.13171 , year=
-
[26]
Advances in Neural Information Processing Systems , year=
Can Language Models Learn to Skip Steps? , author=. Advances in Neural Information Processing Systems , year=
-
[27]
arXiv preprint arXiv:2505.18642 , year=
Skip-Thinking: Chunk-wise Chain-of-Thought Distillation Enable Smaller Language Models to Reason Better and Faster , author=. arXiv preprint arXiv:2505.18642 , year=
-
[28]
arXiv preprint arXiv:2004.09602 , year=
Integer quantization for deep learning inference: Principles and empirical evaluation , author=. arXiv preprint arXiv:2004.09602 , year=
arXiv 2004
-
[29]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Quantization and training of neural networks for efficient integer-arithmetic-only inference , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[30]
int8 (): 8-bit matrix multiplication for transformers at scale , author=
Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale , author=. Advances in neural information processing systems , volume=
-
[31]
IBM Journal of research and development , volume=
Some studies in machine learning using the game of checkers , author=. IBM Journal of research and development , volume=. 1959 , publisher=
1959
-
[32]
CoRR , volume =
Tianhe Lin and Jian Xie and Siyu Yuan and Deqing Yang , title =. CoRR , volume =. 2025 , doi =
2025
-
[33]
Provable Advantage of Curriculum Learning on Parity Targets with Mixed Inputs , booktitle =
Emmanuel Abbe and Elisabetta Cornacchia and Aryo Lotfi , editor =. Provable Advantage of Curriculum Learning on Parity Targets with Mixed Inputs , booktitle =
-
[34]
A Mathematical Model for Curriculum Learning for Parities , booktitle =
Elisabetta Cornacchia and Elchanan Mossel , editor =. A Mathematical Model for Curriculum Learning for Parities , booktitle =
-
[35]
Transformers are
Katharopoulos, Angelos and Vyas, Apoorv and Pappas, Nikolaos and Fleuret, Fran. Transformers are. International Conference on Machine Learning , year=
-
[36]
Winter Conference on Applications of Computer Vision , year=
Efficient Attention: Attention with Linear Complexities , author=. Winter Conference on Applications of Computer Vision , year=
-
[37]
Hinton and Oriol Vinyals and Jeffrey Dean , title =
Geoffrey E. Hinton and Oriol Vinyals and Jeffrey Dean , title =. CoRR , volume =. 2015 , url =
2015
-
[38]
CoRR , volume =
Marko Medvedev and Kaifeng Lyu and Zhiyuan Li and Nathan Srebro , title =. CoRR , volume =
-
[39]
Furst and Jeffrey C
Avrim Blum and Merrick L. Furst and Jeffrey C. Jackson and Michael J. Kearns and Yishay Mansour and Steven Rudich , title =. Proceedings of the Twenty-Sixth Annual ACM Symposium on Theory of Computing , pages =. 1994 , publisher =
1994
-
[40]
Proceedings of the 34th International Conference on Machine Learning , series =
Shai Shalev-Shwartz and Ohad Shamir and Shaked Shammah , title =. Proceedings of the 34th International Conference on Machine Learning , series =. 2017 , publisher =
2017
-
[41]
On the Non-Universality of Deep Learning: Quantifying the Cost of Symmetry , booktitle =
Emmanuel Abbe and Enric Boix-Adser. On the Non-Universality of Deep Learning: Quantifying the Cost of Symmetry , booktitle =. 2022 , doi =
2022
-
[42]
Edelman and Surbhi Goel and Sham M
Boaz Barak and Benjamin L. Edelman and Surbhi Goel and Sham M. Kakade and Eran Malach and Cyril Zhang , title =. Advances in Neural Information Processing Systems , volume =. 2022 , doi =
2022
-
[43]
Kakade , title =
Yiwen Kou and Zixiang Chen and Quanquan Gu and Sham M. Kakade , title =. Advances in Neural Information Processing Systems , volume =. 2024 , doi =
2024
-
[44]
CoRR , volume =
Itamar Shoshani and Ohad Shamir , title =. CoRR , volume =. 2025 , eprint =
2025
-
[45]
Journal of the ACM , volume =
Avrim Blum and Adam Kalai and Hal Wasserman , title =. Journal of the ACM , volume =. 2003 , doi =
2003
-
[46]
Proceedings of the 47th Annual IEEE Symposium on Foundations of Computer Science , pages =
Vitaly Feldman and Parikshit Gopalan and Subhash Khot and Ashok Kumar Ponnuswami , title =. Proceedings of the 47th Annual IEEE Symposium on Foundations of Computer Science , pages =. 2006 , publisher =
2006
-
[47]
Proceedings of the 42nd ACM Symposium on Theory of Computing , pages =
Benny Applebaum and Boaz Barak and Avi Wigderson , title =. Proceedings of the 42nd ACM Symposium on Theory of Computing , pages =. 2010 , publisher =
2010
-
[48]
Proceedings of the 2017 Conference on Learning Theory , series =
Surbhi Goel and Varun Kanade and Adam Klivans and Justin Thaler , title =. Proceedings of the 2017 Conference on Learning Theory , series =. 2017 , publisher =
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.