A Tutorial on Bregman Projection in Statistics
Pith reviewed 2026-06-26 12:26 UTC · model grok-4.3
The pith
Bregman projection under a convex generator makes the GLM score equation the Pythagorean orthogonality, so the fit is both an e-projection and m-projection at once and recovers maximum entropy, EM, and variational inference exactly when fam
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
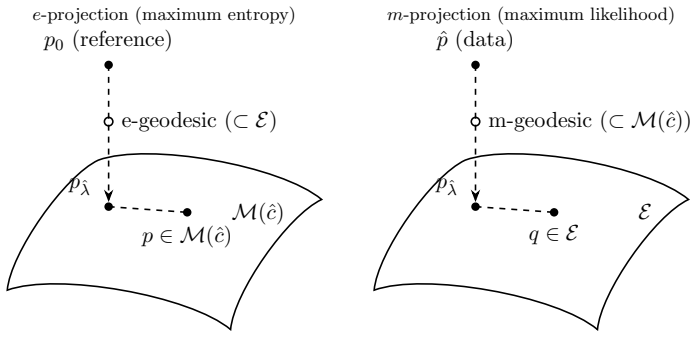
Under the canonical link the GLM score equation is exactly the Pythagorean orthogonality of the Bregman projection, so the fit is simultaneously an e-projection in natural coordinates and an m-projection in mean coordinates; the same single theorem recovers maximum entropy, EM, variational inference and the other listed methods as exact instances when the families are flat.
What carries the argument
The Pythagorean theorem that follows from the conjugacy of a strictly convex generator G and its conjugate F, which produces dual e-projections onto moment-constrained families and m-projections onto exponential families.
Load-bearing premise
The statistical families to which the construction is applied must be flat with respect to the Bregman divergence so that the exact Pythagorean identity holds without extra error terms.
What would settle it
A direct calculation showing that the score equation of a canonical-link GLM does not equal the orthogonality condition supplied by the Bregman projection would falsify the claimed unification.
Figures

read the original abstract
A single geometric operation -- projecting a reference onto a constrained family under a Bregman divergence -- underlies a striking range of statistical methods. This tutorial develops the operation first as pure convex geometry, with no statistics attached. A strictly convex generator $G$ and its conjugate $F$ furnish two coordinate systems, a projection theorem with existence and uniqueness, and a Pythagorean {theorem}; the Pythagorean theorem itself produces {two} dual projections -- the information (e-) projection onto moment-constrained families and the moment (m-) projection onto exponential families -- exchanged by the conjugacy $G\leftrightarrow F$, so a single theorem governs both. Part~II reads off the statistics. The generalized linear model is treated in detail as the concrete carrier of the two projections: {under the canonical link,} the score equation is exactly the Pythagorean orthogonality, and the fit is simultaneously an e-projection in the natural coordinate and an m-projection in the mean coordinate. Maximum entropy, survey calibration, over-identified moment models, the EM algorithm, variational inference, autoencoders, and expectation propagation then fall into place as instances of the same construction -- exactly where the underlying families are flat, and as controlled approximations or neighboring-divergence analogies where they are not. The mathematics of Part~I is self-contained; the statistical sections presume only familiarity with the methods being unified.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
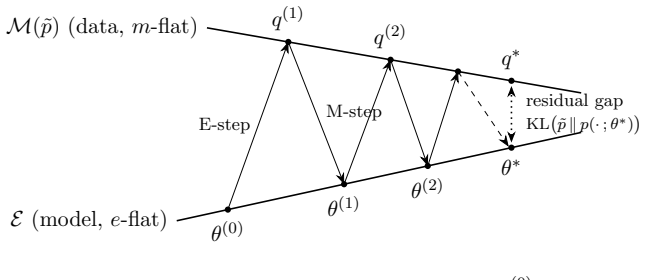
Summary. The manuscript is a tutorial claiming that a single Bregman-projection theorem (with existence/uniqueness and a Pythagorean identity) developed in self-contained convex geometry (Part I) unifies multiple statistical procedures in Part II: under the canonical link the GLM score equation is exactly the Pythagorean orthogonality (simultaneously an e-projection in natural coordinates and m-projection in mean coordinates), while maximum entropy, survey calibration, over-identified moments, EM, variational inference, autoencoders, and expectation propagation are recovered exactly on flat families and as controlled approximations otherwise.
Significance. If the derivations hold, the work supplies a unified geometric account that makes the listed methods instances of one projection theorem, with explicit flatness qualifications and a clean separation between the convex-geometry foundation and the statistical reading. The self-contained Part I and the parameter-free character of the core projection result are strengths that could aid both pedagogy and generalization.
major comments (2)
- [Part II, GLM section] Part II, GLM section: the assertion that the score equation is exactly the Pythagorean orthogonality is load-bearing for the central unification claim; an explicit line-by-line verification that the canonical-link GLM moment constraint matches the Bregman orthogonality condition (without additional approximation) would strengthen the argument.
- [Applications subsection on EM and variational inference] Applications subsection on EM and variational inference: the flatness qualification is stated, but the manuscript should supply a short explicit check (e.g., for the exponential-family case) confirming that the neighboring-divergence error term vanishes identically rather than being merely bounded.
minor comments (2)
- Abstract: the curly braces around 'theorem' and 'two' appear to be LaTeX artifacts; remove them for the final version.
- [Part I] Part I: a single low-dimensional numerical example computing both the e- and m-projections for a simple strictly convex G would help readers verify the dual-projection statement before the statistical applications.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the positive overall assessment. We address the two major comments point by point below and will incorporate the suggested clarifications in the revised manuscript.
read point-by-point responses
-
Referee: [Part II, GLM section] Part II, GLM section: the assertion that the score equation is exactly the Pythagorean orthogonality is load-bearing for the central unification claim; an explicit line-by-line verification that the canonical-link GLM moment constraint matches the Bregman orthogonality condition (without additional approximation) would strengthen the argument.
Authors: We agree that an explicit verification strengthens the central claim. In the revised version we will add a short dedicated paragraph immediately following the statement of the GLM score equation. This paragraph will derive the moment constraint from the Bregman Pythagorean identity in coordinates, showing term-by-term that the canonical-link score equation is identical to the orthogonality condition with no approximation or additional assumption required. revision: yes
-
Referee: [Applications subsection on EM and variational inference] Applications subsection on EM and variational inference: the flatness qualification is stated, but the manuscript should supply a short explicit check (e.g., for the exponential-family case) confirming that the neighboring-divergence error term vanishes identically rather than being merely bounded.
Authors: We accept the suggestion. In the revised manuscript we will insert a brief explicit calculation in the EM/variational-inference subsection. For the case in which the approximating family is itself an exponential family (hence flat with respect to the Bregman divergence), we will show that the neighboring-divergence remainder is identically zero by direct substitution into the definition, confirming exact recovery rather than a bound. revision: yes
Circularity Check
No significant circularity
full rationale
The paper explicitly separates Part I (self-contained convex geometry deriving the Bregman projection theorem, existence/uniqueness, and Pythagorean identity from a strictly convex generator G and conjugate F) from Part II (statistical applications). The GLM score equation is shown to match the Pythagorean orthogonality under the canonical link by direct substitution into the geometric identity; maxent, EM, VI, etc., are recovered exactly on flat families by the same identity. No parameter is fitted to data and then renamed a prediction, no self-citation chain bears the central claim, and no ansatz is smuggled via prior work. The derivation chain is therefore one-directional from the independent convex-analytic results to the statistical instances.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Existence and uniqueness of the Bregman projection for a strictly convex generator G
- standard math Pythagorean identity for Bregman divergences on flat families
Reference graph
Works this paper leans on
-
[1]
Albergo, Nicholas M
Michael S. Albergo, Nicholas M. Boffi, and Eric Vanden-Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions.Journal of Machine Learning Research, 26(209):1– 80, 2025
2025
-
[2]
Albergo and Eric Vanden-Eijnden
Michael S. Albergo and Eric Vanden-Eijnden. Building normalizing flows with stochastic interpolants. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[3]
Wasserstein generative adversarial networks
Martin Arjovsky, Soumith Chintala, and L´ eon Bottou. Wasserstein generative adversarial networks. InInternational Conference on Machine Learning (ICML), volume 70 ofProceedings of Machine Learning Research, pages 214–223, 2017
2017
-
[4]
Dhillon, and Joydeep Ghosh
Arindam Banerjee, Srujana Merugu, Inderjit S. Dhillon, and Joydeep Ghosh. Clustering with Bregman divergences.Journal of Machine Learning Research, 6(58):1705–1749, 2005
2005
-
[5]
Sancharee Basak, Ayanendranath Basu, and M. C. Jones. On the ‘optimal’ density power divergence tuning parameter.Journal of Applied Statistics, 48(3):536–556, 2021
2021
-
[6]
Harris, Nils L
Ayanendranath Basu, Ian R. Harris, Nils L. Hjort, and M. C. Jones. Robust and efficient estimation by minimising a density power divergence.Biometrika, 85(3):549–559, 1998. 33
1998
-
[7]
F.-X. Briol, A. Barp, A. B. Duncan, and M. Girolami. Statistical inference for generative models with maximum mean discrepancy. arXiv:1906.05944, 2019
Pith/arXiv arXiv 1906
-
[8]
Double/debiased machine learning for treatment and structural parameters.The Econometrics Journal, 21(1):C1–C68, 2018
Victor Chernozhukov, Denis Chetverikov, Mert Demirer, Esther Duflo, Christian Hansen, Whitney Newey, and James Robins. Double/debiased machine learning for treatment and structural parameters.The Econometrics Journal, 21(1):C1–C68, 2018
2018
-
[9]
The Annals of Probability, 3(1):146–158, 1975
Imre Csisz´ ar.I-divergence geometry of probability distributions and minimization problems. The Annals of Probability, 3(1):146–158, 1975
1975
-
[10]
Information geometry and alternating minimization proce- dures.Statistics and Decisions, 1984
Imre Csisz´ ar and G´ abor Tusn´ ady. Information geometry and alternating minimization proce- dures.Statistics and Decisions, 1984. Supplement Issue 1, 205–237
1984
-
[11]
Calibration estimators in survey sampling.Journal of the American Statistical Association, 87(418):376–382, 1992
Jean-Claude Deville and Carl-Erik S¨ arndal. Calibration estimators in survey sampling.Journal of the American Statistical Association, 87(418):376–382, 1992
1992
-
[12]
DiCiccio, Peter Hall, and Joseph P
Thomas J. DiCiccio, Peter Hall, and Joseph P. Romano. Empirical likelihood is Bartlett- correctable.The Annals of Statistics, 19(2):1053–1061, 1991
1991
-
[13]
Dieng, Dustin Tran, Rajesh Ranganath, John Paisley, and David M
Adji B. Dieng, Dustin Tran, Rajesh Ranganath, John Paisley, and David M. Blei. Variational inference viaχupper bound minimization. InAdvances in Neural Information Processing Systems (NeurIPS), pages 2729–2738, 2017
2017
-
[14]
Variational inference based on robust divergences
Futoshi Futami, Issei Sato, and Masashi Sugiyama. Variational inference based on robust divergences. InInternational Conference on Artificial Intelligence and Statistics (AISTATS), volume 84 ofProceedings of Machine Learning Research, pages 813–822, 2018
2018
-
[15]
Tilmann Gneiting and Adrian E. Raftery. Strictly proper scoring rules, prediction, and esti- mation.Journal of the American Statistical Association, 102(477):359–378, 2007
2007
-
[16]
Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. InAdvances in Neural Information Processing Systems (NeurIPS), pages 2672–2680, 2014
2014
-
[17]
Gr¨ unwald and A
Peter D. Gr¨ unwald and A. Philip Dawid. Game theory, maximum entropy, minimum discrep- ancy and robust Bayesian decision theory.The Annals of Statistics, 32(4):1367–1433, 2004
2004
-
[18]
Large sample properties of generalized method of moments estimators
Lars Peter Hansen. Large sample properties of generalized method of moments estimators. Econometrica, 50(4):1029–1054, 1982
1982
-
[19]
Hinton, Peter Dayan, Brendan J
Geoffrey E. Hinton, Peter Dayan, Brendan J. Frey, and Radford M. Neal. The wake-sleep algorithm for unsupervised neural networks.Science, 268(5214):1158–1161, 1995
1995
-
[20]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems (NeurIPS), pages 6840–6851, 2020
2020
-
[21]
Horvitz and Donovan J
Daniel G. Horvitz and Donovan J. Thompson. A generalization of sampling without replace- ment from a finite universe.Journal of the American Statistical Association, 47(260):663–685, 1952
1952
-
[22]
Estimation of non-normalized statistical models by score matching.Journal of Machine Learning Research, 6(24):695–709, 2005
Aapo Hyv¨ arinen. Estimation of non-normalized statistical models by score matching.Journal of Machine Learning Research, 6(24):695–709, 2005. 34
2005
-
[23]
Information geometry of the EM and em algorithms for neural networks
Shun ichi Amari. Information geometry of the EM and em algorithms for neural networks. Neural Networks, 8(9):1379–1408, 1995
1995
-
[24]
American Mathe- matical Society and Oxford University Press, 2000
Shun ichi Amari and Hiroshi Nagaoka.Methods of Information Geometry. American Mathe- matical Society and Oxford University Press, 2000
2000
-
[25]
Bing-Yi Jing and Andrew T. A. Wood. Exponential empirical likelihood is not Bartlett cor- rectable.The Annals of Statistics, 24(1):365–369, 1996
1996
-
[26]
Bregman projection for calibration esti- mation in survey sampling
Jae Kwang Kim, Yonghyun Kwon, and Yumou Qiu. Bregman projection for calibration esti- mation in survey sampling. submitted (https://arxiv.org/abs/2603.20780), 2026
Pith/arXiv arXiv 2026
-
[27]
Kingma and Max Welling
Diederik P. Kingma and Max Welling. Auto-encoding variational Bayes. InInternational Conference on Learning Representations (ICLR), 2014
2014
-
[28]
Robustness, infinitesimal neighbor- hoods, and moment restrictions.Econometrica, 81(3):1185–1201, 2013
Yuichi Kitamura, Taisuke Otsu, and Kirill Evdokimov. Robustness, infinitesimal neighbor- hoods, and moment restrictions.Econometrica, 81(3):1185–1201, 2013
2013
-
[29]
An information-theoretic alternative to generalized method of moments estimation.Econometrica, 65(4):861–874, 1997
Yuichi Kitamura and Michael Stutzer. An information-theoretic alternative to generalized method of moments estimation.Econometrica, 65(4):861–874, 1997
1997
-
[30]
Jeremias Knoblauch, Jack Jewson, and Theodoros Damoulas. Generalized variational infer- ence: Three arguments for deriving new posteriors.arXiv preprint arXiv:1904.02063, 2019
arXiv 1904
-
[31]
Yingzhen Li and Richard E. Turner. R´ enyi divergence variational inference. InAdvances in Neural Information Processing Systems (NeurIPS), pages 1081–1089, 2016
2016
-
[32]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[33]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[34]
Nelder.Generalized Linear Models
Peter McCullagh and John A. Nelder.Generalized Linear Models. Chapman & Hall/CRC, 2nd edition, 1989
1989
-
[35]
Thomas P. Minka. Expectation propagation for approximate Bayesian inference. InProceedings of the Seventeenth Conference on Uncertainty in Artificial Intelligence, pages 362–369, 2001
2001
-
[36]
Thomas P. Minka. Divergence measures and message passing. Technical Report MSR-TR- 2005-173, Microsoft Research, 2005
2005
-
[37]
Information geometry of U-boost and Bregman divergence.Neural Computation, 16(7):1437–1481, 2004
Noboru Murata, Takashi Takenouchi, Takafumi Kanamori, and Shinto Eguchi. Information geometry of U-boost and Bregman divergence.Neural Computation, 16(7):1437–1481, 2004
2004
-
[38]
Neal and Geoffrey E
Radford M. Neal and Geoffrey E. Hinton. A view of the EM algorithm that justifies incremen- tal, sparse, and other variants. In Michael I. Jordan, editor,Learning in Graphical Models, pages 355–368. Kluwer Academic Publishers, 1998
1998
-
[39]
Nelder and Robert W
John A. Nelder and Robert W. M. Wedderburn. Generalized linear models.Journal of the Royal Statistical Society, Series A, 135(3):370–384, 1972. 35
1972
-
[40]
Newey and Richard J
Whitney K. Newey and Richard J. Smith. Higher order properties of GMM and generalized empirical likelihood estimators.Econometrica, 72(1):219–255, 2004
2004
-
[41]
InAdvances in Neural Information Processing Systems (NeurIPS), pages 271–279, 2016
Sebastian Nowozin, Botond Cseke, and Ryota Tomioka.f-GAN: Training generative neu- ral samplers using variational divergence minimization. InAdvances in Neural Information Processing Systems (NeurIPS), pages 271–279, 2016
2016
-
[42]
Art B. Owen. Empirical likelihood ratio confidence intervals for a single functional.Biometrika, 75(2):237–249, 1988
1988
-
[43]
Stochastic backpropagation and approximate inference in deep generative models
Danilo Jimenez Rezende, Shakir Mohamed, and Daan Wierstra. Stochastic backpropagation and approximate inference in deep generative models. InProceedings of the 31st International Conference on Machine Learning, volume 32 ofProceedings of Machine Learning Research, pages 1278–1286. PMLR, 2014
2014
-
[44]
Schennach
Susanne M. Schennach. Point estimation with exponentially tilted empirical likelihood.The Annals of Statistics, 35(2):634–672, 2007
2007
-
[45]
Generative modeling by estimating gradients of the data distribution
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. InAdvances in Neural Information Processing Systems (NeurIPS), pages 11918– 11930, 2019
2019
-
[46]
Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations (ICLR), 2021
2021
-
[47]
Tanner and Wing Hung Wong
Martin A. Tanner and Wing Hung Wong. The calculation of posterior distributions by data augmentation.Journal of the American Statistical Association, 82(398):528–540, 1987
1987
-
[48]
A connection between score matching and denoising autoencoders.Neural Computation, 23(7):1661–1674, 2011
Pascal Vincent. A connection between score matching and denoising autoencoders.Neural Computation, 23(7):1661–1674, 2011
2011
-
[49]
InAdvances in Neural Information Processing Systems (NeurIPS), pages 17370–17379, 2020
Neng Wan, Dapeng Li, and Naira Hovakimyan.f-divergence variational inference. InAdvances in Neural Information Processing Systems (NeurIPS), pages 17370–17379, 2020
2020
-
[50]
Chris Jones
Janette Warwick and M. Chris Jones. Choosing a robustness tuning parameter.Journal of Statistical Computation and Simulation, 75(7):581–588, 2005
2005
-
[51]
Divergence function, duality, and convex analysis.Neural Computation, 16(1):159– 195, 2004
Jun Zhang. Divergence function, duality, and convex analysis.Neural Computation, 16(1):159– 195, 2004. 36
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.