A Causal DAG Prior for Synthetic Time-Series Classification Datasets
Pith reviewed 2026-06-26 14:17 UTC · model grok-4.3
The pith
A causal DAG prior over tabular and time-series nodes generates synthetic datasets that improve finetuned time-series classification performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
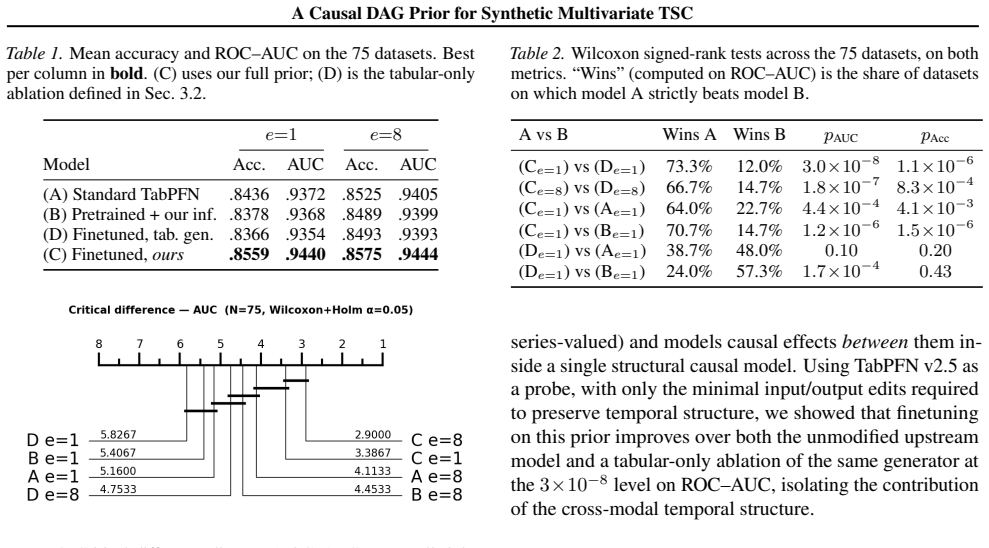
The paper claims that a causal prior built from randomly sampled DAGs over typed nodes for tabular and time series modalities can synthesize complete labelled TSC datasets. When TabPFN is finetuned on such data, it significantly outperforms both the unmodified model and a tabular ablation on 75 UCR/UEA datasets, with the temporal structure providing the key advantage.
What carries the argument
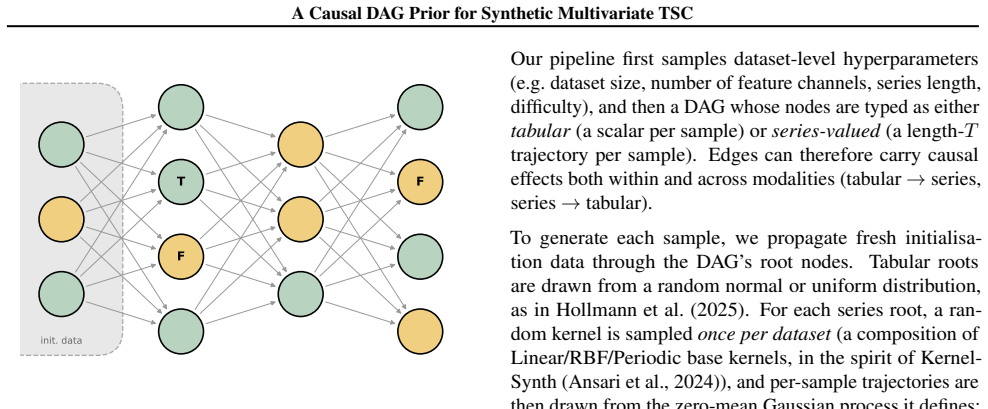
Randomly sampled causal DAGs over typed nodes spanning tabular attributes, time series channels, timesteps, and labels, used to generate synthetic datasets with cross-modal causal structure.
If this is right
- Models finetuned this way show improved ROC-AUC on real time-series classification problems.
- The cross-modal temporal causal structure contributes measurably beyond tabular causal modeling alone.
- This prior enables the creation of multivariate multi-class datasets that reflect causal dependencies across modalities.
- The approach supports better inductive bias transfer for time-series tasks.
Where Pith is reading between the lines
- Similar causal priors could help in generating data for other machine learning tasks involving multiple data types.
- The random sampling of DAGs might be tuned with domain-specific constraints to better match particular real-world distributions.
- This could lead to more efficient use of limited real data by pretraining on large synthetic sets.
Load-bearing premise
Synthetic datasets produced by sampling random causal DAGs over the typed nodes have joint distributions close enough to real data that finetuning transfers the right inductive biases.
What would settle it
A failure to observe statistically significant gains in ROC-AUC from the full causal generator compared to the tabular-only version on the set of 75 benchmarks would indicate that the temporal structure does not provide transferable benefits.
Figures
read the original abstract
A Prior-data fitted Network learns the posterior predictive induced by its training prior; bringing this paradigm to multivariate time-series classification therefore calls for a synthetic generator that produces complete labelled datasets with temporal structure. We introduce a causal prior that synthesizes each dataset from a randomly sampled DAG over typed nodes across two modalities (tabular attributes and time series), natively producing multivariate, multi-class TSC datasets with cross-modal causal structure across channels, timesteps and labels, a regime not addressed by existing synthetic priors. To validate the prior, we finetune TabPFN v2.5 with minimal adaptations and evaluate on 75 UCR/UEA datasets within TabPFN's operating regime. Finetuning on our generator significantly outperforms both the unmodified upstream model and a tabular-only ablation of the same prior (Wilcoxon signed-rank $p=3.0\times 10^{-8}$ on ROC-AUC), isolating the contribution of the cross-modal temporal structure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a causal DAG prior over typed nodes spanning tabular attributes and time series to generate synthetic labeled multivariate TSC datasets with cross-modal causal dependencies. It validates the prior by minimally adapting and finetuning TabPFN v2.5 on data from the generator, reporting statistically significant gains over the unmodified upstream model and a tabular-only ablation on 75 UCR/UEA benchmarks (Wilcoxon signed-rank p=3.0×10^{-8} on ROC-AUC).
Significance. If the randomly sampled DAGs induce synthetic distributions whose temporal and cross-modal structure transfers useful inductive biases, the approach offers a scalable route to equip prior-data fitted networks with explicit temporal causal modeling for TSC, a regime where large labeled corpora are scarce. The external-benchmark evaluation and tabular ablation provide a clean isolation of the temporal component.
major comments (2)
- [Methods (generator construction)] The precise DAG sampling procedure, node-type definitions, and conditional distribution parameterizations (e.g., how parent nodes determine time-series generation across timesteps) are not specified with sufficient detail or pseudocode to allow reproduction or verification that key real-TSC properties (periodicity, long-range dependence, stationarity) are reproduced. This directly bears on the weakest assumption that the synthetic joint distribution is close enough for finetuning to transfer.
- [Experiments / Evaluation] No quantitative diagnostics (e.g., autocorrelation spectra, cross-channel dependence measures, or distributional distances) comparing the generated synthetic datasets to the 75 UCR/UEA benchmarks are reported. Without such checks, the performance lift cannot be confidently attributed to distributional match rather than incidental regularization effects.
minor comments (2)
- [Abstract] The abstract states 'natively producing multivariate, multi-class TSC datasets' but does not clarify the supported range of sequence lengths or number of classes; a short table or sentence in §3 would help.
- [Methods] Notation for the typed nodes (tabular vs. temporal) and the exact form of the causal mechanisms should be introduced with a small illustrative DAG figure early in the methods.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive review. We address each of the major comments below.
read point-by-point responses
-
Referee: [Methods (generator construction)] The precise DAG sampling procedure, node-type definitions, and conditional distribution parameterizations (e.g., how parent nodes determine time-series generation across timesteps) are not specified with sufficient detail or pseudocode to allow reproduction or verification that key real-TSC properties (periodicity, long-range dependence, stationarity) are reproduced. This directly bears on the weakest assumption that the synthetic joint distribution is close enough for finetuning to transfer.
Authors: We agree that the current manuscript lacks sufficient detail for full reproducibility of the generator. In the revised version, we will expand the Methods section to include explicit definitions of node types, a step-by-step description of the DAG sampling procedure, pseudocode for the generation process, and the specific parameterizations used for conditional distributions of time series given parents. This will enable verification of key properties such as periodicity and long-range dependence. revision: yes
-
Referee: [Experiments / Evaluation] No quantitative diagnostics (e.g., autocorrelation spectra, cross-channel dependence measures, or distributional distances) comparing the generated synthetic datasets to the 75 UCR/UEA benchmarks are reported. Without such checks, the performance lift cannot be confidently attributed to distributional match rather than incidental regularization effects.
Authors: The referee raises a valid point regarding the attribution of performance gains. Our evaluation demonstrates statistically significant improvements on real benchmarks when using the full causal prior compared to both the unmodified model and the tabular-only ablation, which helps isolate the role of temporal cross-modal structure. However, to further support that the gains stem from distributional similarity rather than regularization alone, we will include quantitative diagnostics such as autocorrelation spectra, cross-channel dependence measures, and distributional distances between synthetic and real datasets in the revised manuscript. revision: yes
Circularity Check
No significant circularity; central claim validated on external real benchmarks
full rationale
The paper's derivation chain centers on generating synthetic TSC datasets via random DAG sampling over typed nodes and then finetuning TabPFN on those datasets, with the key result being superior ROC-AUC on 75 held-out UCR/UEA real datasets versus both the unmodified model and a tabular ablation. This performance metric is measured on independent external data, not on any quantity defined, fitted, or generated inside the prior itself. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the abstract or described methodology; the ablation isolates the temporal contribution without reducing to a tautology. The distributional-match assumption is a standard empirical risk, not a circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- DAG sampling hyperparameters
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations (ICLR) , year=
Hollmann, Noah and M. International Conference on Learning Representations (ICLR) , year=
-
[2]
Nature , year=
Accurate predictions on small data with a tabular foundation model , author=. Nature , year=
-
[4]
Transformers Can Do
M. Transformers Can Do. International Conference on Learning Representations (ICLR) , year=
-
[5]
UAI Workshop on Causal Inference for Time Series Data , year=
Dynamic Structural Causal Models , author=. UAI Workshop on Causal Inference for Time Series Data , year=
-
[6]
International Conference on Machine Learning (ICML) , pages=
On the difficulty of training recurrent neural networks , author=. International Conference on Machine Learning (ICML) , pages=
-
[7]
and Wang, Hao and Mahoney, Michael W
Ansari, Abdul Fatir and Stella, Lorenzo and Turkmen, Caner and Zhang, Xiyuan and Mercado, Pedro and Shen, Huibin and Shchur, Oleksandr and Rangapuram, Syama Sundar and Pineda Arango, Sebastian and Kapoor, Shubham and Zschiegner, Jasper and Maddix, Danielle C. and Wang, Hao and Mahoney, Michael W. and Torkkola, Kari and Wilson, Andrew Gordon and Bohlke-Sch...
-
[8]
Goswami, Mononito and Szafer, Konrad and Choudhry, Arjun and Cai, Yifu and Li, Shuo and Dubrawski, Artur , booktitle=
-
[9]
Feofanov, Vasilii and Wen, Songkang and Alonso, Marius and Ilbert, Romain and Guo, Hongbo and Tiomoko, Malik and Pan, Lujia and Zhang, Jianfeng and Redko, Ievgen , journal=
-
[10]
Xie, Shifeng and Feofanov, Vasilii and Odonnat, Ambroise and Zan, Lei and Alonso, Marius and Zhang, Jianfeng and Palpanas, Themis and Pan, Lujia and Zhang, Keli and Redko, Ievgen , journal=
-
[11]
Yeh, Chin-Chia Michael and Saini, Uday Singh and Wang, Junpeng and Dai, Xin and Fan, Xiran and Sun, Jiarui and Fan, Yujie and Zheng, Yan , journal=
-
[12]
International Conference on Learning Representations (ICLR) , year=
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers , author=. International Conference on Learning Representations (ICLR) , year=
-
[13]
Dau, Hoang Anh and Bagnall, Anthony and Kamgar, Kaveh and Yeh, Chin-Chia Michael and Zhu, Yan and Gharghabi, Shaghayegh and Ratanamahatana, Chotirat Ann and Keogh, Eamonn , journal=. The
-
[14]
Bagnall, Anthony and Dau, Hoang Anh and Lines, Jason and Flynn, Michael and Large, James and Bostrom, Aaron and Southam, Paul and Keogh, Eamonn , journal=. The
-
[15]
Data Mining and Knowledge Discovery , volume=
Dempster, Angus and Petitjean, Fran. Data Mining and Knowledge Discovery , volume=
-
[16]
Journal of Machine Learning Research , volume=
Middlehurst, Matthew and Ismail-Fawaz, Ali and Guillaume, Antoine and Holder, Christopher and Guijo-Rubio, David and Bulatova, Guzal and Tsaprounis, Leonidas and Mentel, Lukasz and Walter, Martin and Sch. Journal of Machine Learning Research , volume=
-
[17]
Journal of Machine Learning Research , volume=
Statistical Comparisons of Classifiers over Multiple Data Sets , author=. Journal of Machine Learning Research , volume=
-
[18]
F., Stella, L., Turkmen, C., Zhang, X., Mercado, P., Shen, H., Shchur, O., Rangapuram, S
Ansari, A. F., Stella, L., Turkmen, C., Zhang, X., Mercado, P., Shen, H., Shchur, O., Rangapuram, S. S., Pineda Arango, S., Kapoor, S., Zschiegner, J., Maddix, D. C., Wang, H., Mahoney, M. W., Torkkola, K., Wilson, A. G., Bohlke-Schneider, M., and Wang, Y. Chronos : Learning the language of time series. Transactions on Machine Learning Research (TMLR), 2024
2024
-
[19]
The UEA multivariate time series classification archive, 2018
Bagnall, A., Dau, H. A., Lines, J., Flynn, M., Large, J., Bostrom, A., Southam, P., and Keogh, E. The UEA multivariate time series classification archive, 2018. arXiv preprint arXiv:1811.00075, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[20]
and Mooij, J
Boeken, P. and Mooij, J. M. Dynamic structural causal models. In UAI Workshop on Causal Inference for Time Series Data, 2024
2024
-
[21]
A., Bagnall, A., Kamgar, K., Yeh, C.-C
Dau, H. A., Bagnall, A., Kamgar, K., Yeh, C.-C. M., Zhu, Y., Gharghabi, S., Ratanamahatana, C. A., and Keogh, E. The UCR time series archive. IEEE/CAA Journal of Automatica Sinica, 6 0 (6): 0 1293--1305, 2019
2019
-
[22]
Statistical comparisons of classifiers over multiple data sets
Dem s ar, J. Statistical comparisons of classifiers over multiple data sets. Journal of Machine Learning Research, 7: 0 1--30, 2006
2006
-
[23]
Mantis: Lightweight Foundation Model for Time Series Classification
Feofanov, V., Wen, S., Alonso, M., Ilbert, R., Guo, H., Tiomoko, M., Pan, L., Zhang, J., and Redko, I. Mantis : Lightweight calibrated foundation model for user-friendly time series classification. arXiv preprint arXiv:2502.15637, 2025
work page internal anchor Pith review arXiv 2025
-
[24]
MOMENT : A family of open time-series foundation models
Goswami, M., Szafer, K., Choudhry, A., Cai, Y., Li, S., and Dubrawski, A. MOMENT : A family of open time-series foundation models. In International Conference on Machine Learning (ICML), 2024
2024
-
[25]
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
Grinsztajn, L., Fl \"o ge, K., Key, O., Birkel, F., Jund, P., Roof, B., J \"a ger, B., Safaric, D., Alessi, S., Hayler, A., Manium, M., Yu, R., Jablonski, F., Hoo, S. B., Garg, A., Robertson, J., B \"u hler, M., Moroshan, V., Purucker, L., Cornu, C., Wehrhahn, L. C., Bonetto, A., Sch \"o lkopf, B., Gambhir, S., Hollmann, N., and Hutter, F. TabPFN-2.5 : Ad...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
TabPFN : A transformer that solves small tabular classification problems in a second
Hollmann, N., M \"u ller, S., Eggensperger, K., and Hutter, F. TabPFN : A transformer that solves small tabular classification problems in a second. In International Conference on Learning Representations (ICLR), 2023
2023
-
[27]
u ller, S., Purucker, L., Krishnakumar, A., K \
Hollmann, N., M \"u ller, S., Purucker, L., Krishnakumar, A., K \"o rfer, M., Hoo, S. B., Schirrmeister, R. T., and Hutter, F. Accurate predictions on small data with a tabular foundation model. Nature, 2025
2025
-
[28]
aeon : a P ython toolkit for learning from time series
Middlehurst, M., Ismail-Fawaz, A., Guillaume, A., Holder, C., Guijo-Rubio, D., Bulatova, G., Tsaprounis, L., Mentel, L., Walter, M., Sch \"a fer, P., and Bagnall, A. aeon : a P ython toolkit for learning from time series. Journal of Machine Learning Research, 25 0 (289): 0 1--10, 2024
2024
-
[29]
Transformers can do B ayesian inference
M \"u ller, S., Hollmann, N., Pineda Arango, S., Grabocka, J., and Hutter, F. Transformers can do B ayesian inference. In International Conference on Learning Representations (ICLR), 2022
2022
-
[30]
H., Sinthong, P., and Kalagnanam, J
Nie, Y., Nguyen, N. H., Sinthong, P., and Kalagnanam, J. A time series is worth 64 words: Long-term forecasting with transformers. In International Conference on Learning Representations (ICLR), 2023
2023
-
[31]
On the difficulty of training recurrent neural networks
Pascanu, R., Mikolov, T., and Bengio, Y. On the difficulty of training recurrent neural networks. In International Conference on Machine Learning (ICML), pp.\ 1310--1318, 2013
2013
-
[32]
CauKer : Classification time series foundation models can be pretrained on synthetic data
Xie, S., Feofanov, V., Odonnat, A., Zan, L., Alonso, M., Zhang, J., Palpanas, T., Pan, L., Zhang, K., and Redko, I. CauKer : Classification time series foundation models can be pretrained on synthetic data. arXiv preprint arXiv:2508.02879, 2025
-
[33]
Yeh, C.-C. M., Saini, U. S., Wang, J., Dai, X., Fan, X., Sun, J., Fan, Y., and Zheng, Y. TiCT : A synthetically pre-trained foundation model for time series classification. arXiv preprint arXiv:2511.19694, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.