Early-Exit Graph Neural Networks for Link Prediction
Pith reviewed 2026-06-26 12:13 UTC · model grok-4.3
The pith
Graph neural networks for link prediction can exit computation early at intermediate layers without extra training signals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
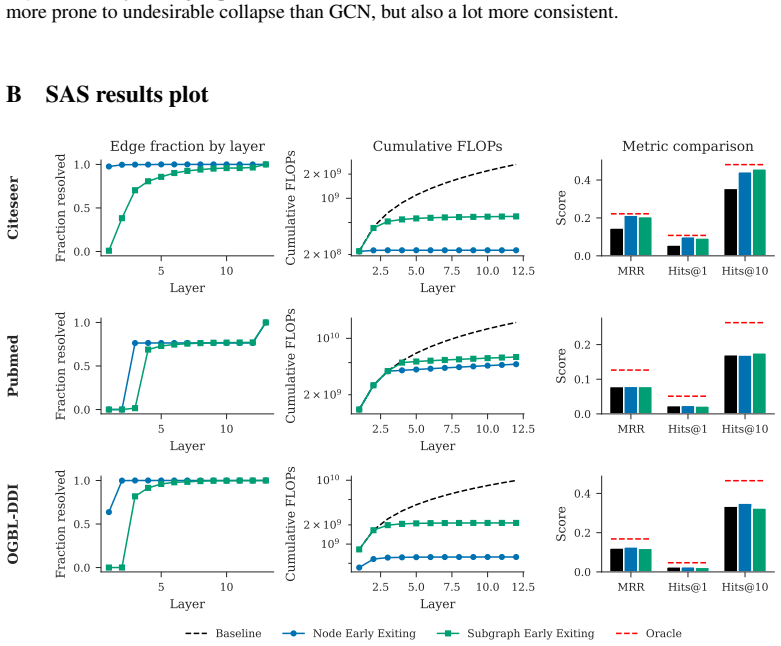
Early-exiting strategies can be applied to Graph Neural Networks to solve the problem of link-prediction faster. The method uses no auxiliary losses to enforce early exiting, allowing it to emerge as an implicit property of the architecture. The findings show that inference speed of GNNs on many link-prediction problems can be improved while losing little or even winning in terms of prediction quality, as measured by moving the Pareto frontier on the HeaRT benchmark for GCN and SAS-GNN backbones.
What carries the argument
Implicit early-exiting mechanism in multi-layer GNNs for link prediction, where the model can halt at an intermediate layer based on its learned node representations without any auxiliary loss to force early decisions.
If this is right
- Inference speed improves on many link-prediction problems while losing little or even gaining in prediction quality.
- The speed-quality Pareto frontier moves for GCN and SAS-GNN backbones on the HeaRT benchmark.
- Early exiting appears across several different experimental setups without needing extra losses.
- The same architecture can be run at variable depths depending on the input, producing a family of faster models.
Where Pith is reading between the lines
- The same implicit exiting might appear in GNNs trained for node classification or graph classification, widening the method beyond link prediction.
- Energy use in production systems on very large graphs could drop if the early-exit pattern holds at scale.
- Designers of new GNN layers could deliberately encourage or measure this implicit property rather than treating depth as fixed.
Load-bearing premise
That early-exiting behavior emerges reliably as an implicit property without auxiliary losses and that results on the HeaRT benchmark generalize to other link-prediction settings.
What would settle it
A controlled test on a held-out large link-prediction graph where the early-exit version either never stops early or produces clearly lower accuracy than the full-depth model.
Figures

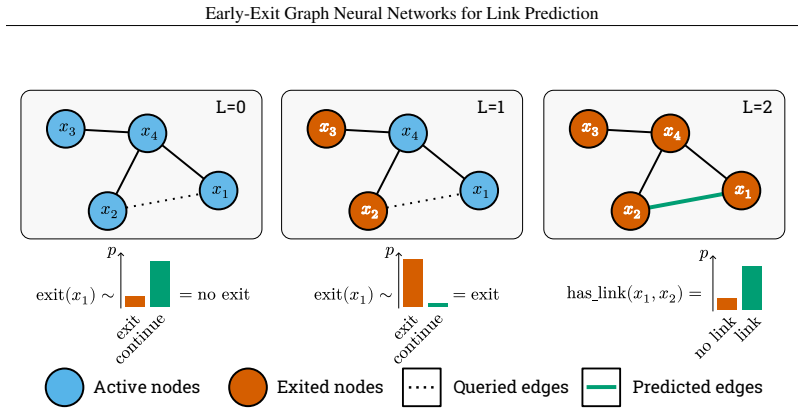
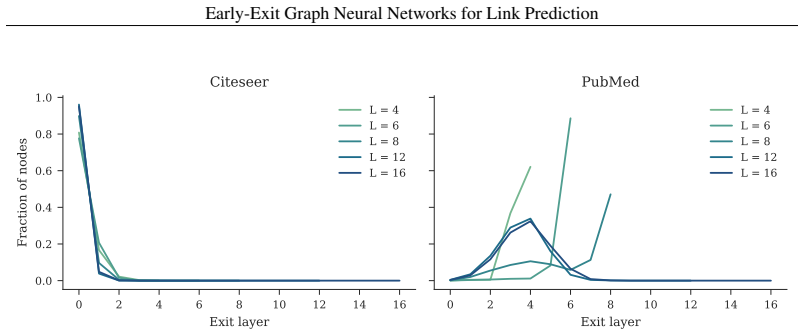
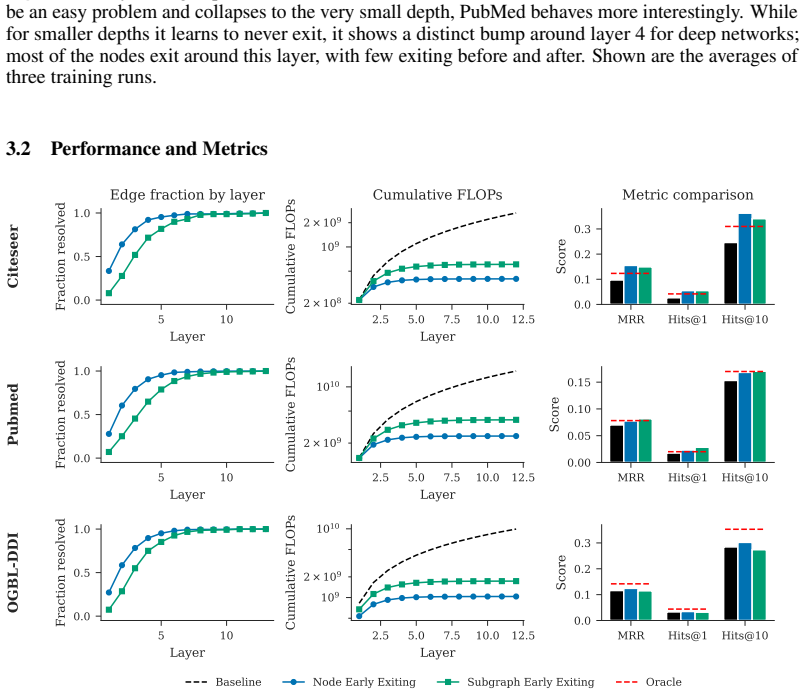
read the original abstract
Graph Neural Networks are great for link prediction in various network-like structures; however, the question of their speed/quality tradeoff has been barely studied. While in practice the time it takes to do inference matters little for small benchmarks, the latency does limit applicability in large-scale domains. In this work, we explore early-exiting strategies that can be applied to Graph Neural Networks to solve the problem of link-prediction faster. We use no auxiliary losses to enforce early exiting, allowing it to emerge as an implicit property of the architecture. We show that our method enables early exiting in several setups, moving the Pareto frontier on the HeaRT benchmark for GCN and SAS-GNN backbones. Our findings show that inference speed of GNNs on many link-prediction problems can be improved, while losing little, or even winning in terms of prediction quality. The code is available in our repository: https://github.com/knyazer/link_prediction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes early-exiting strategies for Graph Neural Networks on link prediction tasks. It claims that early exiting emerges implicitly as a property of the architecture without auxiliary losses, enabling faster inference while preserving or improving quality, and reports that the approach moves the Pareto frontier on the HeaRT benchmark for GCN and SAS-GNN backbones. Code is released at https://github.com/knyazer/link_prediction.
Significance. If the results hold under rigorous controls, the work could meaningfully advance efficient inference for GNN-based link prediction on large graphs by reducing latency with minimal quality trade-off. The decision to forgo auxiliary losses and rely on implicit emergence is a distinguishing design choice; the public code release supports reproducibility.
major comments (2)
- [Abstract] Abstract: the central claim that early-exiting behavior 'emerges as an implicit property' and produces a genuine Pareto improvement is stated without any reported metrics, error bars, baseline controls, or per-layer accuracy-vs-compute curves, so the empirical support for the claim cannot be evaluated from the given text.
- [Abstract] The manuscript provides no description of the exit decision rule (e.g., confidence threshold, layer-wise scoring function, or stopping criterion) used at inference time. This detail is load-bearing for verifying that exits occur reliably without auxiliary losses rather than being an artifact of the specific HeaRT benchmark setup.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address the two major points on the abstract below. We will revise the abstract to strengthen the presentation of empirical results and to clarify the exit decision rule.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that early-exiting behavior 'emerges as an implicit property' and produces a genuine Pareto improvement is stated without any reported metrics, error bars, baseline controls, or per-layer accuracy-vs-compute curves, so the empirical support for the claim cannot be evaluated from the given text.
Authors: We agree the abstract is concise and omits specific numbers. The full manuscript reports metrics with error bars, baseline comparisons, and per-layer accuracy-vs-compute curves on the HeaRT benchmark that support the Pareto improvement for the GCN and SAS-GNN backbones. We will revise the abstract to include key quantitative results (e.g., observed speedups and quality metrics) so the empirical support is more evident directly from the abstract. revision: yes
-
Referee: [Abstract] The manuscript provides no description of the exit decision rule (e.g., confidence threshold, layer-wise scoring function, or stopping criterion) used at inference time. This detail is load-bearing for verifying that exits occur reliably without auxiliary losses rather than being an artifact of the specific HeaRT benchmark setup.
Authors: The exit decision rule is described in the methods section of the full manuscript as part of the implicit early-exiting procedure. To address the concern that this detail is insufficiently highlighted, we will revise the abstract to include a brief description of the inference-time stopping criterion (layer-wise scoring without auxiliary losses). revision: yes
Circularity Check
No circularity: purely empirical benchmark results with no derivations or self-referential predictions
full rationale
The paper presents an empirical study of early-exiting GNNs for link prediction on the HeaRT benchmark. It reports that early-exiting emerges implicitly without auxiliary losses and shifts the Pareto frontier for GCN and SAS-GNN backbones. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided abstract or description. The central claim rests on benchmark measurements rather than any reduction to inputs by construction. This matches the default expectation of no circularity for non-derivational empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Early-exit graph neural networks.ArXiv, abs/2505.18088, 2025
Andrea Giuseppe Di Francesco, Maria Sofia Bucarelli, Franco Maria Nardini, Raffaele Perego, Nicola Tonellotto, and Fabrizio Silvestri. Early-exit graph neural networks.ArXiv, abs/2505.18088, 2025. URL https://api.semanticscholar.org/CorpusID:278886684. 1, 2, 3, 4
arXiv 2025
-
[2]
John Jumper, Richard Evans, Alexander Pritzel, Tim Green, Michael Figurnov, Olaf Ron- neberger, Kathryn Tunyasuvunakool, Russ Bates, Augustin Žídek, Anna Potapenko, Alex Bridgland, Clemens Meyer, Simon A. A. Kohl, Andrew J. Ballard, Andrew Cowie, Bernardino Romera-Paredes, Stanislav Nikolov, Rishub Jain, Jonas Adler, Trevor Back, Stig Petersen, David Reim...
-
[3]
Kipf and Max Welling
Thomas N. Kipf and Max Welling. Semi-Supervised Classification with Graph Convolutional Networks. InICLR, 2017. 1, 2
2017
-
[4]
Hamilton, Zhitao Ying, and Jure Leskovec
William L. Hamilton, Zhitao Ying, and Jure Leskovec. Inductive Representation Learning on Large Graphs. InNIPS, pages 1024–1034, 2017. 1, 3
2017
-
[5]
Revisiting graph neural networks: All we have is low-pass filters, 2019
Hoang NT and Takanori Maehara. Revisiting graph neural networks: All we have is low-pass filters, 2019. URLhttps://arxiv.org/abs/1905.09550. 1
Pith/arXiv arXiv 2019
-
[6]
T. Konstantin Rusch, Michael M. Bronstein, and Siddhartha Mishra. A survey on oversmoothing in graph neural networks, 2023. URLhttps://arxiv.org/abs/2303.10993. 1
arXiv 2023
-
[7]
Haimin Zhang, Min Xu, Guoqiang Zhang, and Kenta Niwa. Ssfg: Stochastically scaling features and gradients for regularizing graph convolutional networks.IEEE Transactions on Neural Networks and Learning Systems, 35(2):2223–2234, February 2024. ISSN 2162-2388. doi: 10.1109/tnnls.2022.3188888. URL http://dx.doi.org/10.1109/TNNLS.2022.3188888. 1
-
[8]
Konstantin Rusch, Ben Chamberlain, James Rowbottom, Siddhartha Mishra, and Michael Bronstein
T. Konstantin Rusch, Ben Chamberlain, James Rowbottom, Siddhartha Mishra, and Michael Bronstein. Graph-coupled oscillator networks. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sabato, editors,Proceedings of the 39th Inter- national Conference on Machine Learning, volume 162 ofProceedings of Machine Learning Rese...
2022
-
[9]
Simone Scardapane, Michele Scarpiniti, Enzo Baccarelli, and Aurelio Uncini. Why should we add early exits to neural networks?Cognitive Computation, 12(5):954–966, September 2020. ISSN 1866-9964. doi: 10.1007/s12559-020-09734-4. URL https://doi.org/10.1007/ s12559-020-09734-4. 1
-
[10]
Indro Spinelli, Simone Scardapane, and Aurelio Uncini. Adaptive propagation graph con- volutional network.IEEE Transactions on Neural Networks and Learning Systems, 32(10): 4755–4760, October 2021. ISSN 2162-2388. doi: 10.1109/TNNLS.2020.3025110. URL https://doi.org/10.1109/TNNLS.2020.3025110. 1
-
[11]
Evaluating graph neural networks for link predic- tion: Current pitfalls and new benchmarking
Juanhui Li, Harry Shomer, Haitao Mao, Shenglai Zeng, Yao Ma, Neil Shah, Jil- iang Tang, and Dawei Yin. Evaluating graph neural networks for link predic- tion: Current pitfalls and new benchmarking. In A. Oh, T. Naumann, A. Glober- son, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Infor- 7 Early-Exit Graph Neural Networks for Link Predict...
-
[12]
URL https://proceedings.neurips.cc/paper_files/paper/2023/file/ 0be50b4590f1c5fdf4c8feddd63c4f67-Paper-Datasets_and_Benchmarks.pdf. 2
2023
-
[13]
Categorical reparameterization with gumbel-softmax,
Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with gumbel-softmax,
-
[14]
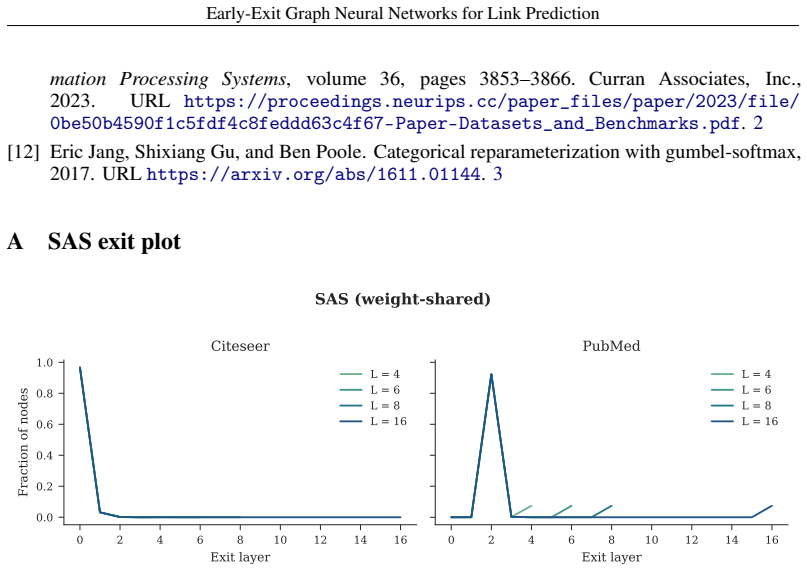
URLhttps://arxiv.org/abs/1611.01144. 3 A SAS exit plot 0 2 4 6 8 10 12 14 16 Exit layer 0.0 0.2 0.4 0.6 0.8 1.0 Fraction of nodes Citeseer L = 4 L = 6 L = 8 L = 16 0 2 4 6 8 10 12 14 16 Exit layer PubMed L = 4 L = 6 L = 8 L = 16 SAS (weight-shared) Figure 5:Early exiting depth distribution of SAS for PubMed and Citeseer. SAS seems to be a lot more prone t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.