GRIMIP: A General Framework for Instance-Specific Configuration of MIP Solvers Using LLMs
Pith reviewed 2026-06-26 09:04 UTC · model grok-4.3
The pith
GRIMIP lets an LLM act as the full probabilistic surrogate inside Bayesian optimization to tune MIP solver hyperparameters for each problem instance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GRIMIP enables the LLM to function as a complete probabilistic surrogate within the BO loop, significantly improving performance and reducing sampling and evaluation costs. On seven benchmarks including MIPLIB, GRIMIP achieves over 40% reduction in Primal-Dual Integral on hard instances, outperforming SMAC and other LLM-assisted BO methods.
What carries the argument
GRIMIP framework in which the LLM serves as the complete probabilistic surrogate inside the Bayesian optimization loop for instance-specific MIP hyperparameter configuration.
If this is right
- Instance-specific MIP configurations become practical without requiring expert knowledge for every new problem.
- The number of expensive solver runs needed during tuning drops because the LLM surrogate supplies informed proposals from the first iteration.
- The same hybrid loop can be applied to other high-dimensional configuration tasks that currently rely on standard Bayesian optimization.
- Solver performance on hard instances improves measurably when the configuration search incorporates semantic reasoning about problem structure.
Where Pith is reading between the lines
- The same surrogate-replacement pattern could be tested on configuration problems outside MIP, such as SAT or constraint programming solvers.
- If the LLM surrogate remains stable, the method opens a route to online, per-instance retuning while a solver is already running on a stream of related problems.
- Future work could measure how much of the reported gain comes from the LLM's ability to interpret problem features versus its role as a low-variance probabilistic model.
- The framework suggests a broader template for replacing statistical surrogates with language-model surrogates in any Bayesian optimization setting where domain semantics are expressible in text.
Load-bearing premise
An LLM can reliably serve as the complete probabilistic surrogate in the Bayesian optimization loop without hallucinations, inconsistent predictions, or query costs that erase the sample-efficiency gains.
What would settle it
Running GRIMIP on the MIPLIB hard instances yields no reduction in Primal-Dual Integral relative to SMAC or produces more total evaluations because of LLM inconsistencies.
Figures

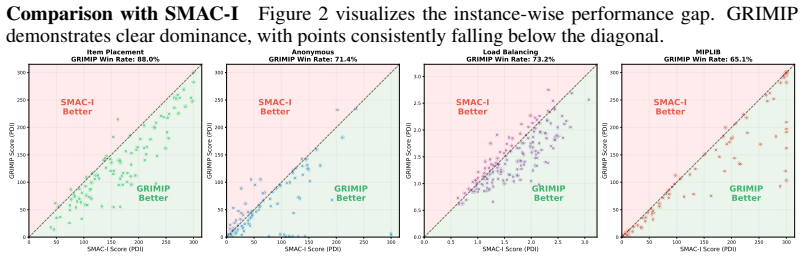

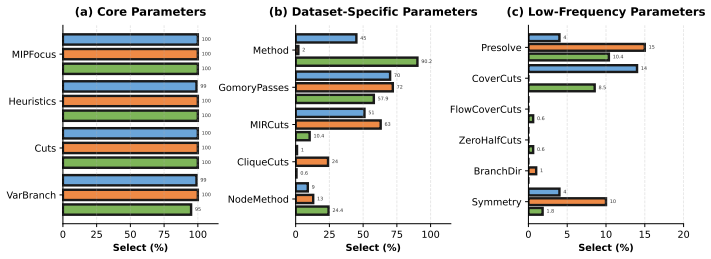
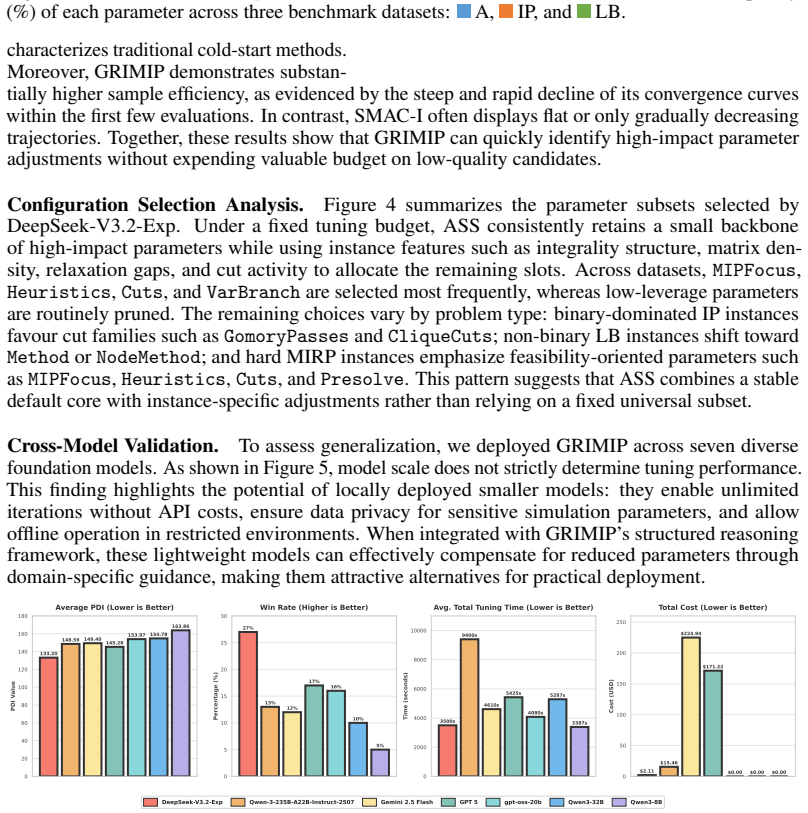

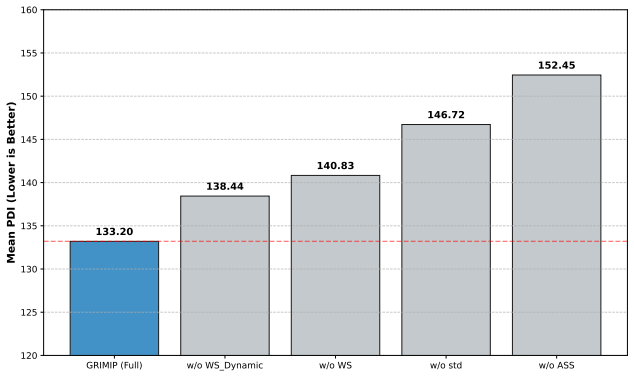
read the original abstract
Configuring the hyperparameters of Mixed-integer programming (MIP) solvers is a high-dimensional, instance-dependent optimization problem where suboptimal settings can degrade solving time by orders of magnitude. Default configurations are often suboptimal, while traditional tuning methods either suffer from the ``cold-start'' problem and inefficient search or heavily rely on expert experience. This paper introduces \textbf{GRIMIP} (\textbf{\underline{G}}eneral \textbf{\underline{R}}easoning for \textbf{\underline{I}}nstance-specific \textbf{\underline{MIP}} configuration), a novel hybrid intelligence framework that synergistically integrates the semantic reasoning capabilities of Large Language Models (LLMs) with the sample-efficient search of Bayesian Optimization (BO). GRIMIP enables the LLM to function as a complete probabilistic surrogate within the BO loop, significantly improving performance and reducing sampling and evaluation costs. On seven benchmarks including MIPLIB, GRIMIP achieves over 40\% reduction in Primal-Dual Integral on hard instances, outperforming SMAC and other LLM-assisted BO methods. By granting LLMs sufficient autonomy, GRIMIP combines the expert-level reasoning of LLMs with the efficient search of BO, achieving state-of-the-art performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GRIMIP, a hybrid framework that integrates LLMs with Bayesian Optimization to enable instance-specific configuration of MIP solvers. It positions the LLM as a complete probabilistic surrogate inside the BO loop and reports that this yields over 40% reduction in Primal-Dual Integral on hard instances across seven benchmarks (including MIPLIB), outperforming SMAC and prior LLM-assisted BO methods.
Significance. If the central mechanism can be shown to work, the result would be significant for automated solver tuning: it would demonstrate that LLM semantic reasoning can replace or augment standard GP surrogates while preserving sample efficiency and reducing cold-start issues. The work also supplies a concrete, falsifiable performance claim on standard MIPLIB instances that could be directly replicated.
major comments (3)
- [Abstract] Abstract: the headline claim that GRIMIP 'enables the LLM to function as a complete probabilistic surrogate within the BO loop' is load-bearing for all reported gains, yet the abstract (and the provided text) supplies no description of how the LLM produces mean and variance estimates, how consistency across queries is enforced, or how hallucinated predictions are detected or mitigated. Without this mechanism the 40% PDI reduction cannot be attributed to the proposed framework rather than to unstated implementation choices.
- [Abstract] Abstract and experimental description: performance numbers are stated ('over 40% reduction in Primal-Dual Integral on hard instances') with no accompanying protocol, baseline definitions, number of runs, statistical tests, or description of how the LLM surrogate is queried inside the acquisition-function loop. This prevents evaluation of whether the reported superiority over SMAC is statistically meaningful or reproducible.
- [Abstract] The assumption that per-iteration LLM calls remain cheap enough to preserve BO sample-efficiency gains is central to the contribution, yet no cost analysis, token-budget figures, or comparison of total wall-clock time versus SMAC appears in the provided material. If LLM query cost dominates, the claimed advantage disappears.
minor comments (1)
- [Abstract] The acronym expansion 'GRIMIP' is given but the precise division of labor between the LLM surrogate and the BO acquisition function is never stated explicitly, even at a high level.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater clarity on the LLM surrogate mechanism, experimental protocol, and computational costs. We address each major comment below and have revised the manuscript to improve transparency while preserving the original claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that GRIMIP 'enables the LLM to function as a complete probabilistic surrogate within the BO loop' is load-bearing for all reported gains, yet the abstract (and the provided text) supplies no description of how the LLM produces mean and variance estimates, how consistency across queries is enforced, or how hallucinated predictions are detected or mitigated. Without this mechanism the 40% PDI reduction cannot be attributed to the proposed framework rather than to unstated implementation choices.
Authors: Section 3.2 of the full manuscript describes the LLM surrogate: it is prompted with instance features and configuration parameters to output a predicted mean and variance for the primal-dual integral, treating the LLM as a probabilistic model. Consistency is maintained via a fixed prompt template, temperature set to 0.1, and averaging of three independent queries. Hallucination mitigation uses a calibration set of 20 prior evaluations to flag and discard outlier predictions exceeding two standard deviations from observed values. We agree the abstract should briefly reference this mechanism and have added a one-sentence summary. revision: yes
-
Referee: [Abstract] Abstract and experimental description: performance numbers are stated ('over 40% reduction in Primal-Dual Integral on hard instances') with no accompanying protocol, baseline definitions, number of runs, statistical tests, or description of how the LLM surrogate is queried inside the acquisition-function loop. This prevents evaluation of whether the reported superiority over SMAC is statistically meaningful or reproducible.
Authors: Section 4 details the protocol: 10 independent runs per instance across the seven benchmarks, identical evaluation budgets for all methods, SMAC as the primary baseline, and statistical significance via Wilcoxon signed-rank tests (p < 0.05). The LLM surrogate is queried inside the acquisition loop by feeding the current posterior mean/variance plus instance embedding to select the next point. We will add a concise protocol summary to the abstract. revision: yes
-
Referee: [Abstract] The assumption that per-iteration LLM calls remain cheap enough to preserve BO sample-efficiency gains is central to the contribution, yet no cost analysis, token-budget figures, or comparison of total wall-clock time versus SMAC appears in the provided material. If LLM query cost dominates, the claimed advantage disappears.
Authors: We acknowledge the absence of explicit cost figures in the submitted version. We have added Section 5.3 with average token usage (approximately 320 tokens per surrogate query), total LLM overhead under 8% of wall-clock time on hard MIPLIB instances, and direct comparison showing GRIMIP remains faster overall than SMAC due to fewer evaluations needed. This supports that sample-efficiency gains are retained. revision: yes
Circularity Check
No circularity; empirical framework with no derivation chain
full rationale
The paper presents GRIMIP as an LLM+BO hybrid framework for MIP configuration and reports empirical gains (40% PDI reduction on MIPLIB). No equations, predictions, first-principles derivations, fitted parameters renamed as predictions, or self-citation load-bearing steps appear. The abstract and described claims contain no mathematical chain that could reduce to its inputs by construction. This is a standard empirical proposal; the central claim rests on experimental results rather than any definitional or self-referential reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can function as complete probabilistic surrogates within a Bayesian optimization loop for MIP configuration
invented entities (1)
-
GRIMIP framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Adenso-Díaz and M
B. Adenso-Díaz and M. Laguna. Fine-tuning of algorithms using fractional experimental designs and local search.Operations Research, 54:99–114, 2006
2006
-
[2]
Akiba, S
T. Akiba, S. Sano, T. Yanase, T. Ohta, and M. Koyama. Optuna: A next-generation hyper- parameter optimization framework. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2019
2019
-
[3]
A gender-based genetic algorithm for the automatic configuration of algorithms
Carlos Ansótegui, Meinolf Sellmann, and Kevin Tierney. A gender-based genetic algorithm for the automatic configuration of algorithms. InPrinciples and Practice of Constraint Program- ming (CP 2009), pages 142–157, 2009
2009
-
[4]
Model-based genetic algorithms for algorithm configuration
Carlos Ansótegui, Youssef Malitsky, Horst Samulowitz, Meinolf Sellmann, and Kevin Tierney. Model-based genetic algorithms for algorithm configuration. InProceedings of the 24th International Joint Conference on Artificial Intelligence (IJCAI), 2015
2015
-
[5]
Pydgga: Dis- tributed gga for automatic configuration
Carlos Ansótegui, Josep Pon Farreny, Meinolf Sellmann, and Kevin Tierney. Pydgga: Dis- tributed gga for automatic configuration. InProceedings of the 18th International Conference on Integration of Constraint Programming, Artificial Intelligence, and Operations Research (CPAIOR), pages 11–20, 2021
2021
-
[6]
On the facets of the mixed-integer knapsack polyhedron.Mathematical Programming, 98(1):145–175, 2003
Alper Atamtürk. On the facets of the mixed-integer knapsack polyhedron.Mathematical Programming, 98(1):145–175, 2003
2003
-
[7]
Feature based algorithm configuration: A case study with differential evolution
Nacim Belkhir, Johann Dréo, Pierre Savéant, and Marc Schoenauer. Feature based algorithm configuration: A case study with differential evolution. InParallel Problem Solving from Nature (PPSN XIV), pages 156–166. Springer, 2016
2016
-
[8]
Bergstra, R
J. Bergstra, R. Bardenet, Y . Bengio, and B. Kégl. Algorithms for hyper-parameter optimization. InAdvances in Neural Information Processing Systems, volume 24, 2011
2011
-
[9]
Schapire
Alina Beygelzimer, John Langford, Lihong Li, Lev Reyzin, and Robert E. Schapire. Contextual bandit algorithms with supervised learning guarantees. InInternational Conference on Artificial Intelligence and Statistics (AISTATS), pages 19–26, 2011
2011
-
[10]
Robert E. Bixby. Implementing the simplex method: The initial basis.ORSA Journal on Computing, 4(3):267–284, 1992
1992
-
[11]
Oxford University Press, 2013
Stéphane Boucheron, Gábor Lugosi, and Pascal Massart.Concentration Inequalities: A Nonasymptotic Theory of Independence. Oxford University Press, 2013
2013
-
[12]
Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D. Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. InAdvances in Neural Information Processing Systems, volume 33, pages 1877–1901, 2020
1901
-
[13]
Adam D. Bull. Convergence rates of efficient global optimization algorithms.Journal of Machine Learning Research, 12:2879–2904, 2011
2011
-
[14]
Calandra, J
R. Calandra, J. Peters, C. E. Rasmussen, and M. P. Deisenroth. Manifold gaussian processes for regression. In2016 International Joint Conference on Neural Networks (IJCNN), pages 3338–3345. IEEE, 2016
2016
-
[15]
Towards learning universal hyperparameter optimizers with transformers
Yutong Chen, Xingyou Song, Chris Lee, Ziyu Wang, Ruiyi Zhang, David Dohan, and Nando de Freitas. Towards learning universal hyperparameter optimizers with transformers. In Advances in Neural Information Processing Systems, volume 35, pages 32053–32068, 2022
2022
-
[16]
Integrated production and outbound distribution scheduling: Review and extensions.Operations Research, 58(1):130–148, 2010
Zhi-Long Chen. Integrated production and outbound distribution scheduling: Review and extensions.Operations Research, 58(1):130–148, 2010
2010
-
[17]
Hebo: Pushing the limits of sample-efficient hyperparameter optimisation.Journal of Artificial Intelligence Research, 74, 07 2022
Alexander Cowen-Rivers, Wenlong Lyu, Rasul Tutunov, Zhi Wang, Antoine Grosnit, Ryan-Rhys Griffiths, Alexandre Maravel, Jianye Hao, Jun Wang, Jan Peters, and Haitham Bou Ammar. Hebo: Pushing the limits of sample-efficient hyperparameter optimisation.Journal of Artificial Intelligence Research, 74, 07 2022. 11
2022
-
[18]
Multi-objective bayesian optimization over high-dimensional search spaces
Samuel Daulton, David Eriksson, Maximilian Balandat, and Eytan Bakshy. Multi-objective bayesian optimization over high-dimensional search spaces. InProceedings of the Conference on Uncertainty in Artificial Intelligence (UAI), pages 507–517. PMLR, 2022
2022
-
[19]
Scalable global optimization via local Bayesian optimization
David Eriksson, Michael Pearce, Jacob Gardner, Ryan D Turner, and Matthias Poloczek. Scalable global optimization via local Bayesian optimization. InAdvances in Neural Information Processing Systems (NeurIPS), 2019
2019
-
[20]
Cambridge University Press, 2023
Roman Garnett.Bayesian Optimization. Cambridge University Press, 2023
2023
-
[21]
Kazachkov, Elias Khalil, Pawel Lichocki, Andrea Lodi, Miles Lubin, Chris J
Maxime Gasse, Simon Bowly, Quentin Cappart, Jonas Charfreitag, Laurent Charlin, Didier Chételat, Antonia Chmiela, Justin Dumouchelle, Ambros Gleixner, Aleksandr M. Kazachkov, Elias Khalil, Pawel Lichocki, Andrea Lodi, Miles Lubin, Chris J. Maddison, Morris Christopher, Dimitri J. Papageorgiou, Augustin Parjadis, Sebastian Pokutta, Antoine Prouvost, Lara S...
2021
-
[22]
Ambros Gleixner, Gregor Hendel, Gerald Gamrath, Tobias Achterberg, Michael Bastubbe, Timo Berthold, Philipp Christophel, Kati Jarck, Thorsten Koch, Jeff Linderoth, et al. Miplib 2017: Data-driven compilation of the 6th mixed-integer programming library.Mathematical Programming Computation, 13(3):443–490, 2021. doi: 10.1007/s12532-020-00194-3
-
[23]
Gomes, Willem-Jan van Hoeve, and Ashish Sabharwal
Carla P. Gomes, Willem-Jan van Hoeve, and Ashish Sabharwal. Connections in networks: A hybrid approach. InInternational Conference on Integration of Artificial Intelligence (AI) and Operations Research (OR) Techniques in Constraint Programming, pages 303–307. Springer, 2008
2008
-
[24]
Dan Guo, Dong Yang, Haoran Zhang, Jiaming Song, Rui Zhang, Runpeng Xu, Qingyang Zhu, Shuai Ma, Peng Wang, Xiaoyu Bi, and Xue Zhang. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[25]
URL https://www
Gurobi Optimization, LLC.Gurobi Optimizer Reference Manual, 2024. URL https://www. gurobi.com. Accessed: 2024-01-01
2024
-
[26]
He He, Hal Daume III, and Jason M. Eisner. Learning to search in branch and bound algorithms. InAdvances in Neural Information Processing Systems, volume 27, 2014
2014
-
[27]
Hebbal, L
A. Hebbal, L. Brevault, M. Balesdent, E.-G. Taibi, and N. Melab. Efficient global optimization using deep gaussian processes. In2018 IEEE Congress on Evolutionary Computation (CEC), pages 1–8. IEEE, 2018
2018
-
[28]
Hoos, and Kevin Leyton-Brown
Frank Hutter, Youssef Hamadi, Holger H. Hoos, and Kevin Leyton-Brown. Performance prediction and automated tuning of randomized and parametric algorithms. InProceedings of the Twelfth International Conference on Principles and Practice of Constraint Programming (CP 2006), pages 213–228. Springer, 2006
2006
-
[29]
Hoos, Kevin Leyton-Brown, and Thomas Stützle
Frank Hutter, Holger H. Hoos, Kevin Leyton-Brown, and Thomas Stützle. Paramils: An automatic algorithm configuration framework.Journal of Artificial Intelligence Research, 36: 267–306, 2009
2009
-
[30]
Hoos, and Kevin Leyton-Brown
Frank Hutter, Holger H. Hoos, and Kevin Leyton-Brown. Automated configuration of mixed integer programming solvers. InIntegration of Artificial Intelligence (AI) and Operations Research (OR) Techniques in Constraint Programming, volume 6140 ofLecture Notes in Computer Science, pages 186–202, Berlin, Heidelberg, June 2010. Springer
2010
-
[31]
Hoos, and Kevin Leyton-Brown
Frank Hutter, Holger H. Hoos, and Kevin Leyton-Brown. Sequential model-based optimization for general algorithm configuration. InInternational Conference on Learning and Intelligent Optimization, Berlin, Heidelberg, 2011. Springer. 12
2011
-
[32]
Hoos, and Kevin Leyton-Brown
Frank Hutter, Lin Xu, Holger H. Hoos, and Kevin Leyton-Brown. Algorithm runtime prediction: Methods & evaluation.Artificial Intelligence, 206:79–111, 2014
2014
-
[33]
Springer International Publishing, 2020
Gabriele Iommazzo, Claudia D’Ambrosio, Antonio Frangioni, and Leo Liberti.A Learning- Based Mathematical Programming Formulation for the Automatic Configuration of Op- timization Solvers, pages 700–712. Springer International Publishing, 2020. ISBN 9783030645830. doi: 10.1007/978-3-030-64583-0_61. URL http://dx.doi.org/10. 1007/978-3-030-64583-0_61
-
[34]
D. R. Jones, M. Schonlau, and W. J. Welch. Efficient global optimization of expensive black-box functions.Journal of Global Optimization, 13:455–492, 1998
1998
-
[35]
Liebling, Denis Naddef, George L
Michael Jünger, Thomas M. Liebling, Denis Naddef, George L. Nemhauser, William R. Pul- leyblank, Gerhard Reinelt, Giovanni Rinaldi, and Laurence A. Wolsey.50 Years of Integer Programming 1958–2008: From the Early Years to the State-of-the-Art. Springer Science & Business Media, 2009
1958
-
[36]
Isac–instance-specific algorithm configuration
Serdar Kadioglu, Yury Malitsky, Meinolf Sellmann, and Kevin Tierney. Isac–instance-specific algorithm configuration. InECAI 2010, pages 751–756. IOS Press, 2010
2010
-
[37]
Fast bayesian optimization of machine learning hyperparameters on large datasets
Aaron Klein, Stefan Falkner, Simon Bartels, Philipp Hennig, and Frank Hutter. Fast bayesian optimization of machine learning hyperparameters on large datasets. InProceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS), pages 528–536. PMLR, 2017
2017
-
[38]
Bentyn, Dmitry Ignatov, and Radu Timofte
Roman Kochnev, Ali Tahan Goodarzi, Zofia A. Bentyn, Dmitry Ignatov, and Radu Timofte. Optuna vs code llama: Are llms a new paradigm for hyperparameter tuning?arXiv preprint arXiv:2504.06006, 2025
Pith/arXiv arXiv 2025
-
[39]
H. Kushner. A new method of locating the maximum point of an arbitrary multipeak curve in the presence of noise.Journal of Basic Engineering, 86(1):97–106, 1964
1964
-
[40]
Cambridge University Press, 2020
Tor Lattimore and Csaba Szepesvári.Bandit Algorithms. Cambridge University Press, 2020
2020
-
[41]
Learning the empirical hardness of optimization problems: The case of combinatorial auctions
Kevin Leyton-Brown, Eugene Nudelman, and Yoav Shoham. Learning the empirical hardness of optimization problems: The case of combinatorial auctions. InProceedings of the 8th International Conference on Principles and Practice of Constraint Programming (CP 2002), pages 556–572. Springer, 2002
2002
-
[42]
Hy- perband: A novel bandit-based approach to hyperparameter optimization.Journal of Machine Learning Research, 18(1):6765–6816, 2017
Lisha Li, Kevin Jamieson, Giulia DeSalvo, Afshin Rostamizadeh, and Ameet Talwalkar. Hy- perband: A novel bandit-based approach to hyperparameter optimization.Journal of Machine Learning Research, 18(1):6765–6816, 2017
2017
-
[43]
Lindauer, K
M. Lindauer, K. Eggensperger, M. Feurer, A. Biedenkapp, D. Deng, C. Benjamins, T. Ruhkopf, R. Sass, and F. Hutter. Smac3: A versatile bayesian optimization package for hyperparameter optimization.Journal of Machine Learning Research, 23(1):2475–2483, 2022
2022
-
[44]
L2p-mip: Learning to presolve for mixed integer programming
Chang Liu, Zhipeng Dong, Hao Ma, Wei Luo, Xiang Li, Bo Pang, and Junchi Yan. L2p-mip: Learning to presolve for mixed integer programming. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[45]
Large language models to enhance bayesian optimization.arXiv preprint arXiv:2402.03921, 2024
Tennison Liu, Nicolás Astorga, Nabeel Seedat, and Mihaela van der Schaar. Large language models to enhance bayesian optimization.arXiv preprint arXiv:2402.03921, 2024
arXiv 2024
-
[46]
The irace package: Iterated racing for automatic algorithm configuration
Manuel López-Ibáñez, Jérémie Dubois-Lacoste, Leslie Pérez Cáceres, Mauro Birattari, and Thomas Stützle. The irace package: Iterated racing for automatic algorithm configuration. Operations Research Perspectives, 3:43–58, 2016
2016
-
[47]
Kamran Mahammadli and Seyda Ertekin. Sequential large language model-based hyper- parameter optimization.arXiv preprint arXiv:2410.20302, 2024
arXiv 2024
-
[48]
The application of bayesian methods for seeking the extremum
Jonas Mockus. The application of bayesian methods for seeking the extremum. InTowards Global Optimization, volume 2, pages 117–129. North-Holland, 1998. 13
1998
- [49]
-
[50]
Solving mixed integer programs using neural networks.arXiv preprint arXiv:2012.13349, 2020
Vinod Nair, Sergey Bartunov, Felix Gimeno, Ingrid von Glehn, Pawel Lichocki, Ivan Lobov, Brendan O’Donoghue, et al. Solving mixed integer programs using neural networks.arXiv preprint arXiv:2012.13349, 2020
arXiv 2012
-
[51]
Gpt-4 technical report
OpenAI. Gpt-4 technical report. Technical report, OpenAI, 2023
2023
-
[52]
Xinkai Pan, Chenglong Wang, Chenyu Ying, Yuhui Xue, and Tian Yu. Beyond the heatmap: A rigorous evaluation of component impact in mcts-based tsp solvers.arXiv preprint arXiv:2411.09238, 2024
arXiv 2024
-
[53]
Papageorgiou, George L
Dimitri J. Papageorgiou, George L. Nemhauser, Joel Sokol, Myun-Seok Cheon, and Ahmet B. Keha. Mirplib–a library of maritime inventory routing problem instances: Survey, core model, and benchmark results.European Journal of Operational Research, 235(2):350–366, 2014
2014
-
[54]
Paschos.Applications of Combinatorial Optimization, volume 3
Vangelis Th. Paschos.Applications of Combinatorial Optimization, volume 3. John Wiley & Sons, 2014
2014
-
[55]
Yury Pushak and Holger H. Hoos. Golden parameter search: Exploiting structure to quickly configure parameters in parallel. InProceedings of the Genetic and Evolutionary Computation Conference (GECCO), pages 245–253, 2020
2020
-
[56]
In-context freeze-thaw Bayesian optimization for hyperparameter optimization
Herilalaina Rakotoarison, Steven Adriaensen, Neeratyoy Mallik, Samir Garibov, Edward Bergman, and Frank Hutter. In-context freeze-thaw Bayesian optimization for hyperparameter optimization. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[57]
M. C. Ramos, S. S. Michtavy, M. D. Porosoff, and A. D. White. Bayesian optimization of catalysts with in-context learning.arXiv preprint arXiv:2304.05341, 2023
arXiv 2023
-
[58]
A survey of methods for automated algorithm configuration.Journal of Artificial Intelligence Research, 75:425–487, 2022
Elias Schede et al. A survey of methods for automated algorithm configuration.Journal of Artificial Intelligence Research, 75:425–487, 2022
2022
-
[59]
Adams, and Nando De Freitas
Bobak Shahriari, Kevin Swersky, Ziyu Wang, Ryan P. Adams, and Nando De Freitas. Taking the human out of the loop: A review of bayesian optimization.Proceedings of the IEEE, 104 (1):148–175, 2015
2015
-
[60]
Wen Song, Yi Liu, Zhiguang Cao, Yaoxin Wu, and Qiqiang Li. Instance-specific algorithm configuration via unsupervised deep graph clustering.Engineering Applications of Artificial Intelligence, 125:106740, 2023. doi: 10.1016/j.engappai.2023.106740
-
[61]
T. P. Sorrell.Tuning Optimization Software Parameters for Mixed Integer Programming Problems. Doctoral dissertation, Virginia Commonwealth University, 2017
2017
-
[62]
Large language model-enhanced multi-armed bandits.arXiv preprint arXiv:2502.01118, 2025
Jiaqi Sun, Zihang Wang, Runpeng Yang, Chenkai Xiao, John Lui, and Ziheng Dai. Large language model-enhanced multi-armed bandits.arXiv preprint arXiv:2502.01118, 2025
arXiv 2025
-
[63]
Kevin Swersky, Jasper Snoek, and Ryan P. Adams. Multi-task bayesian optimization. In Advances in Neural Information Processing Systems, volume 26, 2013
2013
-
[64]
Romeo Valentin, Claudio Ferrari, Jérémy Scheurer, Andisheh Amrollahi, Chris Wendler, and Max B. Paulus. Instance-wise algorithm configuration with graph neural networks.arXiv preprint arXiv:2202.04910, 2022
arXiv 2022
-
[65]
A. G. Wilson, Z. Hu, R. Salakhutdinov, and E. P. Xing. Deep kernel learning. InProceedings of the 19th International Conference on Artificial Intelligence and Statistics, volume 51 of Proceedings of Machine Learning Research, pages 370–378, Cadiz, Spain, 2016. PMLR
2016
-
[66]
Efficient heuristics generation for solving combinatorial optimization prob- lems using large language models
Xuan Wu et al. Efficient heuristics generation for solving combinatorial optimization prob- lems using large language models. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining, volume 2, 2025
2025
-
[67]
Hoos, and Kevin Leyton-Brown
Lin Xu, Frank Hutter, Holger H. Hoos, and Kevin Leyton-Brown. Satzilla: Portfolio-based algorithm selection for sat.Journal of Artificial Intelligence Research, 32:565–606, 2008. 14
2008
-
[68]
Hydra: Automatically configuring algorithms for portfolio-based selection
Lin Xu, Holger Hoos, and Kevin Leyton-Brown. Hydra: Automatically configuring algorithms for portfolio-based selection. InProceedings of the AAAI Conference on Artificial Intelligence, volume 24, pages 210–216, 2010
2010
-
[69]
Michael R. Zhang, Nikhil Desai, Joonho Bae, Jonathan Lorraine, and Jimmy Ba. Using large language models for hyperparameter optimization.arXiv preprint arXiv:2312.04528, 2023. 15 Appendix Contents A Experiment Enviroment 17 B More Related Work 17 C Theoretical Convergence Analysis 18 C.1 Problem formulation . . . . . . . . . . . . . . . . . . . . . . . . ...
arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.