An Analysis of Speculative Window Decoders for Quantum Error Correction
Pith reviewed 2026-06-26 00:38 UTC · model grok-4.3
The pith
Speculative window decoding for quantum error correction reduces wait times for prior windows but its performance gains depend on gate speeds, speculation accuracy, decoder latency, processor count, and workload parallelism.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Speculative window decoding improves performance by reducing the time spent waiting for dependencies from prior decoding windows. However, its benefits are sensitive to gate speeds, speculation accuracy, decoder latency, processor count, and workload parallelism. This yields design principles for when it gives the greatest improvements and reveals conditions under which non-speculative decoders outperform.
What carries the argument
Speculative window decoding, a method that permits decoding of error-correction windows without waiting for complete resolution of dependencies from earlier windows.
If this is right
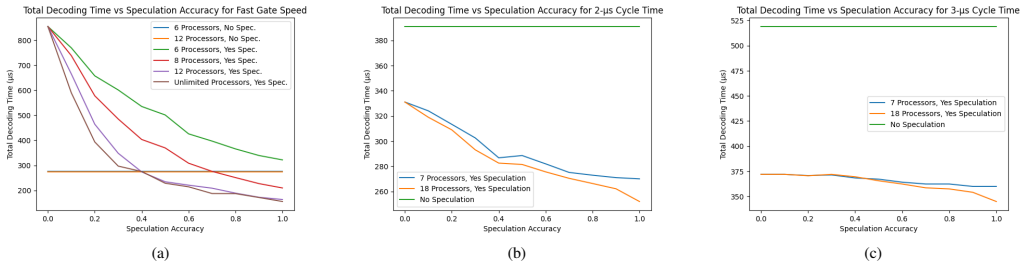
- Designers can select speculative decoding when gate speeds are fast and speculation accuracy is high to minimize dependency stalls.
- For platforms with slower gates or lower speculation accuracy, non-speculative decoders can deliver lower overall latency.
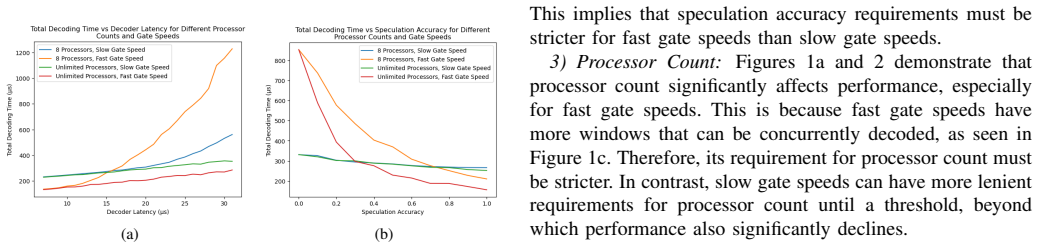
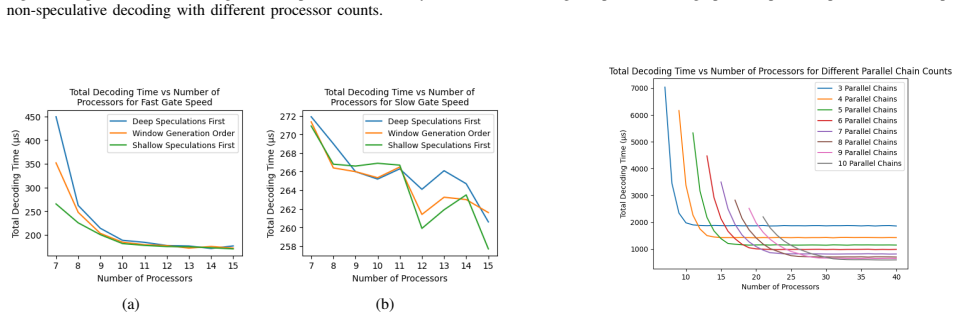
- Increasing processor count improves speculative performance only up to the point where dependency stalls remain the bottleneck.
- Workloads with high parallelism amplify the relative benefit of speculation by keeping more windows in flight.
Where Pith is reading between the lines
- The sensitivity patterns suggest an adaptive decoder that switches between speculative and non-speculative modes based on runtime estimates of gate speed and accuracy.
- Applying the same analysis to other quantum error-correcting codes could identify different crossover points where speculation stops helping.
- Hardware-specific calibration of the speculation-accuracy parameter would be required before the reported design principles can be used for system sizing.
Load-bearing premise
The simulation models of decoder latency, speculation accuracy, and gate-speed effects accurately represent real hardware behavior across different quantum technologies, codes, and platforms.
What would settle it
Direct measurement on physical quantum hardware of decoding latency for both speculative and non-speculative implementations at measured gate speeds, compared against the simulation predictions for the same workloads.
Figures

read the original abstract
Fault-tolerant quantum computing is essential for realizing the substantial computational speedups that quantum computing can bring, but it requires real-time error decoding with high performance. Speculative window decoding improves performance by reducing the time spent waiting for dependencies from prior decoding windows. However, speculative decoders have only been evaluated under the regime of superconducting qubits with fast gate speeds, surface codes, and matching decoders. Since different quantum technologies can have slower gate speeds, we evaluate the performance of speculative decoding under slow gate speeds. We also examine its sensitivity to speculation accuracy, decoder latency, processor count, and workload parallelism, which can vary across different quantum error correction codes, decoders, and hardware platforms. This work presents design principles for identifying when speculative decoding yields the greatest performance improvements. It also reveals the conditions under which non-speculative decoders outperform speculative decoders.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates speculative window decoding for quantum error correction, extending prior work from fast-gate superconducting regimes to slower gate speeds. It claims that speculative decoding reduces dependency waiting times and improves performance only under identifiable conditions on gate speed, speculation accuracy, decoder latency, processor count, and workload parallelism; it derives design principles for when speculative approaches are advantageous and identifies regimes where non-speculative decoders outperform them.
Significance. If the simulation results are reliable, the work supplies concrete, cross-platform guidance for real-time decoder design in fault-tolerant quantum computing. By mapping performance crossovers across parameter regimes that vary with code, decoder, and hardware, it offers actionable criteria that could inform architectural choices beyond the surface-code/matching-decoder setting.
major comments (2)
- [Simulation methodology and results sections] The central claims about performance gains, crossover points, and design principles rest entirely on the fidelity of the timing, latency, and speculation-accuracy models. No section supplies validation of these models against hardware measurements (e.g., measured vs. simulated decoder runtimes or empirical speculation success rates), which is load-bearing for the reported sensitivities and the conclusion that non-speculative decoders can be preferable.
- [Introduction and evaluation sections] The abstract states that the evaluation covers “slow gate speeds” and “different quantum technologies,” yet the manuscript provides no quantitative mapping from the modeled gate times to concrete hardware platforms or error models; without this anchoring, the claimed generality of the design principles cannot be assessed.
minor comments (2)
- Notation for “speculation accuracy” and “decoder latency” should be defined explicitly on first use and used consistently in figures and tables.
- Figure captions should state the exact parameter values used for each curve so that the sensitivity plots can be reproduced from the text alone.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below, proposing revisions to improve clarity on model assumptions and scope.
read point-by-point responses
-
Referee: [Simulation methodology and results sections] The central claims about performance gains, crossover points, and design principles rest entirely on the fidelity of the timing, latency, and speculation-accuracy models. No section supplies validation of these models against hardware measurements (e.g., measured vs. simulated decoder runtimes or empirical speculation success rates), which is load-bearing for the reported sensitivities and the conclusion that non-speculative decoders can be preferable.
Authors: We agree this is a valid concern. As a simulation-based study, we do not have access to hardware measurements for validation in this work. We will revise the methodology section to include a more detailed discussion of the model assumptions, their potential impact on results, and the importance of future empirical validation. This will strengthen the presentation without altering the simulation results. revision: partial
-
Referee: [Introduction and evaluation sections] The abstract states that the evaluation covers “slow gate speeds” and “different quantum technologies,” yet the manuscript provides no quantitative mapping from the modeled gate times to concrete hardware platforms or error models; without this anchoring, the claimed generality of the design principles cannot be assessed.
Authors: The intent was to explore a broader parameter space than prior work focused on fast gates. However, we accept that the abstract and text should avoid implying direct applicability without mapping. We will update the abstract, introduction, and relevant sections to specify that gate times are parameterized, provide example ranges corresponding to slower technologies (e.g., trapped ions), and qualify the design principles as applicable within the modeled conditions. revision: yes
Circularity Check
No circularity: analysis rests on independent simulation evaluations.
full rationale
The paper performs a sensitivity analysis of speculative window decoding via new simulations across gate speeds, speculation accuracy, decoder latency, processor count, and parallelism. No equations, fitted parameters, or self-citations are invoked as load-bearing steps that reduce the central claims to inputs by construction. The design principles and crossover conditions emerge directly from the reported evaluations rather than from re-deriving or renaming prior quantities.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Swiper: Minimizing fault-tolerant quantum program latency via speculative window decoding,
J. Viszlai, J. D. Chadwick, S. Joshi, G. S. Ravi, Y . Li, and F. T. Chong, “Swiper: Minimizing fault-tolerant quantum program latency via speculative window decoding,” inProceedings of the 52nd Annual International Symposium on Computer Architecture, ser. ISCA ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 1386–1401. [Online]. Avai...
-
[2]
E. Dennis, A. Kitaev, A. Landahl, and J. Preskill, “Topological quantum memory,”Journal of Mathematical Physics, vol. 43, no. 9, p. 4452–4505, Sep. 2002. [Online]. Available: http://dx.doi.org/10.1063/1.1499754
-
[3]
Quantum error correction below the surface code threshold,
Google Quantum AI and Collaborators, “Quantum error correction below the surface code threshold,”arXiv preprint arXiv:2408.13687, 2024
arXiv 2024
-
[4]
Neutral atom quantum computing hardware: Performance and end-user perspective,
K. Wintersperger, F. Dommert, T. Ehmer, A. Hoursanov, J. Klepsch, W. Mauerer, G. Reuber, T. Strohm, M. Yin, and S. Luber, “Neutral atom quantum computing hardware: Performance and end-user perspective,” 2023, arxiv
2023
-
[5]
Trapped- ion quantum computing: Progress and challenges,
C. D. Bruzewicz, J. Chiaverini, R. McConnell, and J. M. Sage, “Trapped- ion quantum computing: Progress and challenges,”Applied Physics Reviews, vol. 6, no. 2, p. 021314, 2019
2019
-
[6]
Surface code quantum computing by lattice surgery,
D. Horsman, A. G. Fowler, S. Devitt, and R. V . Meter, “Surface code quantum computing by lattice surgery,”New Journal of Physics, vol. 14, no. 12, p. 123011, Dec. 2012. [Online]. Available: http://dx.doi.org/10.1088/1367-2630/14/12/123011
-
[7]
Almost-linear time decoding algorithm for topological codes,
N. Delfosse and N. H. Nickerson, “Almost-linear time decoding algorithm for topological codes,”Quantum, vol. 5, p. 595, Dec. 2021. [Online]. Available: http://dx.doi.org/10.22331/q-2021-12-02-595
-
[8]
Towards practical classical processing for the surface code,
A. G. Fowler, A. C. Whiteside, and L. C. L. Hollenberg, “Towards practical classical processing for the surface code,”Physical Review Letters, vol. 108, no. 18, May 2012. [Online]. Available: http://dx.doi.org/10.1103/PhysRevLett.108.180501
-
[9]
Neural belief-propagation decoders for quantum error-correcting codes,
Y .-H. Liu and D. Poulin, “Neural belief-propagation decoders for quantum error-correcting codes,”Phys. Rev. Lett., vol. 122, p. 200501, May 2019. [Online]. Available: https://link.aps.org/doi/10. 1103/PhysRevLett.122.200501
2019
-
[10]
Quantum error correction via noise guessing decoding,
D. Cruz, F. A. Monteiro, and B. C. Coutinho, “Quantum error correction via noise guessing decoding,”IEEE Access, vol. 11, pp. 119 446– 119 461, 2023
2023
-
[11]
Y . Liu, S. Ping, J. Zhou, E. Decker, J. Kalloor, M. Weiden, K. Chen, Y . Shi, A. Javadi-Abhari, C. Iancu, and G. Li, “Alphasyndrome: Tackling the syndrome measurement circuit scheduling problem for qec codes,” inProceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, V olume 2, ser. A...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.