What's in an Earth Embedding? An Explainability Analysis of Location Encoders
Pith reviewed 2026-06-26 00:13 UTC · model grok-4.3
The pith
Location embeddings from geographic neural networks decompose into human-interpretable features like forests, deserts, and urban structures while keeping high reconstruction accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
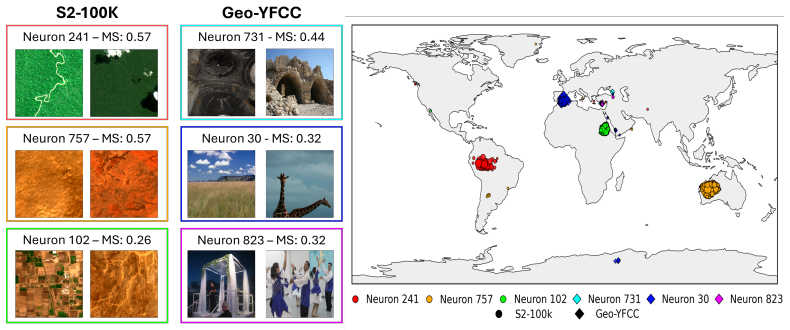
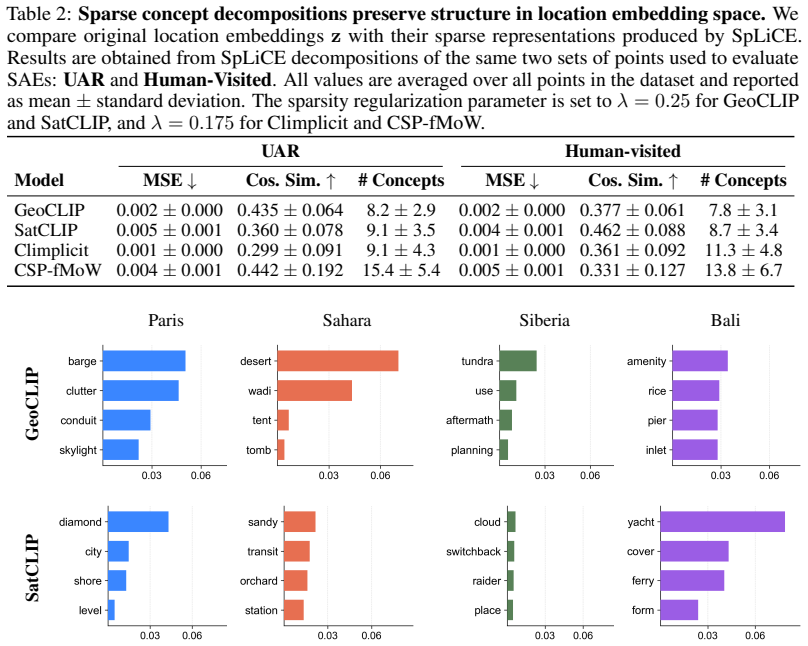
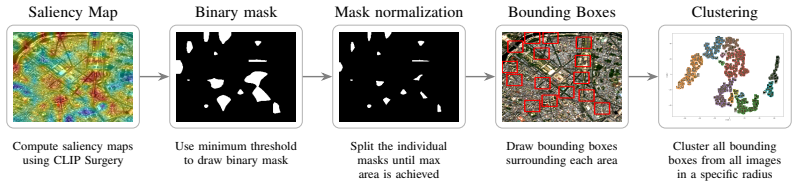
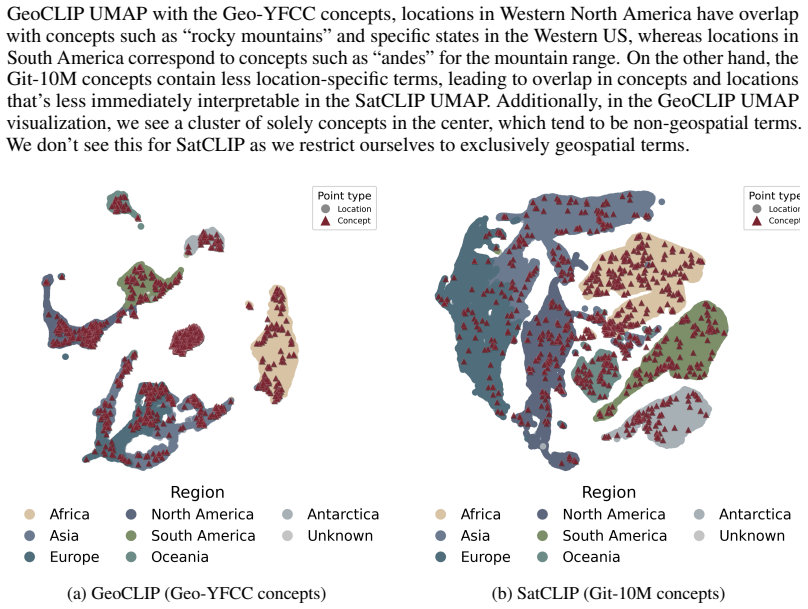
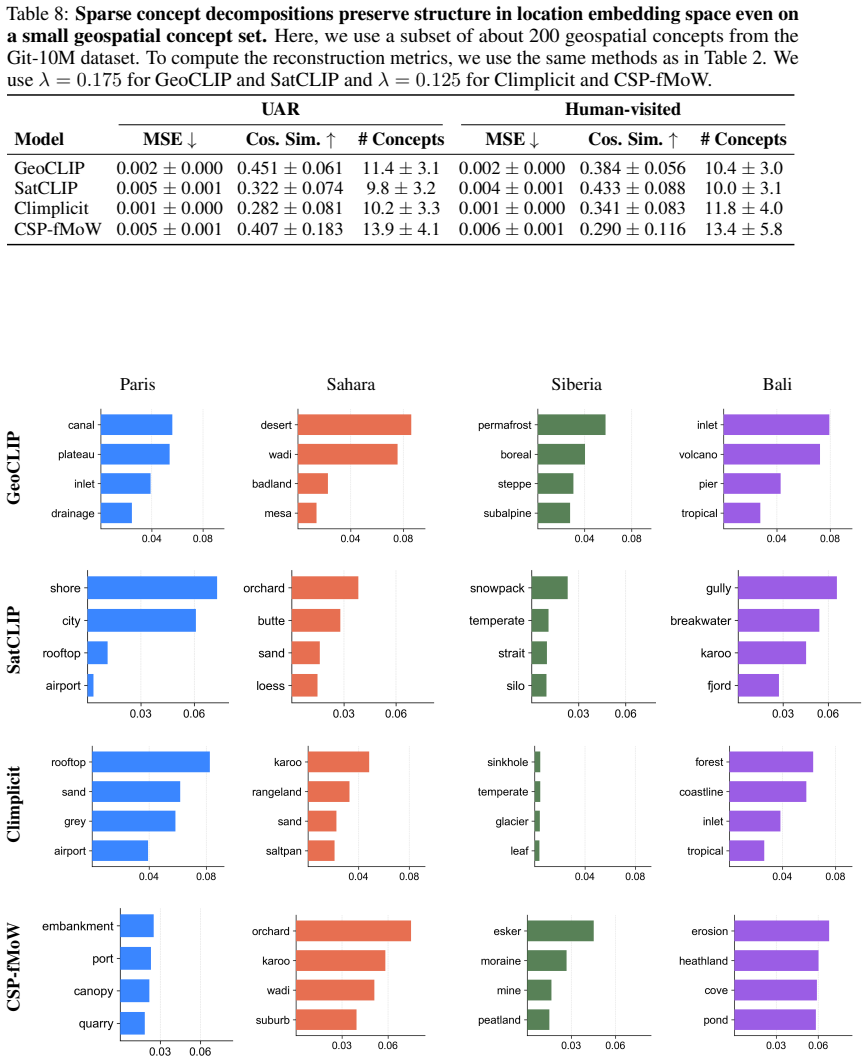
Geographic INRs learn location embeddings that encode geospatial data and can be decomposed into sparse latent concepts via sparse autoencoders, natural language concepts via SpLiCE over a predefined geospatial dictionary, and visual features via CLIP Surgery saliency maps; these decompositions retain high reconstruction capability and expose interpretable structures such as forests, deserts, and urban features, with systematic differences across methods that range from urban structures to broader biome and climate signals.
What carries the argument
Decomposition of location embeddings into sparse latent concepts, natural language concepts, and visual saliency features using sparse autoencoders, SpLiCE, and CLIP Surgery.
If this is right
- Sparse decompositions reveal systematic differences in encoded information, from local urban structures to wider biome and climate signals.
- Saliency maps from pretraining space highlight complementary visual features such as roads and landmarks.
- Location embeddings can be audited for the geographic or semantic information they capture.
- Human-interpretable representations can be obtained from the embeddings without major loss of reconstruction fidelity.
Where Pith is reading between the lines
- The same decomposition approach could be tested on embeddings from other coordinate-based models to check whether interpretability generalizes beyond geographic INRs.
- Practitioners could select among embedding methods by inspecting which geographic scales each one emphasizes in its decompositions.
- If the recovered concepts align with real satellite or map data, the embeddings may be carrying implicit supervision from the pretraining distribution.
- Downstream tasks that rely on these embeddings might gain from an intermediate step that filters or weights the extracted concepts.
Load-bearing premise
The chosen decomposition techniques recover the actual semantic and visual content present in the embeddings without introducing substantial artifacts or omissions.
What would settle it
Reconstruction error rises sharply or known geographic features such as forests disappear from the extracted concepts when the same decomposition methods are applied to the embeddings.
Figures








read the original abstract
Geographic implicit neural representations (INRs) learn to map any coordinate on Earth to a location embedding, implicitly encoding geospatial data into the weights of a neural network. Location embeddings are widely used off the shelf as general-purpose geospatial representations, yet users lack principled tools to audit what geographic or semantic information these embeddings capture. In this work, we analyze the information content of geographic INRs through their location embeddings. We decompose these embeddings into human-interpretable features$\unicode{x2014}$namely, (i) sparse latent concepts, (ii) natural language concepts, and (iii) visual features. The latent concept embeddings are learned using sparse autoencoders. To recover natural language concepts, we apply sparse linear concept embeddings (SpLiCE) over a predefined geospatial dictionary. Finally, visual features are extracted using saliency maps derived from CLIP Surgery. We show that location embeddings can be decomposed into human-interpretable representations while retaining high reconstruction capability, revealing interpretable geographic structures such as forests, deserts, and urban features. Across methods, sparse decompositions expose systematic differences in encoded information, ranging from urban structures to broader biome and climate signals, and pretraining-space saliency maps further highlight complementary features such as roads and landmarks. We hope this work provides a first step toward interpretable geospatial representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that location embeddings from geographic implicit neural representations (INRs) can be decomposed into human-interpretable features using (i) sparse autoencoders for latent concepts, (ii) SpLiCE over a predefined geospatial dictionary for natural language concepts, and (iii) CLIP Surgery saliency maps for visual features. It asserts that these decompositions retain high reconstruction capability while revealing interpretable geographic structures such as forests, deserts, and urban features, and that sparse decompositions expose systematic differences in encoded information ranging from urban structures to biome and climate signals.
Significance. If the central claims hold with supporting evidence, the work provides a useful first step toward auditing and interpreting widely used location embeddings as general-purpose geospatial representations. The multi-method decomposition approach (latent, linguistic, and visual) offers complementary views on encoded information and could support more trustworthy geospatial AI applications.
major comments (1)
- [Abstract] Abstract: the assertion that 'decompositions retain high reconstruction capability' and 'reveal interpretable geographic structures such as forests, deserts, and urban features' supplies no quantitative metrics, ablation results, dataset details, or reconstruction error values. This is load-bearing for the central claim that the chosen techniques faithfully recover semantic and visual content without substantial artifacts.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the work's significance and for highlighting this important point about the abstract. We agree that the abstract's claims would be strengthened by including quantitative support and will revise it accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'decompositions retain high reconstruction capability' and 'reveal interpretable geographic structures such as forests, deserts, and urban features' supplies no quantitative metrics, ablation results, dataset details, or reconstruction error values. This is load-bearing for the central claim that the chosen techniques faithfully recover semantic and visual content without substantial artifacts.
Authors: We agree that the abstract would benefit from quantitative grounding. The body of the manuscript reports reconstruction metrics, ablation studies, and dataset details supporting the decompositions' fidelity (e.g., low reconstruction error while recovering interpretable structures). However, these specifics are not summarized in the abstract. In the revised version we will update the abstract to include key quantitative results, such as reconstruction error values and dataset references, to make the central claims more self-contained. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper applies three previously published external decomposition techniques (sparse autoencoders, SpLiCE over a geospatial dictionary, and CLIP Surgery saliency) to location embeddings produced by geographic INRs. No load-bearing step reduces a reported finding to a quantity defined by the authors' own fitted parameters, self-citation chain, or ansatz smuggled via prior work by the same authors. The central claim that the decompositions retain reconstruction capability and expose structures such as forests and deserts rests on the fidelity of these independent methods rather than on any self-referential definition or renaming of results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Geographic implicit neural representations encode geospatial data into the weights of a neural network via location embeddings.
Reference graph
Works this paper leans on
-
[1]
GPT-4 technical report.arXiv preprint arXiv:2303.08774, 2023
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. GPT-4 technical report.arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[2]
Emily Aiken, Esther Rolf, and Joshua Blumenstock. Fairness and representation in satellite- based poverty maps: evidence of urban-rural disparities and their impacts on downstream policy. InProceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, IJCAI ’23, 2023. doi: 10.24963/ijcai.2023/653. URL https://doi.org/10.24963...
-
[3]
Neural machine translation by jointly learning to align and translate
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. InProceedings of the 3rd International Conference on Learning Representations (ICLR), 2015. URLhttp://arxiv.org/abs/1409.0473
Pith/arXiv arXiv 2015
-
[4]
Ivan Felipe Benavides-Martinez, Justin Guthrie, Jhon Edwin Arias, Yeison Alberto Garces- Gomez, Angela Ines Guzman-Alvis, Cristiam Victoriano Portilla-Cabrera, Somnath Mondal, Andrew J. Allyn, and Auroop R. Ganguly. What on Earth is AlphaEarth? Hierarchical structure and functional interpretability for global land cover.arXiv preprint arXiv:2603.16911, 2026
arXiv 2026
-
[5]
Calmon, and Himabindu Lakkaraju
Usha Bhalla, Alex Oesterling, Suraj Srinivas, Flavio P. Calmon, and Himabindu Lakkaraju. Interpreting clip with sparse linear concept embeddings (splice). 37:84298–84328, 2024. doi: 10.52202/079017-2678. URL https://proceedings.neurips.cc/paper_files/paper/ 2024/file/996bef37d8a638f37bdfcac2789e835d-Paper-Conference.pdf
-
[6]
Brown, Michal Kazmierski, Valerie J
Christopher F. Brown, Michal Kazmierski, Valerie J. Pasquarella, William J. Rucklidge, Masha Samsikova, Chenhui Zhang, Evan Shelhamer, Estefania Lahera, Olivia Wiles, Simon Ilyushchenko, Noel Gorelick, Lihui Zhang, Sophia Alj, Emily Schechter, Sean Askay, Oliver Guinan, Rebecca Moore, Alexis Boukouvalas, and Pushmeet Kohli. Alphaearth foundations: An embe...
Pith/arXiv arXiv 2025
-
[7]
Batchtopk sparse autoencoders
Bart Bussmann, Patrick Leask, and Neel Nanda. Batchtopk sparse autoencoders. InNeurIPS 2024 Workshop on Scientific Methods for Understanding Deep Learning, 2024. URL https: //openreview.net/forum?id=d4dpOCqybL
2024
-
[8]
Adapting Grad-CAM for embedding networks
Lei Chen, Jianhui Chen, Hossein Hajimirsadeghi, and Greg Mori. Adapting Grad-CAM for embedding networks. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 2794–2803, 2020
2020
-
[9]
Functional map of the world
Gordon Christie, Neil Fendley, James Wilson, and Ryan Mukherjee. Functional map of the world. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6172–6180, 2018
2018
-
[10]
Spatial implicit neural representations for global-scale species mapping
Elijah Cole, Grant Van Horn, Christian Lange, Alexander Shepard, Patrick Leary, Pietro Perona, Scott Loarie, and Oisin Mac Aodha. Spatial implicit neural representations for global-scale species mapping. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 6320–6342. PMLR, 23–...
2023
-
[11]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009. doi: 10.1109/CVPR.2009.5206848. 11
-
[12]
Carl Doersch, Saurabh Singh, Abhinav Gupta, Josef Sivic, and Alexei A. Efros. What makes Paris look like Paris?Commun. ACM, 58(12):103–110, November 2015. doi: 10.1145/2830541. URLhttps://doi.org/10.1145/2830541
-
[13]
Climplicit: Climatic implicit embeddings for global ecological tasks
Johannes Dollinger, Damien Robert, Elena Plekhanova, Lukas Drees, and Jan Dirk Wegner. Climplicit: Climatic implicit embeddings for global ecological tasks. InICLR 2025 Workshop on Tackling Climate Change with Machine Learning, 2025. URLhttps://www.climatechange. ai/papers/iclr2025/44
2025
-
[14]
Adaptive methods for real-world domain generalization
Abhimanyu Dubey, Vignesh Ramanathan, Alex Pentland, and Dhruv Mahajan. Adaptive methods for real-world domain generalization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14340–14349, June 2021
2021
-
[15]
A density-based algorithm for discovering clusters in large spatial databases with noise
Martin Ester, Hans-Peter Kriegel, Jörg Sander, and Xiaowei Xu. A density-based algorithm for discovering clusters in large spatial databases with noise. InProceedings of the Second International Conference on Knowledge Discovery and Data Mining, KDD’96, page 226–231. AAAI Press, 1996
1996
-
[16]
Combi-CAM: A novel multi-layer approach for explainable image geolocalization
David Faget, José Luis Lisani, and Miguel Colom. Combi-CAM: A novel multi-layer approach for explainable image geolocalization. In21st International Conference on Computer Vision Theory and Applications, volume 1, pages 275–281. SCITEPRESS-Science and Technology Publications, 2026
2026
-
[17]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[18]
Natural language descriptions of deep features
Evan Hernandez, Sarah Schwettmann, David Bau, Teona Bagashvili, Antonio Torralba, and Jacob Andreas. Natural language descriptions of deep features. InInternational Confer- ence on Learning Representations, 2022. URL https://openreview.net/forum?id= NudBMY-tzDr
2022
-
[19]
LoRA: Low-rank adaptation of large language models
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022. URL https://openreview. net/forum?id=nZeVKeeFYf9
2022
-
[20]
Sparse autoencoders find highly interpretable features in language models
Robert Huben, Hoagy Cunningham, Logan Riggs Smith, Aidan Ewart, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum? id=F76bwRSLeK
2024
-
[21]
Adrian Höhl, Ivica Obadic, Miguel-Ángel Fernández-Torres, Hiba Najjar, Dario Augusto Borges Oliveira, Zeynep Akata, Andreas Dengel, and Xiao Xiang Zhu. Opening the black box: A systematic review on explainable artificial intelligence in remote sensing.IEEE Geoscience and Remote Sensing Magazine, 12(4):261–304, 2024. doi: 10.1109/MGRS.2024.3467001
-
[22]
Majda Ivi´c. Artificial intelligence and geospatial analysis in disaster management.The In- ternational Archives of the Photogrammetry, Remote Sensing and Spatial Information Sci- ences, XLII-3/W8:161–166, 2019. doi: 10.5194/isprs-archives-XLII-3-W8-161-2019. URL https://isprs-archives.copernicus.org/articles/XLII-3-W8/161/2019/
work page doi:10.5194/isprs-archives-xlii-3-w8-161-2019 2019
-
[23]
Furong Jia, Lanxin Liu, Ce Hou, Fan Zhang, Xinyan Liu, and Yu Liu. Towards interpretable geo-localization: a concept-aware global image-GPS alignment framework.arXiv preprint arXiv:2509.01910, 2025
arXiv 2025
-
[24]
Peter Linder, and Michael Kessler
Dirk Nikolaus Karger, Olaf Conrad, Jürgen Böhner, Tobias Kawohl, Holger Kreft, Ro- drigo Wilber Soria-Auza, Niklaus E Zimmermann, H. Peter Linder, and Michael Kessler. Climatologies at high resolution for the earth’s land surface areas.Scientific data, 4(1):1–20,
-
[25]
URLhttps://doi.org/10.1038/sdata.2017.122
doi: 10.1038/sdata.2017.122. URLhttps://doi.org/10.1038/sdata.2017.122
-
[26]
SatCLIP: Global, general-purpose location embeddings with satellite imagery
Konstantin Klemmer, Esther Rolf, Caleb Robinson, Lester Mackey, and Marc Rußwurm. SatCLIP: Global, general-purpose location embeddings with satellite imagery. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 4347–4355, 2025. 12
2025
-
[27]
Konstantin Klemmer, Esther Rolf, Marc Russwurm, Gustau Camps-Valls, Mikolaj Czerkawski, Stefano Ermon, Alistair Francis, Nathan Jacobs, Hannah Rae Kerner, Lester Mackey, Gengchen Mai, Oisin Mac Aodha, Markus Reichstein, Caleb Robinson, David Rolnick, Evan Shelhamer, Vincent Sitzmann, Devis Tuia, and Xiaoxiang Zhu. Earth embeddings: Towards AI-centric repr...
-
[28]
Science, 382 (6677), 1416--1421, doi:10.1126/science.adi2336
Remi Lam, Alvaro Sanchez-Gonzalez, Matthew Willson, Peter Wirnsberger, Meire Fortunato, Ferran Alet, Suman Ravuri, Timo Ewalds, Zach Eaton-Rosen, Weihua Hu, Alexander Merose, Stephan Hoyer, George Holland, Oriol Vinyals, Jacklynn Stott, Alexander Pritzel, Shakir Mohamed, and Peter Battaglia. Learning skillful medium-range global weather forecasting. Scien...
-
[29]
Martha Larson, Mohammad Soleymani, Guillaume Gravier, Bogdan Ionescu, and Gareth J.F. Jones. The benchmarking initiative for multimedia evaluation: Mediaeval 2016.IEEE MultiMe- dia, 24(1):93–96, 2017. doi: 10.1109/MMUL.2017.9
-
[30]
Yi Li, Hualiang Wang, Yiqun Duan, Hang Xu, and Xiaomeng Li. Exploring visual interpretabil- ity for contrastive language-image pre-training.arXiv preprint arXiv:2209.07046, 2022
arXiv 2022
-
[31]
A closer look at the explainability of contrastive language-image pre-training.Pattern Recognition, 162:111409,
Yi Li, Hualiang Wang, Yiqun Duan, Jiheng Zhang, and Xiaomeng Li. A closer look at the explainability of contrastive language-image pre-training.Pattern Recognition, 162:111409,
-
[32]
doi: https://doi.org/10.1016/j.patcog.2025.111409
ISSN 0031-3203. doi: https://doi.org/10.1016/j.patcog.2025.111409. URL https: //www.sciencedirect.com/science/article/pii/S003132032500069X
-
[33]
Mind the gap: Understanding the modality gap in multi-modal contrastive representation learn- ing
Victor Weixin Liang, Yuhui Zhang, Yongchan Kwon, Serena Yeung, and James Zou. Mind the gap: Understanding the modality gap in multi-modal contrastive representation learn- ing. InAdvances in Neural Information Processing Systems, volume 35, pages 17612– 17625, 2022. URL https://proceedings.neurips.cc/paper_files/paper/2022/ file/702f4db7543a7432431df588d5...
2022
-
[34]
Chenyang Liu, Keyan Chen, Rui Zhao, Zhengxia Zou, and Zhenwei Shi. Text2earth: Unlocking text-driven remote sensing image generation with a global-scale dataset and a foundation model. IEEE Geoscience and Remote Sensing Magazine, 13(3):238–259, 2025. doi: 10.1109/MGRS. 2025.3560455
-
[35]
Lundberg and Su-In Lee
Scott M. Lundberg and Su-In Lee. A unified approach to interpreting model predictions. InAdvances in Neural Information Processing Systems, volume 30,
-
[36]
URL https://proceedings.neurips.cc/paper_files/paper/2017/file/ 8a20a8621978632d76c43dfd28b67767-Paper.pdf
2017
-
[37]
Presence-only geographical priors for fine-grained image classification
Oisin Mac Aodha, Elijah Cole, and Pietro Perona. Presence-only geographical priors for fine-grained image classification. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9596–9606, 2019
2019
-
[38]
Multi-scale repre- sentation learning for spatial feature distributions using grid cells
Gengchen Mai, Krzysztof Janowicz, Bo Yan, Rui Zhu, Ling Cai, and Ni Lao. Multi-scale repre- sentation learning for spatial feature distributions using grid cells. InInternational Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=rJljdh4KDH
2020
-
[39]
Gengchen Mai, Krzysztof Janowicz, Yingjie Hu, Song Gao, Bo Yan, Rui Zhu, Ling Cai, and Ni Lao. A review of location encoding for geoai: methods and applications.International Journal of Geographical Information Science, 36(4):639–673, 2022. doi: 10.1080/13658816. 2021.2004602. URLhttps://doi.org/10.1080/13658816.2021.2004602
-
[40]
UMAP: Uniform manifold approximation and projection.The Journal of Open Source Software, 3(29):861, 2018
Leland McInnes, John Healy, Nathaniel Saul, and Lukas Großberger. UMAP: Uniform manifold approximation and projection.The Journal of Open Source Software, 3(29):861, 2018
2018
-
[41]
Text-to-concept (and back) via cross-model alignment
Mazda Moayeri, Keivan Rezaei, Maziar Sanjabi, and Soheil Feizi. Text-to-concept (and back) via cross-model alignment. InInternational Conference on Machine Learning, pages 25037–25060. PMLR, 2023. 13
2023
-
[42]
CLIP-dissect: Automatic description of neuron rep- resentations in deep vision networks
Tuomas Oikarinen and Tsui-Wei Weng. CLIP-dissect: Automatic description of neuron rep- resentations in deep vision networks. InThe Eleventh International Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=iPWiwWHc1V
2023
-
[43]
Sparse autoencoders learn monosemantic features in vision-language mod- els
Mateusz Pach, Shyamgopal Karthik, Quentin Bouniot, Serge Belongie, and Zeynep Akata. Sparse autoencoders learn monosemantic features in vision-language mod- els. InAdvances in Neural Information Processing Systems, volume 38, pages 95706– 95742, 2025. URL https://proceedings.neurips.cc/paper_files/paper/2025/ file/89e83382abeee53b932a6df62edbf9cc-Paper-Co...
2025
-
[44]
Nowara, Joshua Gleason, Carlos D
Shraman Pramanick, Ewa M. Nowara, Joshua Gleason, Carlos D. Castillo, and Rama Chellappa. Where in the world is this image? transformer-based geo-localization in the wild. InEuropean Conference on Computer Vision, pages 196–215, 2022. URL https://doi.org/10.1007/ 978-3-031-19839-7_12
2022
-
[45]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In Proceedings of the 38th International Conference on Machine Learning, volume 139 ofPro- ceeding...
2021
-
[46]
Measuring the intrinsic dimension of earth representations
Arjun Rao, Marc Rußwurm, Konstantin Klemmer, and Esther Rolf. Measuring the intrinsic dimension of earth representations. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=gQPD83DrGp
2026
-
[47]
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. “Why should I trust you?": Explaining the predictions of any classifier. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, page 1135–1144, New York, NY , USA, 2016. Association for Computing Machinery. doi: 10.1145/2939672.2939778. URL http...
-
[48]
Ge- ographic location encoding with spherical harmonics and sinusoidal representation net- works
Marc Rußwurm, Konstantin Klemmer, Esther Rolf, Robin Zbinden, and Devis Tuia. Ge- ographic location encoding with spherical harmonics and sinusoidal representation net- works. InInternational Conference on Learning Representations, volume 2024, pages 1746– 1759, 2024. URL https://proceedings.iclr.cc/paper_files/paper/2024/file/ 073c8584ef86bee26fe9d639ec6...
2024
-
[49]
Grad-CAM: Visual explanations from deep networks via gradient- based localization
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-CAM: Visual explanations from deep networks via gradient- based localization. InProceedings of the IEEE International Conference on Computer Vision, pages 618–626, 2017
2017
-
[50]
A survey on sparse autoencoders: Interpreting the internal mechanisms of large language models
Dong Shu, Xuansheng Wu, Haiyan Zhao, Daking Rai, Ziyu Yao, Ninghao Liu, and Mengnan Du. A survey on sparse autoencoders: Interpreting the internal mechanisms of large language models. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 1690–1712. Association for Computational Linguistics, 2025. doi: 10.18653/v1/2025.findings-emn...
-
[51]
Implicit neural representations with periodic activation functions
Vincent Sitzmann, Julien Martel, Alexander Bergman, David Lindell, and Gordon Wetzstein. Implicit neural representations with periodic activation functions. In Advances in Neural Information Processing Systems, volume 33, pages 7462–7473,
-
[52]
URL https://proceedings.neurips.cc/paper_files/paper/2020/file/ 53c04118df112c13a8c34b38343b9c10-Paper.pdf
2020
-
[53]
Stewart, Caleb Robinson, Isaac A
Adam J. Stewart, Caleb Robinson, Isaac A. Corley, Anthony Ortiz, Juan M. Lavista Ferres, and Arindam Banerjee. Torchgeo: Deep learning with geospatial data.ACM Trans. Spatial Algorithms Syst., 11(4), 2025. ISSN 2374-0353. doi: 10.1145/3707459. URL https://doi. org/10.1145/3707459
-
[54]
Fourier fea- tures let networks learn high frequency functions in low dimensional domains
Matthew Tancik, Pratul Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Ragha- van, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan Barron, and Ren Ng. Fourier fea- tures let networks learn high frequency functions in low dimensional domains. In 14 Advances in Neural Information Processing Systems, volume 33, pages 7537–7547,
-
[55]
URL https://proceedings.neurips.cc/paper_files/paper/2020/file/ 55053683268957697aa39fba6f231c68-Paper.pdf
2020
-
[56]
V o, John Brandt, Justine Spore, Sayantan Majumdar, Daniel Haziza, Janaki Vamaraju, Theo Moutakanni, Piotr Bojanowski, Tracy Johns, Brian White, Tobias Tiecke, and Camille Couprie
Jamie Tolan, Hung-I Yang, Benjamin Nosarzewski, Guillaume Couairon, Huy V . V o, John Brandt, Justine Spore, Sayantan Majumdar, Daniel Haziza, Janaki Vamaraju, Theo Moutakanni, Piotr Bojanowski, Tracy Johns, Brian White, Tobias Tiecke, and Camille Couprie. Very high resolution canopy height maps from RGB imagery using self-supervised vision transformer an...
-
[57]
ISSN 0034-4257. doi: https://doi.org/10.1016/j.rse.2023.113888. URL https://www. sciencedirect.com/science/article/pii/S003442572300439X
-
[58]
Visualizing data using t-SNE.Journal of Machine Learning Research, 9(86):2579–2605, 2008
Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-SNE.Journal of Machine Learning Research, 9(86):2579–2605, 2008. URL http://jmlr.org/papers/v9/ vandermaaten08a.html
2008
-
[59]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Infor- mation Processing Systems, volume 30, 2017. URL https://proceedings.neurips.cc/ paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
2017
-
[60]
Geoclip: Clip- inspired alignment between locations and images for effective worldwide geo-localization
Vicente Vivanco Cepeda, Gaurav Kumar Nayak, and Mubarak Shah. Geoclip: Clip- inspired alignment between locations and images for effective worldwide geo-localization. InAdvances in Neural Information Processing Systems, volume 36, pages 8690–8701,
-
[61]
URL https://proceedings.neurips.cc/paper_files/paper/2023/file/ 1b57aaddf85ab01a2445a79c9edc1f4b-Paper-Conference.pdf
2023
-
[62]
A proxy consistency loss for grounded fusion of earth observation and location encoders
Zhongying Wang, Kevin Lane, Levi Cai, Morteza Karimzadeh, and Esther Rolf. A proxy consistency loss for grounded fusion of earth observation and location encoders. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, pages 8075–8084, June 2026
2026
-
[63]
LiT: Zero-shot transfer with locked-image text tuning
Xiaohua Zhai, Xiao Wang, Basil Mustafa, Andreas Steiner, Daniel Keysers, Alexander Kolesnikov, and Lucas Beyer. LiT: Zero-shot transfer with locked-image text tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18123–18133, June 2022
2022
-
[64]
Learning deep features for discriminative localization
Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, and Antonio Torralba. Learning deep features for discriminative localization. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016
2016
-
[65]
Stewart, Konrad Heidler, Yuanyuan Wang, Zhenghang Yuan, Thomas Dujardin, Qingsong Xu, and Yilei Shi
Xiao Xiang Zhu, Zhitong Xiong, Yi Wang, Adam J. Stewart, Konrad Heidler, Yuanyuan Wang, Zhenghang Yuan, Thomas Dujardin, Qingsong Xu, and Yilei Shi. On the foundations of earth foundation models.Communications Earth & Environment, 7(1):103, Jan 2026. doi: 10.1038/s43247-025-03127-x. URLhttps://doi.org/10.1038/s43247-025-03127-x. 15 7 Appendix 7.1 Reproduc...
-
[66]
rocky mountains
We use a cosine learning rate schedule. The logit temperature is learnable and is initialized at 0.07. We train for 55k steps, validating every 500 steps and applying early stopping based on validation loss (with a patience of 5 validation checks). Training is conducted on NVIDIA RTX 8000s and H100s. Assessing and Visualizing Location–Text Alignment.We sh...
-
[67]
desert” and “wadi
feature, while the sparse latent representation z=f enc(x) determines which features are active for a given input. 7.4.2 Sparse Linear Concept Embeddings (SpLiCE) To apply SpLiCE, we use apredefinedconcept dictionary, C∈R nc×dee, where nc is the num- ber of concepts. Each row in C corresponds to an embedding in the same space as the location embedding x∈R...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.