How Modular Is a Frontier Mixture-of-Experts? A Pre-registered Causal Test in Which Apparent Expert Modularity Mostly Dissolves
Pith reviewed 2026-06-26 00:05 UTC · model grok-4.3
The pith
Causal ablation tests on a frontier MoE model show that only one of six pre-registered expert families acts as a robust selective module.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
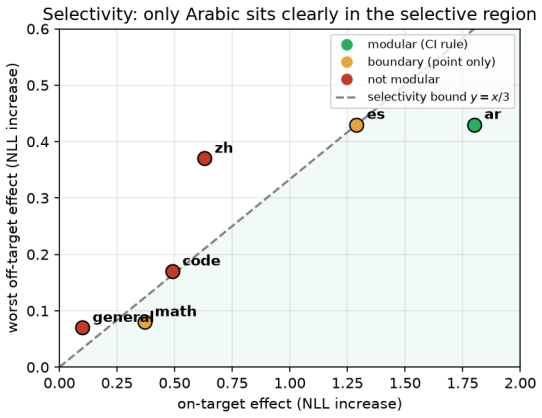
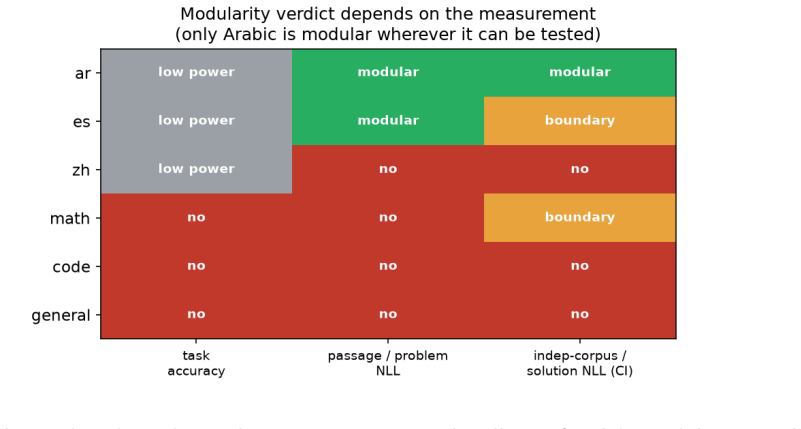
Robust functional modularity is rare and measurement-dependent. Of six pre-registered families, only one, the Arabic-language family, is a clean selective module that survives an independent corpus and a conservative statistical bar (1/6; a more permissive pre-registered point rule admits 3/6, but that count is threshold-sensitive). Every other family has a real causal effect yet fails selectivity, and its apparent modularity flips with the measurement: with the corpus, the metric, and the statistical bar.
What carries the argument
Pre-registered causal ablation of expert families identified via a routing-mass atlas, tested for selective performance drops on hypothesized axes against size-matched random controls.
If this is right
- Ablation-based claims of expert modularity are reliable only when the corpus, metric, and statistical bar are held fixed.
- The Arabic-language family produces selective effects on Arabic-related tasks that survive multiple controls.
- Apparent modularity for the other five families reverses when the evaluation setup changes.
- The method recovers published disjoint structure in a positive-control model, confirming it can detect modularity when present.
Where Pith is reading between the lines
- Existing analyses of MoE expert specialization may need re-examination if they rely on single-metric or single-corpus ablations.
- The pattern observed here could be tested on additional frontier MoE models to determine how widespread the measurement dependence is.
Load-bearing premise
The routing-mass atlas accurately identifies candidate functional families whose ablation will produce measurable, selective effects on the corresponding axes.
What would settle it
Finding two or more additional families that meet the selective criterion on the independent corpus under the conservative statistical bar would falsify the claim that robust modularity is rare.
Figures

read the original abstract
Sparse Mixture-of-Experts (MoE) models route each token to a few of many experts, inviting the hypothesis that experts form functional modules tied to capabilities or languages. We test this causally on Command A+, a frontier open-weights MoE (218B total / 25B active; 128 experts, 8 active, +1 shared). We build a routing-mass atlas, pre-register six family-to-axis hypotheses before any intervention, and ablate each family at inference time against a size-matched random-expert null, measuring whether it selectively breaks its own axis (worst off-target effect at most one third of on-target). Crucially, we test the same families under four metrics and a held-out, independent-corpus run with bootstrap confidence intervals. Our finding is cautionary: robust functional modularity is rare and measurement-dependent. Of six pre-registered families, only one, the Arabic-language family, is a clean selective module that survives an independent corpus and a conservative statistical bar (1/6; a more permissive pre-registered point rule admits 3/6, but that count is threshold-sensitive). Every other family has a real causal effect yet fails selectivity, and its apparent modularity flips with the measurement: with the corpus, the metric, and the statistical bar. A positive control on Qwen3-30B-A3B recovers its published disjoint structure, confirming the method detects modularity when present. The verdict reproduces on the un-quantized BF16 model, ruling out a 4-bit quantization artifact. We conclude that ablation-based modularity verdicts are not safe unless the corpus, metric, and statistical bar are controlled. We release the atlas and ablation data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a pre-registered causal ablation study on expert modularity in the Command A+ MoE model (218B total parameters). It constructs a routing-mass atlas to define six expert families, tests pre-registered family-to-axis hypotheses by ablating each family versus size-matched random nulls, and evaluates selectivity (on-target effect at least three times any off-target) across four metrics, a held-out independent corpus, and bootstrap intervals. Only the Arabic-language family meets the conservative bar; others show causal effects but fail selectivity or are sensitive to corpus/metric/threshold. A positive control recovers Qwen3's published structure, and results reproduce on the BF16 model. The conclusion is that robust functional modularity is rare and measurement-dependent; data and atlas are released.
Significance. If the central claim holds, the work demonstrates that ablation-based claims of expert specialization in frontier MoEs require strict controls on corpus, metric, and statistical threshold, as apparent modularity often dissolves under them. Strengths include the pre-registered design with explicit hypotheses, positive control recovering known structure, independent-corpus replication, bootstrap CIs, reproduction on unquantized weights, and full data release. These elements make the finding that only 1/6 families (Arabic) survives the conservative test internally consistent and falsifiable, providing a cautionary benchmark for future MoE interpretability studies.
minor comments (2)
- Abstract: the description of the routing-mass atlas construction and the exact definition of the six families could be expanded with one additional sentence to clarify how candidate families were identified from the atlas before pre-registration.
- The 1/3 off-target threshold and the 1/6 conservative bar are pre-registered, but a brief justification or sensitivity table in the methods would help readers understand why these specific values were chosen over alternatives.
Simulated Author's Rebuttal
We thank the referee for the positive and accurate summary of our work, the recognition of its methodological strengths (pre-registration, positive control, independent corpus, bootstrap CIs, BF16 reproduction, and data release), and the recommendation to accept. No major comments were raised.
Circularity Check
No significant circularity identified
full rationale
The paper's central claim rests on pre-registered ablation experiments that compare selective effects against size-matched random-expert nulls, an independent held-out corpus, bootstrap intervals, and a positive control recovering known structure in Qwen3. The routing-mass atlas is an input constructed from routing data, but the family-to-axis hypotheses are stated before any ablation, and the selectivity criterion (on-target effect at least three times any off-target) is applied uniformly; no result is forced by re-using the same fitted values or by a self-citation chain that itself lacks external verification. The design is therefore self-contained against the stated benchmarks and does not reduce any prediction to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Bootstrap confidence intervals provide valid uncertainty estimates for the selectivity ratios
Reference graph
Works this paper leans on
-
[1]
Nicol\`o De Sabbata, Greta Tuckute, Zeming Chen, Martin Schrimpf, and Antoine Bosselut
Badr AlKhamissi, C. Nicol\`o De Sabbata, Greta Tuckute, Zeming Chen, Martin Schrimpf, and Antoine Bosselut. Mixture of cognitive reasoners: Modular reasoning with brain-like specialization. arXiv preprint arXiv:2506.13331, 2026
Pith/arXiv arXiv 2026
-
[2]
Multilingual routing in mixture-of-experts
Lucas Bandarkar, Chenyuan Yang, Mohsen Fayyaz, Junlin Hu, and Nanyun Peng. Multilingual routing in mixture-of-experts. arXiv preprint arXiv:2510.04694, 2025
arXiv 2025
-
[3]
Command a+
Cohere . Command a+. https://cohere.com/blog/command-a-plus, 2026. Open-weights sparse Mixture-of-Experts model (218B total / 25B active; 128 experts, 8 active, +1 shared), Apache-2.0. CohereLabs/command-a-plus-05-2026
2026
-
[4]
From observation to intervention: A causal audit of expert importance in mixture-of-experts models
Leonard Engmann, Christian Medeiros Adriano, and Holger Giese. From observation to intervention: A causal audit of expert importance in mixture-of-experts models. arXiv preprint arXiv:2606.10703, 2026
Pith/arXiv arXiv 2026
-
[5]
The expert strikes back: Interpreting mixture-of-experts language models at expert level
Jeremy Herbst, Stefan Wermter, and Jae Hee Lee. The expert strikes back: Interpreting mixture-of-experts language models at expert level. arXiv preprint arXiv:2604.02178, 2026
Pith/arXiv arXiv 2026
-
[6]
Martin, Lucas Bandarkar, and Nanyun Peng
Liu O. Martin, Lucas Bandarkar, and Nanyun Peng. Extracting small translation specialists from llms by aggressively pruning experts. arXiv preprint arXiv:2605.28042, 2026
Pith/arXiv arXiv 2026
-
[7]
Aaron Mueller, Jannik Brinkmann, Millicent Li, Samuel Marks, Koyena Pal, Nikhil Prakash, Can Rager, Aruna Sankaranarayanan, Arnab Sen Sharma, Jiuding Sun, Eric Todd, David Bau, and Yonatan Belinkov. The quest for the right mediator: Surveying mechanistic interpretability through the lens of causal mediation analysis. arXiv preprint arXiv:2408.01416, 2024 a
arXiv 2024
-
[8]
Aaron Mueller et al. Missed causes and ambiguous effects: Counterfactuals pose challenges for interpreting neural networks. arXiv preprint arXiv:2407.04690, 2024 b
arXiv 2024
-
[9]
Claudia Shi, Nicolas Beltran-Velez, Achille Nazaret, Carolina Zheng, Adri\`a Garriga-Alonso, Andrew Jesson, Maggie Makar, and David M. Blei. Hypothesis testing the circuit hypothesis in llms. arXiv preprint arXiv:2410.13032, 2024
arXiv 2024
-
[10]
Deconstructing pre-training: Knowledge attribution analysis in moe and dense models
Bo Wang, Junzhuo Li, Hong Chen, Yuanlin Chu, Yuxuan Fan, and Xuming Hu. Deconstructing pre-training: Knowledge attribution analysis in moe and dense models. arXiv preprint arXiv:2601.08383, 2026
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.