Dataset Usage Inference without Shadow Models or Held-out Data
Pith reviewed 2026-06-26 01:49 UTC · model grok-4.3
The pith
A framework estimates the fraction of a dataset used to train a model without shadow models or real held-out data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
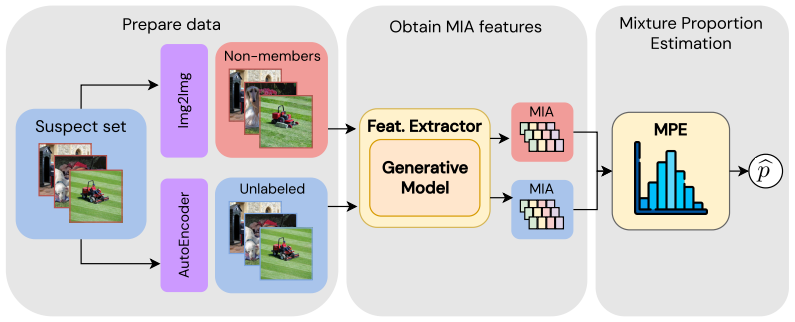
The authors claim that by generating synthetic non-member samples, extracting diverse membership signals, and casting DUI as a mixture proportion estimation problem, one can accurately quantify the share of a candidate dataset used during training, as shown by reliable results on large image generative models.
What carries the argument
Mixture proportion estimation applied to membership signals extracted from synthetically generated non-member samples
Load-bearing premise
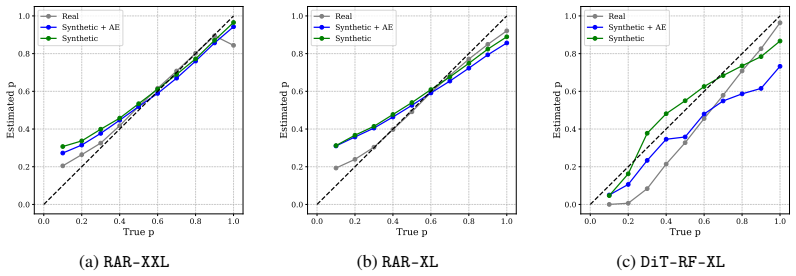
Synthetic non-member samples must generate membership signals sufficiently similar to those from real held-out data for the mixture proportion estimates to be accurate.
What would settle it
A controlled test on a model whose exact training data fraction is known in advance, where the method's output deviates substantially from the true fraction, would show the approach fails.
Figures

read the original abstract
How much of my data was used to train a machine learning model? Dataset Usage Inference (DUI) aims to answer this by estimating what fraction of a dataset contributed to a model's training. However, existing DUI methods rely on assumptions that rarely hold in practice: they require training expensive shadow models to imitate the target model, and they assume access to both known training samples and an in-distribution held-out set confirmed to be absent from training. These conditions make current approaches impractical for modern large models and real data ownership disputes. We introduce a practical DUI framework that removes these constraints. Our method requires neither shadow models nor real held-out data. Instead, it generates synthetic non-member samples, extracts diverse membership signals, and casts DUI as a mixture proportion estimation problem to estimate what share of the candidate dataset was used during training. Experiments on large image generative models show that our method reliably quantifies dataset usage, providing a practical tool for data owners to determine how much of their data was used to train a model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a practical Dataset Usage Inference (DUI) framework that estimates the fraction of a candidate dataset used to train a model without shadow models or real held-out data. It generates synthetic non-member samples, extracts diverse membership signals, and reduces DUI to a mixture proportion estimation problem. The abstract asserts that experiments on large image generative models demonstrate reliable quantification of dataset usage.
Significance. If the result holds, the method would remove major practical barriers (computational cost of shadow models and need for confirmed held-out data) that currently limit DUI to small-scale or artificial settings. This could enable data owners to audit usage in modern large models, with implications for privacy, copyright, and data ownership disputes. The paper receives credit for framing the problem as an external mixture estimation task rather than an internally fitted quantity.
major comments (2)
- [Abstract] Abstract: the claim that experiments 'show that our method reliably quantifies dataset usage' is unsupported by any quantitative results, error analysis, baselines, or validation metrics in the provided text. Soundness cannot be assessed from the abstract alone.
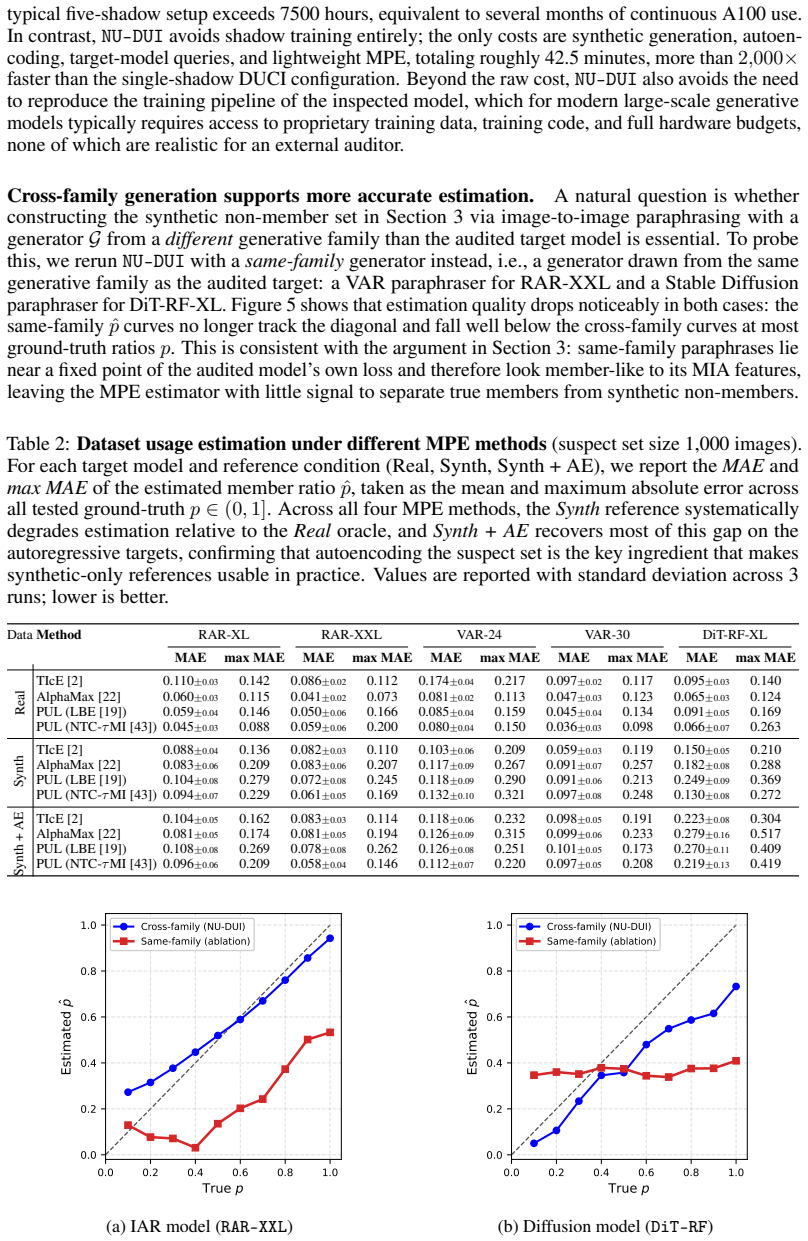
- Method (as described in abstract): the mixture proportion estimator recovers the true usage fraction only if the membership-signal distribution induced by the synthetic non-members is statistically close to that of genuine non-members. Any systematic shift biases the recovered mixing weight. The text supplies no construction details for the synthetic samples nor any empirical test (e.g., Kolmogorov-Smirnov statistic or moment matching) that the two distributions are sufficiently aligned.
minor comments (1)
- [Abstract] Abstract: the acronym 'DUI' is introduced after the first use of the full term; ensure consistent abbreviation on first occurrence.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comments. We address each major point below. The abstract is a high-level summary; the full manuscript contains the supporting experiments, method details, and evaluations. Where the comments identify gaps in the current presentation, we indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that experiments 'show that our method reliably quantifies dataset usage' is unsupported by any quantitative results, error analysis, baselines, or validation metrics in the provided text. Soundness cannot be assessed from the abstract alone.
Authors: We agree that an abstract cannot substitute for the full experimental section. The manuscript body reports quantitative results on large image generative models, including error metrics, baseline comparisons, and validation against known usage fractions. To address the concern, we will revise the abstract to include a brief reference to the key quantitative findings (e.g., mean absolute error ranges) while remaining within length limits, and we will ensure the abstract explicitly points to the experimental section for full details. revision: partial
-
Referee: [—] Method (as described in abstract): the mixture proportion estimator recovers the true usage fraction only if the membership-signal distribution induced by the synthetic non-members is statistically close to that of genuine non-members. Any systematic shift biases the recovered mixing weight. The text supplies no construction details for the synthetic samples nor any empirical test (e.g., Kolmogorov-Smirnov statistic or moment matching) that the two distributions are sufficiently aligned.
Authors: The referee correctly identifies a critical assumption. The method section details the procedure for generating synthetic non-member samples (via controlled perturbations and out-of-distribution sampling) and presents empirical comparisons of membership-signal distributions. However, we did not include formal statistical tests such as Kolmogorov-Smirnov or moment-matching statistics. We will add these explicit alignment tests in the revision, along with sensitivity analysis showing the effect of any residual distributional shift on the recovered mixing weights. revision: yes
Circularity Check
No circularity: DUI framed as reduction to external mixture proportion estimation
full rationale
The paper's core claim is that DUI can be solved by generating synthetic non-members, extracting membership signals, and solving a standard mixture proportion estimation problem. This reduction is to an external statistical primitive rather than a quantity defined inside the paper or fitted to the target result itself. No self-definitional equations, fitted-input predictions, or load-bearing self-citations appear in the provided abstract or description. The method is therefore self-contained against external benchmarks for mixture estimation, warranting a score of 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Getty Images (US), Inc. et al. v. Stability AI Ltd. High Court of Justice, Business and Property Courts of England and Wales, Intellectual Property List (ChD), 2025. Neutral Citation: [2025] EWHC 2863 (Ch); Case No. IL-2023-000007
2025
-
[2]
Estimating the class prior in positive and unlabeled data through decision tree induction
Jessa Bekker and Jesse Davis. Estimating the class prior in positive and unlabeled data through decision tree induction. InProceedings of the AAAI conference on artificial intelligence, 2018
2018
-
[3]
Beyond the selected completely at random assumption for learning from positive and unlabeled data, 2019
Jessa Bekker, Pieter Robberechts, and Jesse Davis. Beyond the selected completely at random assumption for learning from positive and unlabeled data, 2019
2019
-
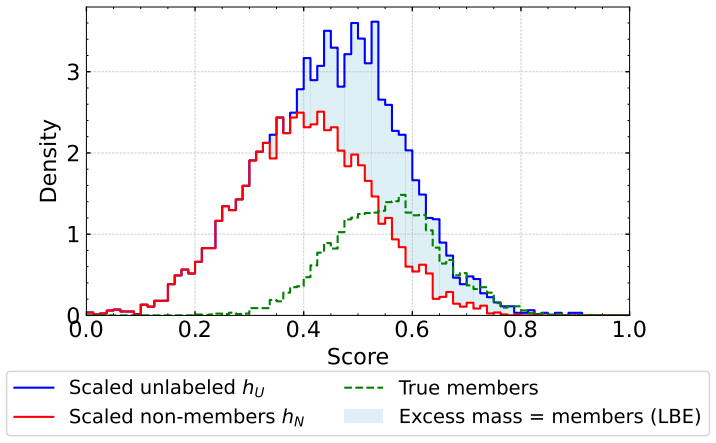
[4]
Semi-supervised novelty detection.Journal of Machine Learning Research, 11(99):2973–3009, 2010
Gilles Blanchard, Gyemin Lee, and Clayton Scott. Semi-supervised novelty detection.Journal of Machine Learning Research, 11(99):2973–3009, 2010
2010
-
[5]
Extracting training data from diffusion models
Nicholas Carlini, Jamie Hayes, Milad Nasr, Matthew Jagielski, Vikash Sehwag, Florian Tramèr, Borja Balle, Daphne Ippolito, and Eric Wallace. Extracting training data from diffusion models. 2023
2023
-
[6]
Hongyan Chang, Ali Shahin Shamsabadi, Kleomenis Katevas, Hamed Haddadi, and Reza Shokri. Context-aware membership inference attacks against pre-trained large language models.arXiv preprint arXiv:2409.13745, 2024
arXiv 2024
-
[7]
Generative pretraining from pixels
Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, and Ilya Sutskever. Generative pretraining from pixels. InInternational conference on machine learning, pages 1691–1703. PMLR, 2020
2020
-
[8]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
2009
-
[9]
BERT: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis,...
2019
-
[10]
Are diffusion models vulnerable to membership inference attacks? InProceedings of the 40th International Conference on Machine Learning, pages 8717–8730
Jinhao Duan, Fei Kong, Shiqi Wang, Xiaoshuang Shi, and Kaidi Xu. Are diffusion models vulnerable to membership inference attacks? InProceedings of the 40th International Conference on Machine Learning, pages 8717–8730. PMLR, 2023. 10
2023
-
[11]
Towards more realistic membership inference attacks on large diffusion models
Jan Dubi´nski, Antoni Kowalczuk, Stanisław Pawlak, Przemyslaw Rokita, Tomasz Trzci´nski, and Paweł Morawiecki. Towards more realistic membership inference attacks on large diffusion models. InPro- ceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 4860–4869, 2024
2024
-
[12]
Cdi: Copyrighted data identification in diffusion models
Jan Dubi ´nski, Antoni Kowalczuk, Franziska Boenisch, and Adam Dziedzic. Cdi: Copyrighted data identification in diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18674–18684, 2025
2025
-
[13]
Dataset inference for self-supervised models.Advances in Neural Information Processing Systems, 35:12058–12070, 2022
Adam Dziedzic, Haonan Duan, Muhammad Ahmad Kaleem, Nikita Dhawan, Jonas Guan, Yannis Cattan, Franziska Boenisch, and Nicolas Papernot. Dataset inference for self-supervised models.Advances in Neural Information Processing Systems, 35:12058–12070, 2022
2022
-
[14]
Learning classifiers from only positive and unlabeled data
Charles Elkan and Keith Noto. Learning classifiers from only positive and unlabeled data. InProceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 213–220, 2008
2008
-
[15]
Taming transformers for high-resolution image synthesis, 2020
Patrick Esser, Robin Rombach, and Björn Ommer. Taming transformers for high-resolution image synthesis, 2020
2020
-
[16]
Scaling diffusion transform- ers to 16 billion parameters, 2024
Zhengcong Fei, Mingyuan Fan, Changqian Yu, Debang Li, and Junshi Huang. Scaling diffusion transform- ers to 16 billion parameters, 2024
2024
-
[17]
zlib compression library
Jean-loup Gailly and Mark Adler. zlib compression library. 2004
2004
-
[18]
Recover- ing the propensity score from biased positive unlabeled data
Walter Gerych, Thomas Hartvigsen, Luke Buquicchio, Emmanuel Agu, and Elke Rundensteiner. Recover- ing the propensity score from biased positive unlabeled data. InProceedings of the AAAI conference on artificial intelligence, pages 6694–6702, 2022
2022
-
[19]
Instance- dependent positive and unlabeled learning with labeling bias estimation.IEEE transactions on pattern analysis and machine intelligence, 44(8):4163–4177, 2022
Chen Gong, Qizhou Wang, Tongliang Liu, Bo Han, Jane You, Jian Yang, and Dacheng Tao. Instance- dependent positive and unlabeled learning with labeling bias estimation.IEEE transactions on pattern analysis and machine intelligence, 44(8):4163–4177, 2022
2022
-
[20]
Membership inference via backdooring.arXiv preprint arXiv:2206.04823, 2022
Hongsheng Hu, Zoran Salcic, Gillian Dobbie, Jinjun Chen, Lichao Sun, and Xuyun Zhang. Membership inference via backdooring.arXiv preprint arXiv:2206.04823, 2022
arXiv 2022
-
[21]
Dedpul: Difference-of-estimated-densities-based positive-unlabeled learning
Dmitry Ivanov. Dedpul: Difference-of-estimated-densities-based positive-unlabeled learning. In2020 19th IEEE International Conference on Machine Learning and Applications (ICMLA), pages 782–790, 2020
2020
-
[22]
Nonparametric semi-supervised learning of class proportions.arXiv preprint arXiv:1601.01944, 2016
Shantanu Jain, Martha White, Michael W Trosset, and Predrag Radivojac. Nonparametric semi-supervised learning of class proportions.arXiv preprint arXiv:1601.01944, 2016
Pith/arXiv arXiv 2016
-
[23]
du Plessis, and Masashi Sugiyama
Ryuichi Kiryo, Gang Niu, Marthinus C. du Plessis, and Masashi Sugiyama. Positive-unlabeled learning with non-negative risk estimator, 2017
2017
-
[24]
An efficient membership inference attack for the diffusion model by proximal initialization
Fei Kong, Jinhao Duan, RuiPeng Ma, Heng Tao Shen, Xiaoshuang Shi, Xiaofeng Zhu, and Kaidi Xu. An efficient membership inference attack for the diffusion model by proximal initialization. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[25]
Privacy attacks on image autoregressive models.arXiv preprint arXiv:2502.02514, 2025
Antoni Kowalczuk, Jan Dubi´nski, Franziska Boenisch, and Adam Dziedzic. Privacy attacks on image autoregressive models.arXiv preprint arXiv:2502.02514, 2025
Pith/arXiv arXiv 2025
-
[26]
Open-sourced dataset protection via backdoor watermarking.arXiv preprint arXiv:2010.05821, 2020
Yiming Li, Ziqi Zhang, Jiawang Bai, Baoyuan Wu, Yong Jiang, and Shu-Tao Xia. Open-sourced dataset protection via backdoor watermarking.arXiv preprint arXiv:2010.05821, 2020
arXiv 2010
-
[27]
Untargeted backdoor watermark: Towards harmless and stealthy dataset copyright protection.Advances in Neural Information Processing Systems, 35:13238–13250, 2022
Yiming Li, Yang Bai, Yong Jiang, Yong Yang, Shu-Tao Xia, and Bo Li. Untargeted backdoor watermark: Towards harmless and stealthy dataset copyright protection.Advances in Neural Information Processing Systems, 35:13238–13250, 2022
2022
-
[28]
Black-box dataset ownership verification via backdoor watermarking.IEEE Transactions on Information Forensics and Security, 2023
Yiming Li, Mingyan Zhu, Xue Yang, Yong Jiang, Tao Wei, and Shu-Tao Xia. Black-box dataset ownership verification via backdoor watermarking.IEEE Transactions on Information Forensics and Security, 2023
2023
-
[29]
Partially supervised classification of text documents
Bing Liu, Wee Sun Lee, Philip S Yu, and Xiaoli Li. Partially supervised classification of text documents. InICML, pages 387–394. Sydney, NSW, 2002
2002
-
[30]
Reassessing emnlp 2024’s best paper: Does divergence-based calibration for mias hold up? InThe Fourth Blogpost Track at ICLR 2025
Pratyush Maini and Anshuman Suri. Reassessing emnlp 2024’s best paper: Does divergence-based calibration for mias hold up? InThe Fourth Blogpost Track at ICLR 2025. 11
2024
-
[31]
Dataset inference: Ownership resolution in ma- chine learning
Pratyush Maini, Mohammad Yaghini, and Nicolas Papernot. Dataset inference: Ownership resolution in ma- chine learning. InProceedings of ICLR 2021: 9th International Conference on Learning Representationsn, 2021
2021
-
[32]
Llm dataset inference: Did you train on my dataset?, 2024
Pratyush Maini, Hengrui Jia, Nicolas Papernot, and Adam Dziedzic. Llm dataset inference: Did you train on my dataset?, 2024
2024
-
[33]
Convex formulation for learning from positive and unlabeled data
Marthinus Du Plessis, Gang Niu, and Masashi Sugiyama. Convex formulation for learning from positive and unlabeled data. InProceedings of the 32nd International Conference on Machine Learning, pages 1386–1394, Lille, France, 2015. PMLR
2015
-
[34]
Language models are unsupervised multitask learners
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners
-
[35]
Mixture proportion estimation via kernel em- beddings of distributions
Harish Ramaswamy, Clayton Scott, and Ambuj Tewari. Mixture proportion estimation via kernel em- beddings of distributions. InInternational conference on machine learning, pages 2052–2060. PMLR, 2016
2052
-
[36]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022
2022
-
[37]
Mutual information between discrete and continuous data sets.PloS one, 9:e87357, 2014
Brian Ross. Mutual information between discrete and continuous data sets.PloS one, 9:e87357, 2014
2014
-
[38]
On the frequency bias of generative models
Katja Schwarz, Yiyi Liao, and Andreas Geiger. On the frequency bias of generative models. InAdvances in Neural Information Processing Systems, pages 18126–18136. Curran Associates, Inc., 2021
2021
-
[39]
Clayton D. Scott. A rate of convergence for mixture proportion estimation, with application to learning from noisy labels. InInternational Conference on Artificial Intelligence and Statistics, 2015
2015
-
[40]
Detecting pretraining data from large language models
Weijia Shi, Anirudh Ajith, Mengzhou Xia, Yangsibo Huang, Daogao Liu, Terra Blevins, Danqi Chen, and Luke Zettlemoyer. Detecting pretraining data from large language models. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[41]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. InInternational Conference on Learning Representations, 2021
2021
-
[42]
Ruixiang Tang, Qizhang Feng, Ninghao Liu, Fan Yang, and Xia Hu. Did you train on my dataset? towards public dataset protection with clean-label backdoor watermarking.arXiv preprint arXiv:2303.11470, 2023
arXiv 2023
-
[43]
Learning from biased positive-unlabeled data via threshold calibration
Paweł Teisseyre, Timo Martens, Jessa Bekker, and Jesse Davis. Learning from biased positive-unlabeled data via threshold calibration. InProceedings of The 28th International Conference on Artificial Intelligence and Statistics, pages 2314–2322. PMLR, 2025
2025
-
[44]
Complaint
The New York Times Company. Complaint. https://nytco-assets.nytimes.com/2023/12/NYT_ Complaint_Dec2023.pdf, 2023. Civil Action No. 1:23-cv-11195, United States District Court for the Southern District of New York
2023
-
[45]
Visual autoregressive modeling: Scalable image generation via next-scale prediction, 2024
Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Liwei Wang. Visual autoregressive modeling: Scalable image generation via next-scale prediction, 2024
2024
-
[46]
How much of my dataset did you use? quantitative data usage inference in machine learning
Yao Tong, Jiayuan Ye, Sajjad Zarifzadeh, and Reza Shokri. How much of my dataset did you use? quantitative data usage inference in machine learning. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[47]
United States Code. U.s. copyright act, title 17, section 107. https://www.copyright.gov/title17/ 92chap1.html#107, 1976. Fair Use
1976
-
[48]
Neural discrete representation learning, 2018
Aaron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. Neural discrete representation learning, 2018
2018
-
[49]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems (NeurIPS), pages 5998–6008, 2017
2017
-
[50]
Privacy risk in machine learning: Analyzing the connection to overfitting
Samuel Yeom, Irene Giacomelli, Matt Fredrikson, and Somesh Jha. Privacy risk in machine learning: Analyzing the connection to overfitting. InIEEE Computer Security Foundations Symposium (CSF), 2018
2018
-
[51]
Randomized autoregressive visual generation, 2024
Qihang Yu, Ju He, Xueqing Deng, Xiaohui Shen, and Liang-Chieh Chen. Randomized autoregressive visual generation, 2024. 12
2024
-
[52]
Low-cost high-power membership inference attacks
Sajjad Zarifzadeh, Philippe Liu, and Reza Shokri. Low-cost high-power membership inference attacks. arXiv preprint arXiv:2312.03262, 2023
arXiv 2023
-
[53]
Membership inference on text-to-image diffusion models via conditional likelihood discrepancy
Shengfang Zhai, Huanran Chen, Yinpeng Dong, Jiajun Li, Qingni Shen, Yansong Gao, Hang Su, and Yang Liu. Membership inference on text-to-image diffusion models via conditional likelihood discrepancy. In Advances in Neural Information Processing Systems, pages 74122–74146. Curran Associates, Inc., 2024
2024
-
[54]
Anqi Zhang and Chaofeng Wu. Adaptive pre-training data detection for large language models via surprising tokens.arXiv preprint arXiv:2407.21248, 2024
arXiv 2024
-
[55]
Unlocking post-hoc dataset inference with synthetic data
Bihe Zhao, Pratyush Maini, Franziska Boenisch, and Adam Dziedzic. Unlocking post-hoc dataset inference with synthetic data. InForty-second International Conference on Machine Learning, 2025. 13 Broader Impact This work can help data owners and auditors estimate whether, and to what extent, a particular dataset was used to train a generative model, support...
2025
-
[56]
excess mass
and the underlying papers; we refer the reader to those works for full derivations. Each scalar score below contributes one featuref m toΦ MIA(x). Denoising loss [5].Following the loss-attack tradition for discriminative models [ 50], this score evaluates the squared denoising error at a fixed timestept ∗=100: SLoss(x) = 1 K KX k=1 ϵk −M z(k) t∗ , t∗ 2 2 ...
-
[57]
Mixture assumption.The unlabeled score distribution is a convex mixture pU(s) =π p M(s) + (1−π)p N(s)of the member and non-member score distributions, as in Section 3
-
[58]
Representative non-members.The reference set N faithfully represents the non-member com- ponent of U, with no covariate or domain shift between N and the non-member portion of U
-
[59]
Support separation.There exists at least one region in score space where members occur but non-members do not, ensuring identifiability ofπ. 18
-
[60]
Sufficient sample size.The histograms hU and hN approximate the true densities closely enough that sampling noise does not dominate the mixture-ratio constraint. When these conditions hold, ˆpconverges to the true member ratio π as the sample sizes of U and N increase. Our framework is not tied to any specific PUL algorithm; other estimators from the lite...
arXiv 2090
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.