Equivariance and Augmentation for Bayesian Neural Networks
Pith reviewed 2026-06-26 01:47 UTC · model grok-4.3
The pith
Data augmentation reaches exact equivariance in Bayesian neural networks when variational distributions belong to the exponential family.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
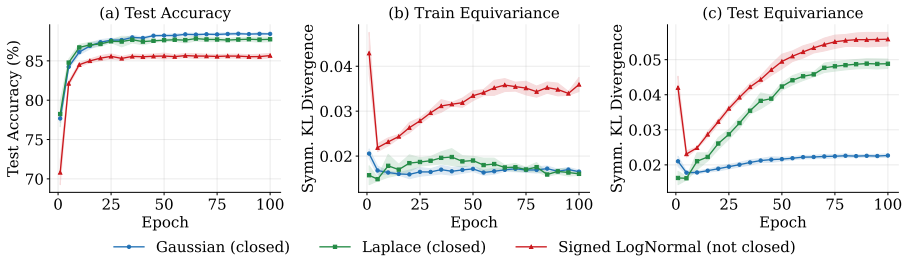
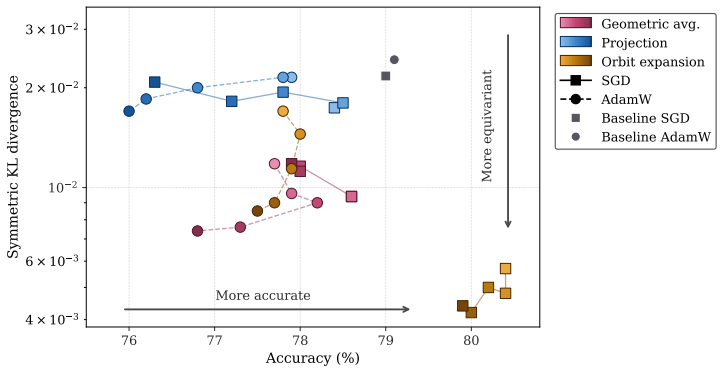
For variational distributions in the exponential family, data augmentation yields exact equivariance in Bayesian neural networks trained with variational inference; the paper derives the necessary conditions, supplies bounds on the equivariance error, and presents three symmetrization techniques that amplify the augmentation effect, with orbit expansion shown to outperform the baseline in numerical tests.
What carries the argument
Conditions on exponential-family variational distributions that turn data augmentation into exact equivariance, together with three symmetrization techniques (including orbit expansion) that reduce equivariance error.
If this is right
- Equivariance can be obtained without modifying the network architecture.
- The three symmetrization techniques provide concrete ways to reduce equivariance error beyond plain augmentation.
- Orbit expansion yields measurable gains in both symmetry and predictive performance on the tested tasks.
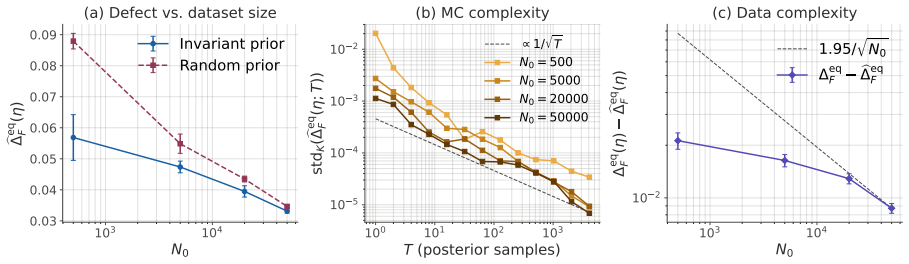
- The derived bounds quantify how far a given augmentation scheme remains from exact equivariance.
Where Pith is reading between the lines
- The same exponential-family argument might extend to other approximate inference methods that admit closed-form updates.
- If orbit expansion scales to larger models, it could reduce the need for hand-crafted equivariant layers in scientific applications.
- The error bounds could be used to decide when augmentation alone is sufficient versus when architectural symmetry is still required.
Load-bearing premise
The variational distributions used in the Bayesian neural networks must belong to the exponential family.
What would settle it
A direct numerical check that, for a variational distribution outside the exponential family, the same augmentation procedure fails to produce exact equivariance even after symmetrization.
Figures






read the original abstract
Symmetries are important for many deep learning tasks, ranging from applications in the sciences to medical imaging. However, there is an ongoing debate about whether to impose symmetry constraints on the neural network architecture (yielding equivariant neural networks) or learn them from augmented training data. Although equivariant networks are well-studied theoretically, much less is known about data augmentation, since analyzing augmentation requires control over the training dynamics. Inspired by recent results that show that augmented infinite deep ensembles are exactly equivariant, we study data augmentation for Bayesian neural networks (BNNs) trained with variational inference. We focus on variational distributions in the exponential family and derive conditions under which exact equivariance is reached. We furthermore obtain bounds on the equivariance error and introduce three novel symmetrization techniques which boost the effect of data augmentation in this setting. We conduct extensive numerical experiments which show that one of our symmetrization methods (orbit expansion) outperforms the baseline in both equivariance and overall performance. Our code is available at github.com/dmw1998/augment-BNNs
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript studies data augmentation for Bayesian neural networks trained via variational inference. Focusing on variational distributions belonging to the exponential family, it derives conditions for exact equivariance under data augmentation, obtains bounds on the equivariance error, and introduces three novel symmetrization techniques. Experiments indicate that the orbit expansion technique outperforms baselines in both equivariance and overall performance. Code is made available.
Significance. If the derivations hold, the work extends results on exact equivariance in infinite ensembles to the variational inference setting for BNNs, providing scoped theoretical conditions, error bounds, and practical symmetrization methods. The explicit restriction to the exponential family and the availability of code for reproducibility are strengths that support verification and potential adoption in symmetry-aware probabilistic modeling.
minor comments (2)
- Abstract: while the three symmetrization techniques are introduced, only orbit expansion is named; briefly listing the other two would improve clarity on the contributions.
- The experimental section would benefit from explicit summary of datasets, metrics, and baseline details in the abstract or early introduction to allow readers to assess the outperformance claim without reading the full results.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the manuscript, recognition of the theoretical contributions on exact equivariance conditions and error bounds for augmented BNNs under variational inference (restricted to the exponential family), and the recommendation for minor revision. The acknowledgment of the code availability and potential for adoption in symmetry-aware modeling is appreciated.
Circularity Check
No significant circularity; derivation self-contained under stated assumptions
full rationale
The paper explicitly scopes its analysis to variational distributions belonging to the exponential family, then derives equivariance conditions, error bounds, and three symmetrization techniques directly from that restriction and the data-augmentation setup. The cited inspiration from infinite-ensemble results functions only as motivation and is not used to define or force any of the new bounds or techniques. No self-citations are load-bearing, no parameters fitted to data are relabeled as predictions, and no uniqueness theorems or ansatzes are smuggled in via prior author work. The experimental validation of orbit expansion is independent of the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Variational distributions belong to the exponential family
invented entities (1)
-
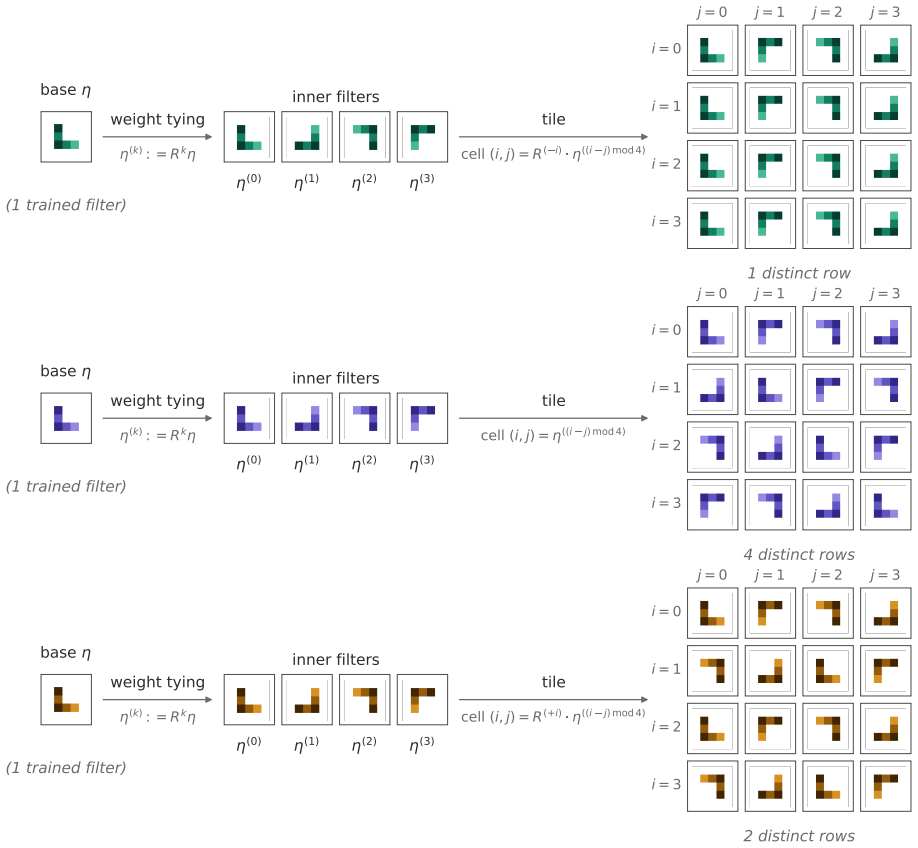
orbit expansion symmetrization technique
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Geometric deep learning: going beyond euclidean data
Michael M Bronstein et al. “Geometric deep learning: going beyond euclidean data”. In:IEEE Signal Processing Magazine34.4 (2017), pp. 18–42
2017
-
[2]
A group-theoretic framework for data augmentation
Shuxiao Chen, Edgar Dobriban, and Jane H Lee. “A group-theoretic framework for data augmentation”. In:The Journal of Machine Learning Research21.1 (2020), pp. 9885–9955
2020
-
[3]
Swallowing the Bitter Pill: Simplified Scalable Conformer Generation
Yuyang Wang et al. “Swallowing the Bitter Pill: Simplified Scalable Conformer Generation”. In:Proceedings of the 41st International Conference on Machine Learning. PMLR, July 2024, pp. 50400–50418. arXiv:2311.17932
arXiv 2024
-
[4]
Emergent Equivariance in Deep Ensembles
Jan E. Gerken and Pan Kessel. “Emergent Equivariance in Deep Ensembles”. In:Proceedings of the 41st International Conference on Machine Learning. PMLR, July 2024, pp. 15438–15465. arXiv:2403.03103
arXiv 2024
-
[5]
Oskar Nordenfors and Axel Flinth.Ensembles provably learn equivariance through data augmentation. 2025. arXiv: 2410.01452
arXiv 2025
-
[6]
Optimization Dynamics of Equivariant and Augmented Neural Networks
Oskar Nordenfors, Fredrik Ohlsson, and Axel Flinth. “Optimization Dynamics of Equivariant and Augmented Neural Networks”. In:Transactions on Machine Learning Research(2025)
2025
-
[7]
Group Equivariant Convolutional Networks
Taco Cohen and Max Welling. “Group Equivariant Convolutional Networks”. In:Proceedings of The 33rd International Conference on Machine Learning. PMLR, June 2016, pp. 2990–2999. arXiv:1602.07576
Pith/arXiv arXiv 2016
-
[8]
On the generalization of equivariance and convolution in neural networks to the action of compact groups
Risi Kondor and Shubhendu Trivedi. “On the generalization of equivariance and convolution in neural networks to the action of compact groups”. In:International Conference on Machine Learning. PMLR. 2018, pp. 2747–2755
2018
-
[9]
Universal invariant and equivariant graph neural networks
Nicolas Keriven and Gabriel Peyr ´e. “Universal invariant and equivariant graph neural networks”. In:Advances in neural information processing systems32 (2019)
2019
-
[10]
Jan E. Gerken et al. “Geometric Deep Learning and Equivariant Neural Networks”. In:Artificial Intelligence Review (June 2023).issn: 1573-7462.doi:10.1007/s10462-023-10502-7. arXiv:2105.13926. 11
-
[11]
Scalars are universal: Equivariant machine learning, structured like classical physics
Soledad Villar et al. “Scalars are universal: Equivariant machine learning, structured like classical physics”. In:Advances in Neural Information Processing Systems34 (2021), pp. 28848–28863
2021
-
[12]
Frame Averaging for Invariant and Equivariant Network Design
Omri Puny et al. “Frame Averaging for Invariant and Equivariant Network Design”. In:International Conference on Learning Representations. 2022
2022
-
[13]
Group invariant machine learning by fundamental domain projec- tions
Benjamin Aslan, Daniel Platt, and David Sheard. “Group invariant machine learning by fundamental domain projec- tions”. In:NeurIPS Workshop on Symmetry and Geometry in Neural Representations. PMLR. 2023, pp. 181–218
2023
-
[14]
Approximately equivariant networks for imperfectly symmetric dynamics
Rui Wang, Robin Walters, and Rose Yu. “Approximately equivariant networks for imperfectly symmetric dynamics”. In:International Conference on Machine Learning. PMLR. 2022, pp. 23078–23091
2022
-
[15]
Clare Lyle et al.On the benefits of invariance in neural networks. 2020. arXiv:2005.00178
arXiv 2020
-
[16]
Provably strict generalisation benefit for equivariant models
Bryn Elesedy and Sheheryar Zaidi. “Provably strict generalisation benefit for equivariant models”. In:Proceedings of the 38th International Conference on Machine Learning. PMLR. 2021, pp. 2959–2969
2021
-
[17]
Implicit Bias of Linear Equivariant Networks
Hannah Lawrence et al. “Implicit Bias of Linear Equivariant Networks”. In:International Conference on Machine Learning. PMLR. 2022, pp. 12096–12125
2022
-
[18]
On the Implicit Bias of Linear Equivariant Steerable Networks
Ziyu Chen and Wei Zhu. “On the Implicit Bias of Linear Equivariant Steerable Networks”. In:Advances in Neural Information Processing Systems36 (2024)
2024
- [19]
-
[20]
Data Augmentation and Regularization for Learning Group Equivariance
Oskar Nordenfors and Axel Flinth. “Data Augmentation and Regularization for Learning Group Equivariance”. In:2025 International Conference on Sampling Theory and Applications (SampTA). 2025, pp. 1–5
2025
-
[21]
Training or Architecture? How to Incorporate Invariance in Neural Networks
Kanchana Vaishnavi Gandikota et al. “Training or Architecture? How to Incorporate Invariance in Neural Networks”. In:arXiv:2106.10044(June 18, 2021). arXiv:2106.10044
arXiv 2021
-
[22]
Equivariance versus Augmentation for Spherical Images
Jan Gerken et al. “Equivariance versus Augmentation for Spherical Images”. In:Proceedings of the 39th International Conference on Machine Learning. PMLR, 2022, pp. 7404–7421
2022
-
[23]
Does Equivariance Matter at Scale?
Johann Brehmer et al. “Does Equivariance Matter at Scale?” In:Transactions on Machine Learning Research(Apr. 2025).issn: 2835-8856. arXiv:2410.23179
arXiv 2025
-
[24]
A Practical Bayesian Framework for Backpropagation Networks
David J. C. MacKay. “A Practical Bayesian Framework for Backpropagation Networks”. In:Neural Computation4.3 (May 1992), pp. 448–472.issn: 0899-7667.doi:10.1162/neco.1992.4.3.448
-
[25]
Uncertainty in Deep Learning
Yarin Gal. “Uncertainty in Deep Learning”. PhD thesis. University of Cambridge, 2016
2016
-
[26]
Practical Variational Inference for Neural Networks
Alex Graves. “Practical Variational Inference for Neural Networks”. In:Advances in Neural Information Processing Systems. Ed. by J. Shawe-Taylor et al. Vol. 24. Curran Associates, Inc., 2011
2011
-
[27]
Weight Uncertainty in Neural Network
Charles Blundell et al. “Weight Uncertainty in Neural Network”. In:Proceedings of the 32nd International Conference on Machine Learning. PMLR, June 2015, pp. 1613–1622
2015
-
[28]
Diederik P Kingma and Max Welling.Auto-Encoding Variational Bayes. 2022. arXiv:1312.6114
Pith/arXiv arXiv 2022
-
[29]
Hands-On Bayesian Neural Networks—A Tutorial for Deep Learning Users
Laurent Valentin Jospin et al. “Hands-On Bayesian Neural Networks—A Tutorial for Deep Learning Users”. In:IEEE Computational Intelligence Magazine17.2 (May 2022), pp. 29–48.issn: 1556-6048.doi:10 . 1109 / MCI . 2022 . 3155327
2022
-
[30]
Learning invariant weights in neural networks
Tycho F.A. van der Ouderaa and Mark van der Wilk. “Learning invariant weights in neural networks”. In:Proceedings of the Thirty-Eighth Conference on Uncertainty in Artificial Intelligence. Ed. by James Cussens and Kun Zhang. Vol. 180. Proceedings of Machine Learning Research. PMLR, Jan. 2022, pp. 1992–2001
2022
-
[31]
A Bayesian Approach to Invariant Deep Neural Networks
Nikolaos Mourdoukoutas et al. “A Bayesian Approach to Invariant Deep Neural Networks”. In:arXiv:2107.09301 [cs, stat](July 2021). arXiv:2107.09301
arXiv 2021
-
[32]
Bishop.Pattern Recognition and Machine Learning
Christopher M. Bishop.Pattern Recognition and Machine Learning. Information Science and Statistics. New York: Springer, 2006.isbn: 978-0-387-31073-2
2006
-
[33]
Han Xiao, Kashif Rasul, and Roland Vollgraf.Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms. 2017. arXiv:1708.07747
Pith/arXiv arXiv 2017
-
[34]
On the method of bounded differences
Colin McDiarmid. “On the method of bounded differences”. In:Surveys in Combinatorics, 1989: Invited Papers at the Twelfth British Combinatorial Conference. Ed. by J.Editor Siemons. London Mathematical Society Lecture Note Series. Cambridge University Press, 1989, pp. 148–188
1989
-
[35]
Regularity Properties of Certain Families of Chance Variables
J. L. Doob. “Regularity Properties of Certain Families of Chance Variables”. In:Transactions of the American Mathe- matical Society47.3 (1940), pp. 455–486.issn: 00029947, 10886850. 12 A From discrete to continuous compact groups It is often the case in the geometric deep learning literature that virtually all results concerning finite groups can be gener...
arXiv 1940
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.