MixTTA: Low-Rank Cross-Channel Mixing for Reliable Test-Time Adaptation
Pith reviewed 2026-06-29 04:53 UTC · model grok-4.3
The pith
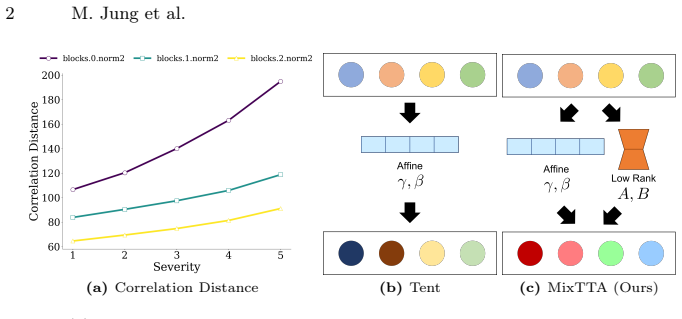
MixTTA adds a low-rank cross-channel transformation to normalization layers so that test-time adaptation can correct structural changes across channels that per-channel affine updates cannot reach.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
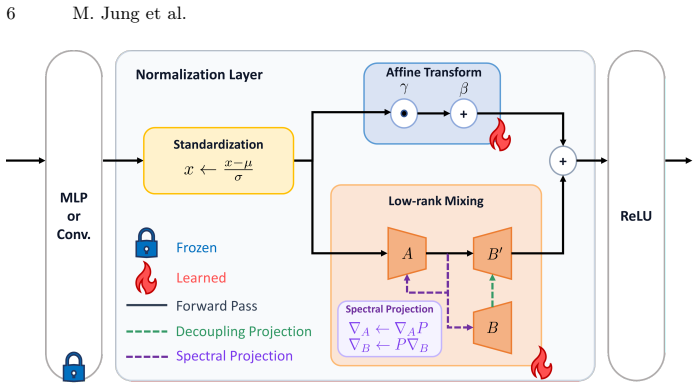
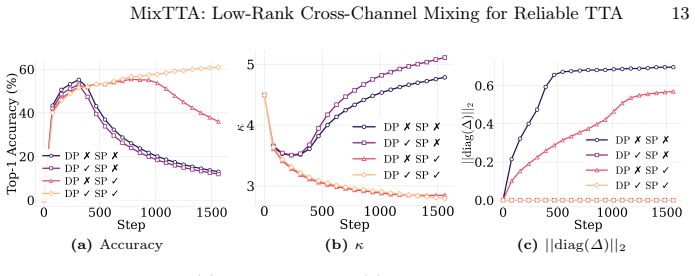
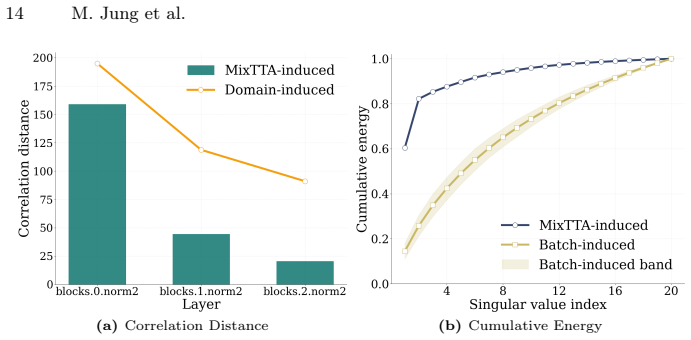
Equipping normalization layers with a low-rank cross-channel transformation, kept separate from the diagonal affine path by Decoupling Projection and guarded against rank-1 collapse by Spectral Projection, allows existing TTA methods to correct cross-channel structural changes induced by distribution shift.
What carries the argument
Low-rank cross-channel transformation inserted into normalization layers, together with Decoupling Projection that enforces separation from the diagonal affine path and Spectral Projection that prevents rank-1 collapse.
If this is right
- Any normalization-based TTA method gains the ability to handle cross-channel distribution effects by adding the module.
- Adaptation remains stable when test distributions keep drifting because the spectral guard prevents rank collapse.
- The added parameters stay low-rank and therefore cheap to optimize at test time.
- The same mixing idea can be dropped into other layers that currently use only per-channel normalization.
Where Pith is reading between the lines
- The same separation principle could be applied to other adaptation settings where diagonal updates are known to be insufficient.
- If the low-rank branch proves robust, similar mixing could replace or augment batch-norm in non-TTA continual-learning pipelines.
- Testing on architectures without batch-norm would reveal whether the benefit is tied to the normalization layer itself.
Load-bearing premise
The projections will keep the low-rank branch strictly off the original affine path and stop rank collapse under non-stationary test streams without creating new failure modes or needing heavy retuning.
What would settle it
A controlled non-stationary test stream in which the low-rank branch collapses to rank one or leaks into the diagonal path and produces no accuracy gain or worse adaptation than the baseline TTA method.
Figures
read the original abstract
Test-Time Adaptation (TTA) methods commonly update the affine parameters of normalization layers to adapt deployed models under distribution shifts. However, per-channel affine parameters perform axis-aligned scaling and shifting, making them geometrically incapable of correcting cross-channel structural changes induced by distribution shift. To address this limitation, we propose MixTTA, a lightweight plug-in module that equips normalization layers with a low-rank cross-channel transformation, enabling inter-channel mixing at each layer. To ensure that the low-rank branch captures only cross-channel interactions, we also propose Decoupling Projection that enforces strict separation from the diagonal affine path, along with Spectral Projection that prevents rank-1 collapse under non-stationary test streams. MixTTA can be seamlessly integrated into any existing normalization-based TTA method. Experiments in both standard and wild TTA settings show consistent improvements over strong baselines while mitigating adaptation failure under challenging conditions. The source code is publicly available at https://github.com/delta6189/MixTTA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MixTTA, a lightweight plug-in module for test-time adaptation (TTA) that augments normalization layers with a low-rank cross-channel transformation. This enables inter-channel mixing to address the geometric limitation of per-channel affine parameters under distribution shift. The method includes Decoupling Projection to enforce separation from the diagonal affine path and Spectral Projection to prevent rank-1 collapse in non-stationary streams. MixTTA integrates into existing normalization-based TTA methods, with experiments claiming consistent gains in standard and wild TTA settings and mitigation of adaptation failures. Source code is released publicly.
Significance. If the projections reliably isolate off-diagonal interactions without leakage or collapse, the approach would directly target a structural shortcoming in current TTA practice and could yield more robust adaptation under covariate shift. The public code release is a clear strength that supports reproducibility.
major comments (2)
- [Abstract / method description] Abstract and method section: The assertion that Decoupling Projection 'enforces strict separation from the diagonal affine path' and that Spectral Projection 'prevents rank-1 collapse' is presented without an explicit algebraic identity, orthogonality proof, or contraction argument showing that the composed low-rank operator remains orthogonal to the diagonal path for arbitrary incoming feature covariances. This is load-bearing for the central geometric claim.
- [Experiments] Experimental claims: The abstract states 'consistent improvements over strong baselines' and 'mitigating adaptation failure,' yet the provided description supplies no quantitative tables, ablation results on the projections, or failure-mode analysis under rapid non-stationary shifts that would confirm the projections avoid introducing new instabilities.
minor comments (1)
- Notation for the low-rank factors and projection operators should be introduced with explicit matrix dimensions and update rules to clarify implementation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the geometric justification and experimental support.
read point-by-point responses
-
Referee: [Abstract / method description] Abstract and method section: The assertion that Decoupling Projection 'enforces strict separation from the diagonal affine path' and that Spectral Projection 'prevents rank-1 collapse' is presented without an explicit algebraic identity, orthogonality proof, or contraction argument showing that the composed low-rank operator remains orthogonal to the diagonal path for arbitrary incoming feature covariances. This is load-bearing for the central geometric claim.
Authors: We agree that explicit algebraic support is needed for the central claim. In the revision we will add a lemma establishing the orthogonality of the Decoupling Projection to the diagonal affine path (via direct matrix identity) and a contraction argument showing that the Spectral Projection bounds the operator away from rank-1 collapse for non-stationary covariance sequences. These will appear in the method section with the relevant proofs. revision: yes
-
Referee: [Experiments] Experimental claims: The abstract states 'consistent improvements over strong baselines' and 'mitigating adaptation failure,' yet the provided description supplies no quantitative tables, ablation results on the projections, or failure-mode analysis under rapid non-stationary shifts that would confirm the projections avoid introducing new instabilities.
Authors: The full manuscript reports quantitative results on standard and wild TTA benchmarks, yet we concur that targeted ablations isolating the two projections and explicit failure-mode analysis under rapid non-stationarity would better substantiate the claims. We will expand the experiments section with these ablations, additional tables, and non-stationary shift analysis in the revised version. revision: yes
Circularity Check
No circularity: proposal introduces new architectural components without reducing claims to fitted inputs or self-citations
full rationale
The paper presents MixTTA as a plug-in module with newly proposed Decoupling Projection and Spectral Projection operators. These are defined to achieve separation and rank preservation by construction of the module itself, but the manuscript does not claim any derivation of performance metrics, predictions, or uniqueness results that reduce back to previously fitted quantities or self-cited theorems. No load-bearing step equates an output quantity to an input by algebraic identity or statistical forcing. The central contribution is an engineering design choice whose correctness is evaluated empirically rather than derived tautologically. This matches the default non-circular case for an architectural proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Deep Residual Learning for Image Recognition , author=. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=. 2016 , organization=
2016
-
[2]
Proceedings of the European conference on computer vision (ECCV) , pages=
Group normalization , author=. Proceedings of the European conference on computer vision (ECCV) , pages=
-
[3]
GitHub repository , doi =
Ross Wightman , title =. GitHub repository , doi =. 2019 , publisher =
2019
-
[4]
International Conference on Learning Representations , year =
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations , author =. International Conference on Learning Representations , year =
-
[5]
International conference on machine learning , pages=
Unsupervised domain adaptation by backpropagation , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[6]
European conference on computer vision , pages=
Deep coral: Correlation alignment for deep domain adaptation , author=. European conference on computer vision , pages=. 2016 , organization=
2016
-
[7]
Advances in Neural Information Processing Systems , volume=
Test-time classifier adjustment module for model-agnostic domain generalization , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
International Conference on Learning Representations , year =
Tent: Fully Test-Time Adaptation by Entropy Minimization , author =. International Conference on Learning Representations , year =
-
[9]
International conference on machine learning , pages=
Efficient test-time model adaptation without forgetting , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[10]
International Conference on Learning Representations , year =
Towards Stable Test-Time Adaptation in Dynamic Wild World , author =. International Conference on Learning Representations , year =
-
[11]
The Twelfth International Conference on Learning Representations , year=
Entropy is not Enough for Test-time Adaptation: From the Perspective of Disentangled Factors , author=. The Twelfth International Conference on Learning Representations , year=
-
[12]
Advances in neural information processing systems , volume=
Memo: Test time robustness via adaptation and augmentation , author=. Advances in neural information processing systems , volume=
-
[13]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Image style transfer using convolutional neural networks , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[14]
International Conference on Learning Representations , year=
Minimal-Entropy Correlation Alignment for Unsupervised Deep Domain Adaptation , author=. International Conference on Learning Representations , year=
-
[15]
HoMM: Higher-Order Moment Matching for Unsupervised Domain Adaptation , booktitle =
Chao Chen and Zhihang Fu and Zhihong Chen and Sheng Jin and Zhaowei Cheng and Xinyu Jin and Xian. HoMM: Higher-Order Moment Matching for Unsupervised Domain Adaptation , booktitle =. 2020 , url =. doi:10.1609/AAAI.V34I04.5745 , timestamp =
-
[16]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Domain adaptation by mixture of alignments of second-or higher-order scatter tensors , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[17]
Advances in neural information processing systems , volume=
Universal style transfer via feature transforms , author=. Advances in neural information processing systems , volume=
-
[18]
Ieee Access , volume=
Deep correlation multimodal neural style transfer , author=. Ieee Access , volume=. 2021 , publisher=
2021
-
[19]
Deep Learning using Rectified Linear Units (ReLU)
Deep learning using rectified linear units (relu) , author=. arXiv preprint arXiv:1803.08375 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Joint geometrical and statistical alignment for visual domain adaptation , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[21]
International conference on machine learning , pages=
Domain adaptation with asymmetrically-relaxed distribution alignment , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[22]
International conference on machine learning , pages=
Batch normalization: Accelerating deep network training by reducing internal covariate shift , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[23]
Layer normalization , author=. arXiv preprint arXiv:1607.06450 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
International Conference on Learning Representations , year =
LoRA: Low-Rank Adaptation of Large Language Models , author =. International Conference on Learning Representations , year =
-
[25]
International conference on machine learning , pages=
Learning transferable features with deep adaptation networks , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[26]
International conference on machine learning , pages=
Parameter-efficient transfer learning for NLP , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[27]
Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
The power of scale for parameter-efficient prompt tuning , author=. Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
2021
-
[28]
International Conference on Learning Representations (ICLR) , year =
Central Moment Discrepancy (CMD) for Domain-Invariant Representation Learning , author =. International Conference on Learning Representations (ICLR) , year =
-
[29]
International Conference on Machine Learning (ICML) , pages =
Deep Transfer Learning with Joint Adaptation Networks , author =. International Conference on Machine Learning (ICML) , pages =
-
[30]
Journal of machine learning research , volume=
Domain-adversarial training of neural networks , author=. Journal of machine learning research , volume=
-
[31]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
Adversarial Discriminative Domain Adaptation , author =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
-
[32]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
Maximum Classifier Discrepancy for Unsupervised Domain Adaptation , author =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
-
[33]
Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics (EACL) , year =
AdapterFusion: Non-Destructive Task Composition for Transfer Learning , author =. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics (EACL) , year =
-
[34]
European Conference on Computer Vision (ECCV) , year =
Visual Prompt Tuning , author =. European Conference on Computer Vision (ECCV) , year =
-
[35]
Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL) , pages =
Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning , author =. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL) , pages =
-
[36]
Advances in neural information processing systems , volume=
Qlora: Efficient finetuning of quantized llms , author=. Advances in neural information processing systems , volume=
-
[37]
Proceedings of the thirteenth international conference on artificial intelligence and statistics , pages=
Understanding the difficulty of training deep feedforward neural networks , author=. Proceedings of the thirteenth international conference on artificial intelligence and statistics , pages=. 2010 , organization=
2010
-
[38]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Projection metric learning on Grassmann manifold with application to video based face recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[39]
SIAM Journal on Matrix Analysis and Applications , volume=
Schubert varieties and distances between subspaces of different dimensions , author=. SIAM Journal on Matrix Analysis and Applications , volume=. 2016 , publisher=
2016
-
[40]
Proceedings of the 25th international conference on Machine learning , pages=
Grassmann discriminant analysis: a unifying view on subspace-based learning , author=. Proceedings of the 25th international conference on Machine learning , pages=
-
[41]
2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , pages=
Test-time low rank adaptation via confidence maximization for zero-shot generalization of vision-language models , author=. 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , pages=. 2025 , organization=
2025
-
[42]
arXiv preprint arXiv:2502.02069 , year=
Lora-ttt: Low-rank test-time training for vision-language models , author=. arXiv preprint arXiv:2502.02069 , year=
-
[43]
International Conference on Machine Learning , pages=
Test-time Correlation Alignment , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[44]
International Conference on Learning Representations , year=
Spectral Normalization for Generative Adversarial Networks , author=. International Conference on Learning Representations , year=
-
[45]
International journal of computer vision , volume=
Imagenet large scale visual recognition challenge , author=. International journal of computer vision , volume=. 2015 , publisher=
2015
-
[46]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[47]
9th International Conference on Learning Representations,
Alexey Dosovitskiy and Lucas Beyer and Alexander Kolesnikov and Dirk Weissenborn and Xiaohua Zhai and Thomas Unterthiner and Mostafa Dehghani and Matthias Minderer and Georg Heigold and Sylvain Gelly and Jakob Uszkoreit and Neil Houlsby , title =. 9th International Conference on Learning Representations,. 2021 , url =
2021
-
[48]
International conference on machine learning , pages=
On the importance of initialization and momentum in deep learning , author=. International conference on machine learning , pages=. 2013 , organization=
2013
-
[49]
Advances in neural information processing systems , volume=
Learning robust global representations by penalizing local predictive power , author=. Advances in neural information processing systems , volume=
-
[50]
International Conference on Machine Learning , pages=
Beyond Entropy: Region Confidence Proxy for Wild Test-Time Adaptation , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[51]
Proceedings of the Asian Conference on Computer Vision , pages=
Learning dual hierarchical representation for 3D surface reconstruction , author=. Proceedings of the Asian Conference on Computer Vision , pages=
-
[52]
IEEE Access , year=
Leveraging Single Positive Class Label Supervision for Weakly Supervised Semantic Segmentation , author=. IEEE Access , year=
-
[53]
IEEE Access , year=
A plug-in curriculum scheduler for improved deformable medical image registration , author=. IEEE Access , year=
-
[54]
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , volume=
Instance-Dependent Multilabel Noise Generation for Multilabel Remote Sensing Image Classification , author=. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , volume=. 2024 , publisher=
2024
-
[55]
ICT Express , year=
EDAS: Effective Data Augmentation Strategies for test-time adaptation , author=. ICT Express , year=
-
[56]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Continual test-time domain adaptation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[57]
Advances in Neural Information Processing Systems , volume=
Swad: Domain generalization by seeking flat minima , author=. Advances in Neural Information Processing Systems , volume=
-
[58]
Yuge Shi and Jeffrey Seely and Philip H. S. Torr and Siddharth Narayanaswamy and Awni Y. Hannun and Nicolas Usunier and Gabriel Synnaeve , title =. The Tenth International Conference on Learning Representations,. 2022 , url =
2022
-
[59]
International conference on machine learning , pages=
Do we really need to access the source data? source hypothesis transfer for unsupervised domain adaptation , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[60]
Advances in neural information processing systems , volume=
Exploiting the intrinsic neighborhood structure for source-free domain adaptation , author=. Advances in neural information processing systems , volume=
-
[61]
Proceedings of the 61st ACM/IEEE Design Automation Conference , pages=
Rl-ptq: Rl-based mixed precision quantization for hybrid vision transformers , author=. Proceedings of the 61st ACM/IEEE Design Automation Conference , pages=
-
[62]
IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems , year=
Autonomous Model Quantization Framework for Hybrid Vision Transformers based on Reinforcement Learning , author=. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems , year=
-
[63]
Proceedings of the IEEE international conference on computer vision , pages=
Mask r-cnn , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[64]
The Twelfth International Conference on Learning Representations,
Jiaming Liu and Senqiao Yang and Peidong Jia and Renrui Zhang and Ming Lu and Yandong Guo and Wei Xue and Shanghang Zhang , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[65]
The Thirteenth International Conference on Learning Representations,
Qingyang Zhang and Yatao Bian and Xinke Kong and Peilin Zhao and Changqing Zhang , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
2025
-
[66]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Neural Collapse in Test-Time Adaptation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[67]
Advances in Neural Information Processing Systems , volume=
Note: Robust continual test-time adaptation against temporal correlation , author=. Advances in Neural Information Processing Systems , volume=
-
[68]
MoETTA: Test-Time Adaptation Under Mixed Distribution Shifts with MoE-LayerNorm , booktitle =
Xiao Fan and Jingyan Jiang and Zhaoru Chen and Fanding Huang and Xiao Chen and Qinting Jiang and Bowen Zhang and Xing Tang and Zhi Wang , editor =. MoETTA: Test-Time Adaptation Under Mixed Distribution Shifts with MoE-LayerNorm , booktitle =. 2026 , url =. doi:10.1609/AAAI.V40I25.39243 , timestamp =
-
[69]
Advances in Neural Information Processing Systems , volume=
Feature-based instance neighbor discovery: Advanced stable test-time adaptation in dynamic world , author=. Advances in Neural Information Processing Systems , volume=
-
[70]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Learning to generate gradients for test-time adaptation via test-time training layers , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[71]
BECoTTA: Input-dependent Online Blending of Experts for Continual Test-time Adaptation , booktitle =
Daeun Lee and Jaehong Yoon and Sung Ju Hwang , editor =. BECoTTA: Input-dependent Online Blending of Experts for Continual Test-time Adaptation , booktitle =. 2024 , url =
2024
-
[72]
Advances in Neural Information Processing Systems , volume=
Rethinking Entropy in Test-Time Adaptation: The Missing Piece from Energy Duality , author=. Advances in Neural Information Processing Systems , volume=
-
[73]
Advances in Neural Information Processing Systems , volume=
Partition-then-adapt: Combating prediction bias for reliable multi-modal test-time adaptation , author=. Advances in Neural Information Processing Systems , volume=
-
[74]
International Conference on Learning Representations , volume=
Dimension agnostic neural processes , author=. International Conference on Learning Representations , volume=
-
[75]
International Conference on Machine Learning , pages=
Boost-and-Skip: A Simple Guidance-Free Diffusion for Minority Generation , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.