Prototype Latent World Model Replay for Class-Incremental Learning
Pith reviewed 2026-06-30 07:55 UTC · model grok-4.3
The pith
Storing old classes as prototype-centered distributions in a frozen latent space allows class-incremental learning without raw image memory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
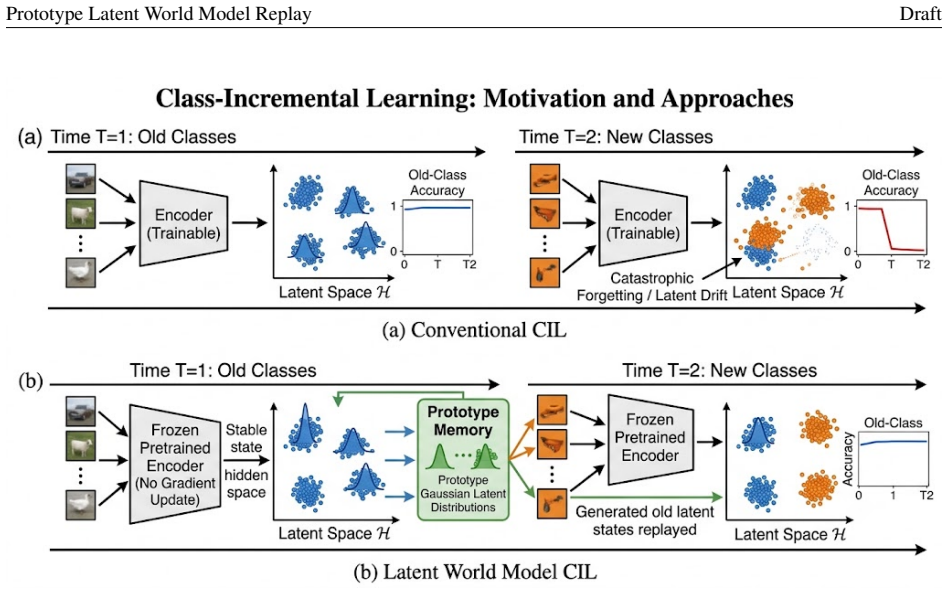
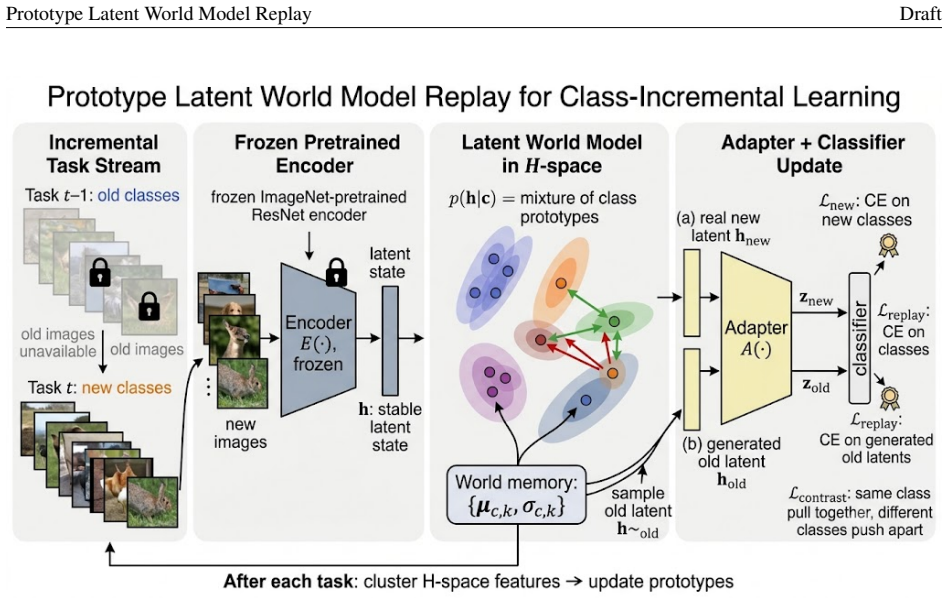
Prototype Latent World Model Replay stores old classes as distributions over hidden states from a frozen ImageNet-pretrained encoder. When new classes arrive, the model samples old states from these prototype distributions to train a lightweight adapter and classifier alongside new data. A supervised contrastive term in the adapter space promotes compactness within classes and separation between old and new ones. On Split CIFAR-100 this yields substantial gains in last and average accuracy across incremental protocols without any raw exemplar storage.
What carries the argument
Prototype Latent World Model Replay, which summarizes each class by several prototype-centered distributions with class-specific variances in the latent space produced by a frozen ImageNet-pretrained encoder, enabling sampling of old class states for replay during new-class training.
If this is right
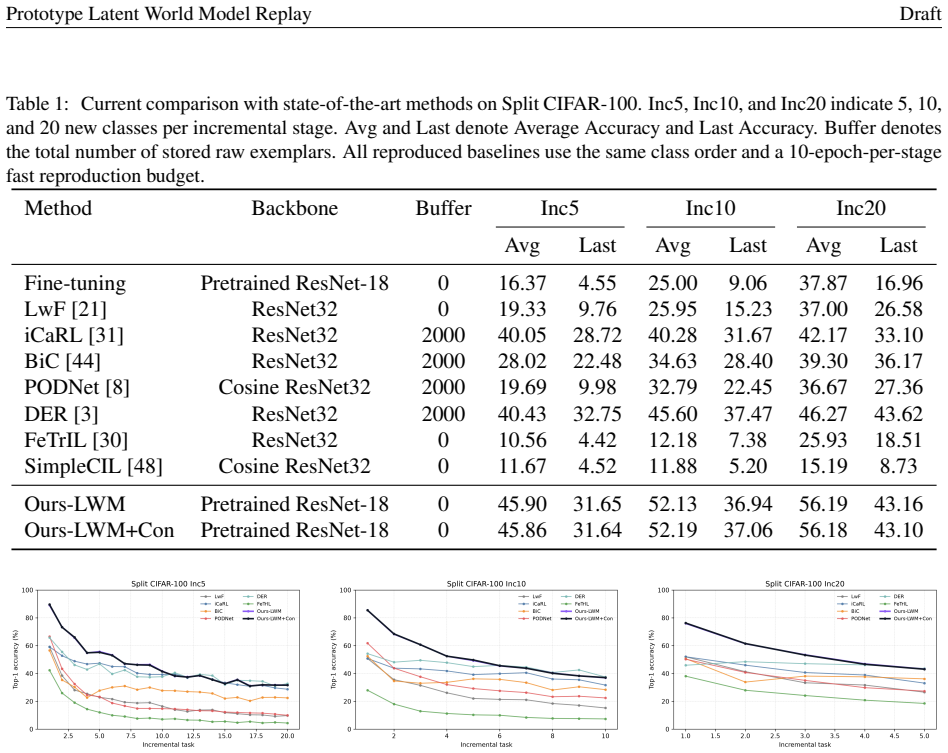
- The method raises LastAcc on Split CIFAR-100 from 4.55% to 31.64% in the Inc5 setting without storing raw exemplars.
- It raises LastAcc from 9.06% to 37.06% in Inc10 and from 16.96% to 43.10% in Inc20.
- Average accuracy reaches 45.86%, 52.19%, and 56.18% respectively across those incremental settings.
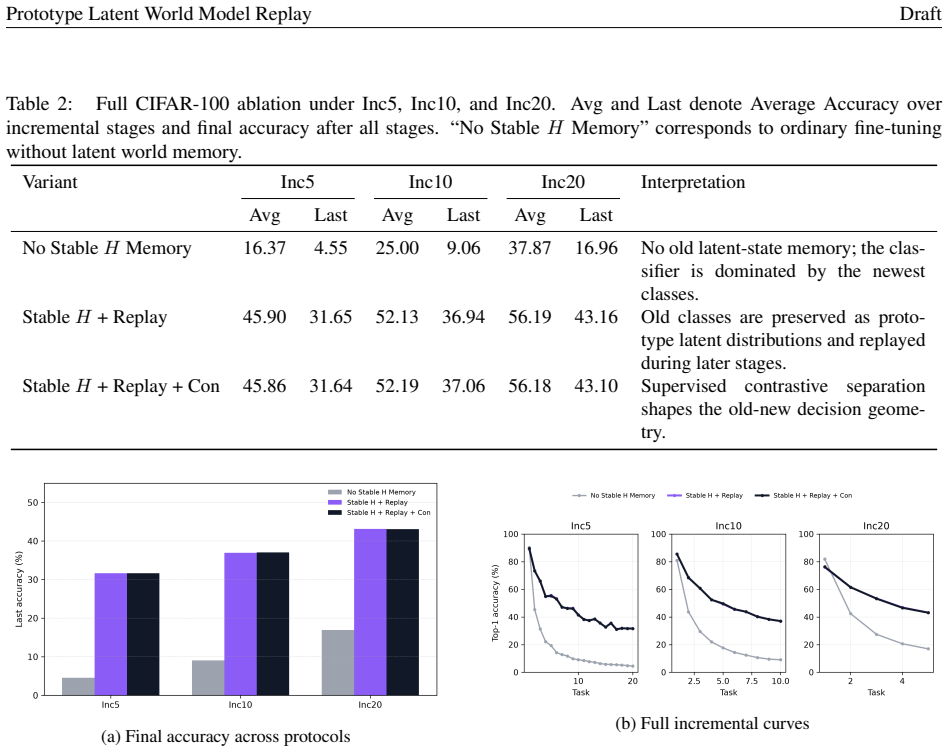
- Ablation studies identify stable latent-state replay as the main source of the performance gain.
- The added contrastive term further refines the geometry between old and new classes.
Where Pith is reading between the lines
- This latent replay strategy could extend to other continual learning benchmarks if the frozen encoder's representations prove sufficiently task-agnostic across domains.
- Reducing reliance on raw data storage might support continual learning in privacy-sensitive settings where retaining old images is restricted.
- The method implies that large-scale pretraining can supply reusable feature spaces that support incremental updates with only lightweight adapters and minimal extra memory.
- If the prototype distributions remain effective when the encoder is frozen from even larger or more diverse pretraining corpora, the memory-free property would strengthen further.
Load-bearing premise
The latent space produced by the frozen ImageNet-pretrained encoder remains stable and sufficiently representative for old classes so that sampling from prototype-centered distributions can preserve decision regions without access to the original images.
What would settle it
If training the adapter and classifier solely on sampled latent states from the prototypes produces no improvement in old-class accuracy over plain fine-tuning after new classes arrive, the claim that prototype replay preserves decision regions would be falsified.
Figures
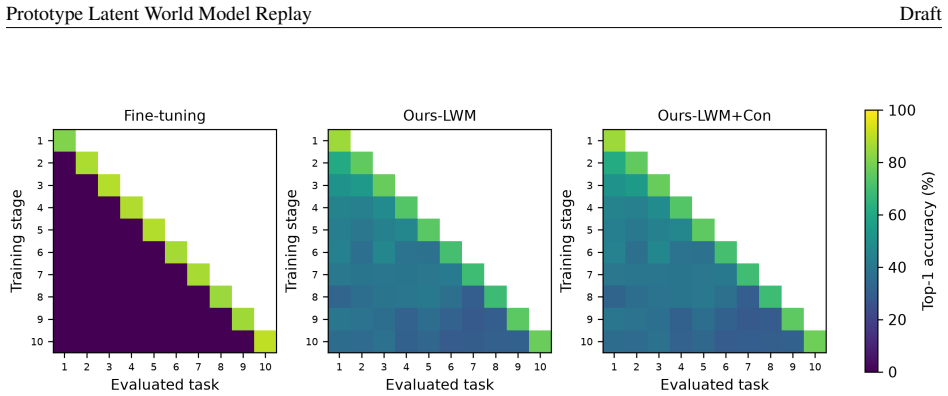
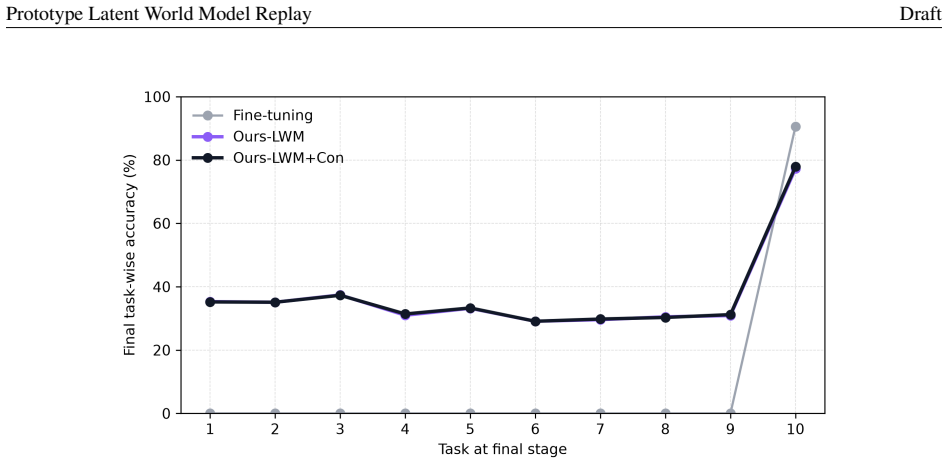
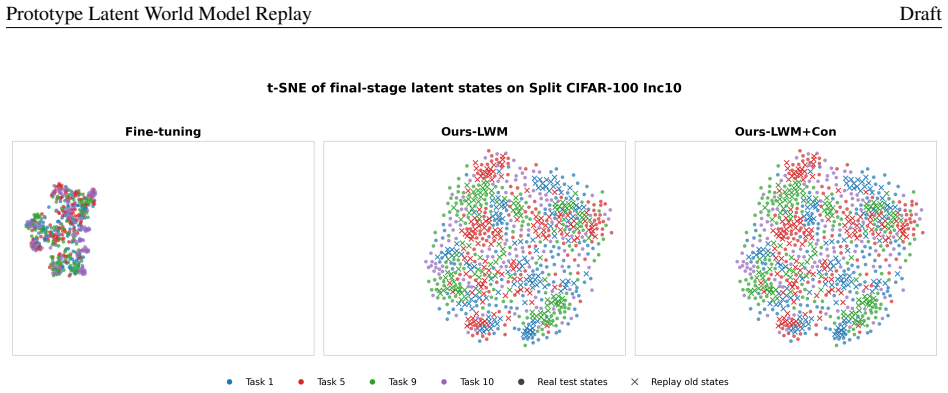
read the original abstract
Class-incremental learning requires a model to learn new classes while preserving decision regions for old ones. This is difficult when raw old samples are no longer available. We propose Prototype Latent World Model Replay, a memory-free framework that stores old classes as distributions over stable hidden states rather than as images. A frozen ImageNet-pretrained encoder maps each image into a latent state space. In this space, each class is summarized by several prototype-centered distributions with class-specific variances. When new classes arrive, the model samples old latent states from this prototype world model. It then trains a lightweight adapter and classifier using both sampled old states and real new-class features. We also add a supervised contrastive term in the adapter space to promote intra-class compactness and old-new class separation. On Split CIFAR-100, our method improves over fine-tuning under Inc5, Inc10, and Inc20 without storing raw exemplars. The full Ours-LWM+Con model raises LastAcc from 4.55% to 31.64%, from 9.06% to 37.06%, and from 16.96% to 43.10% in Inc5, Inc10, and Inc20, respectively. It also achieves AvgAcc of 45.86%, 52.19%, and 56.18%. Ablation and retention analyses show that stable latent-state replay is the main source of the gain. Contrastive separation further refines the old-new geometry. These results suggest that prototype latent memory preserves reusable class-state distributions, rather than only fitting the current classifier.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce Prototype Latent World Model Replay for class-incremental learning without raw exemplar storage. Using a frozen ImageNet-pretrained encoder, classes are modeled as prototype-centered distributions in latent space. New classes are learned by sampling old latent states for replay, training an adapter and classifier with contrastive loss. Significant accuracy improvements are reported on Split CIFAR-100 for different incremental settings.
Significance. If the results are robust, this provides evidence that latent prototype replay can mitigate catastrophic forgetting in a memory-efficient manner. The ablation studies crediting the replay mechanism add value. However, the significance is tempered by the unverified stability of the latent space assumption.
major comments (2)
- [abstract, framework paragraph] The assumption that the frozen encoder's latent space allows faithful replay via fixed prototype Gaussians is central but weakly supported; no direct test of feature distribution fidelity between real and sampled points is described, risking that the adapter learns from off-manifold samples.
- [abstract, results paragraph] The numerical gains are presented without statistical details such as variance across runs or exact baseline configurations, which is load-bearing for claiming superiority over fine-tuning.
minor comments (1)
- Consider adding a table summarizing the key hyperparameters for the prototype estimation and sampling process.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the latent space fidelity and statistical reporting. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [abstract, framework paragraph] The assumption that the frozen encoder's latent space allows faithful replay via fixed prototype Gaussians is central but weakly supported; no direct test of feature distribution fidelity between real and sampled points is described, risking that the adapter learns from off-manifold samples.
Authors: We agree that a direct test of distribution fidelity (e.g., via MMD, Wasserstein distance, or t-SNE visualizations between real and sampled latent features) would strengthen the central assumption. The manuscript provides indirect support through ablation studies showing that replay is the primary source of gains and that the frozen encoder yields stable representations, but this does not substitute for explicit fidelity verification. In the revised manuscript we will add such an analysis on Split CIFAR-100 to quantify how closely the prototype Gaussians match the empirical feature distributions. revision: yes
-
Referee: [abstract, results paragraph] The numerical gains are presented without statistical details such as variance across runs or exact baseline configurations, which is load-bearing for claiming superiority over fine-tuning.
Authors: We concur that variance across runs and precise baseline specifications are necessary for robust claims. The reported numbers reflect single-run results under the standard Split CIFAR-100 incremental protocols; exact baseline configurations follow the original papers but were not exhaustively re-specified. In revision we will rerun all methods with at least three random seeds, report mean and standard deviation, and expand the experimental section with full hyper-parameter tables and baseline implementation details. revision: yes
Circularity Check
No circularity; empirical performance claims rest on external benchmarks
full rationale
The paper proposes an algorithmic framework for class-incremental learning that stores class prototypes as distributions in a frozen ImageNet-pretrained latent space, samples from them for replay, and trains an adapter plus classifier with an added contrastive loss. Reported gains (e.g., LastAcc improvements on Split CIFAR-100 under Inc5/Inc10/Inc20 protocols) are obtained by direct comparison against fine-tuning and other baselines on held-out test data. No equations, fitted parameters, or self-citations are shown that would make any reported accuracy a definitional consequence of the method's own inputs; the central results remain falsifiable against external data splits and standard baselines.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The latent space of a frozen ImageNet-pretrained encoder remains stable and representative for previously seen classes over incremental training steps.
Reference graph
Works this paper leans on
-
[1]
Memory aware synapses: Learning what (not) to forget
Rahaf Aljundi, Francesca Babiloni, Mohamed Elhoseiny, Marcus Rohrbach, and Tinne Tuytelaars. Memory aware synapses: Learning what (not) to forget. InProceedings of the European Conference on Computer Vision, pages 139–154, 2018
2018
-
[2]
Self-supervised learning from images with a joint-embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint-embedding predictive architecture. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15619–15629, 2023
2023
-
[3]
Dark experience for general continual learning: A strong, simple baseline
Pietro Buzzega, Matteo Boschini, Angelo Porrello, Davide Abati, and Simone Calderara. Dark experience for general continual learning: A strong, simple baseline. InAdvances in Neural Information Processing Systems, volume 33, pages 15920–15930, 2020
2020
-
[4]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herve Jegou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 9650–9660, 2021
2021
-
[5]
Castro, Manuel J
Francisco M. Castro, Manuel J. Marin-Jimenez, Nicolas Guil, Cordelia Schmid, and Karteek Alahari. End-to-end incremental learning. InProceedings of the European Conference on Computer Vision, pages 233–248, 2018
2018
-
[6]
Efficient lifelong learning with a-gem
Arslan Chaudhry, Marc’Aurelio Ranzato, Marcus Rohrbach, and Mohamed Elhoseiny. Efficient lifelong learning with a-gem. InInternational Conference on Learning Representations, 2019
2019
-
[7]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InProceedings of the International Conference on Machine Learning, pages 1597–1607, 2020
2020
-
[8]
Podnet: Pooled outputs distillation for small-tasks incremental learning
Arthur Douillard, Matthieu Cord, Charles Ollion, Thomas Robert, and Eduardo Valle. Podnet: Pooled outputs distillation for small-tasks incremental learning. InProceedings of the European Conference on Computer Vision, pages 86–102, 2020
2020
-
[9]
Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Daniel Guo, Mohammad Gheshlaghi Azar, Bilal Piot, Koray Kavukcuoglu, Remi Munos, and Michal Valko
Jean-Bastien Grill, Florian Strub, Florent Altche, Corentin Tallec, Pierre H. Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Daniel Guo, Mohammad Gheshlaghi Azar, Bilal Piot, Koray Kavukcuoglu, Remi Munos, and Michal Valko. Bootstrap your own latent: A new approach to self-supervised learning. InAdvances in Neural Information Pr...
2020
-
[10]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016
2016
-
[11]
Momentum contrast for unsupervised visual representation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9729–9738, 2020
2020
-
[12]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollar, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16000–16009, 2022
2022
-
[13]
Learning a unified classifier incremen- tally via rebalancing
Saihui Hou, Xinyu Pan, Chen Change Loy, Zilei Wang, and Dahua Lin. Learning a unified classifier incremen- tally via rebalancing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 831–839, 2019
2019
-
[14]
Measuring catastrophic forgetting in neural networks.Proceedings of the AAAI Conference on Artificial Intelligence, 32(1), 2018
Ronald Kemker, Marc McClure, Angelina Abitino, Tyler Hayes, and Christopher Kanan. Measuring catastrophic forgetting in neural networks.Proceedings of the AAAI Conference on Artificial Intelligence, 32(1), 2018
2018
-
[15]
Supervised contrastive learning
Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. Supervised contrastive learning. InAdvances in Neural Information Processing Systems, volume 33, pages 18661–18673, 2020. 16 Prototype Latent World Model Replay Draft
2020
-
[16]
Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell. Overcoming catastrophic forgetting in neural networks.Proceedings of the National Academy of Sciences, 114(13):3521–...
2017
-
[17]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009
2009
-
[18]
Causal intervention-based multimodal class-incremental learning network for 3d model classification and retrieval.IEEE Access, 2025
Qiang Li, Qiu-Yang Ma, Ning Zhang, and Wei-Zhi Nie. Causal intervention-based multimodal class-incremental learning network for 3d model classification and retrieval.IEEE Access, 2025
2025
-
[19]
Causal inference-based self-supervised cross-domain fundus image segmentation.Applied Sciences, 15(9):5074, 2025
Qiang Li, Qiyi Zhang, Zheqi Zhang, Hengxin Liu, and Weizhi Nie. Causal inference-based self-supervised cross-domain fundus image segmentation.Applied Sciences, 15(9):5074, 2025
2025
-
[20]
Cd-gan: Comparative disen- tanglement learning for zero-shot cross-modal retrieval.IEEE Transactions on Circuits and Systems for Video Technology, 2026
Qiang Li, Shihao Wang, Yuhao Liu, Xiaorong Zhu, Shaojin Bai, and Weizhi Nie. Cd-gan: Comparative disen- tanglement learning for zero-shot cross-modal retrieval.IEEE Transactions on Circuits and Systems for Video Technology, 2026
2026
-
[21]
Learning without forgetting.IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(12):2935–2947, 2018
Zhizhong Li and Derek Hoiem. Learning without forgetting.IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(12):2935–2947, 2018
2018
-
[22]
Graph disentangled contrastive learning with personalized transfer for cross-domain recommendation
Jing Liu, Lele Sun, Weizhi Nie, Peiguang Jing, and Yuting Su. Graph disentangled contrastive learning with personalized transfer for cross-domain recommendation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 8769–8777, 2024
2024
-
[23]
Gradient episodic memory for continual learning
David Lopez-Paz and Marc’Aurelio Ranzato. Gradient episodic memory for continual learning. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[24]
Mf-gcn: Multimodal infor- mation fusion using incremental graph convolutional network for ship behavior anomaly detection.Journal of Marine Science and Engineering, 14(1):87, 2026
Ruixin Ma, Jinhao Zhang, Weizhi Nie, Naiming Ge, Hao Wen, and Aoxiang Liu. Mf-gcn: Multimodal infor- mation fusion using incremental graph convolutional network for ship behavior anomaly detection.Journal of Marine Science and Engineering, 14(1):87, 2026
2026
-
[25]
Bagdanov, and Joost van de Weijer
Marc Masana, Xialei Liu, Bartlomiej Twardowski, Mikel Menta, Andrew D. Bagdanov, and Joost van de Weijer. Class-incremental learning: survey and performance evaluation on image classification.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(5):5513–5533, 2023
2023
-
[26]
McDonnell, Dong Gong, Amin Parvaneh, Ehsan Abbasnejad, and Anton van den Hengel
Mark D. McDonnell, Dong Gong, Amin Parvaneh, Ehsan Abbasnejad, and Anton van den Hengel. Ranpac: Ran- dom projections and pre-trained models for continual learning. InAdvances in Neural Information Processing Systems, 2023
2023
-
[27]
T2td: Text-3d generation model based on prior knowledge guidance.IEEE Transactions on Pattern Analysis and Machine Intelligence, pages 1–18, 2024
Weizhi Nie, Ruidong Chen, Weijie Wang, Bruno Lepri, and Nicu Sebe. T2td: Text-3d generation model based on prior knowledge guidance.IEEE Transactions on Pattern Analysis and Machine Intelligence, pages 1–18, 2024
2024
-
[28]
Dinov2: Learning robust visual features without supervision.Transactions on Machine Learning Research, 2024
Maxime Oquab, Timothee Darcet, Theo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernan- dez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Jegou, Julien Mairal, Patrick ...
2024
-
[29]
Parisi, Ronald Kemker, Jose L
German I. Parisi, Ronald Kemker, Jose L. Part, Christopher Kanan, and Stefan Wermter. Continual lifelong learning with neural networks: A review.Neural Networks, 113:54–71, 2019
2019
-
[30]
Fetril: Feature trans- lation for exemplar-free class-incremental learning
Gregoire Petit, Adrian Popescu, Hugo Schindler, David Picard, and Bertrand Delezoide. Fetril: Feature trans- lation for exemplar-free class-incremental learning. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 3911–3920, 2023
2023
-
[31]
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H. Lampert. icarl: Incremental classifier and representation learning. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2001–2010, 2017. 17 Prototype Latent World Model Replay Draft
2001
-
[32]
Lr-gcn: Latent relation-aware graph convolutional network for conversational emotion recognition.IEEE Transactions on Multimedia, 24:4422– 4432, 2021
Minjie Ren, Xiangdong Huang, Wenhui Li, Dan Song, and Weizhi Nie. Lr-gcn: Latent relation-aware graph convolutional network for conversational emotion recognition.IEEE Transactions on Multimedia, 24:4422– 4432, 2021
2021
-
[33]
Continual learning with deep generative replay
Hanul Shin, Jung Kwon Lee, Jaehong Kim, and Jiwon Kim. Continual learning with deep generative replay. In Advances in Neural Information Processing Systems, volume 30, 2017
2017
-
[34]
Coda-prompt: Continual decomposed attention-based prompt- ing for rehearsal-free continual learning
James Seale Smith, Leonid Karlinsky, Vyshnavi Gutta, Paola Cascante-Bonilla, Donghyun Kim, Assaf Arbelle, Rameswar Panda, Rogerio Feris, and Zsolt Kira. Coda-prompt: Continual decomposed attention-based prompt- ing for rehearsal-free continual learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11909–11919, 2023
2023
-
[35]
van de Ven and Andreas S
Gido M. van de Ven and Andreas S. Tolias. Generative replay with feedback connections as a general strategy for continual learning. InNeurIPS Workshop on Continual Learning, 2018
2018
-
[36]
van de Ven, Hava T
Gido M. van de Ven, Hava T. Siegelmann, and Andreas S. Tolias. Brain-inspired replay for continual learning with artificial neural networks.Nature Communications, 11(1):4069, 2020
2020
-
[37]
van de Ven, Zhe Li, and Andreas S
Gido M. van de Ven, Zhe Li, and Andreas S. Tolias. Class-incremental learning with generative classifiers.arXiv preprint arXiv:2104.10093, 2021
-
[38]
Cross-domain correlation representation for new fault categories discovery in rolling bearings.Information Processing & Man- agement, 61(3):103659, 2024
Chenglong Wang, Jie Nie, Weizhi Nie, Peizhe Yin, Di Niu, Xinyue Liang, and Shusong Yu. Cross-domain correlation representation for new fault categories discovery in rolling bearings.Information Processing & Man- agement, 61(3):103659, 2024
2024
-
[39]
Foster: Feature boosting and compression for class-incremental learning
Fu-Yun Wang, Da-Wei Zhou, Han-Jia Ye, and De-Chuan Zhan. Foster: Feature boosting and compression for class-incremental learning. InProceedings of the European Conference on Computer Vision, pages 398–414, 2022
2022
-
[40]
A comprehensive survey of continual learning: Theory, method and application.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
Liyuan Wang, Xingxing Zhang, Hang Su, and Jun Zhu. A comprehensive survey of continual learning: Theory, method and application.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[41]
Dualprompt: Complementary prompting for rehearsal-free continual learning
Zifeng Wang, Zizhao Zhang, Sayna Ebrahimi, Ruoxi Sun, Han Zhang, Chen-Yu Lee, Xiaoqi Ren, Guolong Su, Vincent Perot, Jennifer Dy, and Tomas Pfister. Dualprompt: Complementary prompting for rehearsal-free continual learning. InProceedings of the European Conference on Computer Vision, pages 631–648, 2022
2022
-
[42]
Learning to prompt for continual learning
Zifeng Wang, Zizhao Zhang, Chen-Yu Lee, Han Zhang, Ruoxi Sun, Xiaoqi Ren, Guolong Su, Vincent Perot, Jennifer Dy, and Tomas Pfister. Learning to prompt for continual learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 139–149, 2022
2022
-
[43]
Class-incremental learning with strong pre-trained models
Tz-Ying Wu, Gurumurthy Swaminathan, Zhizhong Li, Avinash Ravichandran, Nuno Vasconcelos, Rahul Bhotika, and Stefano Soatto. Class-incremental learning with strong pre-trained models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9601–9610, 2022
2022
-
[44]
Large scale incremental learning
Yue Wu, Yinpeng Chen, Lijuan Wang, Yuancheng Ye, Zicheng Liu, Yandong Guo, and Yun Fu. Large scale incremental learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 374–382, 2019
2019
-
[45]
Continual learning through synaptic intelligence
Friedemann Zenke, Ben Poole, and Surya Ganguli. Continual learning through synaptic intelligence. InPro- ceedings of the International Conference on Machine Learning, pages 3987–3995, 2017
2017
-
[46]
Slca: Slow learner with clas- sifier alignment for continual learning on a pre-trained model
Gengwei Zhang, Liyuan Wang, Guoliang Kang, Ling Chen, and Yunchao Wei. Slca: Slow learner with clas- sifier alignment for continual learning on a pre-trained model. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 19148–19158, 2023
2023
-
[47]
Maintaining discrimination and fairness in class incremental learning
Bowen Zhao, Xi Xiao, Guojun Gan, Bin Zhang, and Shutao Xia. Maintaining discrimination and fairness in class incremental learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13208–13217, 2020. 18 Prototype Latent World Model Replay Draft
2020
-
[48]
Revisiting class-incremental learning with pre-trained models: Generalizability and adaptivity are all you need
Da-Wei Zhou, Zi-Wen Cai, Han-Jia Ye, De-Chuan Zhan, and Ziwei Liu. Revisiting class-incremental learning with pre-trained models: Generalizability and adaptivity are all you need. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5879–5889, 2023
2023
-
[49]
A model or 603 exemplars: Towards memory- efficient class-incremental learning
Da-Wei Zhou, Qi-Wei Wang, Han-Jia Ye, and De-Chuan Zhan. A model or 603 exemplars: Towards memory- efficient class-incremental learning. InInternational Conference on Learning Representations, 2023
2023
-
[50]
Expandable subspace ensemble for pre-trained model-based class-incremental learning
Da-Wei Zhou, Hai-Long Sun, Han-Jia Ye, and De-Chuan Zhan. Expandable subspace ensemble for pre-trained model-based class-incremental learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[51]
Prototype augmentation and self- supervision for incremental learning
Fei Zhu, Xu-Yao Zhang, Chuang Wang, Fei Yin, and Cheng-Lin Liu. Prototype augmentation and self- supervision for incremental learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5871–5880, 2021
2021
-
[52]
Self-sustaining representation expansion for non-exemplar class-incremental learning
Kai Zhu, Wei Zhai, Yang Cao, Jiebo Luo, and Zheng-Jun Zha. Self-sustaining representation expansion for non-exemplar class-incremental learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9296–9305, 2022. 19
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.