Deep Neural Network Symbol Detection for Millimeter Wave Communications
Pith reviewed 2026-05-24 15:45 UTC · model grok-4.3
The pith
A deep neural network detects mmWave symbols nearly as well as the optimal Viterbi method while skipping channel state information acquisition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A sliding bidirectional RNN-based DNN symbol detector for mmWave communications achieves performance comparable to the optimal Viterbi detector with perfect CSI and outperforms the Viterbi detector when CSI estimation errors are present, while remaining robust to varying noise levels and channel conditions such that a single pretrained model applies reliably to different realizations with minimal overhead.
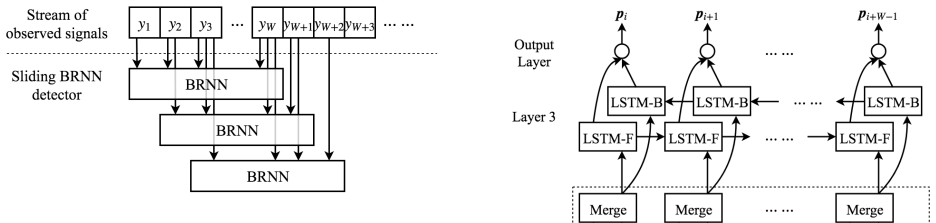
What carries the argument
Sliding bidirectional recurrent neural network (BRNN) architecture suited to the long memory length of mmWave channels.
If this is right
- CSI acquisition can be bypassed in mmWave symbol detection.
- The DNN detector outperforms the Viterbi algorithm under CSI estimation error.
- The detector remains effective across a wide range of noise levels and channel conditions.
- A pretrained detector applies to different mmWave channel realizations with minimal overhead.
Where Pith is reading between the lines
- The approach could reduce pilot overhead and latency in scenarios where channel conditions change faster than traditional estimation allows.
- Similar learned detectors might transfer to other modulation and coding schemes that also suffer from long channel memory.
- End-to-end training that jointly optimizes detection with other receiver blocks becomes feasible once CSI is removed as an explicit input.
- Hardware experiments on actual mmWave testbeds would be needed to confirm whether simulation-trained models retain their reported robustness in practice.
Load-bearing premise
Simulated mmWave channels and noise levels used in training are representative enough of real test conditions that the learned detector generalizes without retraining on each new realization.
What would settle it
A measured drop in detection accuracy when the pretrained DNN is tested on real-world mmWave channel traces whose statistics differ from the simulation distribution used for training.
Figures





read the original abstract
This paper proposes to use a deep neural network (DNN)-based symbol detector for mmWave systems such that CSI acquisition can be bypassed. In particular, we consider a sliding bidirectional recurrent neural network (BRNN) architecture that is suitable for the long memory length of typical mmWave channels. The performance of the DNN detector is evaluated in comparison to that of the Viterbi detector. The results show that the performance of the DNN detector is close to that of the optimal Viterbi detector with perfect CSI, and that it outperforms the Viterbi algorithm with CSI estimation error. Further experiments show that the DNN detector is robust to a wide range of noise levels and varying channel conditions, and that a pretrained detector can be reliably applied to different mmWave channel realizations with minimal overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a sliding bidirectional recurrent neural network (BRNN) architecture as a DNN-based symbol detector for mmWave communications that bypasses explicit CSI acquisition. It evaluates this detector against the Viterbi algorithm, claiming performance close to the optimal Viterbi detector with perfect CSI and superior to Viterbi with CSI estimation error. Additional results indicate robustness across noise levels and channel conditions, with a pretrained model generalizing to new mmWave realizations at minimal overhead.
Significance. If the empirical claims hold under rigorous validation, the work would demonstrate a practical data-driven alternative to CSI-dependent detection in mmWave systems, where beamforming and high path loss make accurate CSI costly. The direct comparison to the Viterbi benchmark and the emphasis on pretrained generalization are concrete strengths that could influence detector design in high-mobility or low-overhead scenarios.
major comments (3)
- [Experimental results / §IV] Experimental evaluation (likely §IV or §V): the abstract and results claim that a single pretrained BRNN generalizes across different mmWave channel realizations with performance near perfect-CSI Viterbi, but no description is given of how training and test channel statistics (path gains, angles, delays, number of clusters, or Rician factors) are generated or whether hold-out parameter ranges were used. This assumption is load-bearing for the 'minimal overhead' conclusion.
- [§III / §IV] Training and dataset details (likely §III or §IV): the performance comparisons lack any specification of the training procedure, loss function, hyperparameter selection, number of realizations, or statistical significance testing of the reported gains over Viterbi with CSI error. Without these, the robustness claims cannot be assessed.
- [§IV] Channel model and noise robustness (likely §IV): the claim of robustness to 'a wide range of noise levels and varying channel conditions' is presented without quantitative details on the tested SNR range, channel parameter sweeps, or whether the same underlying model was used for both training and testing, undermining the generalization argument.
minor comments (2)
- [§II] Notation for the sliding BRNN window size and memory length should be defined explicitly with reference to the mmWave channel memory.
- [Figures in §IV] Figure captions for performance curves should include the exact simulation parameters (e.g., number of antennas, modulation order) rather than referring only to 'typical mmWave channels'.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight areas where additional experimental details will strengthen the manuscript. We have prepared revisions to address each point by expanding the relevant sections with the requested descriptions of the channel model, training procedure, and quantitative robustness results. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Experimental results / §IV] Experimental evaluation (likely §IV or §V): the abstract and results claim that a single pretrained BRNN generalizes across different mmWave channel realizations with performance near perfect-CSI Viterbi, but no description is given of how training and test channel statistics (path gains, angles, delays, number of clusters, or Rician factors) are generated or whether hold-out parameter ranges were used. This assumption is load-bearing for the 'minimal overhead' conclusion.
Authors: We agree that the channel generation process requires explicit description to support the generalization and minimal-overhead claims. In the revised manuscript we will add a dedicated subsection (in §IV) that fully specifies the mmWave channel model, including the distributions and ranges used for path gains, angles, delays, number of clusters, and Rician factors. We will also state that test realizations are generated from hold-out parameter ranges disjoint from those used in training, thereby justifying the claim that a single pretrained detector can be applied to new realizations with minimal overhead. revision: yes
-
Referee: [§III / §IV] Training and dataset details (likely §III or §IV): the performance comparisons lack any specification of the training procedure, loss function, hyperparameter selection, number of realizations, or statistical significance testing of the reported gains over Viterbi with CSI error. Without these, the robustness claims cannot be assessed.
Authors: We acknowledge that these implementation details were omitted. The revised manuscript will expand §III to describe the complete training procedure (optimizer, learning-rate schedule, batch size, and number of epochs), the loss function, the hyperparameter selection method (including any validation-based tuning), the total number of independent channel realizations used for training and testing, and statistical significance measures (standard deviation across runs or hypothesis testing) for the reported performance gains relative to the CSI-error Viterbi baseline. revision: yes
-
Referee: [§IV] Channel model and noise robustness (likely §IV): the claim of robustness to 'a wide range of noise levels and varying channel conditions' is presented without quantitative details on the tested SNR range, channel parameter sweeps, or whether the same underlying model was used for both training and testing, undermining the generalization argument.
Authors: We concur that quantitative bounds are needed. Section IV will be augmented with the exact SNR range evaluated, the specific channel-parameter sweeps performed (e.g., number of clusters, Rician factors), and an explicit statement that training and testing employ independent realizations drawn from the same underlying statistical model. These additions will directly substantiate the robustness claims across noise levels and channel conditions. revision: yes
Circularity Check
No circularity: empirical performance comparison of BRNN detector to Viterbi is not a derivation reducing to inputs
full rationale
The paper's central claims consist of simulation-based performance comparisons (DNN detector close to perfect-CSI Viterbi, outperforms imperfect-CSI Viterbi, robust across noise and channels, pretrained model applies to new realizations). These are direct empirical measurements on held-out test data generated from the same mmWave channel model, not a mathematical derivation, fitted parameter renamed as prediction, or self-citation chain that forces the result. No equations define a quantity in terms of itself, no 'prediction' is statistically forced by construction from a fit, and no uniqueness theorem or ansatz is smuggled via self-citation. The distributional match between train and test is an explicit modeling assumption whose validity can be checked externally; it does not create circularity in the reported results.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The performance of the DNN detector is close to that of the optimal Viterbi detector with perfect CSI... a pretrained detector can be reliably applied to different mmWave channel realizations with minimal overhead.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Millimeter Wave mobile communications for 5G cellular: it will work!
T. Rappaport, S. Sun, R. Mayzus, H. Zhao, Y . Azar, K. Wang, G. Wong, J. Schulz, M. Samimi, and F. Gutierrez. “Millimeter Wave mobile communications for 5G cellular: it will work!”. IEEE Access , vol. 1, pp. 335–349, May 2013
work page 2013
-
[2]
Millimeter wave channel modeling and cellular capacity evaluation
M. Akdeniz, Y . Liu, S. Sun, S. Rangan, T. Rappaport, and E. Erkip. “Millimeter wave channel modeling and cellular capacity evaluation”. IEEE J. Sel. Areas in Commun. , vol. 32, no. 6, pp. 1164–1179, Jun. 2014
work page 2014
-
[3]
An introduction to deep learning for the physical layer
T. O’Shea and J. Hoydis. “An introduction to deep learning for the physical layer”. IEEE Trans. on Cogn. Commun. Netw. , vol. 3, no. 4, Dec. 2017, pp. 563–575
work page 2017
-
[4]
Deep learning for intelligent wireless networks: A comprehensive survey
Q. Mao, F. Hu and Q. Hao. “Deep learning for intelligent wireless networks: A comprehensive survey”. IEEE Commun. Surveys Tuts. , vol. 20, no. 4, 2018, pp. 2595–2621
work page 2018
-
[5]
A very brief introduction to machine learning with appli- cations to communication systems
O. Simeone. “A very brief introduction to machine learning with appli- cations to communication systems”. IEEE Trans. on Cogn. Commun. Netw., vol. 4, no. 4, Dec. 2018, pp. 648–664
work page 2018
-
[6]
Learning to decode linear codes using deep learning
E. Nachmani, Y . Beery, and D. Burshtein. “Learning to decode linear codes using deep learning”. in 54th Annual Allerton Conference on Communication, Control, and Computing, Sep. 2016, pp. 341-346
work page 2016
-
[7]
Learning to communicate: Channel auto-encoders, domain specific regularizers, and attention
T. O’Shea, K. Karra, and T. C. Clancy. “Learning to communicate: Channel auto-encoders, domain specific regularizers, and attention”. in 2016 IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), Dec 2016, pp. 223-228
work page 2016
-
[8]
ViterbiNet: Symbol detection using a deep learning based Viterbi algorithm
N. Shlezinger, N. Farsad, Y . C. Eldar, and A. J. Goldsmith. “ViterbiNet: Symbol detection using a deep learning based Viterbi algorithm”. Submitted to SPA WC, Cannes, France, Jul. 2019
work page 2019
-
[9]
Neural network detection of data sequences in communication systems
N. Farsad and A. Goldsmith. “Neural network detection of data sequences in communication systems”. IEEE Trans. Signal Process. , vol. 66, no. 21, Nov. 2018, pp. 5663–5678
work page 2018
-
[10]
Predicting wireless mmWave massive MIMO channel characteristics using machine learning algo- rithms
H. He , C-K. Wen , S. Jin , and G. Li. “Predicting wireless mmWave massive MIMO channel characteristics using machine learning algo- rithms”. IEEE Wireless Commum. Letters , vol. 7, no. 5, Oct. 2018, pp. 852–855
work page 2018
-
[11]
Deep-Learning-based Millimeter-Wave Massive MIMO for Hybrid Precoding
H. Huang, Y . Song, J. Yang, G. Gui, and F. Adachi. “Deep-learning- based millimeter-Wave massive MIMO for hybrid precoding”. arXiv preprint, arXiv: 1901.06537, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[12]
Deep learning-based beam management and interference coordination in dense mmWave networks
P. Zhou, X. Fang, X. Wang, Y . Long, R. He, and X. Han. “Deep learning-based beam management and interference coordination in dense mmWave networks”. IEEE Trans. on V ehicular Tech. , vol. 68, no. 1, Jan. 2019, pp. 592-603
work page 2019
-
[13]
Noncooperative cellular wireless with unlimited numbers of base station antenna
T. L. Marzetta. “Noncooperative cellular wireless with unlimited numbers of base station antenna”. IEEE Trans. Wireless Commun. , vol. 9, no. 11, Nov. 2010, pp. 3950–3600
work page 2010
-
[14]
S. Verdu. Multiuser Detection . Cambridge Press, 1998
work page 1998
-
[15]
3-D millimeter-wave statistical channel model for 5G wireless system design
M. Samimi, and T. Rappaport. “3-D millimeter-wave statistical channel model for 5G wireless system design”. IEEE Trans. Microwave Theory and Techniques, vol. 64, no. 7, Jul. 2016, pp. 2207–2225
work page 2016
-
[16]
Study on channel model for frequencies from 0.5 to 100 GHz simulations, 2018
3GPP TR 38.901. Study on channel model for frequencies from 0.5 to 100 GHz simulations, 2018
work page 2018
-
[17]
Efficient Viterbi beam search algorithm using dynamic pruning
X. Lingyun and D. Limin. “Efficient Viterbi beam search algorithm using dynamic pruning”. Proc. ICSP, Beijing, China, Aug. 2004
work page 2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.