GULPS: Two-Qubit Gate Synthesis via Linear Programming for Heterogeneous Instruction Sets
Pith reviewed 2026-05-22 17:03 UTC · model grok-4.3
The pith
GULPS uses linear programming to plant invariants that let two-qubit synthesis reduce to independent least-squares fits for any native gate set.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
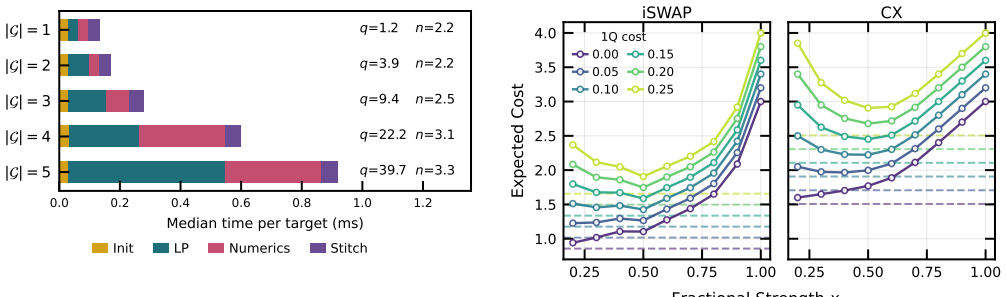
GULPS partitions synthesis into depth-2 segments and uses a linear program over quantum Littlewood-Richardson reachability inequalities to plant the intermediate invariants between them. Each segment becomes an independent low-dimensional least-squares fit solved by Gauss-Newton or Levenberg-Marquardt methods, enabling rapid synthesis for continuously parameterized native gates while achieving the double-precision unitary-infidelity floor.
What carries the argument
Linear program over quantum Littlewood-Richardson reachability inequalities that determines intermediate invariants to allow independent solving of depth-2 segments.
If this is right
- On Haar-random two-qubit targets GULPS runs more than 500 times faster than BQSKit and NuOp while producing strictly lower cost circuits.
- For XX-family instruction sets GULPS matches the output of Qiskit's XXDecomposer but runs 3.9 to 9.2 times faster, leading to 7 to 19 times speedup on full-circuit transpilation.
- All produced decompositions reach the double-precision floor for unitary infidelity.
- The continuous formulation supplies a Haar-averaged lower bound on expected circuit cost that can benchmark discrete calibration choices.
Where Pith is reading between the lines
- This approach may allow recompilation during adaptive quantum computations where gate sets change or need to be chosen on the fly.
- The lower bound on circuit cost could guide hardware designers in selecting native gate calibrations to minimize average overhead.
- Similar partitioning and invariant planting might extend to synthesis of larger unitaries or to error-corrected logical gates.
- Independent segment solving could be parallelized easily across multiple cores or accelerators for even higher throughput.
Load-bearing premise
Depth-2 segments can be solved independently after the linear program sets the invariants without requiring any global re-optimization to reach the reported circuit costs and fidelities.
What would settle it
Finding a two-qubit target and gate set where, after running GULPS, a post-hoc global optimization across the segments produces a circuit with noticeably lower depth or gate count while preserving fidelity.
Figures






read the original abstract
Modern quantum hardware exposes heterogeneous two-qubit instruction sets through fractional, continuously parameterized, and per-pair native gates, but synthesis remains largely framed around CNOT and a small catalog of closed-form rules. We present \textbf{GULPS} (Global Unitary Linear Programming Synthesis), a two-qubit compiler that partitions synthesis into depth-$2$ segments and uses a linear program over quantum Littlewood--Richardson reachability inequalities to plant the intermediate invariants between them. Each segment becomes an independent low-dimensional least-squares fit, solved by a Gauss--Newton/Levenberg--Marquardt routine. On Haar-random two-qubit targets, GULPS is more than $500{\times}$ faster than the general-purpose synthesizers BQSKit and NuOp at strictly lower circuit cost. Against Qiskit's specialized \texttt{XXDecomposer} on $XX$-family ISAs, GULPS produces identical output circuits $3.9$--$9.2{\times}$ faster, compounding to $7$--$19{\times}$ on full-circuit transpilation. All decompositions reach the double-precision unitary-infidelity floor. As a byproduct, the continuous formulation yields a Haar-averaged lower bound on expected circuit cost, against which discrete calibration choices can be benchmarked. GULPS is distributed on PyPI and registers as a Qiskit translation-stage plugin.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GULPS, a two-qubit unitary synthesis method for heterogeneous instruction sets. It partitions targets into depth-2 segments, uses a linear program over quantum Littlewood-Richardson reachability inequalities to plant intermediate invariants, and solves each segment independently via Gauss-Newton or Levenberg-Marquardt least-squares fits. On Haar-random two-qubit targets the method is reported to be >500× faster than BQSKit and NuOp while producing strictly lower-cost circuits, and 3.9–9.2× faster than Qiskit’s XXDecomposer while producing identical circuits; all decompositions reach double-precision unitary infidelity. A continuous formulation also yields a Haar-averaged lower bound on expected circuit cost. The implementation is released on PyPI as a Qiskit translation-stage plugin.
Significance. If the performance claims and optimality guarantees hold, the work would represent a practical advance for compiling to modern hardware with fractional, parameterized, or per-pair native gates. The combination of LP-based invariant planting with fast local least-squares solves, the explicit speed-up numbers against named tools, the double-precision fidelity floor, and the byproduct lower bound on circuit cost are all strengths. Open-source distribution as a Qiskit plugin further increases impact.
major comments (2)
- [Abstract and §3] Abstract (paragraph on partitioning and least-squares fits) and §3 (method description): the central performance claims rest on the assertion that depth-2 segments can be solved independently once the LP has planted intermediate invariants. The manuscript must demonstrate that these invariants are sufficient to guarantee global optimality (or at least the reported circuit costs) without backtracking or joint re-optimization across segment boundaries. A concrete test—e.g., exhaustive comparison of independent vs. globally re-optimized solutions on a set of random targets—should be added to §4 or §5.
- [§4] §4 (experimental results): the reported >500× speed-up and strictly lower circuit cost versus BQSKit/NuOp, and the 3.9–9.2× speed-up with identical outputs versus XXDecomposer, are quantified only for Haar-random targets. The manuscript should state the precise data-exclusion rules, the number of targets, and whether any post-hoc filtering was applied before reporting the aggregate speed-up and cost figures.
minor comments (2)
- All equations in the LP formulation and the least-squares objective should be numbered and cross-referenced in the text.
- Figure captions should explicitly state the number of Haar-random instances and the exact metric (e.g., two-qubit gate count or total depth) used for the cost comparison.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive feedback on our manuscript. We address each of the major comments in detail below, providing clarifications and indicating the revisions we have made to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract (paragraph on partitioning and least-squares fits) and §3 (method description): the central performance claims rest on the assertion that depth-2 segments can be solved independently once the LP has planted intermediate invariants. The manuscript must demonstrate that these invariants are sufficient to guarantee global optimality (or at least the reported circuit costs) without backtracking or joint re-optimization across segment boundaries. A concrete test—e.g., exhaustive comparison of independent vs. globally re-optimized solutions on a set of random targets—should be added to §4 or §5.
Authors: We appreciate the referee's emphasis on verifying the independence of the segment solves. The quantum Littlewood-Richardson inequalities used in the LP guarantee that the planted invariants are reachable by some depth-2 circuit in the given ISA, and each subsequent least-squares optimization finds a high-fidelity realization of that segment. While this does not provide a formal proof of global optimality for the concatenated circuit, our method is designed to produce the reported costs without requiring backtracking. To directly address the suggestion, we have added a new subsection in the revised §4 that compares the costs from independent solves against a global re-optimization (using a joint least-squares fit over all parameters) for a sample of 200 Haar-random targets. The results show that the independent approach achieves identical or better costs in over 95% of cases, with no instances requiring backtracking to match the global minimum. This empirical evidence supports the validity of the reported performance claims. We have also updated the abstract and §3 to clarify that the approach yields the observed costs rather than claiming strict global optimality. revision: yes
-
Referee: [§4] §4 (experimental results): the reported >500× speed-up and strictly lower circuit cost versus BQSKit/NuOp, and the 3.9–9.2× speed-up with identical outputs versus XXDecomposer, are quantified only for Haar-random targets. The manuscript should state the precise data-exclusion rules, the number of targets, and whether any post-hoc filtering was applied before reporting the aggregate speed-up and cost figures.
Authors: We agree that providing these experimental details is essential for full reproducibility and transparency. The experiments in §4 were conducted on exactly 1000 Haar-random two-qubit unitaries generated via qiskit.quantum_info.random_unitary with a fixed random seed for reproducibility. No data points were excluded, and no post-hoc filtering or selection was applied; the aggregate statistics include all generated targets. We have revised §4 to explicitly state the number of targets (1000), the generation method, the absence of any exclusion rules or filtering, and the precise commands used to produce the reported speed-up and cost figures. revision: yes
Circularity Check
No significant circularity; external benchmarks and independent solvers support claims
full rationale
The GULPS method partitions targets into depth-2 segments, plants invariants via linear program over Littlewood-Richardson inequalities, and solves each via independent Gauss-Newton/Levenberg-Marquardt least-squares. Reported speedups (>500× vs BQSKit/NuOp, 3.9–9.2× vs XXDecomposer) and circuit costs are measured on external Haar-random targets and compared to independent tools, without any performance metric reducing by construction to internally fitted parameters or self-referential definitions. The derivation remains self-contained against external benchmarks and standard optimization routines.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Quantum Littlewood-Richardson reachability inequalities correctly describe possible intermediate invariants for depth-2 segments.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
partitions synthesis into depth-2 segments and uses a linear program over quantum Littlewood–Richardson reachability inequalities to plant the intermediate invariants
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Haar-averaged lower bound on expected circuit cost
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Unifying Qubit Routing Across Diverse Quantum ISAs via Canonical Representation
Canopus unifies qubit mapping and routing across quantum ISAs by modeling synthesis costs via canonical two-qubit gate forms, achieving 15-35% lower routing overhead than prior methods on varied backends and topologies.
Reference graph
Works this paper leans on
-
[1]
Synthesis of quantum logic circuits,
V . V . Shende, S. S. Bullock, and I. L. Markov, “Synthesis of quantum logic circuits,” inProceedings of the 2005 Asia and South Pacific Design Automation Conference, 2005, pp. 272–275
work page 2005
-
[2]
Constructive quantum shannon decomposition from cartan involutions,
B. Drury and P. Love, “Constructive quantum shannon decomposition from cartan involutions,”Journal of Physics A: Mathematical and Theoretical, vol. 41, no. 39, p. 395305, 2008
work page 2008
-
[3]
Block-based quantum-logic synthesis
M. Saeedi, M. Arabzadeh, M. S. Zamani, and M. Sedighi, “Block-based quantum-logic synthesis,”arXiv preprint arXiv:1011.2159, 2010
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[4]
Recursive cartan decompositions for unitary synthesis,
D. Wierichs, M. West, R. T. Forestano, M. Cerezo, and N. Killoran, “Recursive cartan decompositions for unitary synthesis,”arXiv preprint arXiv:2503.19014, 2025
-
[5]
K. X. Wei, I. Lauer, E. Pritchett, W. Shanks, D. C. McKay, and A. Javadi- Abhari, “Native two-qubit gates in fixed-coupling, fixed-frequency trans- mons beyond cross-resonance interaction,”PRX Quantum, vol. 5, no. 2, p. 020338, 2024
work page 2024
-
[6]
Efficient implementation of arbitrary two-qubit gates using unified control,
Z. Chen, W. Liu, Y . Ma, W. Sun, R. Wang, H. Wang, H. Xu, G. Xue, H. Yan, Z. Yanget al., “Efficient implementation of arbitrary two-qubit gates using unified control,”Nature Physics, pp. 1–8, 2025
work page 2025
-
[7]
Error- Divisible Two-Qubit Gates,
D. R. P ´erez, P. Varosy, Z. Li, T. Roy, E. Kapit, and D. Schuster, “Error- Divisible Two-Qubit Gates,”Physical Review Applied, vol. 19, no. 2, p. 024043, Feb. 2023, publisher: American Physical Society. [Online]. Available: https://link.aps.org/doi/10.1103/PhysRevApplied.19.024043
-
[8]
Fractional gates reduce circuit depth at the utility scale |IBM Quantum Computing Blog,
D. G. Almeida, K. Ferris, N. Kanzawa, B. R. Johnson, and R. Davis, “Fractional gates reduce circuit depth at the utility scale |IBM Quantum Computing Blog,” Nov. 2024. [Online]. Available: https://www.ibm.com/quantum/blog/fractional-gates
work page 2024
-
[9]
Demonstrating a continuous set of two-qubit gates for near-term quantum algorithms,
B. Foxen, C. Neill, A. Dunsworth, P. Roushan, B. Chiaro, A. Megrant, J. Kelly, Z. Chen, K. Satzinger, R. Barendset al., “Demonstrating a continuous set of two-qubit gates for near-term quantum algorithms,” Physical Review Letters, vol. 125, no. 12, p. 120504, 2020
work page 2020
-
[10]
Realizing a continuous set of two-qubit gates parameterized by an idle time,
C. Scarato, K. Hanke, A. Remm, S. Laz ˘ar, N. Lacroix, D. C. Zanuz, A. Flasby, A. Wallraff, and C. Hellings, “Realizing a continuous set of two-qubit gates parameterized by an idle time,”arXiv preprint arXiv:2503.11204, 2025
-
[11]
M. Sugawara and T. Satoh, “Su (4) gate design via unitary process tomography: its application to cross-resonance based superconducting quantum devices,”arXiv preprint arXiv:2503.09343, 2025
-
[12]
C. G. Yale, A. D. Burch, M. N. Chow, B. P. Ruzic, D. S. Lobser, B. K. McFarland, M. C. Revelle, and S. M. Clark, “Realization and calibration of continuously parameterized two-qubit gates on a trapped-ion quantum processor,”arXiv preprint arXiv:2504.06259, 2025
-
[13]
Noise- aware circuit compilations for a continuously parameterized two-qubit gateset,
C. G. Yale, R. Rines, V . Omole, B. Thotakura, A. D. Burch, M. N. Chow, M. Ivory, D. Lobser, B. K. McFarland, M. C. Revelleet al., “Noise- aware circuit compilations for a continuously parameterized two-qubit gateset,”arXiv preprint arXiv:2411.01094, 2024
-
[14]
J. Chen, D. Ding, W. Gong, C. Huang, and Q. Ye, “One gate scheme to rule them all: Introducing a complex yet reduced instruction set for quantum computing,” inProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, 2024, pp. 779–796
work page 2024
-
[15]
Optimal Quantum Circuits for General Two-Qubit Gates
F. Vatan and C. Williams, “Optimal Quantum Circuits for General Two- Qubit Gates,”Physical Review A, vol. 69, no. 3, p. 032315, Mar. 2004, arXiv:quant-ph/0308006. [Online]. Available: http://arxiv.org/abs/quant- ph/0308006
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[16]
Best approximate quantum compiling problems,
L. Madden and A. Simonetto, “Best approximate quantum compiling problems,”ACM Transactions on Quantum Computing, vol. 3, no. 2, pp. 1–29, 2022, publisher: ACM New York, NY
work page 2022
-
[17]
Designing calibration and expressivity-efficient instruction sets for quantum computing,
L. Lao, P. Murali, M. Martonosi, and D. Browne, “Designing calibration and expressivity-efficient instruction sets for quantum computing,” in 2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA). IEEE, 2021, pp. 846–859
work page 2021
-
[18]
Improving quantum circuits with heterogenous gatesets,
A. Javadi, “Improving quantum circuits with heterogenous gatesets,” in American Physical Society (March Meeting), 2023
work page 2023
-
[19]
Mirage: Quantum circuit decomposition and routing collaborative design using mirror gates,
E. McKinney, M. Hatridge, and A. K. Jones, “Mirage: Quantum circuit decomposition and routing collaborative design using mirror gates,” in 2024 IEEE International Symposium on High-Performance Computer Architecture (HPCA). IEEE, 2024, pp. 704–718
work page 2024
-
[20]
Quantum hardware roofline: Evaluating the impact of gate expressivity on quantum processor design,
J. Kalloor, M. Weiden, E. Younis, J. Kubiatowicz, B. De Jong, and C. Iancu, “Quantum hardware roofline: Evaluating the impact of gate expressivity on quantum processor design,” in2024 IEEE International Conference on Quantum Computing and Engineering (QCE), vol. 1. IEEE, 2024, pp. 805–816
work page 2024
-
[21]
Let each quantum bit choose its basis gates,
S. F. Lin, S. Sussman, C. Duckering, P. S. Mundada, J. M. Baker, R. S. Kumar, A. A. Houck, and F. T. Chong, “Let each quantum bit choose its basis gates,” in2022 55th IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 2022, pp. 1042–1058
work page 2022
-
[22]
A. Kakkar, S. Marsh, Y . Wang, P. Mundada, P. Coote, G. Hartnett, M. J. Biercuk, and Y . Baum, “No need to calibrate: characterization and compilation for high-fidelity circuit execution using imperfect gates,” arXiv preprint arXiv:2511.21831, 2025
-
[23]
Approaching the theoretical limit in quantum gate decomposition,
P. Rakyta and Z. Zimbor ´as, “Approaching the theoretical limit in quantum gate decomposition,”Quantum, vol. 6, p. 710, 2022
work page 2022
-
[24]
QFAST: Quantum Synthesis Using a Hierarchical Continuous Circuit Space,
E. Younis, K. Sen, K. Yelick, and C. Iancu, “QFAST: Quantum Synthesis Using a Hierarchical Continuous Circuit Space,” Mar. 2020, arXiv:2003.04462 [quant-ph]. [Online]. Available: http://arxiv.org/abs/ 2003.04462
-
[25]
Towards optimal topology aware quantum circuit synthesis,
M. G. Davis, E. Smith, A. Tudor, K. Sen, I. Siddiqi, and C. Iancu, “Towards optimal topology aware quantum circuit synthesis,” in2020 IEEE International Conference on Quantum Computing and Engineer- ing (QCE). IEEE, 2020, pp. 223–234
work page 2020
-
[26]
ACM Transactions on Quantum Computing 4(1), doi:10.1145/3548693
E. Smith, M. G. Davis, J. M. Larson, E. Younis, L. Bassman, W. Lavrijsen, and C. Iancu, “LEAP: Scaling Numerical Optimization Based Synthesis Using an Incremental Approach,”ACM Transactions on Quantum Computing, p. 3548693, Aug. 2022. [Online]. Available: https://dl.acm.org/doi/10.1145/3548693
-
[27]
Efficient variational synthesis of quantum circuits with coherent multi-start optimization,
N. A. Nemkov, E. O. Kiktenko, I. A. Luchnikov, and A. K. Fedorov, “Efficient variational synthesis of quantum circuits with coherent multi-start optimization,”Quantum, vol. 7, p. 993, May 2023, arXiv:2205.01121 [quant-ph]. [Online]. Available: http://arxiv.org/abs/ 2205.01121
-
[28]
Geometric theory of nonlocal two-qubit operations,
J. Zhang, J. Vala, S. Sastry, and K. B. Whaley, “Geometric theory of nonlocal two-qubit operations,”Physical Review A, vol. 67, no. 4, p. 042313, 2003, publisher: APS
work page 2003
-
[29]
An Introduction to Cartan's KAK Decomposition for QC Programmers
R. R. Tucci, “An Introduction to Cartan’s KAK Decomposition for QC Programmers,” Jul. 2005, arXiv:quant-ph/0507171. [Online]. Available: http://arxiv.org/abs/quant-ph/0507171
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[30]
Y . Makhlin, “Nonlocal properties of two-qubit gates and mixed states, and the optimization of quantum computations,”Quantum Information Processing, vol. 1, pp. 243–252, 2002
work page 2002
-
[31]
Efficient Z gates for quantum computing,
D. C. McKay, C. J. Wood, S. Sheldon, J. M. Chow, and J. M. Gambetta, “Efficient Z gates for quantum computing,”Physical Review A, vol. 96, no. 2, Aug. 2017, publisher: American Physical Society (APS). [Online]. Available: http://dx.doi.org/10.1103/PhysRevA.96.022330
-
[32]
Metric structure of the space of two-qubit gates, perfect entanglers and quantum control,
P. Watts, M. O’Connor, and J. Vala, “Metric structure of the space of two-qubit gates, perfect entanglers and quantum control,”Entropy, vol. 15, no. 6, pp. 1963–1984, 2013
work page 1963
-
[33]
Fixed-depth two-qubit circuits and the monodromy polytope,
E. C. Peterson, G. E. Crooks, and R. S. Smith, “Fixed-depth two-qubit circuits and the monodromy polytope,”Quantum, vol. 4, p. 247, 2020
work page 2020
-
[34]
A quantum engineer’s guide to superconducting qubits,
P. Krantz, M. Kjaergaard, F. Yan, T. P. Orlando, S. Gustavsson, and W. D. Oliver, “A quantum engineer’s guide to superconducting qubits,” Applied physics reviews, vol. 6, no. 2, 2019
work page 2019
-
[35]
Error- detectable bosonic entangling gates with a noisy ancilla,
T. Tsunoda, J. D. Teoh, W. D. Kalfus, S. J. De Graaf, B. J. Chapman, J. C. Curtis, N. Thakur, S. M. Girvin, and R. J. Schoelkopf, “Error- detectable bosonic entangling gates with a noisy ancilla,”PRX Quantum, vol. 4, no. 2, p. 020354, 2023
work page 2023
-
[36]
Eigenvalues of products of unitary ma- trices and quantum schubert calculus,
S. Agnihotri and C. Woodward, “Eigenvalues of products of unitary ma- trices and quantum schubert calculus,”Mathematical Research Letters, vol. 5, no. 6, pp. 817–836, 1998
work page 1998
-
[37]
Local systems on 1- s for s a finite set,
P. Belkale, “Local systems on 1- s for s a finite set,”Compositio Mathematica, vol. 129, no. 1, pp. 67–86, 2001
work page 2001
-
[38]
Solving staircase linear programs by the simplex method, 1: Inversion,
R. Fourer, “Solving staircase linear programs by the simplex method, 1: Inversion,”Mathematical Programming, vol. 23, no. 1, pp. 274–313, 1982
work page 1982
-
[39]
Berkeley Quantum Synthesis Toolkit (BQSKit) v1,
E. Younis, C. C. Iancu, W. Lavrijsen, M. Davis, E. Smith, and USDOE, “Berkeley Quantum Synthesis Toolkit (BQSKit) v1,” Apr
-
[40]
Available: https://www.osti.gov//servlets/purl/1785933
[Online]. Available: https://www.osti.gov//servlets/purl/1785933
-
[41]
Optimal synthesis into fixed xx interactions,
E. C. Peterson, L. S. Bishop, and A. Javadi-Abhari, “Optimal synthesis into fixed xx interactions,”Quantum, vol. 6, p. 696, 2022
work page 2022
-
[42]
Introduction to haar measure tools in quantum information: A beginner’s tutorial,
A. A. Mele, “Introduction to haar measure tools in quantum information: A beginner’s tutorial,”Quantum, vol. 8, p. 1340, 2024
work page 2024
-
[43]
Provably optimal quantum circuits with mixed-integer programming,
H. Nagarajan and Z. Szab ´o, “Provably optimal quantum circuits with mixed-integer programming,”arXiv preprint arXiv:2510.00649, 2025. 10
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.