Physics Priors Offer Useful Accuracy-Carbon Trade-Offs in Spatio-Temporal Forecasting
Pith reviewed 2026-05-22 12:57 UTC · model grok-4.3
The pith
Models with stronger physics priors achieve substantially lower training carbon footprints for spatio-temporal forecasting but the advantage does not extend straightforwardly to inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Models with stronger physics priors achieve substantially lower training footprints, but this advantage does not straightforwardly extend to inference, highlighting the importance of evaluating carbon costs across the full model lifecycle rather than any single stage.
What carries the argument
Physics inductive biases of varying strength inserted into neural networks for predicting flows governed by the Navier-Stokes equations.
If this is right
- Carbon costs must be measured across training and inference rather than at one stage alone.
- Model efficiency should stand as a core design goal alongside accuracy in machine learning development.
- Physics priors can deliver useful accuracy-carbon trade-offs on tasks whose governing equations are known.
Where Pith is reading between the lines
- The same prior-strength approach could be tested on larger or higher-dimensional flow datasets to check whether training savings scale.
- When training compute is the dominant cost, practitioners might prefer strong-physics models even if inference costs remain comparable.
- Quantifying carbon across data preparation and deployment stages would complete the lifecycle picture the paper begins.
Load-bearing premise
The incompressible shear flow task is representative enough of other spatio-temporal forecasting problems that the measured accuracy-carbon trade-offs will hold when the same physics-prior approach is applied elsewhere.
What would settle it
Running the identical comparison on a different governed forecasting problem such as weather or ocean currents and finding no training-footprint reduction for the strong-prior models would falsify the central trade-off claim.
Figures






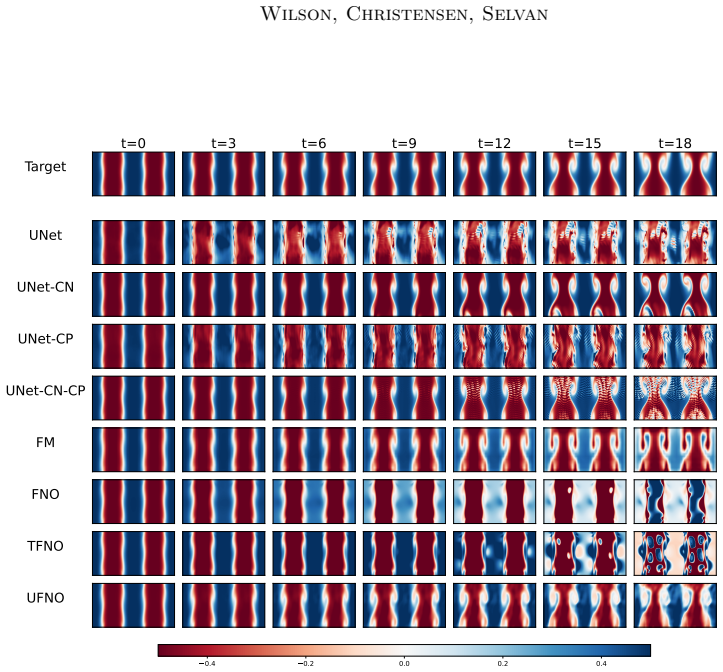






read the original abstract
Development of modern deep learning methods has been driven primarily by the push for improving model efficacy (accuracy metrics). This sole focus on efficacy has steered development of large-scale models that require massive computational resources, and results in considerable energy consumption and corresponding carbon footprint across the model lifecycle. In this work, we explore how physics inductive biases can offer useful trade-offs between model efficacy and model efficiency (compute, energy, and carbon). We study models with strong, weak, and no physics-inductive biases for spatio-temporal forecasting of incompressible shear flow, a task governed by the Navier-Stokes equations. We find that models with stronger physics priors achieve substantially lower training footprints, but this advantage does not straightforwardly extend to inference, highlighting the importance of evaluating carbon costs across the full model lifecycle rather than any single stage. We argue that model efficiency, along with model efficacy, should become a core consideration driving machine learning model development and deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines accuracy-carbon trade-offs in spatio-temporal forecasting by comparing deep learning models with strong, weak, and no physics inductive biases on the task of predicting incompressible shear flow governed by the Navier-Stokes equations. It reports that stronger physics priors yield substantially lower training carbon footprints, though this advantage does not extend straightforwardly to inference, and concludes that model efficiency should be considered alongside efficacy in ML development.
Significance. If the empirical findings hold under broader testing, the work would usefully highlight lifecycle carbon costs in scientific ML and demonstrate that physics priors can reduce training footprints without sacrificing accuracy on this flow problem. The emphasis on evaluating both training and inference stages is a constructive contribution to green AI discussions, though the single-task scope limits immediate generalizability.
major comments (2)
- [Experimental setup and results] The central claim that stronger physics priors achieve substantially lower training footprints (and the associated accuracy-carbon trade-off) rests entirely on results from the incompressible shear flow task. No other spatio-temporal forecasting problems, governing equations, or datasets are evaluated, so it is unclear whether the reported training-footprint reductions are an artifact of this specific flow regime, boundary conditions, or data statistics rather than a general property of physics priors.
- [Abstract and §4 (Results)] The abstract and main claims state directional findings on training footprints without supplying quantitative values, error bars, baseline model details, dataset sizes, or hardware specifications. This absence makes it impossible to judge the magnitude of the carbon savings or to reproduce the comparison between strong/weak/no physics-prior variants.
minor comments (2)
- [Figures] Figure captions and axis labels should explicitly state the units and normalization used for carbon footprint (e.g., kg CO2e) and whether values are per epoch, per run, or total.
- [Introduction] The manuscript would benefit from a short related-work paragraph contrasting the physics-prior approach with other efficiency techniques such as pruning or quantization that have been applied to spatio-temporal models.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below, clarifying our position and outlining revisions to improve the paper's clarity and scope.
read point-by-point responses
-
Referee: [Experimental setup and results] The central claim that stronger physics priors achieve substantially lower training footprints (and the associated accuracy-carbon trade-off) rests entirely on results from the incompressible shear flow task. No other spatio-temporal forecasting problems, governing equations, or datasets are evaluated, so it is unclear whether the reported training-footprint reductions are an artifact of this specific flow regime, boundary conditions, or data statistics rather than a general property of physics priors.
Authors: We agree that the study is confined to the incompressible shear flow task governed by the Navier-Stokes equations, which was selected as a canonical, well-characterized benchmark to isolate the effects of varying physics inductive biases under controlled conditions. While this focused setting enables rigorous comparison of strong, weak, and no-prior models, we acknowledge that broader validation across additional spatio-temporal problems would be needed to establish generality. In the revised manuscript we will expand the discussion and limitations sections to explicitly address the single-task scope, discuss why this flow regime is representative for studying physics priors, and outline concrete directions for future multi-task evaluations. revision: partial
-
Referee: [Abstract and §4 (Results)] The abstract and main claims state directional findings on training footprints without supplying quantitative values, error bars, baseline model details, dataset sizes, or hardware specifications. This absence makes it impossible to judge the magnitude of the carbon savings or to reproduce the comparison between strong/weak/no physics-prior variants.
Authors: We appreciate this observation and agree that the abstract and results presentation would benefit from greater specificity. In the revised manuscript we will augment the abstract with concise quantitative highlights (e.g., relative training-carbon reductions and associated accuracy metrics) and ensure Section 4 includes error bars, baseline architecture details, dataset sizes, and hardware specifications to support reproducibility and magnitude assessment. revision: yes
Circularity Check
No circularity: empirical comparison of physics-prior models on measured carbon and accuracy
full rationale
The paper conducts an experimental study comparing model variants with strong, weak, and no physics priors on the incompressible shear flow task. Reported accuracy-carbon trade-offs are obtained by direct measurement of training and inference footprints on the chosen dataset; no equations, derivations, or fitted parameters are defined in terms of the target quantities. No self-citation chains, ansatzes, or uniqueness theorems are invoked to justify the central results. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The forecasting task is governed by the Navier-Stokes equations for incompressible shear flow.
Reference graph
Works this paper leans on
-
[1]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[2]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[3]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
- [4]
-
[5]
URL http://dx.doi.org/10.1109/ICASSP48485.2024.10447579
P. Bakhtiarifard, C. Igel, and R. Selvan. Ec-nas: Energy consumption aware tabular benchmarks for neural architecture search. In ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), page 5660–5664. IEEE, Apr. 2024. doi:10.1109/icassp48485.2024.10448303. URL http://dx.doi.org/10.1109/ICASSP48485.2024.10448303
- [6]
-
[7]
B. R. Bartoldson, B. Kailkhura, and D. Blalock. Compute-efficient deep learning: Algorithmic trends and opportunities. Journal of Machine Learning Research, 24 0 (122): 0 1--77, 2023
work page 2023
-
[8]
J. Brehmer, S. Behrends, P. de Haan, and T. Cohen. Does equivariance matter at scale?, 2024. URL https://arxiv.org/abs/2410.23179
-
[9]
K. J. Burns, G. M. Vasil, J. S. Oishi, D. Lecoanet, and B. P. Brown. Dedalus: A flexible framework for numerical simulations with spectral methods. Physical Review Research, 2 0 (2): 0 023068, 2020. doi:10.1103/PhysRevResearch.2.023068
-
[10]
B. Cottier, R. Rahman, L. Fattorini, N. Maslej, T. Besiroglu, and D. Owen. The rising costs of training frontier ai models. arXiv preprint arXiv:2405.21015, 2024
- [11]
- [12]
- [13]
-
[14]
M. Evchenko, J. Vanschoren, H. H. Hoos, M. Schoenauer, and M. Sebag. Frugal machine learning. arXiv preprint arXiv:2111.03731, 2021
-
[15]
P. Henderson, J. Hu, J. Romoff, E. Brunskill, D. Jurafsky, and J. Pineau. Towards the systematic reporting of the energy and carbon footprints of machine learning, 2022. URL https://arxiv.org/abs/2002.05651
-
[16]
IEA . Electricity 2025 . https://www.iea.org/reports/electricity-2025, 2025. Accessed: 2025-09-20
work page 2025
-
[17]
M. Jahani-nasab and M. A. Bijarchi. Enhancing convergence speed with feature enforcing physics-informed neural networks using boundary conditions as prior knowledge. Scientific Reports, 14: 0 23836, 2024. doi:10.1038/s41598-024-74711-y. URL https://doi.org/10.1038/s41598-024-74711-y
- [18]
-
[19]
N. Khoa. Tutorials for physics-informed neural networks (pinns), 2022. URL https://github.com/nguyenkhoa0209/pinns_tutorial. Accessed: 2024-07-12
work page 2022
-
[20]
D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. In ICLR (Poster), 2015. URL http://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2015
- [21]
-
[22]
J. Kossaifi, N. Kovachki, K. Azizzadenesheli, and A. Anandkumar. Multi-grid tensorized fourier neural operator for high-resolution pdes, 2023. URL https://arxiv.org/abs/2310.00120
-
[23]
N. B. Kovachki, Z. Li, K. Azizzadenesheli, K. Bhattacharya, A. M. Stuart, and A. Anandkumar. Neural operator: Learning maps between function spaces. Journal of Machine Learning Research, 24 0 (89): 0 1--97, 2023
work page 2023
-
[24]
R. Lam, A. Sanchez-Gonzalez, M. Willson, P. Wirnsberger, M. Fortunato, F. Alet, S. Ravuri, T. Ewalds, Z. Eaton-Rosen, W. Hu, A. Merose, S. Hoyer, G. Holland, O. Vinyals, J. Stott, A. Pritzel, S. Mohamed, and P. Battaglia. GraphCast : Learning skillful medium-range global weather forecasting, 2023. URL http://arxiv.org/abs/2212.12794
- [25]
- [26]
-
[27]
Flow Matching for Generative Modeling
Y. Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling, 2023. URL https://arxiv.org/abs/2210.02747. Published as a conference paper at ICLR 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
D. C. Liu and J. Nocedal. On the limited memory BFGS method for large scale optimization. Mathematical Programming, 45: 0 503--528, 1989. doi:10.1007/BF01589116
-
[29]
Z. Liu, H. Mao, C.-Y. Wu, C. Feichtenhofer, T. Darrell, and S. Xie. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11976--11986, 2022. doi:10.1109/CVPR52688.2022.01167
-
[30]
I. Loshchilov and F. Hutter. Decoupled weight decay regularization. In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=Bkg6RiCqY7
work page 2019
-
[31]
L. Lu, P. Jin, G. Pang, Z. Zhang, and G. E. Karniadakis. Learning nonlinear operators via deeponet based on the universal approximation theorem of operators. Nature Machine Intelligence, 3 0 (3): 0 218--229, 2021. doi:10.1038/s42256-021-00302-5. URL https://doi.org/10.1038/s42256-021-00302-5
-
[32]
A. S. Luccioni, S. Viguier, and A.-L. Ligozat. Estimating the carbon footprint of bloom, a 176b parameter language model. Journal of machine learning research, 24 0 (253): 0 1--15, 2023
work page 2023
-
[33]
G. Moro, L. Ruggazzi, and L. Valgimigli. Carburacy: Summarization models tuning and comparison in eco-sustainable regimes with a novel carbon-aware accuracy. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 14417--14425, 2023. doi:10.1609/aaai.v37i12.26686
-
[34]
R. Ohana, M. McCabe, L. Meyer, R. Morel, F. J. Agocs, M. Beneitez, M. Berger, B. Burkhart, S. Dalziel, D. Fielding, et al. The well: A large-scale collection of diverse physics simulations for machine learning. Dataset, 2024. URL https://doi.org/10.17863/CAM.113689. Accepted at NeurIPS 2024 Datasets and Benchmarks
-
[35]
S. Patra, S. Panda, B. K. Parida, M. Arya, K. Jacobs, D. I. Bondar, and A. Sen. Physics informed kolmogorov-arnold neural networks for dynamical analysis via efficent-kan and wav-kan, 2024. URL https://arxiv.org/abs/2407.18373
-
[36]
A. F. Psaros, R. Pestourie, P. T. Rakich, S. G. Johnson, P. Dey, P. Das, J. Moucer, et al. Physics-enhanced deep surrogates for partial differential equations. Nature Machine Intelligence, 5: 0 1458--1468, 2023. doi:10.1038/s42256-023-00761-y
-
[37]
M. A. Rahman, Z. E. Ross, and K. Azizzadenesheli. U-no: U-shaped neural operators. Transactions on Machine Learning Research, 2023. URL https://openreview.net/forum?id=rE7Xhez8mE
work page 2023
-
[38]
M. Raissi, P. Perdikaris, and G. Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational Physics, 378: 0 686--707, 2019. ISSN 0021-9991. doi:https://doi.org/10.1016/j.jcp.2018.10.045. URL https://www.sciencedirect.com/scie...
-
[39]
U -Net: Convolutional Networks for Biomedical Image Segmentation,
O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention -- MICCAI 2015, volume 9351 of LNCS, pages 234--241. Springer, 2015. doi:10.1007/978-3-319-24574-4_28
-
[40]
J. Sevilla, L. Heim, A. Ho, T. Besiroglu, M. Hobbhahn, and P. Villalobos. Compute trends across three eras of machine learning. In 2022 International Joint Conference on Neural Networks (IJCNN), page 1–8. IEEE, July 2022. doi:10.1109/ijcnn55064.2022.9891914. URL http://dx.doi.org/10.1109/IJCNN55064.2022.9891914
-
[41]
Energy and Policy Considerations for Deep Learning in NLP
E. Strubell, A. Ganesh, and A. McCallum. Energy and policy considerations for deep learning in NLP . In A. Korhonen, D. Traum, and L. M \`a rquez, editors, Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3645--3650, Florence, Italy, July 2019. Association for Computational Linguistics. doi:10.18653/v1/P19-135...
work page internal anchor Pith review doi:10.18653/v1/p19-1355 2019
- [42]
-
[43]
A. Van Wynsberghe. Sustainable AI : AI for sustainability and the sustainability of AI . 1 0 (3): 0 213--218, 2021. ISSN 2730-5953, 2730-5961. doi:10.1007/s43681-021-00043-6. URL https://link.springer.com/10.1007/s43681-021-00043-6
-
[44]
Y. Zhao, Y. Liu, B. Jiang, and T. Guo. Ce-nas: An end-to-end carbon-efficient neural architecture search framework. Advances in Neural Information Processing Systems, 37: 0 82673--82704, 2024
work page 2024
-
[45]
Y. D. Zhong, B. Dey, and A. Chakraborty. Benchmarking energy-conserving neural networks for learning dynamics from data. In A. Jadbabaie, J. Lygeros, G. J. Pappas, P. A. Parrilo, B. Recht, C. J. Tomlin, and M. N. Zeilinger, editors, Proceedings of the 3rd Conference on Learning for Dynamics and Control, volume 144 of Proceedings of Machine Learning Resear...
work page 2021
- [46]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.