Accelerating Inference for Multilayer Neural Networks with Quantum Computers
Pith reviewed 2026-05-21 20:54 UTC · model grok-4.3
The pith
With quantum access to inputs and weights, multilayer neural networks achieve polylogarithmic inference cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
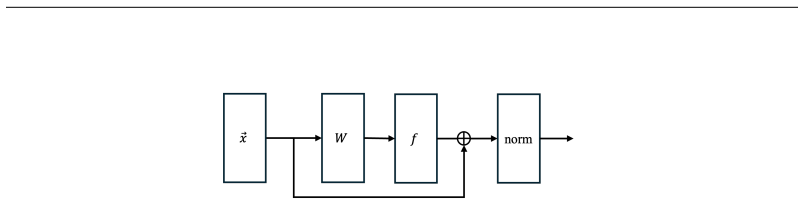
A network with an N-dimensional vectorized input, k residual block layers, and a final residual-linear-pooling layer can be implemented with an error of ε with O(polylog(N/ε)^k) inference cost when efficient quantum access to both the inputs and the network weights is available.
What carries the argument
Coherent quantum circuits for residual blocks that embed multi-filter 2D convolutions, sigmoid activations, skip connections, and layer normalizations, realized via quantum oracles for data and weight access.
Load-bearing premise
Efficient quantum oracles or quantum random access memory must exist that supply coherent, low-overhead access to the input data and all network weights.
What would settle it
A controlled simulation or small-scale quantum run that measures whether the total gate count for a fixed-depth ResNet-style network grows as polylog(N) rather than any polynomial in N when the input dimension N is increased while keeping error below a fixed ε.
Figures


read the original abstract
Fault-tolerant Quantum Processing Units (QPUs) promise to deliver exponential speed-ups in select computational tasks, yet their integration into modern deep learning pipelines remains unclear. In this work, we take a step towards bridging this gap by presenting the first fully-coherent quantum implementation of a multilayer neural network with non-linear activation functions. Our constructions mirror widely used deep learning architectures based on ResNet, and consist of residual blocks with multi-filter 2D convolutions, sigmoid activations, skip-connections, and layer normalizations. We analyse the complexity of inference for networks under three quantum data access regimes. Without any assumptions, we establish a quadratic speedup over classical methods for shallow bilinear-style networks. With efficient quantum access to the weights, we obtain a quartic speedup over classical methods. With efficient quantum access to both the inputs and the network weights, we prove that a network with an $N$-dimensional vectorized input, $k$ residual block layers, and a final residual-linear-pooling layer can be implemented with an error of $\epsilon$ with $O(\text{polylog}(N/\epsilon)^k)$ inference cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the first fully-coherent quantum implementation of multilayer neural networks modeled on ResNet architectures, consisting of residual blocks with multi-filter 2D convolutions, sigmoid activations, skip connections, and layer normalizations. It analyzes inference complexity under three quantum data-access regimes: no assumptions (quadratic speedup for shallow bilinear networks), efficient quantum access to weights only (quartic speedup), and efficient quantum access to both inputs and weights (O(polylog(N/ε)^k) cost for an N-dimensional input, k residual-block layers, and a final residual-linear-pooling layer with error ε).
Significance. If the constructions and complexity bounds hold, the work would constitute a concrete advance in quantum machine learning by showing how non-linear activations and residual connections can be realized coherently, with explicit scaling that improves from quadratic to polylogarithmic under progressively stronger access models. The regime-based analysis is useful for clarifying the oracle requirements needed for quantum advantage in deep-network inference.
major comments (2)
- [§5] §5 (polylog regime): the O(polylog(N/ε)^k) bound is derived under the assumption of efficient coherent quantum oracles/QRAM for both inputs and all network weights, yet the manuscript provides no explicit query-complexity analysis or circuit construction showing how these oracles are realized while preserving superposition and coherence through the k layers, convolutions, sigmoid activations, and layer norms. Any super-logarithmic overhead in oracle implementation would invalidate the claimed scaling.
- [§4 and §5] §4 (quartic regime) and §5: the transition from the no-assumption quadratic regime to the weight-access quartic and then to the joint-access polylog regimes is load-bearing for the central claim, but the paper does not quantify the concrete gate or query overhead of implementing the residual blocks and non-linear functions under each access model, nor does it include an error-propagation analysis across layers.
minor comments (2)
- [Abstract] The abstract states the three regimes and final bound but omits any reference to the specific sections or equations containing the derivations; adding such pointers would improve readability.
- [§2] Notation for the vectorized input dimension N and the number of layers k is introduced without an explicit table or diagram summarizing the network architecture parameters used in the complexity statements.
Simulated Author's Rebuttal
Thank you for your thorough review and for recognizing the potential significance of our work on coherent quantum implementations of multilayer neural networks. We address each of the major comments in detail below and have made revisions to the manuscript to incorporate clarifications and additional analyses as suggested.
read point-by-point responses
-
Referee: [§5] §5 (polylog regime): the O(polylog(N/ε)^k) bound is derived under the assumption of efficient coherent quantum oracles/QRAM for both inputs and all network weights, yet the manuscript provides no explicit query-complexity analysis or circuit construction showing how these oracles are realized while preserving superposition and coherence through the k layers, convolutions, sigmoid activations, and layer norms. Any super-logarithmic overhead in oracle implementation would invalidate the claimed scaling.
Authors: We thank the referee for this observation. Our polylogarithmic bound is stated under the standard assumption of efficient coherent quantum oracles (QRAM-style) for inputs and weights, which by definition support O(polylog N) queries while preserving superposition. The network constructions (convolutions via quantum linear algebra techniques, sigmoid via coherent polynomial approximations, layer norms via quantum mean/variance estimation, and residual additions) are composed to interface directly with these oracles. To make the query complexity and coherence preservation explicit, we have added a dedicated subsection in §5 together with an appendix that tabulates the per-component oracle queries and shows that no super-logarithmic overhead is introduced beyond the factors already absorbed in the O(polylog(N/ε)^k) expression. revision: yes
-
Referee: [§4 and §5] §4 (quartic regime) and §5: the transition from the no-assumption quadratic regime to the weight-access quartic and then to the joint-access polylog regimes is load-bearing for the central claim, but the paper does not quantify the concrete gate or query overhead of implementing the residual blocks and non-linear functions under each access model, nor does it include an error-propagation analysis across layers.
Authors: We agree that explicit overhead quantification and error propagation strengthen the regime transitions. In the revised manuscript we have expanded §4 and §5 with (i) concrete gate-count estimates for each residual-block primitive (2-D convolution, sigmoid, layer norm, skip connection) under the three access models, and (ii) a new error-propagation subsection showing that choosing per-layer precision O(ε/k) keeps the total accumulated error ≤ ε while preserving the stated complexity scalings. These additions make the quartic-to-polylog transition fully rigorous. revision: yes
Circularity Check
No circularity; complexity bounds derived from standard quantum primitives under external access assumptions
full rationale
The paper derives quadratic, quartic, and polylog(N/ε)^k inference costs for ResNet-style networks by composing known quantum algorithms (block-encodings, quantum linear algebra for convolutions, and coherent implementations of sigmoid/layer-norm) under three explicitly stated regimes of quantum data access. The O(polylog(N/ε)^k) claim for k residual blocks follows directly from the assumed efficient oracles/QRAM without any reduction of a derived quantity to a fitted parameter, self-defined term, or unverified self-citation chain. All steps remain self-contained against external quantum query complexity benchmarks and do not invoke internal fits or renamings that would create circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Efficient quantum access to inputs and weights is possible via oracles or QRAM without destroying coherence
- domain assumption Non-linear activations such as sigmoid can be implemented coherently on quantum states with controlled error
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We derive a novel quantum algorithm for the multiplication of arbitrary full-rank and dense matrices with the element-wise square of a given vector, without incurring a rank-dependence... QRAM-free block-encoding for 2D multi-filter convolutions.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
residual blocks with multi-filter 2D convolutions, sigmoid activations, skip-connections, and layer normalizations... norm preservation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. Deep learning.Nature, 521(7553): 436–444, 2015. URLhttps://doi.org/10.1038/nature14539
-
[2]
Ian Goodfellow, Yoshua Bengio, and Aaron Courville.Deep Learning. MIT Press, 2016. URL http://www.deeplearningbook.org
work page 2016
-
[3]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016. URLhttps://doi.org/10.1109/CVPR. 2016.90
-
[4]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors,Advances in Neural Information Processing Systems, volume 33, pages 6840–6851. Curran Associates, Inc.,
-
[5]
URL https://proceedings.neurips.cc/paper_files/paper/2020/ hash/4c5bcfec8584af0d967f1ab10179ca4b-Abstract.html
work page 2020
-
[6]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2021. URL https:...
work page 2021
-
[7]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, U. V on Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc.,
-
[8]
URL https://proceedings.neurips.cc/paper_files/paper/2017/ hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html
work page 2017
-
[9]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhari- wal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agar- wal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Sco...
work page 1901
-
[10]
URL https://proceedings.neurips.cc/paper_files/paper/2020/ hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html
work page 2020
-
[11]
David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel, and Demis Hassabis. Master- ing the...
-
[12]
John Jumper, Richard Evans, Alexander Pritzel, Tim Green, Michael Figurnov, Olaf Ron- neberger, Kathryn Tunyasuvunakool, Russ Bates, Augustin Žídek, Anna Potapenko, Alex Bridgland, Clemens Meyer, Simon A. A. Kohl, Andrew J. Ballard, Andrew Cowie, Bernardino Romera-Paredes, Stanislav Nikolov, Rishub Jain, Jonas Adler, Trevor Back, Stig Petersen, David Reim...
-
[13]
Alhussein Fawzi, Matej Balog, Aja Huang, Thomas Hubert, Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Francisco J. R. Ruiz, Julian Schrit- twieser, Grzegorz Swirszcz, David Silver, Demis Hassabis, and Pushmeet Kohli. Discov- ering faster matrix multiplication algorithms with reinforcement learning.Nature, 610 (7930):47–53, October...
work page 2022
-
[14]
Gordon E. Moore. Cramming more components onto integrated circuits.Electronics, 38(8):114–117, April 1965. URL https://ieeexplore.ieee.org/document/ 4785860
work page 1965
-
[15]
Richard P. Feynman. Simulating physics with computers.International Journal of Theoretical Physics, 21(6–7):467–488, June 1982. ISSN 1572-9575. URL https://doi.org/10. 1007/BF02650179
work page 1982
-
[16]
Richard P. Feynman. Quantum mechanical computers.Foundations of Physics, 16(6):507–531, June 1986. ISSN 1572-9516. URLhttps://doi.org/10.1007/BF01886518
-
[17]
Michael A. Nielsen and Isaac L. Chuang.Quantum Computation and Quantum Information. Cambridge University Press, 2010. ISBN 9781107002173. URL https://doi.org/10. 1017/CBO9780511976667
work page 2010
-
[18]
Jacob Biamonte, Peter Wittek, Nicola Pancotti, Patrick Rebentrost, Nathan Wiebe, and Seth Lloyd. Quantum machine learning.Nature, 549(7671):195–202, 2016. URL https: //doi.org/10.1038/nature23474
-
[19]
M. Schuld and F. Petruccione.Machine Learning with Quantum Computers. Springer Cham, 2021. ISBN 9783030830984. URL https://doi.org/10.1007/ 978-3-030-83098-4
work page 2021
-
[20]
Yuxuan Du, Xinbiao Wang, Naixu Guo, Zhan Yu, Yang Qian, Kaining Zhang, Min-Hsiu Hsieh, Patrick Rebentrost, and Dacheng Tao. Quantum machine learning: A hands-on tutorial for machine learning practitioners and researchers, 2025. URL https://arxiv.org/abs/ 2502.01146
-
[21]
Quantum Computing in the NISQ era and beyond
John Preskill. Quantum computing in the NISQ era and beyond.Quantum, 2:79, August 2018. URLhttps://doi.org/10.22331/q-2018-08-06-79. 11
work page internal anchor Pith review doi:10.22331/q-2018-08-06-79 2018
-
[22]
Nature Communications , author =
Alberto Peruzzo, Jarrod McClean, Peter Shadbolt, Man-Hong Yung, Xiao-Qi Zhou, Peter J. Love, Alán Aspuru-Guzik, and Jeremy L. O’Brien. A variational eigenvalue solver on a photonic quantum processor.Nature Communications, 5:4213, 2014. URLhttps://doi. org/10.1038/ncomms5213
-
[23]
Variational Quantum Algorithms,
Marco Cerezo, Andrew Arrasmith, Ryan Babbush, Simon C. Benjamin, Suguru Endo, Keisuke Fujii, Jarrod R. McClean, Kosuke Mitarai, Xiao Yuan, Lukasz Cincio, and Patrick J. Coles. Variational quantum algorithms.Nat. Rev. Phys, 3(9):625–644, August 2021. URL http: //doi.org/10.1038/s42254-021-00348-9
-
[24]
Marcello Benedetti, Erika Lloyd, Stefan Sack, and Mattia Fiorentini. Parameterized quantum circuits as machine learning models.Quantum Sci. Technol., 4(4):043001, November 2019. URLhttp://doi.org/10.1088/2058-9565/ab4eb5
-
[25]
Training variational quantum algorithms is NP-hard.Phys
Lennart Bittel and Martin Kliesch. Training variational quantum algorithms is NP-hard.Phys. Rev. Lett., 127:120502, Sep 2021. URL https://link.aps.org/doi/10.1103/ PhysRevLett.127.120502
work page 2021
-
[26]
Eric R. Anschuetz and Bobak T. Kiani. Quantum variational algorithms are swamped with traps.Nature Communications, 13(1), December 2022. ISSN 2041-1723. URL https: //doi.org/10.1038/s41467-022-35364-5
-
[27]
Jarrod R. McClean, Sergio Boixo, Vadim N. Smelyanskiy, Ryan Babbush, and Hartmut Neven. Barren plateaus in quantum neural network training landscapes.Nature Communications, 9 (1), November 2018. URLhttps://doi.org/10.1038/s41467-018-07090-4
-
[28]
Coles, Lukasz Cincio, Jarrod R
Martín Larocca, Supanut Thanasilp, Samson Wang, Kunal Sharma, Jacob Biamonte, Patrick J. Coles, Lukasz Cincio, Jarrod R. McClean, Zoë Holmes, and M. Cerezo. Barren plateaus in variational quantum computing, March 2025. ISSN 2522-5820. URL https://doi.org/ 10.1038/s42254-025-00813-9
-
[29]
Cerezo, Martin Larocca, Diego García-Martín, N
M. Cerezo, Martin Larocca, Diego García-Martín, N. L. Diaz, Paolo Braccia, Enrico Fontana, Manuel S. Rudolph, Pablo Bermejo, Aroosa Ijaz, Supanut Thanasilp, Eric R. Anschuetz, and Zoë Holmes. Does provable absence of barren plateaus imply classical simulability?Nature Communications, 16(1), August 2025. ISSN 2041-1723. URL https://doi.org/10. 1038/s41467-...
work page 2025
-
[30]
Rudolph, Zoë Holmes, Lukasz Cincio, and M
Pablo Bermejo, Paolo Braccia, Manuel S. Rudolph, Zoë Holmes, Lukasz Cincio, and M. Cerezo. Quantum convolutional neural networks are (effectively) classically simulable,
-
[31]
URLhttps://arxiv.org/abs/2408.12739
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
V ojtˇech Havlíˇcek, Antonio D. Córcoles, Kristan Temme, Aram W. Harrow, Abhinav Kandala, Jerry M. Chow, and Jay M. Gambetta. Supervised learning with quantum-enhanced feature spaces.Nature, 567(7747):209–212, March 2019. ISSN 1476-4687. URL https://doi. org/10.1038/s41586-019-0980-2
-
[33]
Quantum machine learning in feature Hilbert spaces
Maria Schuld and Nathan Killoran. Quantum machine learning in feature Hilbert spaces. Phys. Rev. Lett., 122:040504, February 2019. URL https://link.aps.org/doi/10. 1103/PhysRevLett.122.040504
work page 2019
-
[34]
Marcello Benedetti, Delfina Garcia-Pintos, Oscar Perdomo, Vicente Leyton-Ortega, Yunseong Nam, and Alejandro Perdomo-Ortiz. A generative modeling approach for benchmarking and training shallow quantum circuits.npj Quantum Information, 5(1), May 2019. ISSN 2056-6387. URLhttps://doi.org/10.1038/s41534-019-0157-8
-
[35]
Po-Wei Huang and Patrick Rebentrost. Post-variational quantum neural networks, 2024. URL https://arxiv.org/abs/2307.10560
-
[36]
Supanut Thanasilp, Samson Wang, M. Cerezo, and Zoë Holmes. Exponential concentration in quantum kernel methods.Nature Communications, 15(1), June 2024. ISSN 2041-1723. URL https://doi.org/10.1038/s41467-024-49287-w. 12
-
[37]
Manuel S. Rudolph, Sacha Lerch, Supanut Thanasilp, Oriel Kiss, Oxana Shaya, Sofia Val- lecorsa, Michele Grossi, and Zoë Holmes. Trainability barriers and opportunities in quantum generative modeling.npj Quantum Information, 10(1), November 2024. ISSN 2056-6387. URLhttps://doi.org/10.1038/s41534-024-00902-0
-
[38]
Quantum A lgorithm for Linear Systems of Equations
Aram W. Harrow, Avinatan Hassidim, and Seth Lloyd. Quantum algorithm for linear systems of equations.Phys. Rev. Lett., 103:150502, October 2009. URL https://link.aps. org/doi/10.1103/PhysRevLett.103.150502
-
[39]
Quantum algorithms: an overview.npj Quantum Information, 2(1), January
Ashley Montanaro. Quantum algorithms: an overview.npj Quantum Information, 2(1), January
-
[40]
Quantum algorithms: an overview,
ISSN 2056-6387. URLhttps://doi.org/10.1038/npjqi.2015.23
-
[41]
Proceedings of the 51st Annual ACM SIGACT Symposium on Theory of Computing , pages =
András Gilyén, Yuan Su, Guang Hao Low, and Nathan Wiebe. Quantum singular value transformation and beyond: exponential improvements for quantum matrix arithmetics. In Proceedings of the 51st Annual ACM SIGACT Symposium on Theory of Computing, STOC 2019, pages 193–204, New York, NY , USA, 2019. Association for Computing Machinery. ISBN 9781450367059. URLht...
-
[42]
Dalzell, Sam McArdle, Mario Berta, Przemyslaw Bienias, Chi-Fang Chen, András Gilyén, Connor T
Alexander M. Dalzell, Sam McArdle, Mario Berta, Przemyslaw Bienias, Chi-Fang Chen, András Gilyén, Connor T. Hann, Michael J. Kastoryano, Emil T. Khabiboulline, Aleksander Kubica, Grant Salton, Samson Wang, and Fernando G. S. L. Brandão. Quantum algorithms: A survey of applications and end-to-end complexities, April 2025. URL https://doi.org/ 10.1017/9781009639651
-
[43]
Patrick Rebentrost, Masoud Mohseni, and Seth Lloyd. Quantum support vector machine for big data classification.Phys. Rev. Lett., 113:130503, September 2014. URL https: //link.aps.org/doi/10.1103/PhysRevLett.113.130503
-
[44]
Quantum algorithm for data fitting.Phys
Nathan Wiebe, Daniel Braun, and Seth Lloyd. Quantum algorithm for data fitting.Phys. Rev. Lett., 109:050505, Aug 2012. URL https://link.aps.org/doi/10.1103/ PhysRevLett.109.050505
work page 2012
-
[45]
Quantum algorithms for feedforward neural networks.ACM Trans
Jonathan Allcock, Chang-Yu Hsieh, Iordanis Kerenidis, and Shengyu Zhang. Quantum algorithms for feedforward neural networks.ACM Trans. Quantum Comput., 1(1), October
-
[46]
URLhttps://doi.org/10.1145/3411466
-
[47]
Quantum algorithms for deep convolutional neural networks
Iordanis Kerenidis, Jonas Landman, and Anupam Prakash. Quantum algorithms for deep convolutional neural networks. InInternational Conference on Learning Representations,
-
[48]
URLhttps://openreview.net/forum?id=Hygab1rKDS
-
[49]
Quantum linear algebra is all you need for Transformer architectures,
Naixu Guo, Zhan Yu, Matthew Choi, Aman Agrawal, Kouhei Nakaji, Alán Aspuru-Guzik, and Patrick Rebentrost. Quantum linear algebra is all you need for Transformer architectures,
- [50]
-
[51]
Quantum principal component analysis
Seth Lloyd, Masoud Mohseni, and Patrick Rebentrost. Quantum principal component analysis. Nature Physics, 10(9):631–633, July 2014. ISSN 1745-2481. URL https://doi.org/ 10.1038/nphys3029
-
[52]
Nathan Wiebe, Ashish Kapoor, and Krysta M. Svore. Quantum deep learning.Quantum Information and Computation, 16(7 & 8):541–587, May 2016. ISSN 1533-7146. URL https://doi.org/10.26421/QIC16.7-8-1
-
[53]
Bromley, Christian Weedbrook, and Seth Lloyd
Patrick Rebentrost, Thomas R. Bromley, Christian Weedbrook, and Seth Lloyd. Quantum Hopfield neural network.Phys. Rev. A, 98:042308, October 2018. URL https://link. aps.org/doi/10.1103/PhysRevA.98.042308
-
[54]
Ashish Kapoor, Nathan Wiebe, and Krysta Svore. Quantum perceptron models. In D. Lee, M. Sugiyama, U. Luxburg, I. Guyon, and R. Garnett, editors,Ad- vances in Neural Information Processing Systems, volume 29. Curran Associates, Inc., 2016. URL https://proceedings.neurips.cc/paper/2016/hash/ d47268e9db2e9aa3827bba3afb7ff94a-Abstract.html. 13
work page 2016
-
[55]
Quantum vision transformers.Quantum, 8:1265, February 2024
El Amine Cherrat, Iordanis Kerenidis, Natansh Mathur, Jonas Landman, Martin Strahm, and Yun Yvonna Li. Quantum vision transformers.Quantum, 8:1265, February 2024. ISSN 2521-327X. URLhttps://doi.org/10.22331/q-2024-02-22-1265
-
[56]
A rig orous and robust quantum speed-up in supervised machine learning
Yunchao Liu, Srinivasan Arunachalam, and Kristan Temme. A rigorous and robust quantum speed-up in supervised machine learning.Nature Physics, 17:1013–1017, 2021. URL https: //doi.org/10.1038/s41567-021-01287-z
-
[57]
Siyi Yang, Naixu Guo, Miklos Santha, and Patrick Rebentrost. Quantum Alphatron: quantum advantage for learning with kernels and noise.Quantum, 7:1174, November 2023. ISSN 2521-327X. URLhttps://doi.org/10.22331/q-2023-11-08-1174
-
[58]
QKAN: Quantum Kolmogorov-Arnold networks, 2024
Petr Ivashkov, Po-Wei Huang, Kelvin Koor, Lirandë Pira, and Patrick Rebentrost. QKAN: Quantum Kolmogorov-Arnold networks, 2024. URL https://arxiv.org/abs/2410. 04435
work page 2024
-
[59]
Towards efficient quantum algorithms for diffusion probability models, 2025
Yunfei Wang, Ruoxi Jiang, Yingda Fan, Xiaowei Jia, Jens Eisert, Junyu Liu, and Jin-Peng Liu. Towards efficient quantum algorithms for diffusion probability models, 2025. URL https://arxiv.org/abs/2502.14252
-
[60]
Quantum gradient descent for linear systems and least squares.Phys
Iordanis Kerenidis and Anupam Prakash. Quantum gradient descent for linear systems and least squares.Phys. Rev. A, 101(2), February 2020. ISSN 2469-9934. URL https: //link.aps.org/doi/10.1103/PhysRevA.101.022316
-
[61]
Huggins, Ramis Movas- sagh, Dar Gilboa, and Jarrod McClean
Amira Abbas, Robbie King, Hsin-Yuan Huang, William J. Huggins, Ramis Movas- sagh, Dar Gilboa, and Jarrod McClean. On quantum backpropagation, informa- tion reuse, and cheating measurement collapse. In A. Oh, T. Naumann, A. Glober- son, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Informa- tion Processing Systems, volume 36, pages 44792–4...
-
[62]
URL https://proceedings.neurips.cc/paper_files/paper/2023/ hash/8c3caae2f725c8e2a55ecd600563d172-Abstract.html
work page 2023
-
[63]
Ji Liu, Mengzhen Liu, Jiapeng Liu, Chengran Peng, Liyuan Zhang, Xiao Yuan, Peng Xue, and Xiongfeng Ma. Towards provably efficient quantum algorithms for large-scale machine- learning models.Nature Communications, 15:434, 2024. URL https://doi.org/10. 1038/s41467-023-43957-x
work page 2024
-
[64]
Aggregated residual transformations for deep neural networks
Saining Xie, Ross Girshick, Piotr Dollár, Zhuowen Tu, and Kaiming He. Aggregated residual transformations for deep neural networks. In2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 5987–5995, 2017. URL https://doi.org/10. 1109/CVPR.2017.634
work page 2017
-
[65]
Attention is not all you need: pure attention loses rank doubly exponentially with depth
Yihe Dong, Jean-Baptiste Cordonnier, and Andreas Loukas. Attention is not all you need: pure attention loses rank doubly exponentially with depth. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 2793–2803. PMLR, 18–24 Jul 2021. URLhtt...
work page 2021
-
[66]
Iris Cong, Soonwon Choi, and Mikhail D. Lukin. Quantum convolutional neural networks. Nature Physics, 15(12):1273–1278, August 2019. URL http://doi.org/10.1038/ s41567-019-0648-8
work page 2019
-
[67]
Arthur G. Rattew and Patrick Rebentrost. Non-linear transformations of quantum amplitudes: Exponential improvement, generalization, and applications, 2023. URL https://arxiv. org/abs/2309.09839
-
[68]
Yu Cheng, Duo Wang, Pan Zhou, and Tao Zhang. Model compression and acceleration for deep neural networks: The principles, progress, and challenges.IEEE Signal Processing Magazine, 35(1):126–136, 2018. URLhttps://doi.org/10.1109/MSP.2017.2765695
-
[69]
Sergey Zagoruyko and Nikos Komodakis. Wide residual networks. InProcedings of the British Machine Vision Conference 2016, BMVC 2016, pages 87.1–87.12. British Machine Vision Association, 2016. URLhttps://doi.org/10.5244/C.30.87. 14
- [70]
-
[71]
Dalzell, András Gilyén, Connor T
Alexander M. Dalzell, András Gilyén, Connor T. Hann, Sam McArdle, Grant Salton, Quynh T. Nguyen, Aleksander Kubica, and Fernando G. S. L. Brandão. A distillation-teleportation pro- tocol for fault-tolerant QRAM, 2025. URLhttps://arxiv.org/abs/2505.20265
-
[72]
Bilinear CNN models for fine- grained visual recognition
Tsung-Yu Lin, Aruni RoyChowdhury, and Subhransu Maji. Bilinear CNN models for fine- grained visual recognition. In2015 IEEE International Conference on Computer Vision (ICCV), pages 1449–1457. IEEE, December 2015. URL https://doi.org/10.1109/ ICCV.2015.170
work page 2015
-
[73]
Quantum-state preparation with universal gate decomposi- tions.Phys
Martin Plesch and ˇCaslav Brukner. Quantum-state preparation with universal gate decomposi- tions.Phys. Rev. A, 83:032302, March 2011. URL https://link.aps.org/doi/10. 1103/PhysRevA.83.032302
work page 2011
-
[74]
Yudong Cao, Anargyros Papageorgiou, Iasonas Petras, Joseph Traub, and Sabre Kais. Quan- tum algorithm and circuit design solving the Poisson equation.New Journal of Physics, 15(1):013021, January 2013. ISSN 1367-2630. URL https://doi.org/10.1088/ 1367-2630/15/1/013021
work page 2013
-
[75]
High-precision quantum algorithms for partial differential equations.Quantum, 5:574, 2021
Andrew M Childs, Jin-Peng Liu, and Aaron Ostrander. High-precision quantum algorithms for partial differential equations.Quantum, 5:574, 2021. URL https://doi.org/10. 22331/q-2021-11-10-574
work page 2021
-
[76]
Dominic W. Berry and Pedro C. S. Costa. Quantum algorithm for time-dependent differential equations using Dyson series.Quantum, 8:1369, June 2024. ISSN 2521-327X. URL https://doi.org/10.22331/q-2024-06-13-1369
-
[77]
David Jennings, Matteo Lostaglio, Robert B Lowrie, Sam Pallister, and Andrew T Sornborger. The cost of solving linear differential equations on a quantum computer: fast-forwarding to explicit resource counts.Quantum, 8:1553, 2024. URL https://doi.org/10.22331/ q-2024-12-10-1553
work page 2024
-
[78]
Fast-forwarding quantum algorithms for linear dissipative differential equations, 2024
Dong An, Akwum Onwunta, and Gengzhi Yang. Fast-forwarding quantum algorithms for linear dissipative differential equations, 2024. URL https://arxiv.org/abs/2410. 13189
work page 2024
-
[79]
Designing a nearly optimal quantum algorithm for linear differential equations via Lindbladians.Phys
Zhong-Xia Shang, Naixu Guo, Dong An, and Qi Zhao. Designing a nearly optimal quantum algorithm for linear differential equations via Lindbladians.Phys. Rev. Lett., 135:120604, Sep
-
[80]
URLhttps://link.aps.org/doi/10.1103/cvl9-97qg
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.